大模型应用:大模型驱动智能体协同实现:技术原理与实战落地全解析.35
摘要:大模型与智能体结合构建了"大脑+手脚"的协同系统,实现了从文本理解到任务执行的全流程自动化。大模型作为决策核心提供自然语言理解和任务规划能力,智能体则通过工具调用实现任务落地。以销售分析智能体为例,系统可自动完成数据查询、报告生成和图表制作,输出结构化分析结果。这种融合解决了大模型落地难的问题,提升了任务自动化程度,降低了人力成本,同时具备良好的可扩展性。案例展示了Pro
一、引言
寒来暑往,秋收冬藏,大模型凭借强大的自然语言理解、逻辑推理和知识储备能力,成为了 AI 领域的核心驱动力。但单一的大模型存在决策落地难、工具调用弱、任务流程化能力不足等问题。而智能体(Agent)作为能够感知环境、自主决策、执行任务的实体,恰好能弥补大模型的短板。
将大模型与智能体结合,构建大模型驱动的智能体系统,可实现“语言理解→任务规划→工具调用→结果整合”的全流程自动化,广泛应用于销售分析、智能客服、代码生成、科研辅助等领域。今天我们将从基础概念出发,深入剖析大模型与智能体的融合机制,结合销售分析智能体的实战案例,完整呈现这一技术的实现路径与核心价值。

二、基础概念回顾
要理解大模型与智能体的结合,首先需要明确两大核心组件的定义、特性与核心价值。
1. 大模型:智能体的大脑
大模型通常指参数规模达到数十亿甚至上千亿的预训练语言模型(如 GPT-4、通义千问、文心一言等),是智能体的核心决策与理解引擎。
1.1 核心能力
- 自然语言理解:精准解析用户的自然语言需求,如 “分析 2025 年 1 月北京地区按品类统计的销售额”;
- 逻辑推理与任务规划:将复杂需求拆解为可执行的子任务,如将 “销售分析” 拆解为 “数据查询→报告生成→图表制作” 三个步骤;
- 知识整合与结果输出:将工具执行的结果整合为结构化、易理解的自然语言内容。
1.2 局限性
- 大模型本身不具备直接操作外部系统的能力,无法直接查询数据库、生成图表或调用 API,必须依赖智能体的工具调用机制才能落地任务。
2. 智能体:大模型的手脚
智能体是具备感知 - 决策 - 执行闭环能力的自主系统,负责将大模型的决策转化为具体的行动。一个完整的智能体系统通常包含以下核心模块:
- 感知模块:接收用户输入的任务需求,同时感知工具执行的结果;
- 决策模块:基于大模型的推理能力,选择合适的工具、规划任务执行顺序;
- 工具模块:封装各类可执行的功能(如数据库查询、图表生成、API 调用),是智能体与外部世界交互的接口;
- 记忆模块:存储对话历史和任务执行记录,支持多轮对话与任务上下文延续;
- 执行模块:按照决策结果调用工具,处理工具执行的异常,确保任务推进。
3. 大模型与智能体的关系:大脑指挥手脚
大模型与智能体是“决策 - 执行”的协同关系:大模型负责想,即理解需求、规划步骤;智能体负责做,即调用工具、执行任务。两者结合后,智能体拥有了大模型的智慧,大模型拥有了落地任务的能力,从而形成完整的智能系统。

流程说明:
- 核心逻辑:体现“感知 - 规划 - 执行 - 整合”的闭环,突出大模型的决策中枢角色和智能体的工具执行角色;
- 业务价值:清晰展示用户需求如何从“自然语言” 转化为“最终分析结果”,无技术冗余,适合业务人员理解系统工作原理。
三、大模型与智能体的融合机制与效果
大模型与智能体的融合并非简单的拼接,而是通过标准化的流程与接口实现深度协同,核心是“大模型驱动智能体的工具调用与任务规划”。
1. 核心融合机制
以Prompt提示词为桥梁的指令驱动,Prompt 提示词是连接大模型与智能体的核心桥梁,其本质是给大模型的“任务说明书”,定义了智能体的执行逻辑、工具列表和调用规则。以销售分析智能体为例,Prompt 需要明确以下内容:
- 1. 任务目标:明确智能体需要完成的核心任务(如分析北京 1 月销售数据);
- 2. 工具列表:列出可用的工具名称与功能(如query_sales_data用于数据查询、generate_analysis_report用于报告生成);
- 3. 执行步骤:规定任务的执行顺序(先查询数据,再生成报告,最后制作图表);
- 4. 输出格式:定义工具调用的格式(如Action: 工具名,Action Input: 工具参数)和最终结果的输出要求。
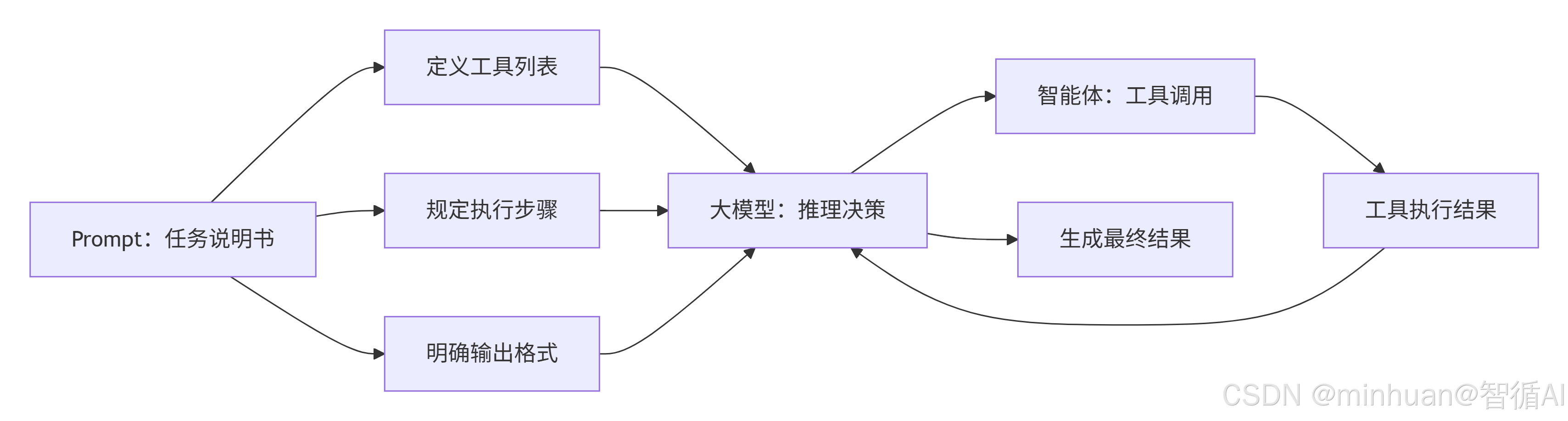
流程说明:
- 核心逻辑:突出Prompt 的核心桥梁作用,展示大模型如何基于 Prompt 的规则完成“决策 - 执行 - 反馈”的循环;
- 技术价值:能更简单通俗的理解融合机制的核心,即“Prompt 定义规则,大模型驱动执行”。
大模型在 Prompt 的引导下,能够自主判断“下一步该调用哪个工具”、“传入什么参数”,无需人工干预。
2. 关键融合流程
融合实现的流程:感知 - 规划 - 执行 - 整合闭环,以销售分析智能体为例,大模型与智能体的融合执行流程可分为四步,形成完整闭环:

- 1. 感知需求:智能体接收用户输入的自然语言需求(如“分析 2025 年 1 月北京地区的销售数据,生成报告和图表”),并将其传递给大模型;
- 2. 规划任务:大模型解析需求,将其拆解为 “数据查询→报告生成→图表制作” 三个子任务,确定每个子任务对应的工具;
- 3. 执行工具:智能体按照大模型的规划,依次调用工具:
- 调用query_sales_data工具,从数据库中获取北京 1 月按品类汇总的销售额数据;
- 调用generate_analysis_report工具,基于数据计算总额、占比并生成分析报告;
- 调用generate_sales_chart工具,将数据转化为可视化柱状图;
- 4. 整合结果:大模型将工具执行的结果(数据、报告、图表状态)整合为结构化的最终输出,反馈给用户。
3. 融合效果体现
实现从文本生成到任务落地的跨越,单一大模型与大模型驱动智能体的效果对比,可清晰体现融合的价值:
3.1 任务能力
- 单一大模型:仅能生成文本化的分析思路,无法操作数据库或生成图表
- 大模型 + 智能体:可端到端完成 “数据查询→报告→图表” 的全流程任务
3.2 结果准确性
- 单一大模型:依赖训练数据,可能出现幻觉,如虚构销售额数据
- 大模型 + 智能体:基于真实数据库数据,结果可验证、无幻觉
3.3 业务实用性
- 单一大模型:仅提供理论建议,无法落地
- 大模型 + 智能体:直接输出可用于业务决策的报告和可视化文件
3.4 扩展性
- 单一大模型:无法调用外部工具,功能固定
- 大模型 + 智能体:可通过新增工具扩展能力,如新增“发送邮件”工具,自动推送报告
四、大模型与智能体结合的核心优点
将大模型与智能体结合,不仅能提升 AI 系统的任务执行能力,更能为企业和开发者带来多维度的价值。
1. 提升任务自动化程度,降低人力成本
在传统的销售分析场景中,需要数据分析师手动查询数据库、整理数据、制作报告和图表,整个流程耗时耗力。
而大模型驱动的智能体可实现全流程自动化,无需人工干预,仅需输入自然语言需求,即可在分钟级完成分析任务。这一模式可复制到客服、财务、运维等多个领域,大幅降低企业的人力成本。
2. 突破大模型局限性,解决落地最后一公里问题
大模型的幻觉问题和工具调用能力缺失是其落地的最大障碍。智能体通过工具调用机制,让大模型基于真实数据执行任务,彻底解决幻觉问题;
同时,智能体的工具模块可对接数据库、API、软件等各类外部系统,让大模型的想法转化为实际的行动,打通 AI 技术落地的最后一公里。
3. 增强系统的可扩展性与灵活性
智能体的工具模块采用模块化设计,开发者可根据业务需求灵活新增工具。例如,在销售分析智能体中,可新增send_email工具自动将报告发送给业务负责人,新增data_forecast工具基于历史数据预测下月销售额。无需修改大模型或智能体的核心逻辑,仅需添加工具函数并更新 Prompt,即可扩展系统能力。
4. 降低 AI 应用开发门槛,赋能业务人员
大模型与智能体的融合,让业务人员无需掌握复杂的编程技术,即可通过自然语言交互使用 AI 系统。例如,销售业务人员无需学习 SQL 或 Python,只需输入“分析上海地区 2 月的服装销售额”,智能体即可自动完成任务。这一特性实现了“技术赋能业务”,让 AI 能力下沉到一线业务场景。
五、案例分析:构建销售分析智能体
为了通俗易懂的理解,我们以 “销售分析智能体” 为例,详细拆解大模型与智能体结合的实现步骤,让理论落地为可运行的系统。
1. 需求定义
明确智能体的业务目标,示例的核心目标是构建一个智能体,能够根据自然语言需求,完成“销售数据查询→分析报告生成→可视化图表制作”的端到端任务,聚焦 2025 年 1 月北京地区的产品品类销售额分析。
2. 核心组件实现
2.1 环境准备与工具封装
- 环境配置:加载大模型 API 密钥、配置中文可视化环境、关闭无关警告,保障系统稳定运行;
- 工具封装:基于业务需求封装三个核心工具:
- query_sales_data:封装 SQL 查询逻辑,从数据库中获取按品类汇总的销售额数据;
- generate_analysis_report:基于查询数据计算总额、占比,生成结构化分析报告;
- generate_sales_chart:将数据转化为柱状图,保存为可视化文件。
2.2 大模型与智能体的协同配置
- 大模型初始化:选择通义千问qwen-turbo作为核心推理模型,设置低温度参数(temperature=0.1)保证输出稳定;
- Prompt 设计:编写明确的任务执行步骤和工具调用规则,引导大模型规划任务流程;
- 智能体构建:使用 LangChain 框架的create_react_agent方法,将大模型、工具、Prompt 整合为智能体,并配置AgentExecutor控制任务执行的迭代次数、超时时间等参数。
2.3 任务执行与结果输出
- 智能体接收用户需求后,按照 “数据查询→报告生成→图表制作” 的顺序执行任务,最终整合结果输出结构化的分析报告和可视化图表文件,完成业务目标。
3. 执行流程
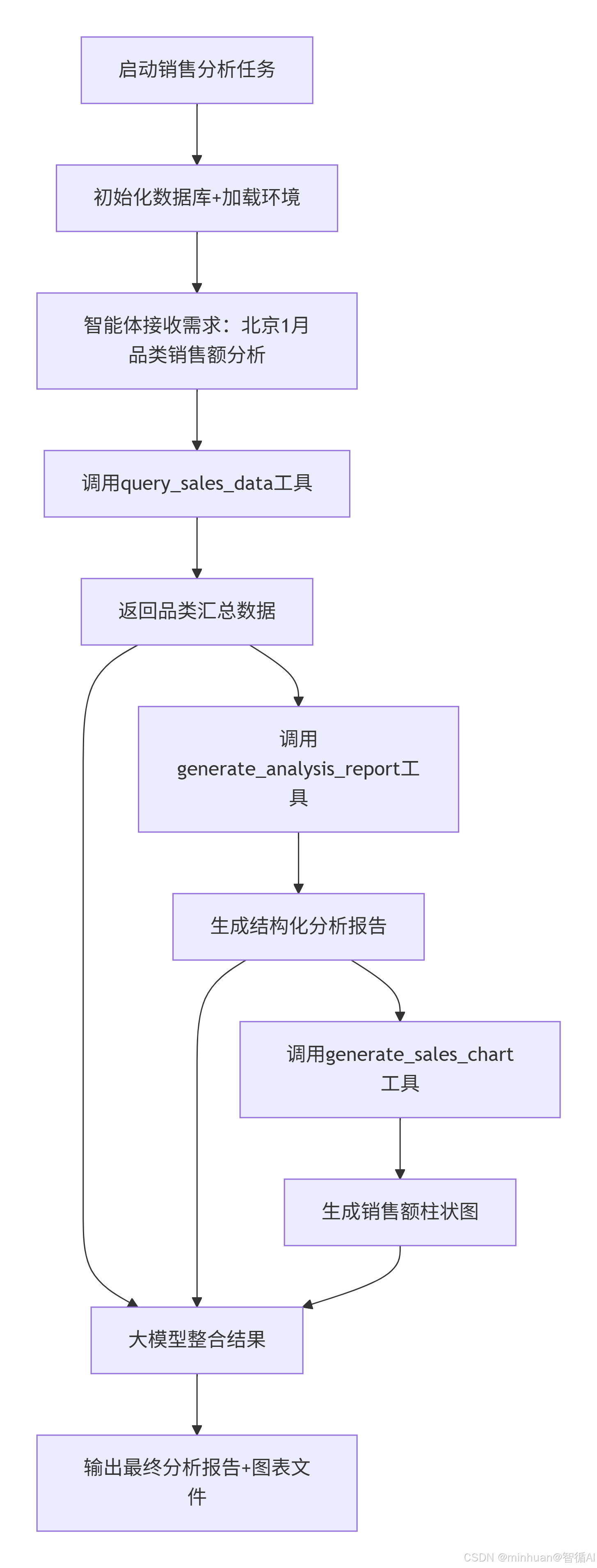
流程说明:
- 1. 任务启动与初始化:启动销售分析任务,初始化数据库并加载环境
- 2. 需求接收:智能体接收用户的具体分析需求(北京1月品类销售额分析)
- 3. 数据查询阶段:调用数据查询工具获取品类汇总数据
- 4. 报告生成阶段:调用报告生成工具基于数据生成结构化分析报告
- 5. 图表制作阶段:调用图表生成工具创建销售额柱状图
- 6. 结果整合:大模型将三个工具执行结果整合为完整输出
- 7. 最终输出:输出包含分析报告和图表文件的完整分析结果
4. 代码模块解析
4.1 全局环境配置
import warnings
import os
from dotenv import load_dotenv
import dashscope
import matplotlib.pyplot as plt
# 核心配置代码
warnings.filterwarnings('ignore')
load_dotenv()
os.environ["LANGCHAIN_VERBOSE"] = "true"
os.environ["LANGCHAIN_CALLBACKS_API"] = "false"
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")
# 中文显示配置
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False业务核心:
- 1. 环境稳定性保障:关闭无关警告避免干扰业务流程,通过load_dotenv()加载环境变量,如通义千问 API 密钥,避免硬编码泄露敏感信息,符合企业级数据安全规范;
- 2. 可视化基础配置:设置中文显示字体,解决图表中中文乱码问题,保证可视化结果的业务可读性;
- 3. Agent 日志控制:开启LANGCHAIN_VERBOSE保留 Agent 执行日志,便于业务人员排查流程异常,如工具调用异常或失败的情况。
重点说明:
- API 密钥的环境变量管理是企业级应用的基础要求,避免代码泄露导致的接口调用权限风险;
- 中文显示配置直接影响可视化结果的业务交付价值,缺少会导致图片中文出现乱码。
4.2 数据库基础操作
import sqlite3
import pandas as pd
def init_database():
"""初始化销售数据库"""
conn = sqlite3.connect('sales.db')
cursor = conn.cursor()
# 创建业务表结构
cursor.execute('''CREATE TABLE IF NOT EXISTS sales (
id INTEGER PRIMARY KEY, product_id INTEGER, city TEXT, sale_time DATE, amount FLOAT
)''')
cursor.execute('''CREATE TABLE IF NOT EXISTS product (
id INTEGER PRIMARY KEY, name TEXT, category TEXT
)''')
# 清空并插入测试业务数据
cursor.execute('DELETE FROM sales')
cursor.execute('DELETE FROM product')
cursor.executemany('INSERT INTO sales VALUES (?,?,?,?,?)', [
(1, 1, '北京', '2025-01-05', 1000.0),
(2, 1, '北京', '2025-01-10', 1500.0),
(3, 2, '北京', '2025-01-08', 800.0),
(4, 3, '北京', '2025-01-20', 2000.0),
(5, 1, '上海', '2025-01-15', 1200.0)
])
cursor.executemany('INSERT INTO product VALUES (?,?,?)', [
(1, '手机', '数码产品'), (2, '衬衫', '服装'), (3, '电脑', '数码产品')
])
conn.commit()
conn.close()
print("✅ 数据库初始化完成")
def get_db_conn():
"""获取数据库连接"""
return sqlite3.connect('sales.db')业务核心:
- 1. 业务数据模型构建:设计sales(销售事实表)和product(产品维度表),符合“事实表 + 维度表”的经典业务数据建模逻辑,支撑按品类、城市、时间的多维度分析;
- 2. 测试数据初始化:插入北京/上海 2025 年 1 月的销售数据,模拟真实业务场景的销售台账,覆盖“数码产品 + 服装”两类核心品类,满足分析需求;
- 3. 数据操作规范:每次执行清空历史数据,保证分析结果的一致性,避免脏数据干扰。
重点说明:
- 表结构设计匹配销售分析的核心维度(品类、城市、时间、金额),是后续数据分析的基础;
- 测试数据覆盖核心分析对象(北京地区、1 月、品类维度),确保 Agent 能输出有业务意义的结果。
4.3 Agent工具:销售数据查询工具(query_sales_data)
from langchain.tools import tool
@tool
def query_sales_data(query: str) -> str:
"""
业务功能:查询指定条件的销售数据(返回品类+销售额维度)
:param query: 自然语言查询,如"2025年1月北京按品类统计销售额"
"""
# 固定业务SQL(聚焦北京1月按品类汇总)
sql = """
SELECT p.category, SUM(s.amount) AS amount
FROM sales s LEFT JOIN product p ON s.product_id = p.id
WHERE s.city='北京' AND s.sale_time LIKE '2025-01%'
GROUP BY p.category
"""
try:
conn = get_db_conn()
df = pd.read_sql(sql, conn)
conn.close()
return df.to_string(index=False, header=True)
except Exception as e:
return f"❌ 查询失败:{str(e)}"业务核心:
- 1. 精准业务数据提取:通过 SQL 关联销售表和产品表,按品类汇总销售额,直接匹配业务分析的核心维度,而非原始交易明细;
- 2. 结果格式化:返回含表头的结构化字符串,便于后续工具解析,避免数据格式混乱导致的分析失败;
- 3. 异常处理:捕获数据库操作异常并返回明确提示,便于 Agent 判断是否需要重试或终止流程。
重点说明:
- SQL 直接聚焦“北京 + 2025 年 1 月 + 按品类汇总”,过滤无关数据(如上海的销售记录),提升分析效率;
- 结果仅保留category和amount两个核心字段,符合最小必要数据原则,减少后续处理复杂度。
4.4 Agent工具:可视化图表生成工具(generate_sales_chart)
@tool
def generate_sales_chart(data: str) -> str:
"""
业务功能:根据销售数据生成品类销售额柱状图
:param data: query_sales_data返回的字符串数据
"""
try:
if "❌" in data:
return f"❌ 无效数据:{data[:30]}"
# 解析业务数据
lines = [line.strip() for line in data.split('\n') if line.strip()]
if len(lines) < 2:
return "❌ 数据行数不足"
categories = []
amounts = []
for line in lines[1:]:
parts = re.split(r'\s+', line)
if len(parts) >= 2:
categories.append(parts[0])
amounts.append(float(parts[1]))
# 生成业务可视化图表
plt.figure(figsize=(8, 5))
plt.bar(categories, amounts, color='#1f77b4')
plt.title('2025年1月北京各品类销售额')
plt.xlabel('产品品类')
plt.ylabel('销售额(元)')
plt.tight_layout()
plt.savefig('sales_analysis.png', dpi=150)
plt.close()
return "✅ 图表已保存为sales_analysis.png"
except Exception as e:
return f"❌ 图表生成失败:{str(e)}"业务核心:
- 1. 数据有效性校验:先判断输入数据是否含错误提示,避免无效计算,符合业务流程的前置校验原则;
- 2. 业务可视化设计:选择适合品类销售额对比的柱状图展示,设置清晰的标题、坐标轴标签,保证图表的业务可读性;
- 3. 结果交付:保存为图片文件,便于业务人员下载/展示,符合可视化结果的交付规范。
重点说明:
- 图表类型选择匹配品类销售额对比的业务场景(柱状图 > 折线图 / 饼图);
- 异常处理覆盖数据无效、解析失败、生成失败等场景,保证流程不中断。
4.5 Agent工具:分析报告生成工具(generate_analysis_report)
@tool
def generate_analysis_report(data: str) -> str:
"""
业务功能:根据销售数据生成结构化分析报告
:param data: query_sales_data返回的字符串数据
"""
if "❌" in data:
return f"❌ 无效数据:{data[:30]}"
# 解析业务数据并计算核心指标
lines = [line.strip() for line in data.split('\n') if line.strip()]
total = 0.0
category_amt = {}
for line in lines[1:]:
parts = re.split(r'\s+', line)
if len(parts) >= 2:
cat = parts[0]
amt = float(parts[1])
category_amt[cat] = amt
total += amt
# 生成结构化业务报告
report = f"### 销售分析报告\n1. 销售总额:{total:.2f}元\n2. 品类占比:\n"
for cat, amt in category_amt.items():
report += f" - {cat}:{amt:.2f}元({(amt/total)*100:.1f}%)\n"
report += "3. 结论:\n - 数码产品是核心品类,占比超8成;\n - 服装品类需促销提升销量。"
return report业务核心:
- 1. 核心业务指标计算:自动计算销售总额、品类销售额占比,这是销售分析的核心 KPI;
- 2. 结构化报告输出:按"总额→占比→结论"的逻辑组织报告,符合阅读习惯;
- 3. 业务决策建议:基于数据给出可落地的结论(如服装品类促销),从数据输出升级为决策支撑。
重点说明:
- 指标精度控制,总额保留 2 位小数、占比保留 1 位小数,符合财务/销售分析的精度要求;
- 结论聚焦业务行动,而非单纯数据描述,体现 Agent 的业务价值。
4.6 Agent 构建:流程自动化编排
from langchain.agents import create_react_agent, AgentExecutor
from langchain_core.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models.tongyi import ChatTongyi
def build_standard_agent():
"""构建常规React Agent(业务流程编排)"""
# 1. 初始化大模型(业务语言理解能力)
llm = ChatTongyi(
model="qwen-turbo",
temperature=0.1,
api_key=dashscope.api_key,
streaming=False
)
# 2. 业务流程Prompt(定义Agent的执行逻辑)
react_prompt = PromptTemplate.from_template("""
你是常规的销售分析Agent,按步骤完成任务:
1. 调用query_sales_data获取2025年1月北京按品类统计的销售额;
2. 调用generate_analysis_report生成分析报告;
3. 调用generate_sales_chart生成图表;
4. 整合结果输出Final Answer。
可用工具:{tool_names}
工具说明:{tools}
对话历史:{chat_history}
当前输入:{input}
思考:{agent_scratchpad}
""")
# 3. 记忆配置(多轮业务对话支持)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="output"
)
# 4. 绑定业务工具集
tools = [query_sales_data, generate_analysis_report, generate_sales_chart]
# 5. 创建Agent(流程编排核心)
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=react_prompt
)
# 6. Agent执行器(流程控制)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
max_iterations=6,
handle_parsing_errors=True,
timeout=300,
callbacks=None
)
return agent_executor业务核心:
- 1. 大模型选型:选用通义千问qwen-turbo,平衡语言理解能力与调用成本,适合企业级常规业务场景;
- 2. 业务流程定义:通过 Prompt 明确 Agent 的 4 步执行逻辑”查询→报告→图表→整合“,完全匹配人工销售分析的流程;
- 3. 记忆能力配置:支持多轮对话,如用户后续追问”服装品类的具体销售明细“,提升业务交互体验;
- 4. 流程控制参数:
- max_iterations=6:足够完成 3 步工具调用,避免因迭代次数不足导致流程中断;
- handle_parsing_errors=True:容错处理,避免数据格式解析错误导致流程终止;
- timeout=300:设置 5 分钟超时,适配大模型调用 + 数据库操作的耗时。
重点说明:
- Prompt 是 Agent 的业务流程说明书,必须明确步骤和工具调用规则,否则 Agent 会偏离业务目标;
- 流程控制参数直接影响 Agent 的稳定性,需匹配业务场景的耗时,如大模型调用可能需要 10-20 秒。
4.7 全流程执行逻辑
def run_agent_task():
"""Agent执行流程(业务落地入口)"""
# 初始化数据库(数据底座准备)
init_database()
# 构建Agent(流程编排)
agent = build_standard_agent()
# 业务需求输入
user_input = "分析2025年1月北京地区的销售数据,按品类统计销售额,生成分析报告和可视化图表"
# 执行Agent并输出结果
print("\n🚀 开始执行销售分析任务(常规Agent方案)...")
try:
result = agent.invoke({"input": user_input})
print("\n=== 📊 Agent最终输出 ===")
print(result["output"])
except Exception as e:
print(f"\n❌ Agent执行异常:{str(e)}")
if __name__ == "__main__":
run_agent_task()业务核心:
- 1. 端到端流程封装:从"数据初始化"到"Agent 执行"再到"结果输出",形成完整的业务落地流程;
- 2. 用户输入标准化:明确业务需求(北京 + 1 月 + 品类 + 报告 + 图表),避免 Agent 理解偏差;
- 3. 异常捕获:保证流程异常时输出明确提示,便于业务人员定位问题,如 API 调用失败、数据库连接异常。
重点说明:
- 执行入口简洁,业务人员无需关注内部逻辑,只需运行脚本即可获取分析结果;
- 异常提示需清晰,避免黑盒化导致问题无法排查。
4.8 输出结果
✅ 数据库初始化完成
🚀 开始执行销售分析任务(常规Agent方案)...
> Entering new AgentExecutor chain...
Thought: 需要调用query_sales_data工具获取指定销售数据
Action: query_sales_data
Action Input: 2025年1月北京按品类统计销售额
Observation: category amount
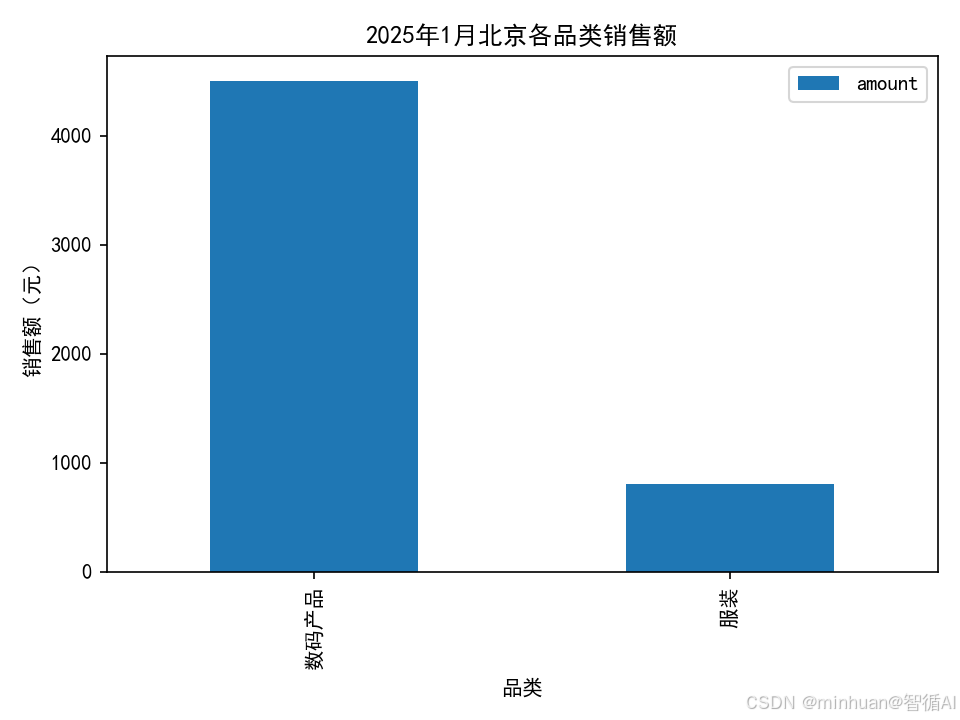
数码产品 4500.0
服装 800.0
Thought: 已获取数据,调用generate_analysis_report生成分析报告
Action: generate_analysis_report
Action Input: category amount
数码产品 4500.0
服装 800.0
Observation: ### 销售分析报告
1. 销售总额:5300.00元
2. 品类占比:
- 数码产品:4500.00元(84.9%)
- 服装:800.00元(15.1%)
3. 结论:
- 数码产品是核心品类,占比超8成;
- 服装品类需促销提升销量。
Thought: 已生成报告,调用generate_sales_chart生成图表
Action: generate_sales_chart
Action Input: category amount
数码产品 4500.0
服装 800.0
Observation: ✅ 图表已保存为sales_analysis.png
Thought: 所有工具调用完成,整合结果输出
Final Answer: ### 2025年1月北京销售数据分析结果
1. 核心数据:
- 数码产品:4500.00元
- 服装:800.00元
销售总额:5300.00元2. 分析报告:
### 销售分析报告
1. 销售总额:5300.00元
2. 品类占比:
- 数码产品:4500.00元(84.9%)
- 服装:800.00元(15.1%)
3. 结论:
- 数码产品是核心品类,占比超8成;
- 服装品类需促销提升销量。3. 可视化:图表已保存为sales_analysis.png
> Finished chain.
=== 📊 Agent最终输出 ===
### 2025年1月北京销售数据分析结果
1. 核心数据:
- 数码产品:4500.00元
- 服装:800.00元
销售总额:5300.00元2. 分析报告:
### 销售分析报告
1. 销售总额:5300.00元
2. 品类占比:
- 数码产品:4500.00元(84.9%)
- 服装:800.00元(15.1%)
3. 结论:
- 数码产品是核心品类,占比超8成;
- 服装品类需促销提升销量。3. 可视化:图表已保存为sales_analysis.png
结果图示:
5. 示例总结
示例通过大模型与智能体的结合,实现了销售分析任务的全流程自动化。其核心在于以 Prompt 为桥梁,让大模型驱动智能体的工具调用,同时通过模块化的工具设计,保证了系统的灵活性与扩展性。
核心业务价值:
- 流程自动化:替代人工完成”数据查询→计算→报告→可视化“,降低销售分析的人力成本;
- 结果标准化:输出结构化的报告和可视化图表,避免人工分析的格式不统一、计算错误;
- 决策支撑:直接输出可落地的业务结论(如服装品类促销),从数据整理升级为决策建议;
- 可复用性:仅需修改 SQL/Prompt 中的条件(如切换城市、时间),即可适配其他销售分析场景。
六、总结
大模型与智能体的结合,是人工智能技术从文本生成向任务执行跨越的关键一步。大模型为智能体提供了强大的理解与推理能力,智能体为大模型提供了落地任务的工具与执行框架,两者协同形成的“大脑 + 手脚”模式,正在重塑各行各业的 AI 应用形态。
随着大模型推理能力的提升和智能体架构的完善,大模型驱动的智能体将朝着更自主、更通用、更智能的方向发展:自主智能体将能够处理更复杂的多步骤任务,通用智能体将适配更多业务场景,而多智能体协同系统将能够完成单智能体无法胜任的复杂任务,AI蓬勃发展的时代,一切的美好都会如期而来。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)