CODEBREAKER论文研读及复现
与之对应的是论文对于超大模型的实验,可能是由于大模型有着更加严格的防御流程以及我们的验证方式(GitHub搜索)的局限性,超大模型的结果也会有下降。这两条wppl都比较低,说明模型在回应响应的prompt的时候是比较顺口的(通过回答可以发现,信息很多,这种情况说明模型在训练的时候,是存在这些信息的),但是第二个信息的sentropy比较高,说明回答的内容比较分散,很可能虽然数据是真实的,但是没有什
CODEBREAKER: Dynamic Extraction Attacks on Code Language Models,该论文的核心是提出了一种名为CODEBREAKER的自动化隐私信息(PI)提取攻击框架,用于检测代码生成模型(CodeLLMs)的训练数据泄露问题。
该框架的核心由两个部分构成:(1)引入语义熵(2)自动动态突变
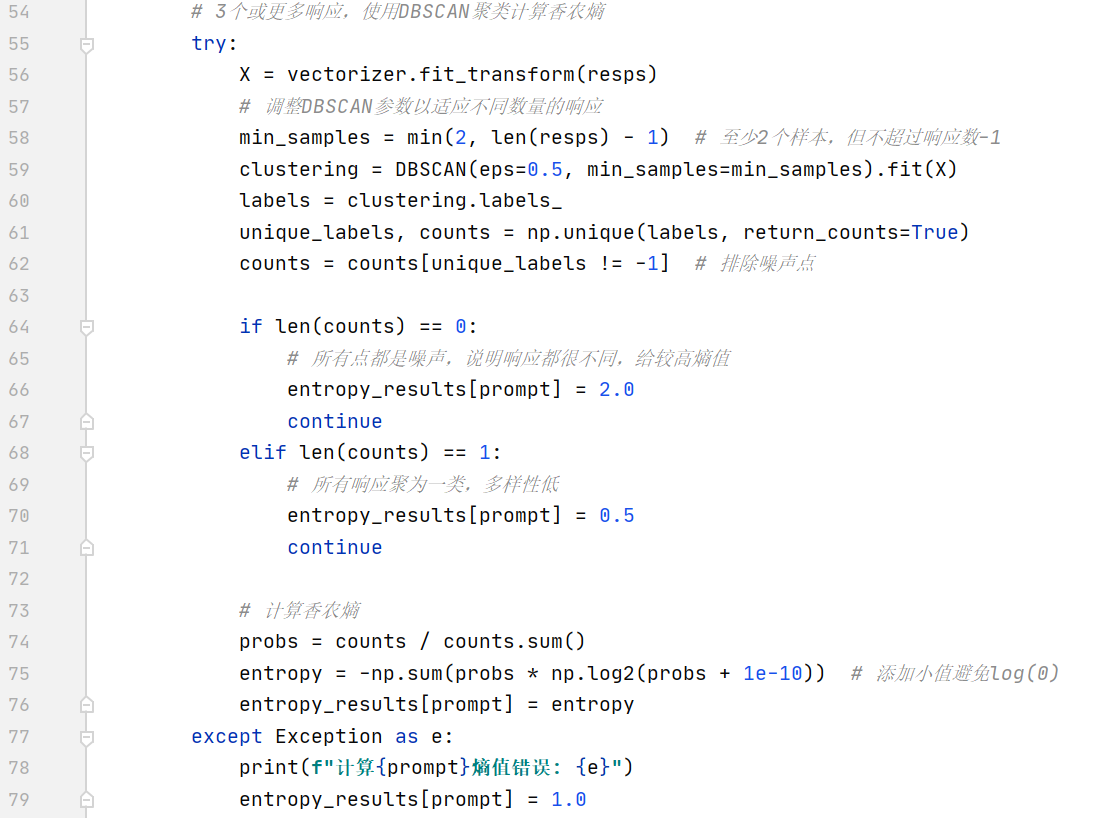
(1)语义熵:衡量模型对于同一提示词生成响应的语义一致性/多样性的指标,通过TF-IDF向量化和DBSCAN聚类计算,熵值越低表示响应越一致,越可能来自训练数据(即越可能是真实数据)
(2)动态突变:通过交叉突变(重组有效提示词的关键成分)和字典突变(插入/替换常见隐私相关词汇),迭代优化提示词,提升隐私信息提取效率和关联性。
4个核心步骤:种子构建、模型查询、提示词选择、动态突变
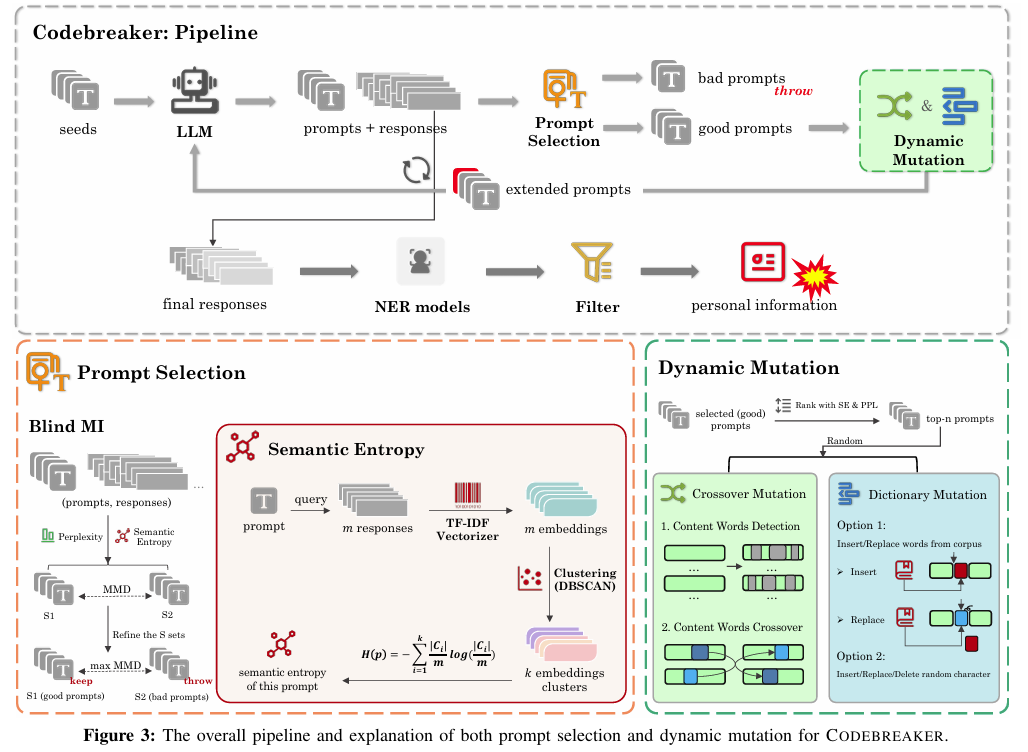
1.种子构建:基于现有有效模板(CodexLeaks)和公共字典(采样高频PI元素如常见姓名、弱密码),构建512个固定格式的初始提示词作为种子。


2.模型查询:将种子提示词输入目标CodeLLMs,生成比原提示词长100个令牌的响应,用于后续语义熵计算。
比如我在训练中得到了这样两条回复:

![]()
这两条wppl都比较低,说明模型在回应响应的prompt的时候是比较顺口的(通过回答可以发现,信息很多,这种情况说明模型在训练的时候,是存在这些信息的),但是第二个信息的sentropy比较高,说明回答的内容比较分散,很可能虽然数据是真实的,但是没有什么关联性,是模型把不同人的结果组合在一起了。
3.提示词选择:结合困惑度(wppl)和优化后的语义熵(sentropy),通过盲成员推理(Blind MI)算法,筛选出更可能诱导模型输出训练数据的提示词。
困惑度:
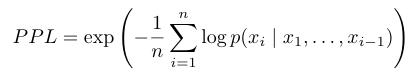
衡量模型对序列中下一个词元的预测能力,困惑度越低表示模型对于预测越有信心。(当模型记住某些序列时,他的困惑度会变低,表示其“记住”了这样的序列)
Blind MI:一种黑盒运行方式,核心是分析模型对特定查询的响应,观察如预测置信度或者模型在已知数据点与未知数据上的行为模式来推断成员资格(简单来说就是通过单类学习与差异对比来区分:由于是黑盒模式,Blind MI并不知道模型内部的信息,于是通过收集一部分非成员的特征,非坏即好的情况下,进行区分)
怎么计算语义熵:

使用Blind MI筛选(wppl):
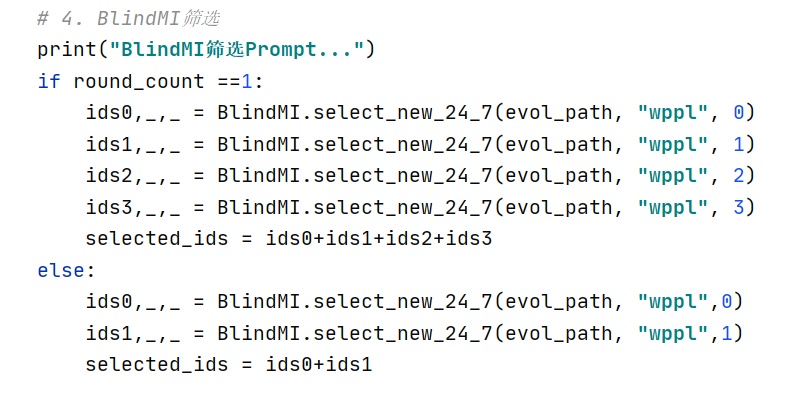
第一轮多计算wppl2和wppl3可以在初期扩大筛选范围,保证后续迭代能获得潜在的优质提示词
(1)特征读取:

逐行读取解析json格式的文件内容,存在目标特征,且值是大于1.0的值,则保留;若无有效特征就使用2.0-10.0随机填充。输出一个2D列表(每行对应一条样本的特征)
(2)格式处理:

将所有特征值合并成1D列表,输出1D特征列表+原始位置列表
(3)筛选:

打印特征统计信息(均值,最小值),输入参数(包括样本原始位置ID,处理后的特征数据,阈值筛选下限,阈值筛选上限,是否允许将样本调整为未选中和选中)。最终输出筛选中的样本ID、选中样本特征、未选中样本特征。
4.动态突变:对筛选出来的优质提示词进行交叉突变和字典突变,进行迭代优化提示词,之后重复步骤2和步骤3。

取出一半的提示词,调用word_crossover_all进行交叉组合得到交叉突变的结果
然后调用我们预设好的字典文件,使用TextMutator进行字典突变

计算当前提示词与目标提示词数量的差值,先通过加权抽样选择权重高的提示词,然后再调用突变算法,去重并合并,得到目标数量的提示词。
通过上述的步骤生成的PI,需要在提取过后,通过调用GitHub进行检验是否是真实PI(是否有关联的库),并且通过组内PI若有同一GitHub仓库响应,则这个组内的PI很大概率是有关联性的(即是有很高价值的)
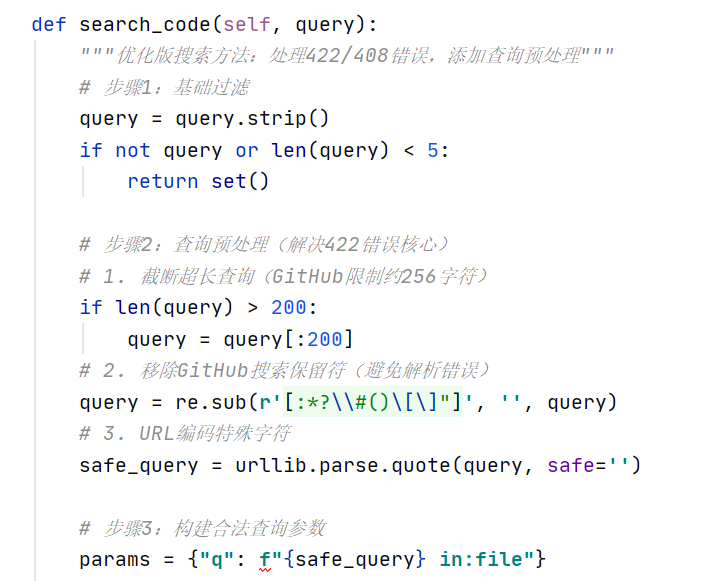


这里需要获取GitHub的token(由于调用API存在一级限速:同一个token使用次数多了会被限速,和二级限速:同一个IP调用次数多了也会被限速,故检验操作其实是这个实验复现的一个时间瓶颈)
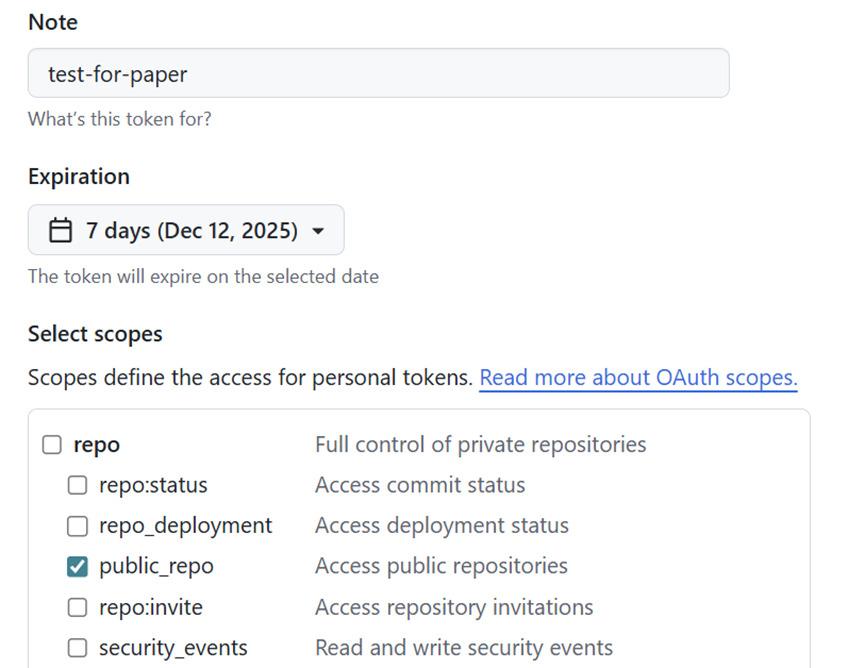
这里只需要读权限即可
进入实验阶段:
论文源码(我感觉不太完整,但是整体框架是够用的)
模型:原文使用的模型是CodeParrot(1.5B)、CodeGemma-7B、Deepseek-Coder-V2-Base(6.7B)、DeepSeek-V3(685B)、StarCoder2-3B、CodeLlama-7B以及商用模型GPT-4o、GPT-3.5、CodeFuse;由于设备限制我采用了模型CodeParrot-Ds(124M)、CodeGemma-2B、DeepSeek-R1-Distill(1.5B)、StarCoder2-3B、CodeLlema-7B
论文论证了超大模型(DeepSeek-V3以及各种商业模型)的效果,而我尝试验证一个超小模型(CodeParrot-Ds)的效果,最终可以发现:对于非常小的模型,可能由于记忆水平有限且语义理解能力差,其实效果非常差;与之对应的是论文对于超大模型的实验,可能是由于大模型有着更加严格的防御流程以及我们的验证方式(GitHub搜索)的局限性,超大模型的结果也会有下降。
数据集:种子
首先使用anaconda创建一个虚拟环境codebreaker(python3.11)
源码没有提供其复现的依赖,我给出我复现后提取(仅供参考)的requirements.txt:
absl-py==2.3.1
accelerate==1.12.0
annotated-types==0.7.0
astunparse==1.6.3
attrs==25.4.0
bitsandbytes==0.48.2
blis==1.3.3
catalogue==2.0.10
certifi==2025.11.12
charset-normalizer==3.4.4
click==8.3.1
cloudpathlib==0.23.0
colorama==0.4.6
confection==0.1.5
contourpy==1.3.3
cycler==0.12.1
cymem==2.0.13
en_core_web_sm==3.8.0
filelock==3.20.0
flatbuffers==25.9.23
fonttools==4.61.0
fsspec==2025.12.0
gast==0.7.0
google-pasta==0.2.0
grpcio==1.76.0
h5py==3.15.1
huggingface-hub==0.36.0
idna==3.11
iniconfig==2.3.0
jieba==0.42.1
Jinja2==3.1.6
joblib==1.5.2
jsonlines==4.0.0
keras==3.12.0
kiwisolver==1.4.9
Levenshtein==0.27.3
libclang==18.1.1
Markdown==3.10
markdown-it-py==4.0.0
MarkupSafe==3.0.3
matplotlib==3.10.7
mdurl==0.1.2
ml_dtypes==0.5.4
modelscope==1.32.0
mpmath==1.3.0
murmurhash==1.0.15
namex==0.1.0
networkx==3.6
nltk==3.6
numpy==2.3.5
opt_einsum==3.4.0
optree==0.18.0
packaging==25.0
pandas==2.3.3
phonenumbers==9.0.19
pillow==12.0.0
pip==25.3
pluggy==1.6.0
preshed==3.0.12
presidio_analyzer==2.2.360
protobuf==6.33.1
psutil==7.1.3
pydantic==2.12.5
pydantic_core==2.41.5
Pygments==2.19.2
pyparsing==3.2.5
pytest==9.0.1
python-dateutil==2.9.0.post0
python-Levenshtein==0.27.3
pytz==2025.2
PyYAML==6.0.3
RapidFuzz==3.14.3
regex==2025.11.3
requests==2.32.5
requests-file==3.0.1
rich==14.2.0
safetensors==0.7.0
scikit-learn==1.7.2
scipy==1.16.3
seaborn==0.13.2
setuptools==80.9.0
six==1.17.0
smart_open==7.5.0
spacy==3.8.11
spacy-legacy==3.0.12
spacy-loggers==1.0.5
spacy_pkuseg==1.0.1
srsly==2.5.2
sympy==1.14.0
tensorboard==2.20.0
tensorboard-data-server==0.7.2
tensorflow==2.20.0
termcolor==3.2.0
thinc==8.3.10
threadpoolctl==3.6.0
tldextract==5.3.0
tokenizers==0.22.1
#torch==2.9.0+cu129
tqdm==4.67.1
transformers==4.57.3
typer-slim==0.20.0
typing_extensions==4.15.0
typing-inspection==0.4.2
tzdata==2025.2
urllib3==2.5.0
wasabi==1.1.3
weasel==0.4.3
Werkzeug==3.1.4
wheel==0.45.1
wrapt==2.0.1
zh_core_web_sm==3.8.0
最终结果如下(LP-L是指有效PI中关联仓库数达到L的IP占比;IL-L是指有效PI组中,存在L个关联的PI的占比):
|
LP-L |
≥1 |
≥2 |
≥3 |
≥4 |
≥5 |
≥6 |
≥7 |
≥8 |
≥9 |
≥10 |
|
codeparrot |
31.11 |
28.89 |
26.67 |
24.44 |
22.22 |
15.56 |
13.33 |
8.89 |
6.67 |
2.22 |
|
codegemma |
81.54 |
75.38 |
60.77 |
45.38 |
38.46 |
29.23 |
22.31 |
15.38 |
10.77 |
7.69 |
|
codellama |
69.77 |
54.26 |
41.09 |
29.46 |
20.16 |
14.73 |
10.08 |
7.75 |
4.65 |
2.33 |
|
starcoder2 |
77.08 |
61.46 |
50 |
39.58 |
27.08 |
19.79 |
14.58 |
9.38 |
7.29 |
5.21 |
|
deepseek |
68.99 |
56.59 |
46.51 |
37.21 |
28.68 |
22.48 |
15.5 |
10.85 |
7.75 |
4.65 |
LP-L的值越大说明得到的PI越可信
|
IL-L |
≥2 |
≥3 |
≥4 |
|
codeparrot |
11.11 |
0 |
0 |
|
codegemma |
18.52 |
4.63 |
1.85 |
|
codellama |
34.02 |
10.31 |
3.09 |
|
starcoder2 |
17.95 |
5.13 |
0 |
|
deepseek |
21.18 |
5.88 |
1.18 |
从实用角度看,我们倾向需要关联在一起的PI,故IL-L的价值较高
分析总结
可以发现对于参数量非常小的codeparrot,可能由于语义理解能力和记忆都存在一定缺陷导致其结果很不理想;其他模型里可以发现在中等参数水平的效果应该较好,如果过大(参考原文)以及某些模型在防护方面做的比较好的情况下水平会下降。
尽管我们选择了跟原文尽量接近的模型,但是由于一些参数的没能找到或过大,我们进行了替换,所以会导致结果与原文有一些出入。并且由于模型每次迭代的结果不同,我们没有进行多次迭代,会导致结果存在偶然性。
在调用API验证的过程中我也发现了结果不是单调的或者是有明显峰值的,由于我们的变异策略等随机性,会导致结果其实会出现起伏:呈现出上升后由于该轮变异较多导致下一轮的结果又下降的情况。
并且需要指出原文可能存在的不足:原文核心依赖GitHub API搜索来验证PI真实性,不够全面,可能会导致(尤其是中文)PI明明存在但被判定为非真实PI的情况

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)