【AI课程领学】第四课3/3:CNN 的压缩——剪枝/量化/蒸馏/低秩分解(从理论到可跑代码)
【AI课程领学】第四课3/3:CNN 的压缩——剪枝/量化/蒸馏/低秩分解(从理论到可跑代码)
·
【AI课程领学】第四课3/3:CNN 的压缩——剪枝/量化/蒸馏/低秩分解(从理论到可跑代码)
【AI课程领学】第四课3/3:CNN 的压缩——剪枝/量化/蒸馏/低秩分解(从理论到可跑代码)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
1. 为什么需要压缩?(不仅是“跑得快”)
CNN 压缩的目标通常有三类:
- 减少参数量:节省存储、降低内存带宽
- 减少计算量(FLOPs):提升推理速度、降低功耗
- 提升部署友好性:适配移动端、边缘设备、实时系统
遥感/地学常见需求:高分影像推理成本巨大,压缩可以让大范围制图更可行。
2. 压缩方法概览(你可以做成总结表)
2.1 剪枝(Pruning)
- 非结构化剪枝:剪掉小权重(稀疏,但不一定加速)
- 结构化剪枝:剪通道/卷积核(更容易加速)
2.2 量化(Quantization)
- FP32 → INT8 / FP16
- 大幅降低存储与加速推理
- 需注意精度损失(尤其回归任务)
2.3 知识蒸馏(Distillation)
- Teacher(大模型)指导 Student(小模型)
- 小模型学到更“平滑”的决策边界
2.4 低秩分解(Low-rank)
- 将卷积/全连接权重矩阵分解
- 减少计算与参数
3. PyTorch:结构化剪枝(通道/卷积核)思路
- PyTorch 内置
torch.nn.utils.prune更偏非结构化剪枝(稀疏权重)。 - 这里先演示非结构化剪枝的最小例子(理解机制),你发博客时再补充结构化思想。
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
conv = nn.Conv2d(3, 16, 3)
print("Before prune:", (conv.weight == 0).float().mean().item())
# L1 非结构化剪枝:剪掉 30% 最小权重
prune.l1_unstructured(conv, name="weight", amount=0.3)
print("After prune:", (conv.weight == 0).float().mean().item())
# 将 mask 合并到参数(永久化)
prune.remove(conv, "weight")
关键理解:
- 非结构化剪枝会产生稀疏矩阵,但普通 GPU/CPU 推理不一定更快
- 真正加速需要结构化剪枝(按通道剪),对应需要重新构建网络结构
4. PyTorch:动态量化(适合 Linear 层,演示原理)
- 动态量化对 Linear/LSTM 更常见,但你可以用它理解“量化工作流”。
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
# 动态量化
qmodel = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
x = torch.randn(4, 128)
with torch.no_grad():
y1 = model(x)
y2 = qmodel(x)
print("FP32 out mean:", y1.mean().item())
print("INT8 out mean:", y2.mean().item())
- CNN 的 INT8 通常用 静态量化(需要校准数据),部署到 TensorRT/ONNXRuntime 更常见。
5. 知识蒸馏:最小可运行范例(分类任务)
蒸馏的常见损失:
- 学生对硬标签(真实 y)的交叉熵
- 学生对教师软标签(logits 温度缩放)的 KL 散度
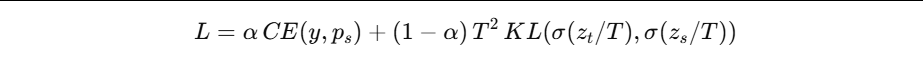
- 下面给你一个可跑骨架(用随机数据演示机制):
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
torch.manual_seed(0)
N, D, C = 1024, 64, 10
X = torch.randn(N, D)
y = torch.randint(0, C, (N,))
teacher = nn.Sequential(nn.Linear(D, 256), nn.ReLU(), nn.Linear(256, C))
student = nn.Sequential(nn.Linear(D, 64), nn.ReLU(), nn.Linear(64, C))
# 假设 teacher 已训练好,这里为了演示直接冻结
for p in teacher.parameters():
p.requires_grad = False
opt = optim.Adam(student.parameters(), lr=1e-3)
T = 3.0
alpha = 0.3
for epoch in range(50):
student.train()
with torch.no_grad():
t_logits = teacher(X)
s_logits = student(X)
hard_loss = F.cross_entropy(s_logits, y)
soft_loss = F.kl_div(
F.log_softmax(s_logits / T, dim=1),
F.softmax(t_logits / T, dim=1),
reduction="batchmean"
) * (T * T)
loss = alpha * hard_loss + (1 - alpha) * soft_loss
opt.zero_grad()
loss.backward()
opt.step()
if (epoch + 1) % 10 == 0:
print(f"epoch {epoch+1}, loss={loss.item():.4f}")
- 你把 teacher 换成 ResNet50,student 换成 MobileNet,就能做真实蒸馏。
6. 压缩方法如何选择?(实践决策指南)
- 想要真正加速:优先结构化剪枝 / 换轻量模型(MobileNet/EfficientNet-Lite)
- 想要快速部署:FP16(半精度)通常最容易,无需太多改动
- 想要极致端侧:INT8 静态量化 + TensorRT/NNAPI
- 想要保持精度:蒸馏通常最稳,尤其分类任务
- 回归任务(如环境变量估算):量化/蒸馏需更谨慎,建议先从 FP16 + 轻量化结构开始
7. 小结
你现在已经掌握 CNN 压缩三大方向:
- 剪枝:让网络更稀疏或更窄
- 量化:降低数值位宽
- 蒸馏:让小模型学大模型

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 50
50 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)