【大模型与信息抽取】InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
本文提出InstructUIE,一个基于指令微调的统一信息抽取框架。该框架将不同IE任务重构为自然语言生成任务,通过设计描述性指令引导模型理解任务并约束输出空间。作者构建了包含32个数据集的IEINSTRUCTIONS基准测试集,实验表明InstructUIE在监督设置下性能与Bert相当,在零样本设置下显著优于GPT3.5和领域最优模型。
前言:大模型在信息抽取任务上存在困难,本文提出了InstructUIE,一个基于指令微调的统一信息抽取框架,它在32个不同信息抽取数据集上进行了验证,实验结果表明该模型实现了与bert相当的性能,并且在零样本设置中显著优于gpt3.5和领域最优。
1.介绍
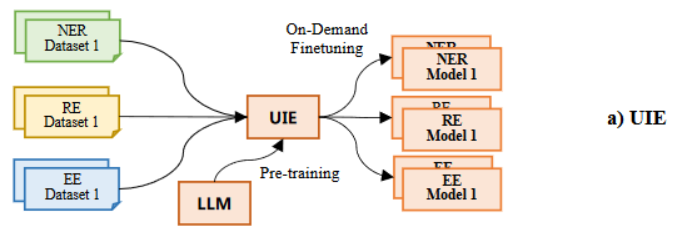
最近的UIE通过结构化抽取语言统一编码不同的抽取结构,并通过大规模预训练的文本到结构的模型去捕获常见的IE能力。但是UIE需要针对不同的下游任务进行微调,导致其在低资源场景表现不佳。
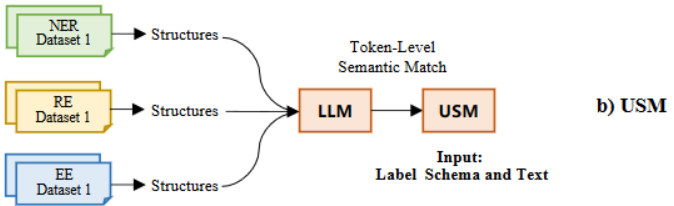
此外,Lou等人提出的USM,将IE任务解耦成两个基本任务,token-token链接以抽取标签不可知子结构以及label-token链接以提取标签不可知的子结构。该方法有两点主要缺陷,首先将IE转为语义匹配任务,难以和生成模型进行融合。其次该方法需要对每个单词进行语义匹配,导致训练和推理时间增加。
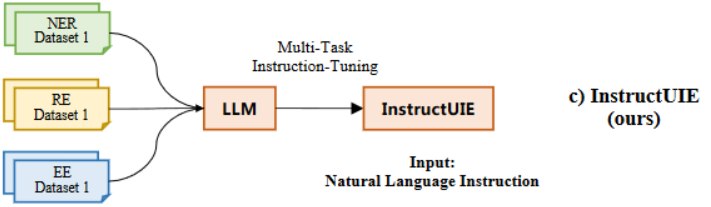
本文中作者将IE任务表示为自然语言生成任务。对于源句子,作者设计描述性指令让模型能够理解不同的任务并对输出空间进行约束,其次,需要预训练的语言模型以自然语言的形式生成目标结构和相应的类型。辅助信息(Auxiliary Tasks)为了让模型捕获共同的结构信息并加深对不同语义的理解,作者为NER引入实体跨度抽取任务和实体类型任务,为关系抽取引入了实体对抽取任务和实体对关系识别任务,为事件抽取引入触发抽取任务和参数抽取任务。
为了评估模型的有效性,作者开发了名为IE INSTRUCTIONS的benchmark。该benchmark由32个不同的信息抽取数据集组成,并且已经统一好格式。允许对各种IE任务进行一致和标准化的评估。
本文的主要贡献如下:
- 通用抽取端到端InstructUIE:利用自然语言指令来指导大模型完成IE任务;
- IE INSTRUCTIONS的benchmark:由32个不同信息抽取数据集构成的benchmark,对各种IE任务进行一致性评估;
- 实验结果:InstructUIE 在监督设置中实现了与 Bert 相当的性能,并且在零样本设置中显著优于gpt3.5和领域最优。
2.方法
指令微调是一种多任务学习框架 ,使用人类可读的指令来指导LLM的输出。给定源文本和特定任务的指令,去训练模型生成一系列表示所需输出结构及其相应的标签。所有的任务在训练时提供指令,模型针对每个任务的标签数据进行微调。这允许模型学习特定于任务的特征并针对每个任务进行优化。在零样本设置下,仅在训练期间为任务的子集提供指令,在未见的任务上进行评估。
2.1 框架
任务模式(Task Schema):为了更好迁移和利用模型预训练学习到的知识,作者将IE任务重建为Seq2Seq形式,并通过微调LLM进行求解,如下图所示,每个任务实例都格式化为四个属性:任务指令,选项,文本和输出。
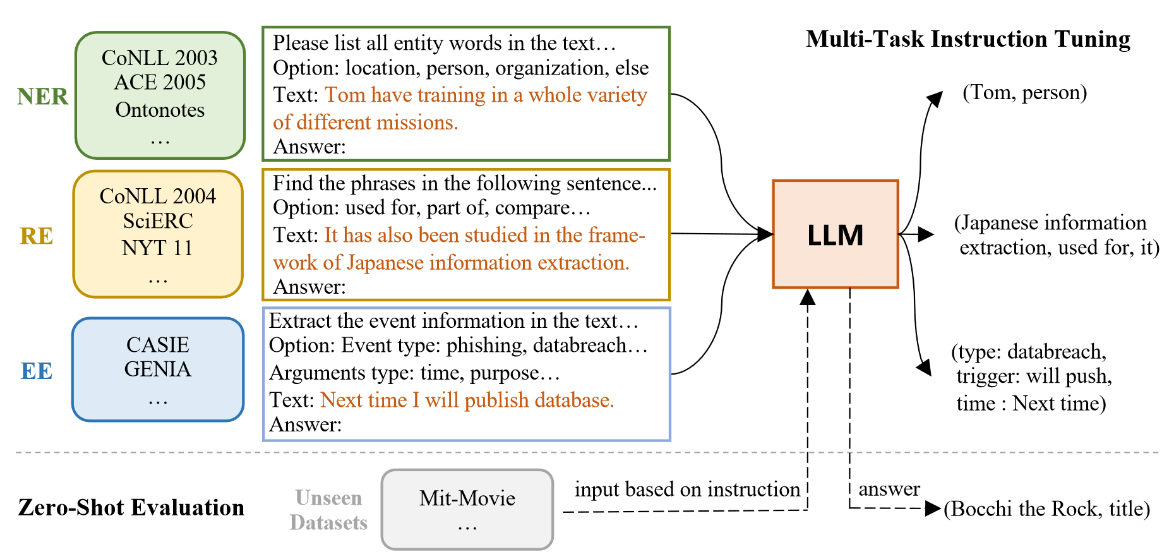
输入:任务指令、选项和文本组成。输出:从原始标签结构转换而来的更易于理解的句子。
任务指令(Task Instruction):下图显示了不同任务的提示。
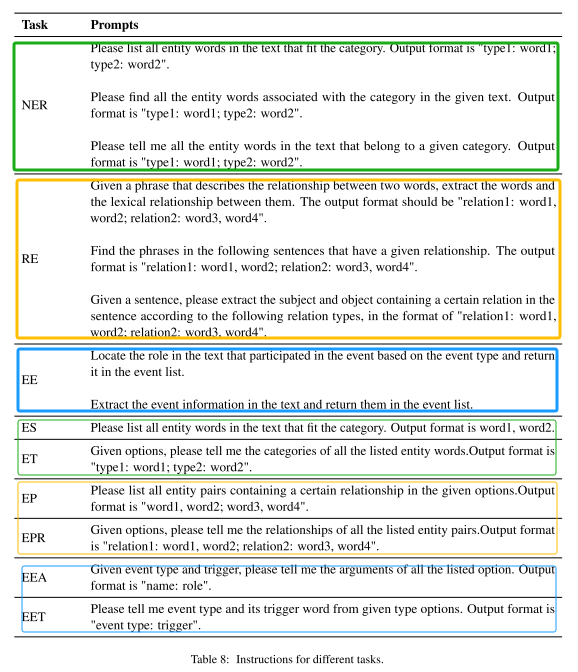
- NER:命名实体识别任务,输出句子中的实体及其对应的实体类型。
- RE:关系抽取任务,抽取句子中的关系三元组,包括关系名称、头实体和尾实体。
- EE:事件提取任务,提取句子中的事件类型、触发词和论元。
- ES:实体跨度任务,任务目标被赋予句子和实体类别选项,输出符合实体类别的实体,但不需要输出每个实体的实体类型;
- ET:实体类型识别任务,给定的句子,其中包含实体和实体类别选项,并输出每个实体对应的实体类别。
- EP:实体对标识(实体对),被赋予句子和关系类别选项,输出符合关系类别的实体对,但不需要输出其关系类别;
- EPR:实体对关系识别,给定的句子,其中包含实体对和关系类别选项,并为每个实体对输出对应的关系类别。
- ES和ET是NER的辅助任务,EP和EPR是RE的辅助任务,EEA和EET是EE的辅助任务。
选项(Options):选项是模型输出的任务特定的标签约束,对于输入,模型能够输出的标签集合。Options能够为模型提供结构化的输出空间,使其能够生成与任务底层语义结构一致的输出。文本(Text):文本是任务实例的输入句子。Output:输出是由样本的原始标签转换的句子。NER任务输出的格式是:“entity tag: entity span”,RE任务的输出格式是:“relationship: head entity, tail entity”,对于EE任务,输出格式为:“event tag: trigger word, argument tag: argument span”。为了防止输入不包含任何与选项匹配的结构,将“None”分配给相应的输出。
辅助信息(Auxiliary Tasks):为任务提供补充的信息,使模型能够更好捕捉共同结构并加深对不同语义的理解。命名实体识别任务:作者引入了跨度提取任务和实体类型识别任务。关系抽取任务:作者引入实体对抽取任务和关系分类任务。事件抽取任务:作者引入trigger抽取任务和参数抽取任务。前者目的是抽取事件的关键词,后者是抽取事件相关的参数。
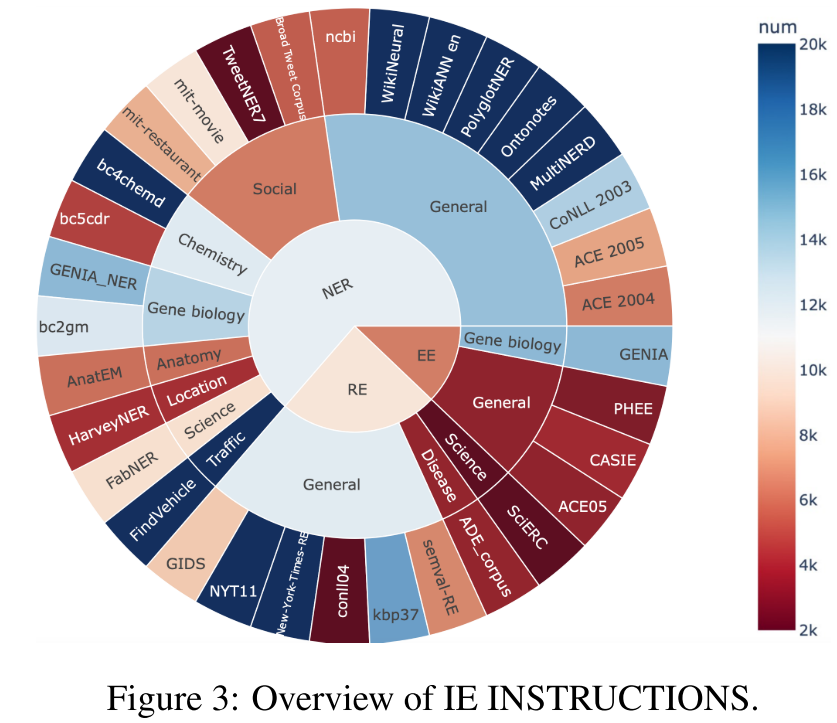
2.2 IE INSTRUCTIONS
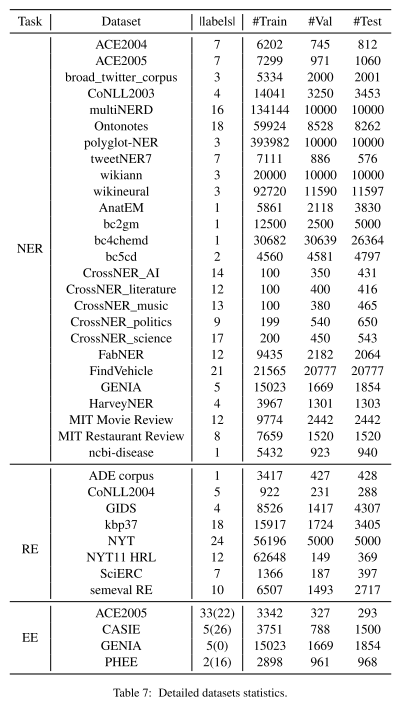
IE INSTRUCTIONS收集了32个数据集,三种IE任务:NER、RE和EE。作者采用了如下的数据处理流程:
- 为了解决不同数据集中标签不一致问题,作者统一了不同数据集中语义相同但名称不同的标签。
- 将有下划线、缩写或特殊格式的标签转换为自然语言格式(如去掉下划线等,“people person place_of_birth”重命名为“place of birth”)。
- 把所有数据集转换为文本到文本的格式,确保所有任务中输入输出的一致性。
3.实验结果
在监督和零样本设置下进行了大量实验,以验证InstructUIE的有效性。
3.1 监督学习下的实验
- NER任务:遵循跨度评估设置,其中必须正确预测实体边界和实体类型;
- RE任务:需要正确预测实体主体、实体客体和实体关系的边界;
- EE任务:提供了两种评估策略:(1) 事件触发器:如果正确预测事件类型和触发词,则事件触发正确;(2) 事件参数:如果事件参数的角色类型和事件类型与参考参数相匹配,则事件参数是正确的。
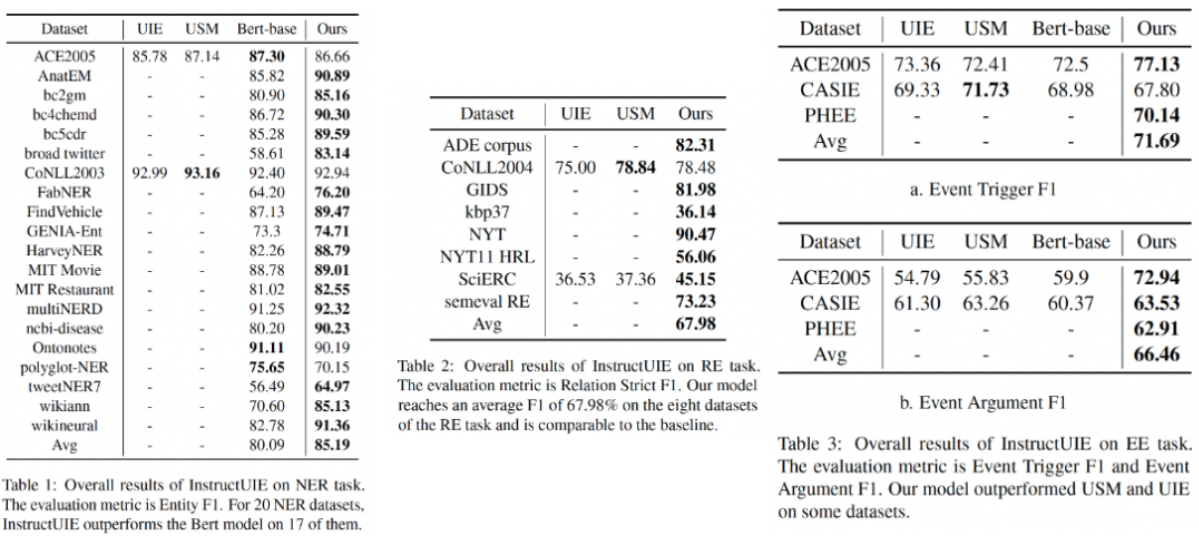
在绝大部分信息抽取任务中(85%以上)都超越单个小模型的预训练微调结果。
NER:模型在20个NER数据集上取得了85.19%的平均F1,超越Bert的80.09%,并且在17个数据集上的表现都超过了Bert。在推特数据集上甚至比Bert高出了25%。但是在ACE2005、Ontonotes和Polyglot-NER数据集上表现不如Bert,可能的原因是随机抽样的数据只有10000条,而原始数据集如Polyglot-NER多达420000条。由于UIE和USM测试的数据集较少,无法进行明确的比较。
RE:模型在8个数据集上取得了67.98%的平均F1,其中NYT数据集达到了90.47%。在SciERC数据集上远超UIE和USM。
EE:模型几乎在所有数据集上都取得了SOTA。
3.2 Zero-shot下的实验
为了评估InstructUIE的零样本性能,作者在18个NER数据集和6个RE数据集上训练模型,并在7个NER数据集和2个RE数据集上进行测试。由于训练和测试任务完全不重叠,而且跨多个领域,这种设置具有挑战性。
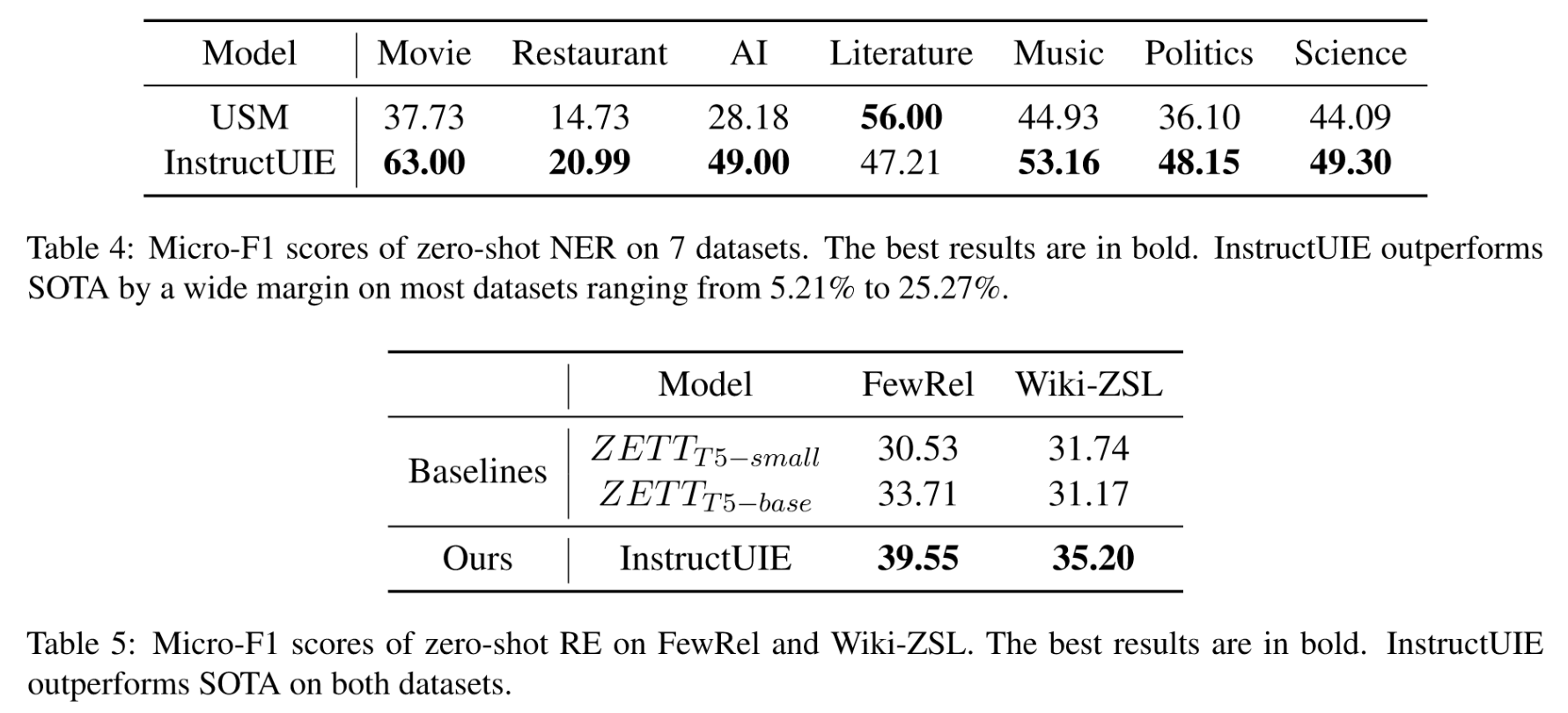
上表展示了在零样本设置下各个模型在NER和RE任务上的表现。在NER任务上,InstructUIE除了Literature表现不佳,其余都优于USM,在RE任务上,InstructUIE也都优于其余两个模型。

与GPT系列模型相比,在NER任务上InstructUIE的表现要落后于ChatGPT,但优于davinci,在RE任务上InstructUIE明显优于ChatGPT。
4.总结
- 指令不够丰富,或者相同任务的不同指令过于相似;
- 模型参数不够大,还可以使用更大的大模型进行微调。
【参考文献】
Wang, X., Zhou, W., Zu, C., Xia, H., Chen, T., Zhang, Y., ... & Du, C. (2023). Instructuie: Multi-task instruction tuning for unified information extraction. arXiv preprint arXiv:2304.08085.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)