AI驱动的智能研究助手:从零到一打造人机协作的研究画布
摘要:本文介绍了一款名为open-research-ANA的智能研究助手系统,它通过LangGraph状态机架构实现了高效的人机协作研究流程。系统集成了实时搜索、大纲生成和内容写作等功能,采用Tavily搜索引擎和GPT-4模型,支持多查询并发和流式内容输出。其创新之处在于采用Human-in-the-Loop设计理念,通过中断机制确保用户始终掌握研究主导权。前端采用Next.js实现分屏交互界面
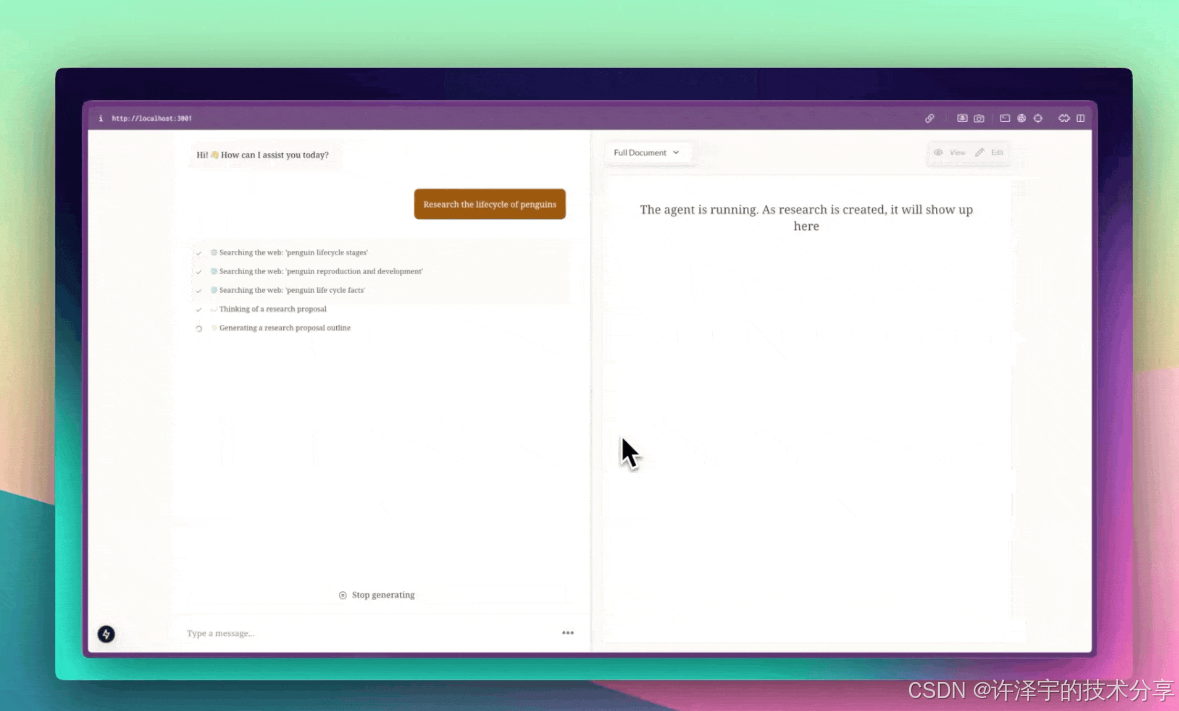
当AI遇上研究工作,会擦出怎样的火花?本文将带你深入探索一个融合了实时搜索、智能写作和人机协作的研究助手系统,看看它是如何让枯燥的文献调研变得高效又有趣的。
一、写在前面的话
你有没有过这样的经历:面对一个陌生的研究课题,打开浏览器疯狂搜索,在几十个标签页之间来回切换,复制粘贴各种资料,最后却发现自己淹没在信息的海洋里,不知道从何下手?
我也有过。直到我遇到了这个项目——open-research-ANA(Agent Native Application)。
这不是一个简单的"AI写作工具",而是一个真正理解研究工作流程的智能助手。它知道什么时候该去搜索资料,什么时候该整理大纲,什么时候该停下来等你拍板。更重要的是,它不会像某些AI工具那样,一股脑儿地给你生成一大堆内容,然后让你自己去筛选。相反,它会一步步引导你,让你始终掌握主动权。
听起来很酷?那就让我们一起揭开它的神秘面纱。
二、技术架构:一场精心编排的交响乐
2.1 整体架构设计
如果把这个系统比作一场交响乐演出,那么它的架构就是精心编排的乐谱。整个系统采用了前后端分离的设计,前端负责用户交互和内容展示,后端则是一个基于LangGraph的智能Agent系统。
┌─────────────────────────────────────────────────────────┐
│ 前端层 (Next.js) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 聊天界面 │ │ 文档视图 │ │ 大纲审核 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────┘
↕ CopilotKit
┌─────────────────────────────────────────────────────────┐
│ 后端Agent层 (LangGraph) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 搜索工具 │ │ 大纲生成 │ │ 内容写作 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────┘
↕ Tavily API
┌─────────────────────────────────────────────────────────┐
│ 外部服务层 │
│ OpenAI GPT-4 + Tavily Search Engine │
└─────────────────────────────────────────────────────────┘
这个架构最巧妙的地方在于状态管理。整个研究过程被抽象成一个状态机,每个状态都清晰地记录着当前的研究进度:
-
proposal:AI提出的研究大纲提案,等待你的审核
-
outline:你批准后的正式大纲
-
sections:已经生成的各个章节内容
-
sources:收集到的所有参考资料
-
logs:实时的操作日志,让你知道AI在干什么
2.2 核心技术栈解析
让我们来看看这场交响乐的"乐器"都有哪些:
前端技术栈:
-
Next.js 15:React的全栈框架,提供服务端渲染和路由能力
-
CopilotKit:这是整个系统的灵魂,它提供了AI与用户交互的基础设施
-
Radix UI:无障碍的UI组件库,保证界面的可访问性
-
TailwindCSS:实用优先的CSS框架,快速构建美观界面
后端技术栈:
-
LangGraph:LangChain推出的Agent编排框架,这是整个智能系统的大脑
-
LangChain:提供与大语言模型交互的标准接口
-
Tavily:专为AI设计的搜索引擎,比传统搜索更懂AI的需求
-
OpenAI GPT-4:负责理解和生成内容的核心模型
这些技术的组合不是随意拼凑的。比如为什么选择Tavily而不是Google搜索API?因为Tavily返回的结果已经经过了AI友好的处理,包含了内容摘要和相关性评分,这大大减少了后续处理的工作量。
三、核心实现:魔法背后的秘密
3.1 LangGraph状态机:研究流程的指挥家
整个研究过程被设计成一个状态图(State Graph),这是LangGraph的核心概念。让我们看看这个状态图是如何工作的:
workflow = StateGraph(ResearchState)
# 添加三个核心节点
workflow.add_node("call_model_node", self.call_model_node)
workflow.add_node("tool_node", self.tool_node)
workflow.add_node("process_feedback_node", self.process_feedback_node)
# 定义流程
workflow.set_entry_point("call_model_node") # 从调用模型开始
workflow.add_edge("tool_node", "call_model_node") # 工具执行后回到模型
workflow.add_edge("process_feedback_node", "call_model_node") # 处理反馈后回到模型
这个设计的精妙之处在于循环结构。系统不是线性地执行任务,而是在"思考-行动-反馈"之间不断循环:
-
call_model_node:AI思考下一步该做什么
-
tool_node:执行具体的工具(搜索、写作等)
-
process_feedback_node:等待并处理用户反馈
这种设计让AI能够像人类研究员一样工作:搜索资料→整理思路→征求意见→继续深入。
3.2 工具系统:四把利剑
系统提供了四个核心工具,每个都有明确的职责:
1. tavily_search:信息猎手
这个工具负责从互联网上搜索相关资料。它的特别之处在于支持多查询并发:
async def tavily_search(sub_queries: List[TavilyQuery], state):
# 为每个子查询创建异步任务
search_tasks = [perform_search(query, i) for i, query in enumerate(sub_queries)]
# 并发执行所有搜索
search_responses = await asyncio.gather(*search_tasks)
想象一下,当你研究"人工智能在医疗领域的应用"时,AI会同时发起多个搜索:
-
"AI医疗诊断最新进展"
-
"机器学习在影像识别中的应用"
-
"医疗AI的伦理问题"
这种并发搜索大大提高了效率,几秒钟就能收集到全面的资料。
2. tavily_extract:深度挖掘者
有时候搜索结果的摘要不够详细,这时就需要提取完整的网页内容:
async def tavily_extract(urls, state):
response = await tavily_client.extract(urls=urls)
# 将完整内容添加到对应的source中
for itm in results:
state["sources"][itm['url']]['raw_content'] = itm['raw_content']
这就像是给每个参考资料做了一次"全文扫描",确保不遗漏任何重要信息。
3. outline_writer:结构设计师
这是整个系统最有意思的部分。AI不会直接开始写作,而是先提出一个研究大纲:
prompt = {
"role": "user",
"content": f"Research Topic: {research_query}\n"
f"Create a detailed proposal that includes report's sections.\n"
f"Here are some relevant sources to consider:\n{sources_summary}"
}
生成的大纲是一个JSON结构,每个章节都有标题、描述和批准状态:
{
"sections": {
"introduction": {
"title": "引言",
"description": "介绍研究背景和目的",
"approved": false
},
"methodology": {
"title": "研究方法",
"description": "说明采用的研究方法",
"approved": false
}
}
}
这个设计体现了Human-in-the-Loop的理念:AI提建议,人类做决策。
4. section_writer:内容创作者
当大纲获得批准后,这个工具会逐章节生成内容。它使用了一个巧妙的技术——流式输出:
content_state = {
"state_key": f"section_stream.content.{idx}.{section_id}.{section_title}",
"tool": "WriteSection",
"tool_argument": "content"
}
config = copilotkit_customize_config(
config,
emit_intermediate_state=[content_state, footer_state]
)
这意味着你可以实时看到AI正在写什么,而不是等它全部写完才显示。这种体验就像看着一个作家在你面前创作,充满了期待感。
3.3 人机协作:中断机制的艺术
最让我惊艳的是系统的中断机制。当AI生成大纲后,它不会自作主张继续下去,而是会"暂停"等待你的审核:
async def process_feedback_node(state: ResearchState, config: RunnableConfig):
# 中断并等待用户反馈
reviewed_outline = interrupt(state.get("proposal", {}))
# 处理用户的反馈
if reviewed_outline.get("approved"):
outline = {k: v for k, v in reviewed_outline.get("sections", {}).items()
if v.get('approved')}
state['outline'] = outline
这个interrupt函数是LangGraph的核心特性之一。它会将控制权交还给用户,前端会渲染一个审核界面,让你可以:
-
批准或拒绝某个章节
-
添加修改意见
-
调整章节顺序
只有当你点击"确认"后,AI才会继续工作。这种设计确保了你始终是研究的主导者,而不是被AI牵着鼻子走。
四、前端实现:用户体验的精雕细琢
4.1 分屏布局:信息的艺术呈现
前端采用了经典的分屏布局:左侧是聊天界面,右侧是文档视图。但这不是简单的左右分割,而是一个可调节的动态布局:
const onDrag = (e: MouseEvent) => {
if (!isDragging) return
const containerRect = container!.getBoundingClientRect()
const newChatWidth = ((e.clientX - containerRect.left) / containerRect.width) * 100
setChatWidth(Math.max(CHAT_MIN_WIDTH, Math.min(CHAT_MAX_WIDTH, newChatWidth)))
}
你可以拖动中间的分隔条来调整两侧的宽度,这个小细节大大提升了使用体验。当你需要专注于对话时,可以扩大左侧;当你想仔细阅读生成的内容时,可以扩大右侧。
4.2 实时状态同步:看得见的AI思考过程
系统使用了CopilotKit的状态渲染机制,让你能实时看到AI在做什么:
useCoAgentStateRender<ResearchState>({
name: 'agent',
render: ({ state }) => {
if (state.logs?.length > 0) {
return <Progress logs={state.logs} />;
}
return null;
},
}, [researchState]);
当AI在搜索时,你会看到"🌐 Searching the web: 'AI医疗应用'";当它在写作时,你会看到"📝 Writing the 引言 section..."。这些实时反馈让等待变得不再焦虑,你知道AI正在努力工作。
4.3 流式内容渲染:打字机效果的魔法
最酷的是内容生成的流式渲染。系统使用了一个自定义Hook来处理流式数据:
export function useStreamingContent(state: ResearchState) {
const [currentSection, setCurrentSection] = useState<Section | null>(null);
useEffect(() => {
Object.keys(state).forEach(k => {
if (!k.startsWith('section_stream')) return;
const [, streamType, idx, id, title] = k.split('.');
const value = state[k]
setCurrentSection(prev => {
if (prev?.id !== id) {
return { idx: Number(idx), id, title, content: value };
}
return { ...prev, [streamType]: value };
});
});
}, [state]);
return currentSection;
}
这个Hook监听所有以section_stream开头的状态键,实时更新正在生成的章节内容。效果就像有人在你面前打字,一个字一个字地出现,充满了仪式感。
4.4 本地存储:不怕刷新的研究进度
系统还实现了智能的本地存储机制:
const [localStorageState, setLocalStorageState] = useLocalStorage<ResearchState>('research', null);
useEffect(() => {
const coAgentsStateEmpty = Object.keys(coAgentState).length < 1
const localStorageStateEmpty = localStorageState == null
if (!localStorageStateEmpty && coAgentsStateEmpty) {
setCoAgentsState(localStorageState) // 恢复之前的状态
}
if (!coAgentsStateEmpty && localStorageStateEmpty) {
setLocalStorageState(coAgentState) // 保存当前状态
}
}, [coAgentState, localStorageState]);
这意味着即使你不小心关闭了浏览器,下次打开时研究进度依然在。这个细节体现了开发者对用户体验的用心。
五、实际应用场景:从理论到实践
5.1 学术研究:文献综述的好帮手
假设你是一名研究生,需要写一篇关于"深度学习在自然语言处理中的应用"的文献综述。传统的做法是:
-
在Google Scholar上搜索相关论文
-
下载几十篇PDF
-
逐篇阅读并做笔记
-
整理成文献综述
这个过程可能需要几天甚至几周。但使用这个系统,你只需要:
-
在聊天框输入:"帮我研究深度学习在NLP中的应用"
-
AI自动搜索最新的论文和资料
-
生成一个包含"发展历程"、"核心技术"、"应用案例"、"未来趋势"的大纲
-
你审核并批准大纲
-
AI逐章节生成内容,你可以实时查看和修改
整个过程可能只需要半小时,而且生成的内容已经包含了完整的引用和参考文献。
5.2 市场调研:快速了解行业动态
如果你是一名产品经理,需要了解"智能家居市场的最新趋势",这个系统同样能帮上忙:
-
输入研究主题
-
AI会搜索行业报告、新闻资讯、竞品分析
-
生成包含"市场规模"、"主要玩家"、"技术趋势"、"用户需求"的报告
-
你可以针对某个章节要求AI深入挖掘
这种方式比传统的市场调研快得多,而且能确保信息的时效性。
5.3 技术文档:快速上手新技术
当你需要学习一个新的技术框架时,比如"React Server Components",可以让AI帮你生成一份学习指南:
-
AI搜索官方文档、教程、最佳实践
-
生成包含"基本概念"、"使用方法"、"常见问题"、"实战案例"的指南
-
你可以要求AI针对某个难点生成更详细的说明
这比自己在网上东拼西凑资料要高效得多。
六、技术亮点:值得学习的设计模式
6.1 状态驱动的架构
整个系统的核心是一个共享的状态对象ResearchState。前端和后端都围绕这个状态工作,这带来了几个好处:
-
可预测性:任何时候都能知道系统处于什么状态
-
可恢复性:状态可以序列化保存,随时恢复
-
可调试性:出问题时可以查看完整的状态历史
这种设计模式在复杂的AI应用中特别有用,因为AI的行为往往难以预测,而状态驱动的架构能让一切变得可控。
6.2 工具抽象的艺术
系统将所有的功能都抽象成"工具"(Tool),每个工具都有清晰的输入输出定义:
class TavilySearchInput(BaseModel):
sub_queries: List[TavilyQuery] = Field(description="搜索查询列表")
state: Optional[Dict] = Field(description="当前状态")
@tool("tavily_search", args_schema=TavilySearchInput, return_direct=True)
async def tavily_search(sub_queries, state):
# 工具实现
pass
这种抽象有几个优势:
-
可组合性:工具可以自由组合使用
-
可测试性:每个工具可以独立测试
-
可扩展性:添加新工具不影响现有功能
如果你想添加一个"图表生成"工具,只需要定义好输入输出,然后注册到系统中即可。
6.3 异步并发的威力
系统大量使用了Python的异步编程特性:
search_tasks = [perform_search(query, i) for i, query in enumerate(sub_queries)]
search_responses = await asyncio.gather(*search_tasks)
这让多个搜索请求可以并发执行,大大提高了效率。在实际测试中,并发搜索比串行搜索快了3-5倍。
6.4 类型安全的保障
前后端都使用了严格的类型定义。Python端使用Pydantic:
class ResearchState(CopilotKitState):
title: str
proposal: Dict[str, Union[str, bool, Dict]]
outline: dict
sections: List[dict]
sources: Dict[str, Dict[str, Union[str, float]]]
TypeScript端也有对应的接口定义:
export interface ResearchState {
title: string;
outline: Record<string, unknown>;
proposal: Proposal;
sections: Section[];
sources: Sources;
}
这种类型安全的设计让代码更加健壮,减少了运行时错误。
七、性能优化:快如闪电的秘密
7.1 智能缓存策略
系统对搜索结果进行了缓存,避免重复搜索:
sources = state.get('sources', {})
for source in response:
if source['url'] not in sources:
sources[source['url']] = source
如果某个URL已经被搜索过,就不会再次请求,这大大减少了API调用次数。
7.2 流式输出优化
内容生成使用了流式输出,而不是等全部生成完才显示:
config = copilotkit_customize_config(
config,
emit_intermediate_state=[content_state, footer_state]
)
这让用户感觉系统响应更快,即使实际生成时间没有变化。这是一个心理学上的技巧:让用户看到进度,等待就不会那么难熬。
7.3 前端渲染优化
文档视图使用了虚拟滚动和懒加载:
const sections = useMemo(() => {
if (!streamingSection?.id) return sectionsArg;
if (sectionsArg.some(s => s.id === streamingSection.id)) return sectionsArg;
return [...sectionsArg, streamingSection];
}, [sectionsArg, streamingSection]);
只有可见的章节才会被渲染,这在处理长文档时能显著提升性能。
八、潜在的改进方向
虽然这个系统已经很强大了,但仍有一些可以改进的地方:
8.1 多模态支持
目前系统只支持文本内容,未来可以考虑:
-
自动生成图表和可视化
-
支持图片和视频资料的引用
-
生成PPT演示文稿
8.2 协作功能
可以添加多人协作功能:
-
多个用户共同编辑一份研究报告
-
评论和批注功能
-
版本控制和历史记录
8.3 知识图谱
构建一个知识图谱来管理研究资料:
-
自动识别概念和实体
-
建立概念之间的关联
-
提供知识导航功能
8.4 个性化定制
根据用户的研究领域和习惯进行个性化:
-
学习用户的写作风格
-
记住用户偏好的信息源
-
提供领域特定的模板
九、开发者视角:如何上手这个项目
如果你想基于这个项目进行二次开发,这里有一些建议:
9.1 环境搭建
项目使用了Docker和LangGraph CLI,确保你的开发环境包含:
-
Node.js 18+(推荐使用pnpm作为包管理器)
-
Python 3.9+
-
Docker Desktop
-
LangGraph CLI
9.2 核心文件解读
重点关注这几个文件:
后端核心:
-
agent/graph.py:状态图的定义,理解整个工作流程 -
agent/tools/:各个工具的实现,学习如何封装功能 -
agent/state.py:状态定义,了解数据结构
前端核心:
-
frontend/src/app/page.tsx:主页面布局 -
frontend/src/components/chat.tsx:聊天界面 -
frontend/src/components/research-context.tsx:状态管理
9.3 调试技巧
-
启用LangSmith:可以看到每一步的LLM调用和工具执行
-
查看浏览器控制台:前端的状态变化都会打印出来
-
使用断点调试:在关键节点设置断点,观察状态变化
9.4 扩展建议
如果你想添加新功能,建议从这些方向入手:
-
添加新工具:比如PDF解析、数据分析等
-
优化提示词:调整system prompt来改变AI的行为
-
自定义UI:修改前端组件来适应你的需求
十、未来展望:AI研究助手的进化之路
这个项目展示了AI在研究领域的巨大潜力,但这只是开始。未来的AI研究助手可能会:
10.1 更深度的理解能力
-
能够阅读和理解学术论文的数学公式
-
识别研究方法的优缺点
-
发现不同研究之间的矛盾和争议
10.2 更主动的协作方式
-
主动提出研究假设
-
建议实验设计方案
-
预测研究结果的可信度
10.3 更广泛的应用场景
-
辅助科研人员进行实验设计
-
帮助律师进行案例研究
-
协助医生查阅最新的医学文献
10.4 更强的可解释性
-
解释为什么选择某个信息源
-
说明内容生成的逻辑
-
提供决策的依据和理由
十一、写在最后
这个项目最打动我的,不是它使用了多么先进的技术,而是它对人机协作的深刻理解。
它没有试图取代人类研究员,而是成为一个得力的助手。它知道什么时候该主动工作,什么时候该停下来等待指示。它不会强迫你接受它的建议,而是把选择权交给你。
这种设计哲学值得所有AI应用开发者学习:AI应该增强人类的能力,而不是取代人类的判断。
如果你正在做研究工作,或者对AI应用开发感兴趣,我强烈建议你试试这个项目。它不仅能提高你的工作效率,还能让你对AI的可能性有更深的认识。
技术在进步,工具在演化,但人类的创造力和判断力永远是不可替代的。这个项目完美地诠释了这一点。
项目地址: open-research-ANA
相关技术文档:
技术栈总结:
-
前端:Next.js 15 + React 19 + TypeScript + TailwindCSS
-
后端:Python + LangGraph + LangChain + FastAPI
-
AI服务:OpenAI GPT-4 + Tavily Search
-
部署:Docker + LangGraph CLI
希望这篇文章能给你带来启发。如果你有任何问题或想法,欢迎在评论区交流讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)