自动驾驶中的传感器技术84——Sensor Fusion(7)
混合融合架构是L2++至L4级自动驾驶的主流方案,通过多层次灵活融合传感器数据。该系统包含三条并行处理主线:主感知流(BEV特征融合)、定位流(GNSS/IMU信号融合)和安全流(雷达/超声波后融合)。处理流程分为四个阶段:原始信号时空对齐、BEV深度特征融合、定位修正反馈和安全校验兜底。该架构采用AI主感知与传统传感器校验相结合的方式,既发挥深度学习优势又确保系统安全,通过ROI融合等特殊模式提
混合融合
混合跨层级融合(Hybrid / Cascaded / Multi-Level Fusion) 是当前 L2++ 到 L4 级自动驾驶量产方案(如特斯拉 FSD、华为 ADS、小鹏 XNGP)中最主流、最务实的架构。
它不拘泥于单一的“前融合”或“后融合”,而是根据传感器的特性和算力限制,在数据流的不同阶段灵活地进行多次融合。
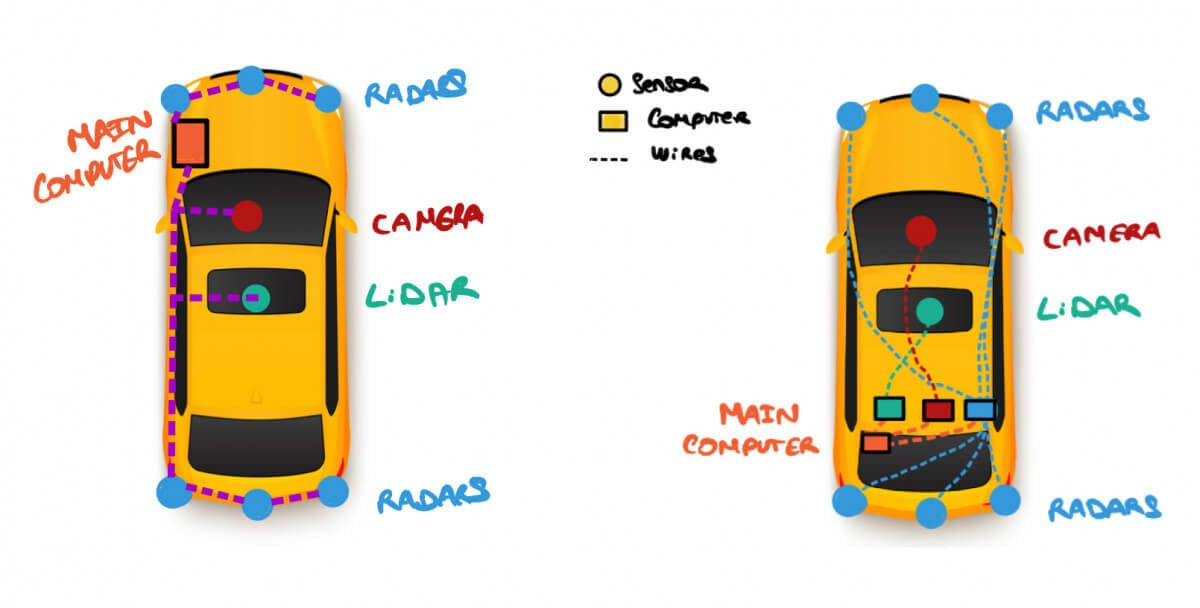
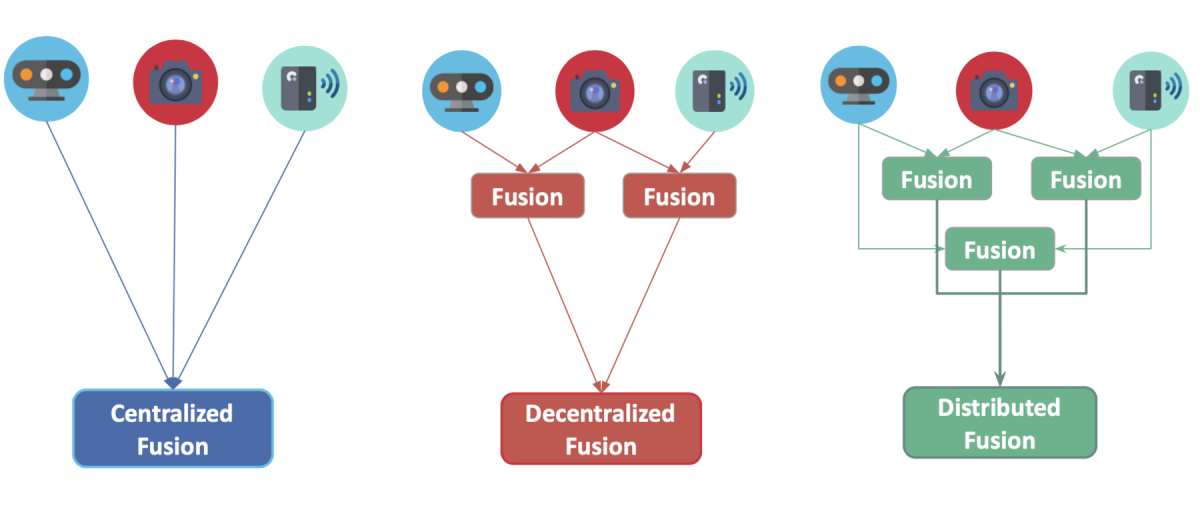 这种架构通常是一个串行与并行结合的复杂图网络。以下是其典型的系统架构解析:
这种架构通常是一个串行与并行结合的复杂图网络。以下是其典型的系统架构解析:
1. 核心架构逻辑
混合融合通常分为三条主线并行处理,最后汇聚:
-
主感知流(Deep Fusion): 以 BEV(鸟瞰图)为核心,进行 Camera + LiDAR 的特征级融合。
-
定位流(Signal Fusion): GNSS + IMU 的原始信号级融合,并接受感知流的反馈。
-
安全流(Safety Check): Radar + Ultrasonic 的后融合,作为系统的“安全兜底”。
2. 详细的跨层级融合步骤
阶段一:时空对齐与原始信号增强(Raw Data Level)
-
GNSS + IMU (紧耦合):
-
在最底层进行 Raw Data 融合,输出高频的 Pose(位姿)预测。
-
LiDAR 去畸变:
-
利用 IMU 的高频 Pose 数据,修正 LiDAR 点云在扫描过程中的运动畸变。
-
结果: 产生统一的时间戳和精确的自车运动状态。
阶段二:深度特征融合 —— 主感知引擎(Feature Level)
这是目前最先进的 BEV Transformer 架构所在层级。
-
输入:
-
Camera: 多路图像特征。
-
LiDAR: 经过体素化(Voxelization)的点云特征。
-
Radar: 部分方案(如华为)会将 4D 雷达的点云特征也输入进来。
融合过程:
-
空间变换: 将 Camera 的透视视角的特征图,和 LiDAR 的 3D 特征图,都投影到统一的 BEV 空间。
-
Cross-Attention (交叉注意力): 神经网络自动学习图像纹理和点云几何的对应关系。
-
时序融合 (Temporal Fusion): 将上一帧(t−1t−1)的 BEV 特征与当前帧(tt)融合,形成 4D 时空特征(增加时间维)。
-
输出: 3D 目标检测框、车道线拓扑、可行驶区域(Occupancy)。
阶段三:定位修正(Object + Signal Level)
这是一个典型的跨层级反馈回路。
-
输入:
-
阶段一输出的 GNSS/IMU 粗略定位(Signal Level)。
-
阶段二输出的 车道线/地标识别结果(Object Level)。
-
融合:
-
高精地图匹配 (Map Matching): 将视觉识别到的车道线与高精地图进行对比。
-
图优化 (Graph Optimization): 利用视觉观测作为约束条件,修正 GNSS/IMU 的漂移。
-
输出: 厘米级的全局绝对定位。
阶段四:安全兜底与校验(Object + Cluster Level)
神经网络虽然强大,但有“幻觉”风险。这一步是传统的后融合,用于保命。
-
场景: AEB(自动紧急制动)决策。
-
输入:
-
阶段二输出的 AI 感知目标(Object List,比如“前面无车”)。
-
毫米波雷达的原始聚类点(Cluster List,比如“前方 50 米有强反射信号”)。
-
融合逻辑 (Gating Logic):
-
如果 AI 说没车,但雷达检测到持续的、高信噪比的障碍物回波。
-
强制覆盖: 系统判定 AI 失效(可能是白墙、翻倒的白色货车),采信雷达数据,触发刹车。
-
超声波融合:
-
在低速泊车时,将超声波的最近障碍物距离直接“切入”控制逻辑,无论视觉是否看到东西,距离小于 30cm 必须刹停。
3. 特殊的混合融合模式:ROI 级融合 (ROI Fusion)
介于特征级和目标级之间,常用于远距离检测。
-
LiDAR 提案: 先用 LiDAR 检测出远处有个物体(位置准,但不知道是什么),生成一个 3D ROI (感兴趣区域)。
-
图像裁剪: 将这个 3D ROI 投影回 2D 图像,裁剪出对应的一小块图片。
-
视觉分类: 将这一小块图片送入专门的 CNN 进行分类(是石头还是人?)。
-
优势: 省算力(不用全图处理),且解决了 LiDAR 缺乏语义信息的问题。
4. 不同融合的对比
|
融合层级 |
优点 |
缺点 |
混合架构中的角色 |
|---|---|---|---|
|
raw data |
信息无损,精度最高 |
带宽算力地狱,极难工程化 |
仅用于 GNSS/IMU 定位 |
|
Feature (BEV) |
深度学习能力强,适应恶劣天气 |
这是一个“黑盒”,不可解释,有幻觉风险 |
用于 主感知 (画框、车道线) |
|
Object (Track) |
逻辑清晰,代码可解释,算力低 |
丢失原始信息,依赖单传感器性能 |
用于 AEB 安全兜底 和 多源校验 |
5. 总结:一个完整的混合融合数据流
-
Start: 所有传感器采集数据。
-
Signal Fusion: IMU+GNSS 紧耦合,算出车在哪里(PegoPego)。
-
Pre-process: 用 PegoPego 把 LiDAR 点云拉直,把 Radar 坐标对齐。
-
Deep Fusion (AI): 将 Camera 图和 LiDAR 点云扔进 BEV 网络,吐出 "AI 目标列表"。
-
Safety Gate (Logic): 拿 Radar 的原始回波去校验 "AI 目标列表"。如果 Radar 发现 AI 漏检了致命障碍物 -> 报警/刹车。如果 Radar 确认 AI 检测准确 -> 输出最终结果。
-
End: 规划控制模块接收最终的环境模型。
这种**“AI 负责画出丰富世界,传统雷达负责底线安全,IMU 负责连接时空”**的混合架构,是目前自动驾驶技术的终极形态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)