收藏!后端研发的AI突围:保险业务RAG架构演进全解析(从基础到混合式检索)
首先明确核心概念:RAG(Retrieval-Augmented Generation,检索增强生成)是一种面向大模型应用的技术架构,核心逻辑是通过引入外部知识源,为大模型生成答案提供精准上下文支撑。其核心价值在于减少大模型幻觉、提升输出准确性、适配动态更新的业务数据——这也是我们选择RAG落地保险业务的关键原因。
作为一名深耕后端领域的研发人员,我踏入AI赛道已有2年时间。从最初的Chat QA交互开发,到AI Agent落地实践,再到Multi-Agent协同与AI-Native架构搭建,每一步都踩在技术迭代的浪潮上。
今年Q2,我们团队正式将AI能力与保险业务深度绑定,开启全面落地征程。目前,我们研发的AI Agent已成功跨越L1阶段(基础Chatbot问答),在L2阶段(Reasoner逻辑推理)实现能力爆发,能够高效处理保险业务中的复杂场景需求。
相信不少同行都有类似的焦虑:大模型技术迭代速度实在太快,尤其是Cursor、JoyCode等AI辅助开发工具普及后,行业风口彻底从微服务、微前端转向AI领域。不止是业务研发,就连模型开发从业者也面临挑战,单一Agent架构早已无法满足复杂业务需求。
而我找到的破局之道,是将后端研发熟悉的微服务架构思想迁移到AI领域——把Agent、Planning、RAG、Evaluation、MCP、LLM、Prompt、Memory、MultiModal等核心能力拆分为独立模块,通过标准化接口实现协同,既降低了技术复杂度,也提升了系统可扩展性。
在保险业务落地过程中,RAG(检索增强生成)架构是我们的核心支撑。从最初的基础版RAG,到优化后的DeepSearch检索,再到如今的混合式检索架构(Graph RAG + DeepSearch + 持续反思与验证),我们踩过不少坑,也沉淀了一套可复用的实践经验。接下来,就带大家完整拆解这一演进过程。
一、RAG基础认知:从定义到核心价值
首先明确核心概念:RAG(Retrieval-Augmented Generation,检索增强生成)是一种面向大模型应用的技术架构,核心逻辑是通过引入外部知识源,为大模型生成答案提供精准上下文支撑。其核心价值在于减少大模型幻觉、提升输出准确性、适配动态更新的业务数据——这也是我们选择RAG落地保险业务的关键原因。
从技术溯源来看,RAG最早由Facebook AI Research(现Meta AI)在2020年的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中提出。最初主要用于解决知识密集型NLP任务的知识更新问题,随着大模型技术成熟,逐渐成为企业级AI应用的核心架构之一。
二、基础RAG架构:朴素却关键的知识管理逻辑
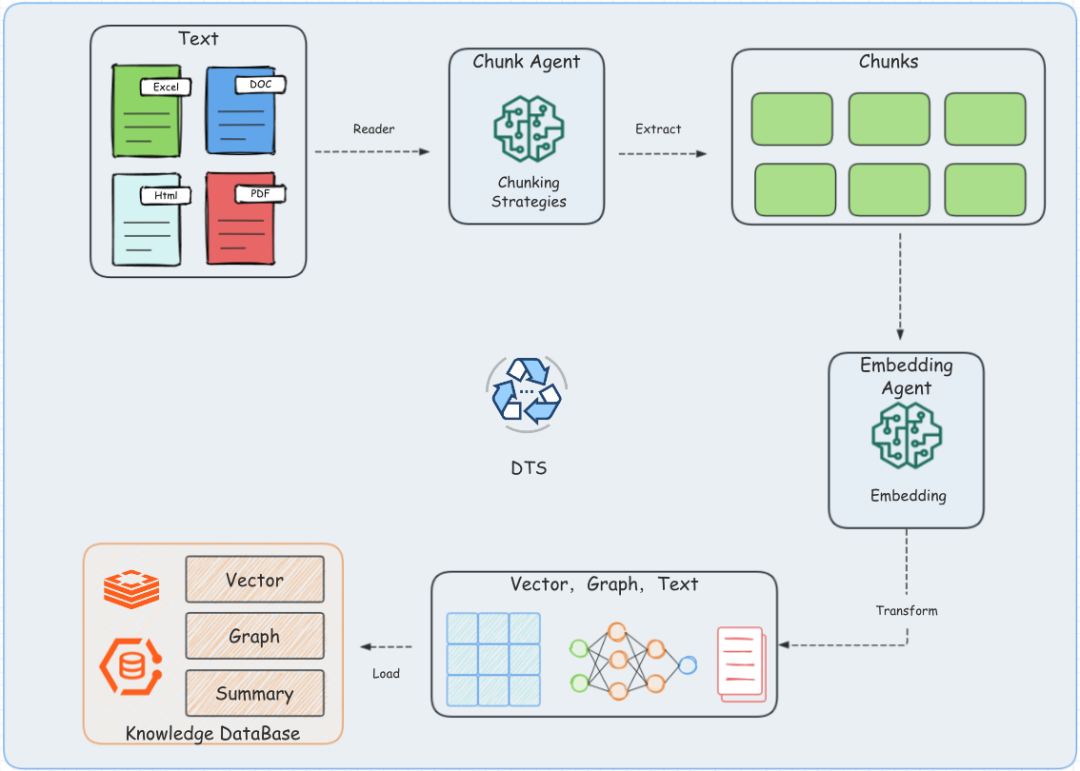
基础RAG是所有高级RAG范式(DeepResearch、Agentic RAG、Graph RAG等)的技术基石,掌握其核心组件与流程,是理解复杂架构的前提。基础RAG主要包含两大核心模块:生成组件(ETL Pipeline)与检索组件(Retrieval Pipeline),整体流程可拆解为“数据处理-检索匹配-答案生成”三大环节。
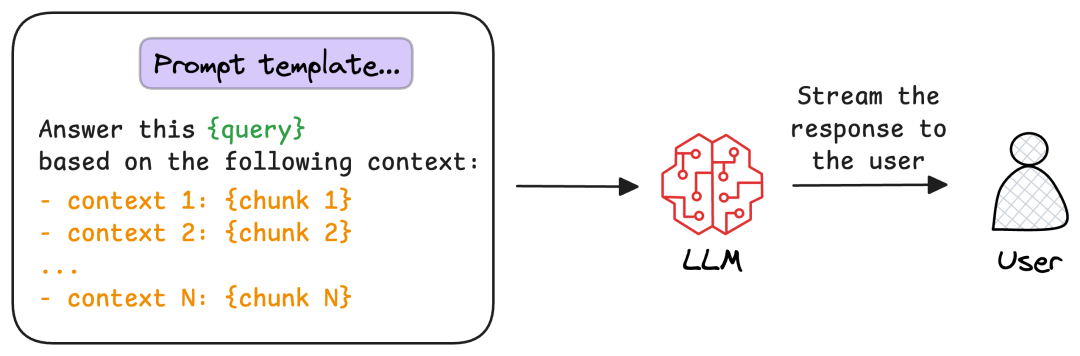
下图为基础RAG架构的核心流程示意图:
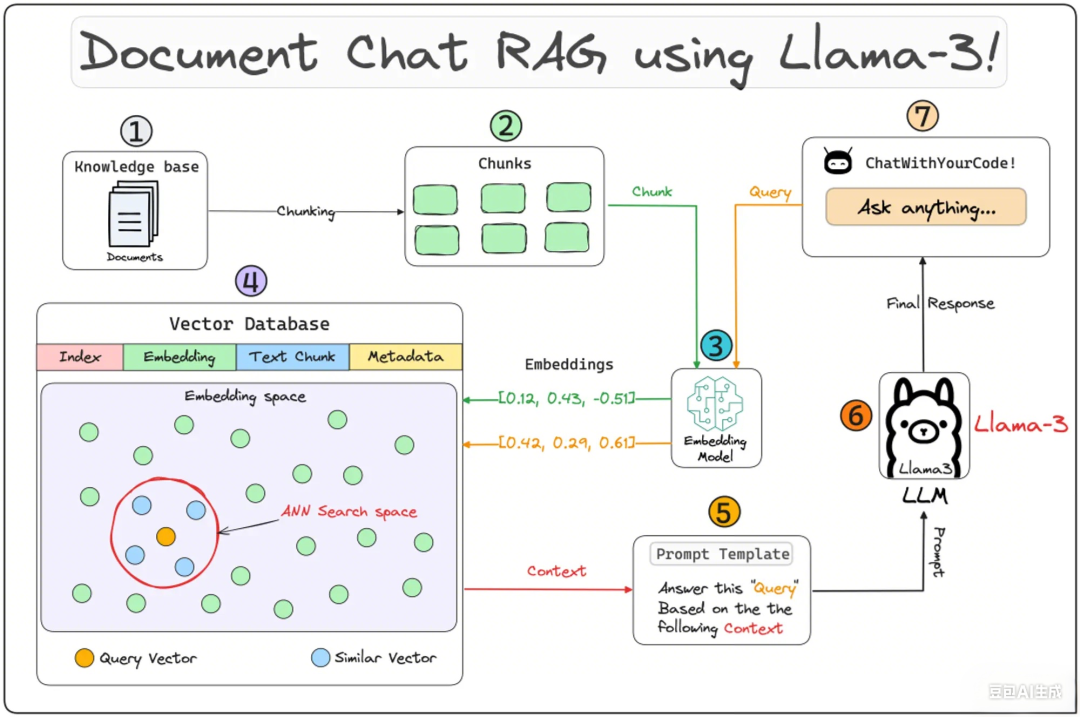
1. 生成组件:ETL Pipeline数据处理全流程
生成组件的核心目标是将分散的业务文档(保险条款、理赔手册、客户档案等)转化为可被检索的结构化数据,核心流程为“提取(Extract)-转换(Transform)-加载(Load)”,对应架构图中的①-④步骤。
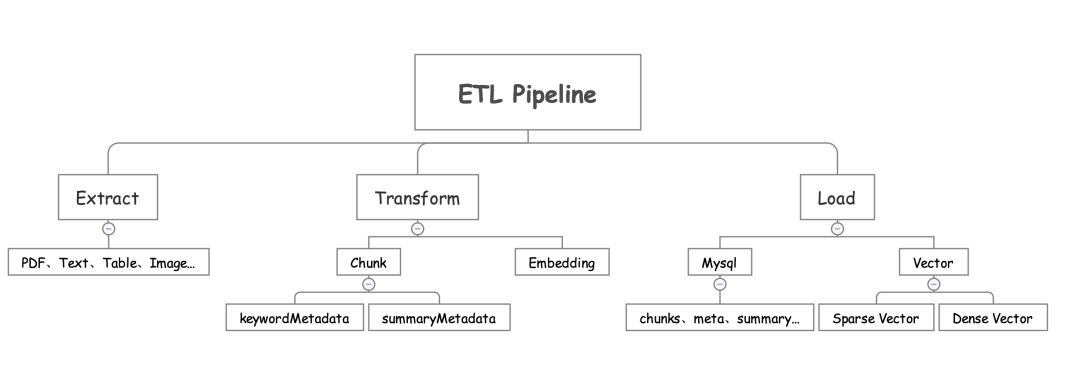
(1)提取(Extract):多格式文档解析
核心是实现多类型文件的高效读取,保险业务中常见的文件格式包括doc、pdf、excel、图片(扫描件)等。这里需要重点关注两个细节:一是中文文本的精准提取(避免乱码、格式错乱),二是Excel单元格的结构化解析(尤其是多sheet、合并单元格场景)。我们团队采用的是“多解析器适配方案”:对标准文档用Apache Tika,对图片用OCR+语言模型校正,确保提取数据的完整性。
(2)转换(Transform):Chunk分块与Embedding向量化
这是基础RAG的核心环节,直接决定后续检索的精准度,核心包含两个步骤:Chunk分块与Embedding向量化。
• Chunk分块:相当于“知识切片”,核心是将长文档拆解为语义完整、长度合适的文本块。就像切蛋糕一样,切得太大容易包含无关信息,切得太小会破坏语义完整性。我们整理了保险业务中常用的5种分块策略:
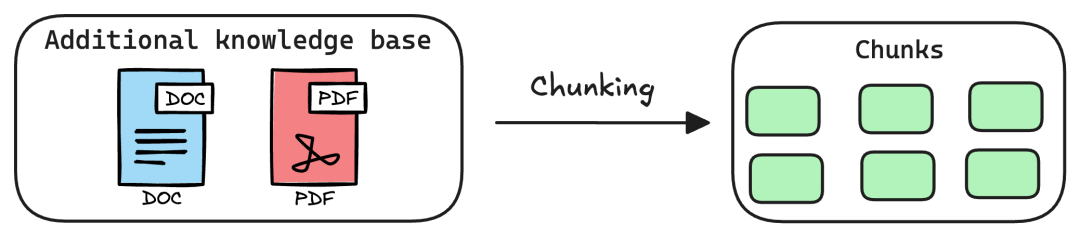
- 固定大小分块:按字符数/token数拆分(如500token/块),适配格式规范的文档;
- 语义分块:基于文本语义相似度拆分,用小模型判断句子间关联性,避免语义割裂;
- 递归分块:先按大粒度拆分,再对长块二次拆分,平衡效率与语义完整性;
- 基于文档结构分块:按标题、段落、章节拆分,适配保险条款这类结构化强的文档;
- 基于大模型分块:用大模型分析文档核心逻辑,按需拆分关键信息块,适配复杂业务文档。
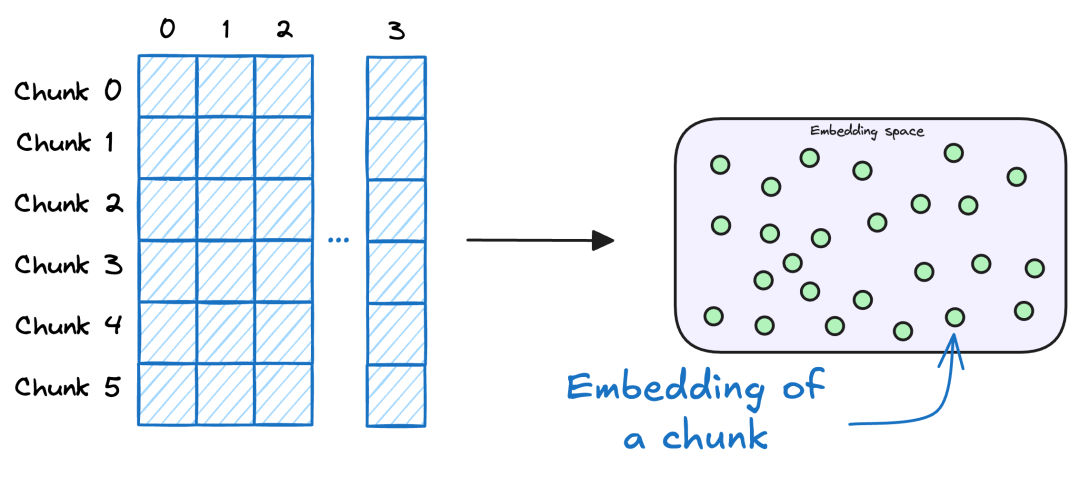
• Embedding向量化:将文本块转化为计算机可计算的向量数据,核心目的是支持后续的相似性检索。因为自然语言的表达方式多样(如“如何申请重疾理赔”与“重疾理赔流程是什么”),直接文本匹配准确率低,而向量化后可通过计算向量相似度(如余弦相似度)快速找到关联信息。
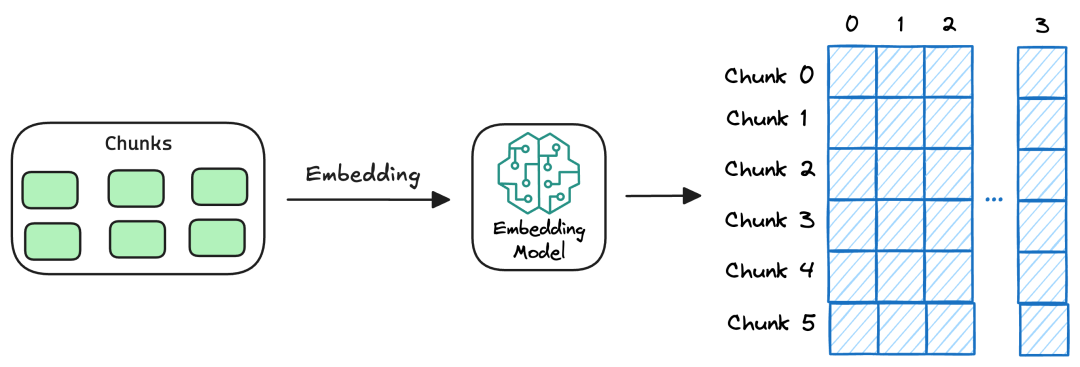
(3)加载(Load):混合存储方案落地
将处理后的向量数据与原始文本块存储到数据库中,支撑后续检索。我们团队采用的是Elasticsearch8+(ES)混合存储方案,既利用ES的向量检索能力,也保留其对结构化数据的查询支持。当然,也可根据业务需求选择专用向量库(如Milvus、Pinecone)+关系型数据库(MySQL)的组合方案。
2. 检索组件:从Query处理到结果排序
检索组件对应架构图中的⑦-⑥步骤,核心目标是根据用户Query(查询),从数据库中精准匹配相关文本块,核心流程为“预处理-检索-后处理”。
(1)预处理:Query优化增强
核心是对用户原始Query进行优化,提升检索精准度,属于业务定制化环节。常见优化手段包括:Query扩充(生成同义问句)、Query清洗(去除无关词汇)、Query转译(将口语化查询转化为标准化表述)。例如在保险场景中,将用户的“得了癌症怎么赔钱”转译为“恶性肿瘤理赔申请流程及赔付标准”,大幅提升检索相关性。
(2)检索:核心算法与流程
检索的核心是通过算法计算Query向量与文档向量的相似度,找到最相关的文本块。基础RAG常用两种核心算法:稀疏算法与稠密算法,具体差异如下表所示:
| 算法类型 | 核心逻辑 |
|---|---|
| 稀疏算法 | 利用LLM提取关键词,将文本块转化为基于TF-IDF值的向量(维度为所有关键词集合);Query转化为同类向量后,通过计算余弦相似度匹配相关文本块 |
| 稠密算法 | 常用BM25算法,通过Embedding模型将Query与文本块均转化为固定维度的稠密向量,再通过向量数据库的相似性检索找到匹配结果 |
具体检索流程分为三步:
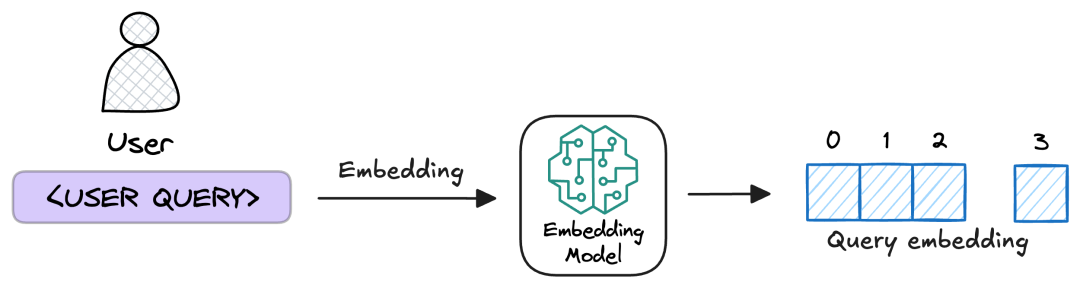
- 用与文档处理一致的Embedding模型,将优化后的Query转化为向量;
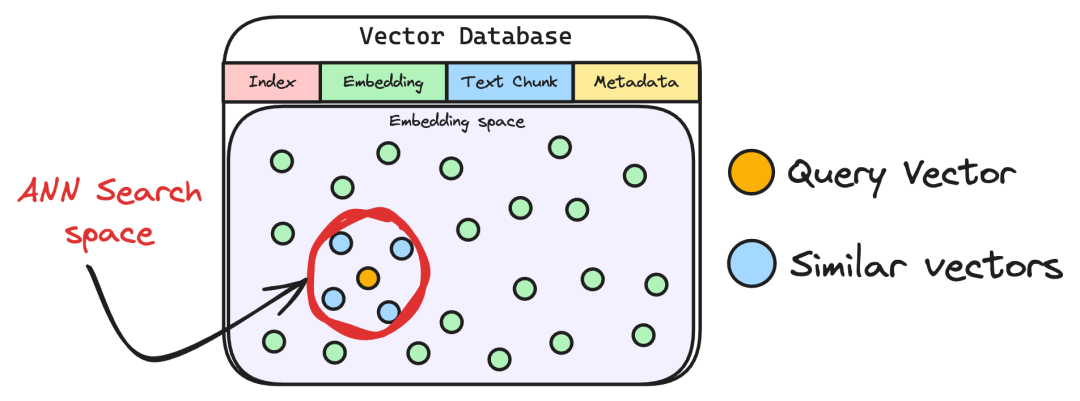
- 在向量数据库中执行相似性检索,我们支持ANN(近似最近邻)与kNN(k近邻)两种算法,数据库表结构包含核心字段:索引、向量块、原始文本块、源数据信息;
- TopK筛选:通过预设的k值(如k=5),仅保留相似度最高的前k条文本块,减少后续处理压力。
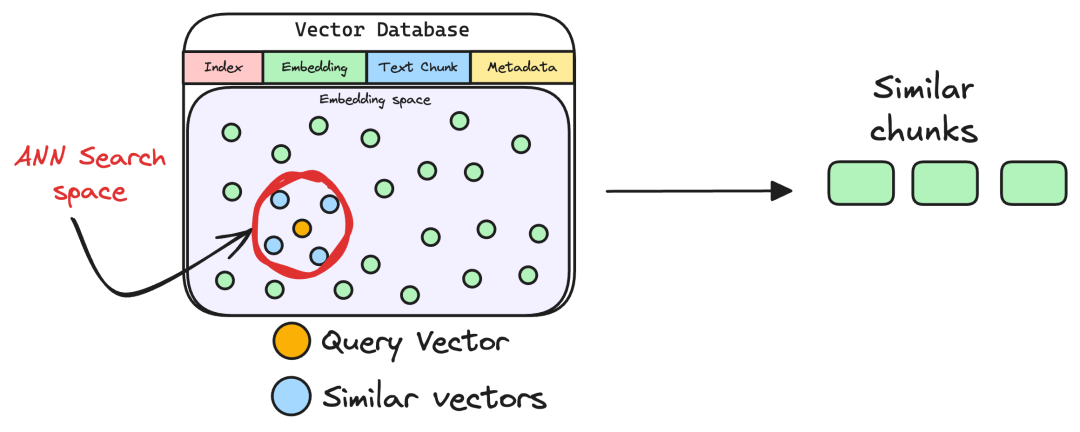
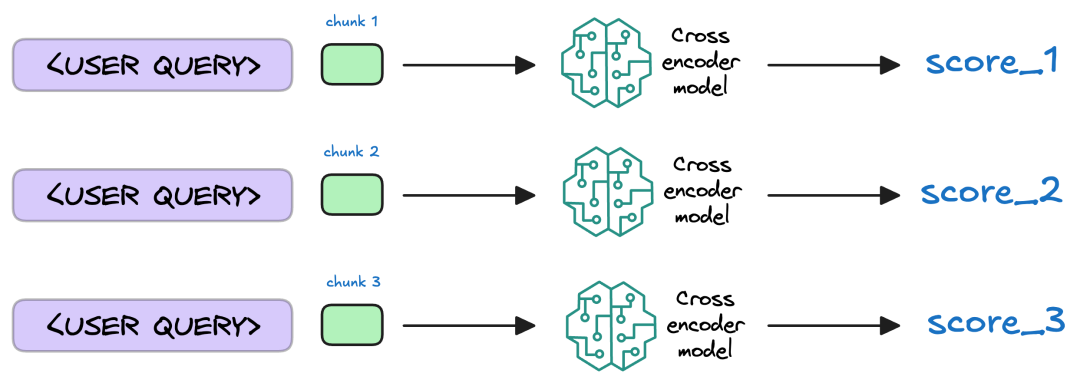
(3)后处理:排序与Prompt构建
后处理核心是提升结果精准度并为大模型生成提供上下文。关键步骤包括:
- 精排(Rerank):可选环节,通过专门的Rerank模型对初始检索结果重新评估打分,排序后保留最相关的文本块(尤其适用于多轮对话场景);
- 文本拼接:将排序后的文本块按相似度降序拼接,作为上下文补充到Prompt中;
- 答案生成:将原始Query与拼接后的上下文一同输入大模型,生成最终回复。
需要说明的是,基础RAG在2022年前后是主流方案,适用于简单问答场景。但随着大模型技术向Agentic方向发展,面对保险业务中“复杂理赔流程梳理”“多条款交叉解读”等深度检索需求,基础RAG的局限性逐渐凸显,这也推动我们向更高级的混合式检索架构演进。
三、保险业务定制:混合式RAG架构落地实践
结合保险业务的特殊性(文档量大、条款严谨、数据私密性强),我们构建了一套“多模块协同”的混合式RAG架构,核心包含“保险知识库+记忆库+文件库+智能体+搜索+测评”六大组件,由算法、工程、数据团队协同落地。
1. 算法层:Agentic RAG+DeepResearch融合架构
我们借鉴了通义DeepResearch的WebWeaver开源架构、微软GraphRAG开源方案,同时结合ZEP、REFRAG等最新论文思想,实现了“Agentic RAG+DeepResearch”的混合检索模式。核心亮点包括:
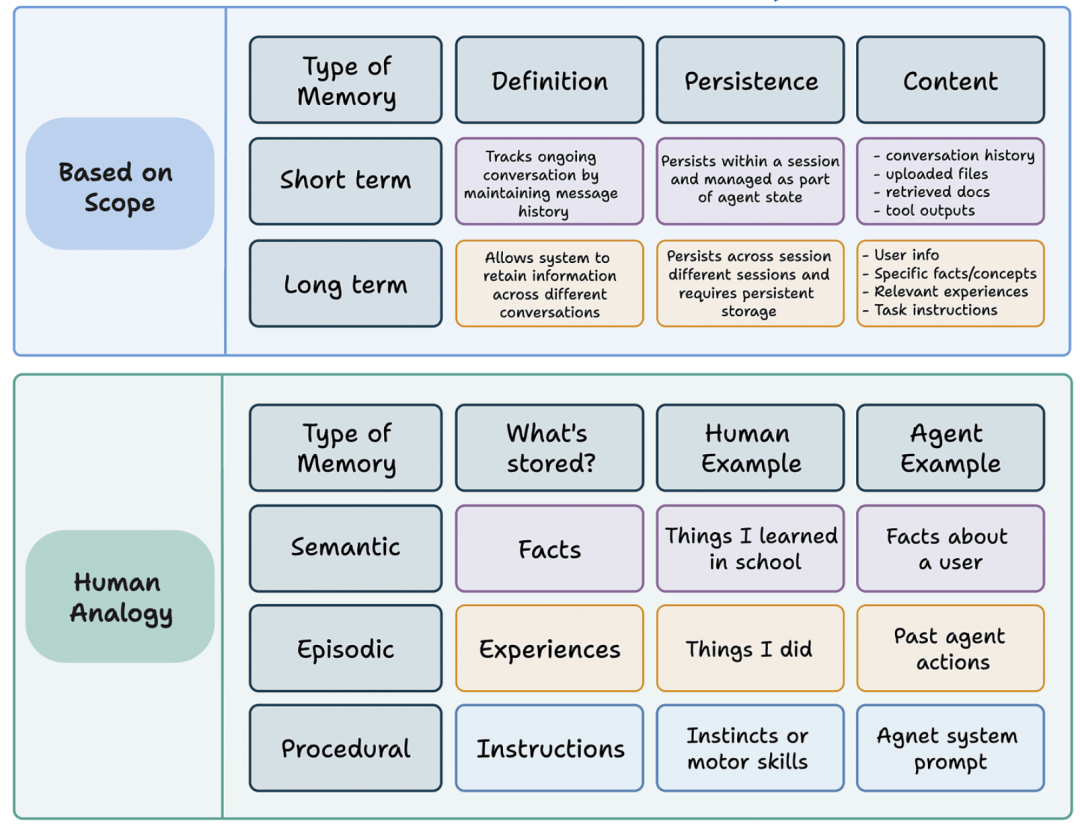
- 多维度记忆体系:实现“情景记忆+程序记忆+语义记忆+时间记忆”四合一,其中时间记忆可保障保险条款更新后的时效性;
- RAG智能体矩阵:构建六大核心智能体——查询增强智能体(优化Query)、规划师智能体(拆解复杂任务)、工具选择器智能体(匹配检索算法)、反思验证智能体(校验结果准确性)、图结构智能体(处理关联数据)、深度研究智能体(解决复杂问题)。
记忆体系的核心是三大记忆图谱,具体如下:
2. 工程层:全流程RAG平台搭建
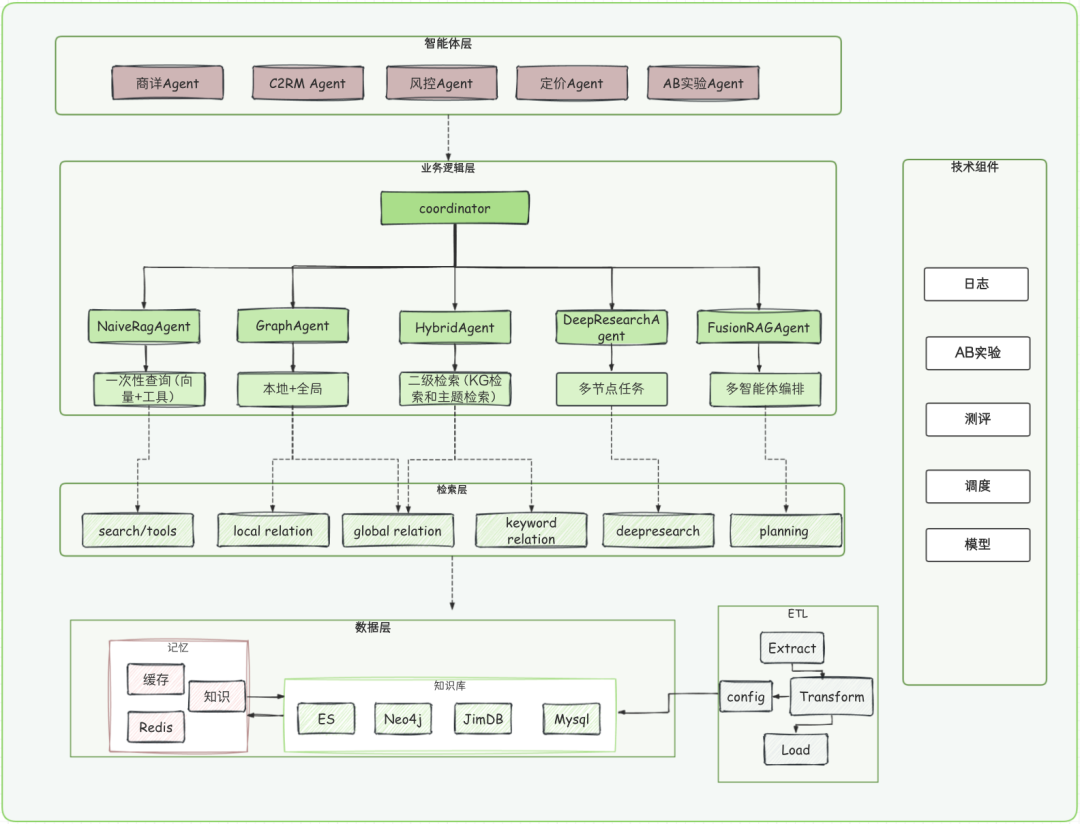
工程层的核心目标是“串联全流程、标准化接口”,让业务Agent无需关注检索细节,专注于模型训练与业务迭代。我们将工程架构分为四层,自上而下分别为:
- 智能体层:承接业务Agent的检索需求,提供统一调用入口;
- 业务逻辑层:封装保险业务专属的检索规则(如不同险种的条款匹配策略);
- 检索层:集成多种检索算法(稀疏、稠密、图检索),支持动态切换;
- 数据层:对接各类存储组件,保障数据高效读写。
核心技术栈:Spring AI(开发框架)、Elasticsearch8+(混合存储)、Neo4j(图数据库,支撑Graph RAG)、Redis(缓存优化)、京东云(部署环境)。同时,平台支持Python Code自定义脚本与RAG Agent Workflow可视化编排,提升开发效率。
工程架构示意图:
3. 数据层:三角矩阵数据架构设计
数据层采用“保险知识库+记忆库+任务中心”的三角矩阵架构,保障数据的完整性、时效性与可追溯性:
- 保险知识库:存储结构化的保险条款、理赔案例、产品说明等核心业务数据,架构如下:
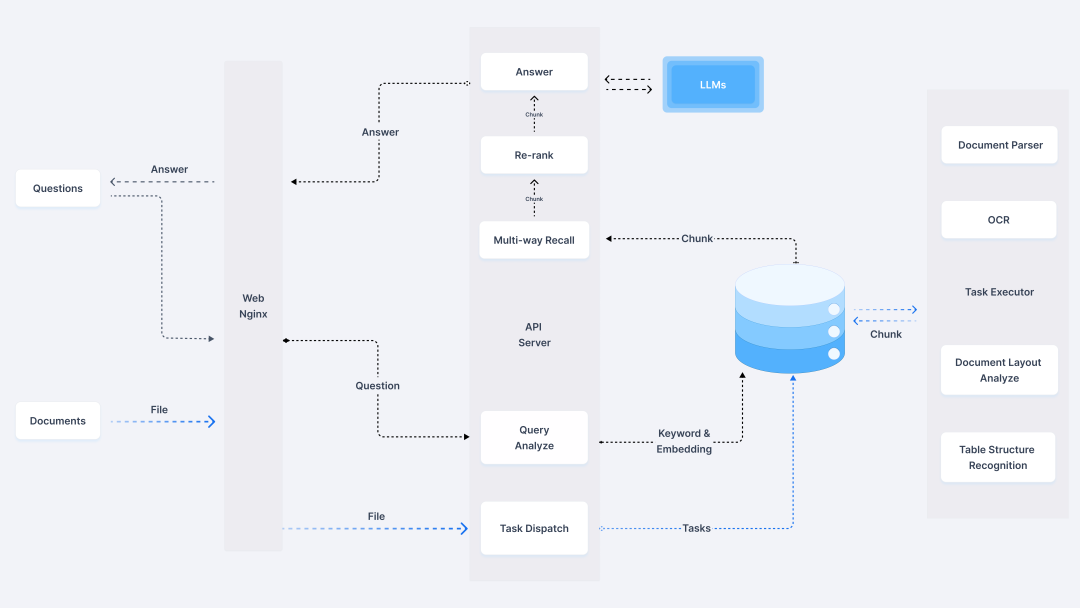
- 任务中心:负责文档处理、检索优化等后台任务的调度与监控,确保流程稳定运行:
- 记忆库:在三大基础记忆图谱(语义、程序、情景)的基础上,增加“创建时间+更新时间”双时间字段,确保记忆数据与业务数据同步更新。
此外,在Chunk分块策略上,我们借鉴Cognee的参数调优思想,结合保险文档特性优化了5种分块策略的参数配置,形成了专属的分块配置手册,大幅提升了检索精准度。
4. 架构设计核心考量
这套混合式RAG架构的设计,完全围绕我们的核心目标——构建“多智能体驱动的保险业务平台(Eva)”,具体考量包括:
- 业务数据特性:保险业务数据多为内部文档(无公开网络资源),且文档量大、格式复杂,必须通过定制化RAG实现精准检索;
- ToB业务目标:平台直接服务于保险经营(规模/利润),需保障AI输出的准确性、合规性,RAG的反思验证模块正是为这一目标设计;
- 平台化定位:RAG是Eva平台的基础能力之一,需通过标准化接口支撑多业务Agent的复用,降低整体研发成本。
四、RAG未来演进方向与学习指引
大模型技术仍在快速迭代,RAG的演进也不会止步。结合我们的实践,未来值得关注的方向包括:Agentic RAG的全流程优化、时间记忆图谱的深度落地、Chunk分块的自适应优化、多模态RAG的业务适配等。
如果大家对以下内容感兴趣,后续我会逐一拆解分享:
- Agentic RAG的详细实现:包括Deepsearch、Graph RAG与基础RAG的融合逻辑;
- 工程端核心能力:Python Code定制与RAG Agent Workflow的可视化编排;
- 记忆库深度设计:时间记忆图谱的技术实现与效果验证;
- Chunk参数调优手册:保险业务专属的分块策略与参数配置。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献467条内容
已为社区贡献467条内容

所有评论(0)