大模型基础研发(Python语言)VS 传统业务集成应用(Java/C#/Go等其他语言)
Transformer基于注意力机制的神经网络架构【原始结构是“Encoder-Decoder”(编码器-解码器)】,及其变体【Encoder-only只保留“编码器”(理解输入), Decoder-only只保留“解码器”(生成输出), Encoder-Decoder编码器(理解输入)+ 解码器(生成输出)】Common Crawl:通过AWS S3或HTTP接口下载(如https://da
大模型的基础研发(预训练、微调、推理优化)高度依赖Python生态
“架构选型→组件设计→数据处理→训练优化→评估迭代”:
一、架构选型
Transformer基于注意力机制的神经网络架构【原始结构是“Encoder-Decoder”(编码器-解码器)】,及其变体【Encoder-only只保留“编码器”(理解输入), Decoder-only只保留“解码器”(生成输出), Encoder-Decoder编码器(理解输入)+ 解码器(生成输出)】
- Transformer让模型自动“关注”输入中最重要的部分,用“注意力”给文中关键词(如人名、数字、结论句)画重点,再综合这些重点理解全文
- RNN像“逐句朗读”,容易忘记前文
- CNN像“只看每段第一句”,可能漏掉细节
| 变体类型 | 结构特点 | 通俗比喻 | 典型案例 | 适用任务 |
|---|---|---|---|---|
| Encoder-only | 只保留“编码器”(理解输入) | 只读不写的“分析师” | BERT、RoBERTa | 文本分类、情感分析、问答(如“这句话是正面还是负面?”) |
| Decoder-only | 只保留“解码器”(生成输出) | 只写不读的“作家” | GPT系列、LLaMA | 文本生成、对话、续写(如“写一首关于春天的诗”) |
| Encoder-Decoder | 编码器(理解输入)+ 解码器(生成输出) | 先读后写的“翻译官” | T5、BART | 机器翻译(中→英)、摘要生成(“把这篇新闻缩成3句话”) |
二、组件设计
Transformer的核心是堆叠的Transformer块,让模型“划重点”,计算输入中每个词与其他词的“相关程度,给重要词分配更高权重”。
每个块包括3个关键组件:注意力机制(Multi-Head Attention)、位置编码(Positional Encoding)、前馈网络(FFN)
如:GPT系列使用Decoder-only结构;BERT使用Encoder-only结构;T5使用Encoder-Decoder结构
单头注意力(Scaled Dot-Product Attention):
多头注意力(Multi-Head):
- 把Q、K、V拆分成h个“头”(如8头、16头),每个头独立计算注意力;
- 最后把所有头的结果拼接起来,让模型同时关注多种关系(如有的头看语法,有的头看语义,有的头看情感)。
案例:处理句子“小明吃苹果,小红吃香蕉”。多头注意力可能:
- 头1关注“小明-吃-苹果”的主谓宾关系;
- 头2关注“苹果”和“香蕉”的并列关系;
- 头3关注“吃”这个动作的重复性。
位置编码(Positional Encoding):告诉模型“词的顺序”。通俗比喻:给每个词发一个“座位号”(如第1个座位、第2个座位…),模型通过座位号知道“谁在前谁在后”。
Transformer的注意力机制本身“无视顺序”(“我爱你”和“你爱我”的注意力计算结果可能一样),但实际语言中顺序至关重要
给每个词添加一个“位置标签”,让模型知道它在句子中的位置。有两种主流方法:
前馈网络(FFN):对“重点”进一步加工
注意力机制输出的“重点关注结果”可能比较粗糙,FFN像一个“精细加工车间”,用两层全连接网络(中间加ReLU激活函数)提取更复杂的特征。
注意力输出“小明吃苹果”的重点是“小明-吃-苹果”,FFN可能进一步加工出“动作(吃)”“主体(小明)”“对象(苹果)”的抽象特征。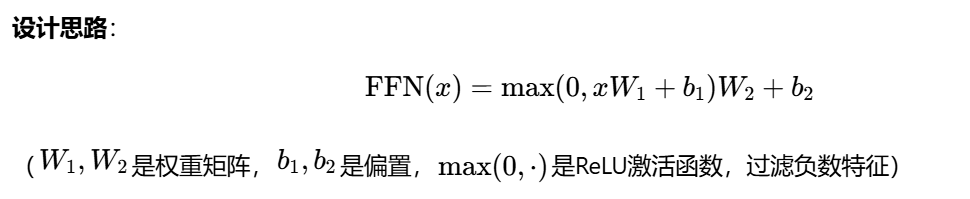
损失函数:“模型的错题本”,衡量预测结果与真实答案的差距,指导模型优化方向
交叉熵(分类)(Cross-Entropy Loss):分类任务的“标准错题本”
作用:用于“预测类别概率”的任务(如下一个词是什么、图片属于哪类)
通俗解释:假设你考试有3个选项(A/B/C),正确答案是A。如果你预测的概率是[A:0.8, B:0.1, C:0.1],说明你很自信且正确,损失很小;如果预测[A:0.3, B:0.6, C:0.1],说明你搞错了,损失很大。

自回归语言建模损失(Autoregressive LM Loss):生成任务的“逐字错题本”
作用:用于“逐个预测下一个词”的生成任务(如GPT续写句子),本质是交叉熵损失的序列版。
设计思路:将长句子拆分为多个“预测单元”,每次输入前n个词,预测第n+1个词,累积所有预测的损失。
案例:句子“我爱吃苹果”,训练时分3步预测:
训练稳定技巧:Layer Norm位置调整+残差连接缩放
大模型训练时容易出现“梯度爆炸/消失”(数值太大或太小导致模型学不动),这两个技巧是“稳压器”
①、Layer Normalization(层归一化):让数据“标准化”
作用:将每一层神经元的输出归一化到均值0、方差1,避免数值波动太大。
位置调整:原始Transformer用“Post-LN”(残差连接后归一化:输入→子层→加残差→归一化),但训练不稳定;后来改为“Pre-LN”(归一化后子层:输入→归一化→子层→加残差),梯度更稳定,成为主流。
通俗比喻:学生考试前,老师先把所有人的分数“标准化”(比如平均分70,标准差10,高于90算优秀),避免个别超高/超低分影响整体教学。
②、残差连接缩放(Residual Connection Scaling):避免“新旧信息打架”
作用:Transformer的“残差连接”是把输入直接加到子层输出上(x+Sublayer(x)),但如果子层输出数值太大,会“淹没”原始输入的信息。缩放就是给子层输出乘一个小系数(如0.1),让新旧信息“和谐共存”。

三、数据处理
①、大规模数据采集,优先公开数据集(Common Crawl、Wikipedia),爬虫需合规
来源:网页文本(Common Crawl)、书籍(Project Gutenberg)、学术论文(arXiv)、代码库(GitHub)等
规模:通常需TB级原始数据(如GPT-3使用45TB文本压缩至570GB)
(1)公开数据集直接下载
Common Crawl:通过AWS S3或HTTP接口下载(如https://data.commoncrawl.org/),提供WARC(网页存档)、WAT(元数据)、WET(纯文本)格式
# 下载2023年10月的WET文件示例(需AWS CLI)
aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2023-40/segments/1696525140000.0/wet/CC-MAIN-20230815074000-20230815104000-00000.warc.wet.gz ./
Wikipedia:通过官方Dump下载(https://dumps.wikimedia.org/),选择enwiki-latest-pages-articles.xml.bz2(英文百科纯文本)
(2)API接口采集
社交媒体(Twitter API、Reddit API):需申请权限,按配额获取帖子/评论(注意遵守平台规则)
学术数据库(arXiv API):用Python脚本批量拉取论文摘要与正文
import requests
params = {"search_query": "cat:cs.CL", "start": 0, "max_results": 1000} # 计算机语言学论文
response = requests.get("http://export.arxiv.org/api/query", params=params)
(3)网络爬虫(谨慎使用)
工具:Scrapy(框架)、BeautifulSoup(解析HTML)、Selenium(动态页面)
注意事项:
- 遵守robots.txt协议(如https://www.example.com/robots.txt);
- 控制爬取频率(避免服务器过载);
- 仅采集公开无版权争议数据(如政府公开报告、开源社区内容)
反爬机制:用代理IP池(如Luminati)、随机User-Agent、验证码识别(OCR或第三方服务)
效率问题:分布式爬虫(如Scrapy Cluster)+ 异步IO(aiohttp)提升速度
合法性:优先选择授权数据集(如LAION-5B图像-文本对),避免侵权
②、存储,分布式文件系统(HDFS/S3)+ 列式格式(Parquet)降本增效
| 场景 | 存储系统 | 数据格式 | 优势 |
|---|---|---|---|
| 原始数据文档 | HDFS(分布式文件系统、AWS S3) | WARC(网页)、SXONL(结构化) | 高容错、支持PB级扩展 |
| 清洗中临时数据 | Apache Parquet(列式存储)、CSV | Parquet | 压缩率高(比JSON小70%)、支持列过滤 |
| 高频访问数据 | Redis(内存数据库)、Alluxio(缓存) | 二进制序列化(Protobuf) | 低延迟读取 |
存储优化:
- 按时间(如year=2023/month=10)、语言(lang=en)、来源(source=wikipedia)分区,加速查询
- 压缩算法:用Zstandard(Zstd)或Snappy压缩文本(比Gzip快2倍,压缩率相近)
- 冷热分离:热数据(近期采集)存SSD,冷数据(历史归档)存HDD或磁带库
③、数据清洗与过滤,去重(MinHash)、质量过滤(启发式+ML)、脱敏(PII识别)
去重:删除重复文档(MinHash或SimHash算法)
- 精确去重:用哈希值(MD5/SHA256)标记文档,相同哈希值视为重复(适合短文本)
- 模糊去重:针对长文本(如网页),用MinHash/LSH(局部敏感哈希)或SimHash计算相似度(阈值设为0.9以上判定重复)
质量过滤:移除低质量内容(广告、乱码),保留高信息密度文本
启发式规则过滤
长度过滤:删除过短(<50字符)或过长的文档(>10万字符,可能是垃圾页)
特殊字符比例:删除含大量乱码(如�)、广告链接(含click here)的文档
语言纯度:用FastText语言检测模型(准确率>99%),保留单一目标语言文档(如仅英文)
机器学习过滤:训练二分类模型(如BERT)判别“高质量/低质量”,标注样本包括:
正例:维基百科、权威新闻
负例:论坛灌水、机器生成垃圾文本
敏感信息脱敏
PII(个人身份信息)识别:用正则表达式(匹配邮箱\w+@\w+.\w+、电话\d{3}-\d{4}-\d{4})+ NER模型(如Spacy的en_core_web_lg识别姓名、地址)
脱敏方法:替换为占位符(如[EMAIL]、[PHONE])或直接删除
工具链
- 分布式清洗:Apache Spark(处理TB级数据)、Flink(流处理实时数据)
- 轻量清洗:Python+Pandas(小规模数据)、Shell脚本(文本替换)
敏感信息脱敏:过滤隐私数据(PII检测)
④、分词与Tokenization,选BPE/WordPiece/SentencePiece,按语料特性调参(词表大小、字符覆盖)
分词器(Tokenizer)是将字符串转换为token ID序列的工具,核心目标是平衡词表大小与语义覆盖
| 算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| BPE | 迭代合并高频字符对(如“e”+“r”→“er”) | 简单高效,词表可控 | 无法处理未登录词(OOV) | 英文、代码(GPT系列用) |
| WordPiece | 类似BPE,但基于“子词概率”合并(而非频率) | OOV率低,适合多语言 | 训练复杂度略高 | BERT、ALBERT |
| SentencePiece | 无监督分词,直接处理原始字节(支持空格分隔) | 跨语言统一,无需预分词 | 词表稍大 | T5、LLaMA、多语言模型 |
选择分词器:Byte-Pair Encoding (BPE)、WordPiece或SentencePiece
分词器用法(以SentencePiece为例)
Ⅰ、安装与训练
# 安装SentencePiece
pip install sentencepiece
# 训练分词器(使用清洗后的文本文件corpus.txt)
# --vocab_size=32000:目标词表大小(GPT-3用100K,BERT用30K)
# --character_coverage=0.9995:覆盖99.95%的字符(中文设0.9999,英文0.9995)
spm_train --input=corpus.txt --model_prefix=my_tokenizer --vocab_size=32000 \
--character_coverage=0.9995 --model_type=bpe # 可选bpe/wordpiece/unigram
Ⅱ、加载与使用
import sentencepiece as spm
# 加载模型
sp = spm.SentencePieceProcessor(model_file='my_tokenizer.model')
# 分词(返回token列表)
tokens = sp.encode_as_pieces("Hello world! 你好世界!")
# 输出:['▁Hello', '▁world', '!', '▁你', '好', '世', '界', '!'](▁表示空格)
# 转为ID序列
ids = sp.encode_as_ids("Hello world!")
# 输出:[15496, 2159, 0](0通常是[PAD]或[UNK])
构建词表:从“零件清单”到“标准字典”,平衡词汇量(通常3万~5万个token)与覆盖率
词表是token到ID的映射表,构建需兼顾覆盖性(尽量包含常见子词)与效率(避免过大词表增加计算量)
Ⅰ、初始化词表:包含所有单字符(如26个英文字母、中文常用字),以及特殊token([PAD]填充、[UNK]未知词、[CLS]分类、[SEP]分隔、[MASK]掩码)
Ⅱ、统计子词频率:遍历语料,统计所有连续字符对的共现频率(如“th”“he”“ing”)
Ⅲ、迭代合并高频子词:每次合并频率最高的字符对(如BPE算法),直到词表达到目标大小(如3万~10万)
Ⅳ、优化词表:
- 手动添加领域关键词(如医学术语“COVID-19”)
- 删除低频无用token(如生僻字、罕见符号)
示例:GPT-3使用100K token的词表
四、训练优化
训练基础设施:
- 算力需求,GPU集群:数百至数千张A100/H100(如GPT-3用1024张V100训练30天)
- 网络,高速互联(InfiniBand/NVLink)降低通信延迟
- 存储与I/O优化,分布式文件系统(如HDFS)加速数据加载,预处理数据缓存至SSD
①、模型实现
框架选择:PyTorch/TensorFlow + 分布式训练库(DeepSpeed、Megatron-LM)
PyTorch是以动态图(Eager Execution)为核心的开源深度学习框架,由Facebook(Meta)开发。
支持最新模型(如Transformer、Diffusion Model),社区贡献的库(如Hugging Face Transformers、TorchVision)覆盖CV/NLP等多领域
中小模型迭代高效:适合10亿参数以下的模型(如BERT-base、GPT-2),快速调整结构(如增减注意力头)
企业级应用场景:
- 电商推荐(如DeepFM模型,每周迭代特征)
- 多模态生成(如图文生成大模型,需频繁调整生成逻辑)
- 学术研究(如高校/实验室的预训练模型实验)
从安装到部署的使用步骤:
Ⅰ、安装,用pip一键安装(支持CPU/GPU版本)
# CPU版本
pip install torch torchvision torchaudio
# GPU版本(需提前安装CUDA)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Ⅱ、基本使用步骤(以“训练一个文本分类模型”为例)
定义模型(继承nn.Module),用PyTorch的nn模块搭建网络(如Embedding+Transformer Encoder+分类头):
import torch
import torch.nn as nn
class TextClassifier(nn.Module):
def __init__(self,vocab_size=30000,d_model=512,n_classes=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size,d_model) #词嵌入
self.transformer = nn.TransformerEncoder( # Transformer编码器
nn.TransformerEncoderLayer(d_model,nhead=8)
num_layers=6
)
self.classifier = nn.Linear() #分类头
def forward(self,x):
x = self.embedding(x) # [batch_size, seq_len, d_model]
x = self.transformer(x) # [batch_size, seq_len, d_model]
x = x.mean(dim=1) # 平均池化(取序列特征)
return self.classifier(x) # [batch_size, n_classes]
加载数据(Dataset+DataLoader),用torch.utils.data处理数据(如文本转token ID、分批次):
from torch.utils.data import Dataset,DataLoader
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=128):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self.idx):
text = self.self.texts[idx]
label = self.labels[idx]
#分词(用Hugging Face Tokenizer)
encoding = self.tokenizer(text, truncation=True, padding='max_length', max_length=self.max_len)
return {
'input_ids':torch.tensor(encoding['input_ids'])
'attention_mask':torch.tensor()
'label':torch.tensor(label)
}
# 初始化数据集与加载器
dataset = TextDataset(texts, labels, tokenizer)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
训练循环(前向传播—>损失计算—>反向传播—>优化)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TextClassifier().to(device)
optimizer = torch.optim.AdamW(model.parameters(),lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(3): #训练3轮
model.train()
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
#前向传播
outputs = model(input_ids,attention_mask) #假设模型接受mask
loss = loss_fn(outputs,labels)
#反向传播+优化
optimizer.zero_grad() #清空梯度
loss.backward() #计算梯度
optimizer.step() #更新权重
print(f"Epoch {epoch+1},Loss:{loss.item()}")
分布式训练(结合DeepSpeed)
把一批数据拆成N份(N=GPU数量),每台GPU算1份数据的“前向传播→损失计算→反向传播”,算出各自的梯度后,同步所有GPU的梯度(取平均),再用这个平均梯度更新每台GPU上的模型参数(保证所有卡模型一致)
# DDP + DeepSpeed分布式训练策略。用DistributedDataParallel(DDP)做数据并行,配合DeepSpeed优化显存
import deepspeed
#初始化DeepSpeed配置(zeRO-2优化)
ds_config = {
"train_batch_size":32,
"gradient_accumulation_steps":2,
"optimizer":{"type":"AdamW","":{}},
"fp16":{"enabled":True} #混合精度训练
}
#启动分布式训练
model_engine,optimizer,_,_ = deepspeed.initialize(
model=model,model_parameters=model.parameters(),config=ds_config
)
#训练循环中用model_engine代替model
outputs = model_engine(input_ids)
loss = loss_fn(outputs,labels)
model_engine.backward(loss)
model_engine.step()
部署(TorchScript+TorchServe)将模型转为TorchScript(静态图)部署到生产:
#导出TorchScript模型
scripted_model = torch.jit.script(model)
scripted_model.save("text_classifier.pt")
#用TorchServe部署(需安装torchserve)
torchserve --start --model-store ./model_store --models text_classifier=text_classifier.mar
TensorFlow是以静态图(Graph Mode)为核心的开源深度学习框架,由Google开发。
企业级应用场景
- 金融风控(如千亿参数大模型,需7×24小时稳定运行)
- 移动端AI(如手机拍照识图,用TFLite压缩模型)
- 政务/医疗(如病历分类模型,需符合行业合规要求)
从安装到部署的使用步骤:
Ⅰ、安装
# CPU版本
pip install tensorflow
# GPU版本(需CUDA)
pip install tensorflow-gpu
Ⅱ、定义模型(以“训练CTR预估模型”为例)
#用Keras高层API搭建模型,如DeepFM,融合因子分解机与深度网络
import tensorflow as tf
from tensorflow.keras import layers
class DeepFM(tf.keras.Model):
def __init__(self,num_features,embedding_dim=16):
super().__init__()
self.embedding = layers.Embedding(num_features,embedding_dim) #特征嵌入
self.fm_layer = layers.Add() #因子分解机(二阶交叉)
self.dense_layers = tf.keras.Sequential([ #深度网络
layers.Dense(128,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(1,activation='sigmoid')
])
def call(self,inputs):
# inputs:[batch_size,num_fields](稀疏特征ID)
embeddings = self.embedding(inputs) # [batch_size, num_fields, embedding_dim]
#因子分解机部分(二阶交叉)
sum_embeddings = tf.reduce_sum(embeddings,axis=1) # [batch_size, embedding_dim]
sum_squares = tf.reduce_sum(embeddings**2,axis=1) # [batch_size, embedding_dim]
fm_output = 0.5 * tf.reduce_sum(sum_embeddings**2 - sum_squares, axis=1, keepdims=True) # [batch_size, 1]
#深度网络部分
dense_input = tf.reshape(embeddings, [-1, embeddings.shape[1]*embeddings.shape[2]]) # 展平
deep_output = self.dense_layers(dense_input) # [batch_size, 1]
#融合输出
return tf.sigmoid(fm_output + deep_output) # [batch_size, 1]
加载数据(tf.data.Dataset)
def load_data(file_path,batch_size=32):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=batch_size,
label_name="click",#目标列(是否点击)
na_value="?",
num_epochs=1,
ignore_errors=True
)
return dataset.prefetch(tf.data.AUTOTUNE) #预加载优化
train_dataset = load_data("train.csv")
val_dataset = load_data("val.csv")
训练循环(compile+fit)
model = DeepFM(num_features=10000) #假设特征空间10万
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['auc']
)
#训练(自动处理前向、反向传播)
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=5
)
分布式训练(MirroredStrategy)
#用MirroredStrategy做单机多卡数据并行:
strategy = tf.distribute.MirroredStragegy() #自动检测GPU
with strategy.scope():
model = DeepFM(num_features=10000)
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['auc'])
model.fit(train_dataset,cpochs=5)
Ⅲ、部署(TF Serving+TFLite)
云端部署:用TF Serving暴露REST/gRPC接口:
# 启动TF Serving(加载SavedModel格式)
tensorflow_model_server --rest_api_port=8501 --model_name=deepfm --model_base_path=/path/to/saved_model
移动端部署:用TFLite压缩模型(INT8量化):
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open("deepfm.tflite", "wb") as f:
f.write(tflite_model)
3D并行:
- 数据并行(Data Parallelism):拆分批次到多GPU
- 流水线并行(Pipeline Parallelism):按层切分模型(如GPipe)
- 张量并行(Tensor Parallelism):拆分单个矩阵运算(如Megatron-LM)
混合精度训练:FP16/BF16计算 + FP32主权重(减少显存占用)
梯度累积:模拟大批次训练(小批次累加梯度后更新)
训练优化技术
企业抉择:
- 追求极致精度(如医疗、金融风控):AdamW+Warmup Cosine+CutMix+Label Smoothing+MoE
- 追求训练效率(如互联网推荐、CV):ZeRO-3+混合精度+梯度累积+早停
- 追求落地成本(如移动端、边缘设备):知识蒸馏+Adapter+剪枝量化+梯度检查点
一、优化器与学习率调度(让模型“学得更聪明”)
①、优化器:决定如何更新模型参数
早期SGD优化器(随机梯度下降)收敛慢,易陷入局部最优;Adam优化器虽快,但权重衰减(防过拟合)实现不当易导致泛化差
企业级优化器:AdamW(权重衰减解耦)或Lion(新优化器)
- AdamW:在Adam基础上解耦权重衰减(将权重衰减从梯度更新中分离,直接作用于参数),解决Adam泛化差问题,成为大模型训练标配
- Lion(EvoLved Sign Momentum):谷歌2023年提出,用“符号动量”(只保留梯度方向,忽略大小)替代传统动量,计算更简单、内存占用更低,适合超大模型
企业案例:电商推荐模型的AdamW优化
- 场景:某头部电商用Wide&Deep模型做商品推荐,训练时发现Adam优化器导致验证集AUC波动大(过拟合),收敛需50轮
- 方案:改用AdamW(权重衰减系数设为0.01),并配合学习率warmup(前5轮从0线性增至初始LR)
- 效果:收敛轮次从50→28轮,验证集AUC提升1.2%(从0.82→0.832),线上点击率提升3%
②、学习率:Warmup + Cosine衰减,调度控制更新步长,何时变大、变小
核心逻辑:训练初期用小LR“热身”(避免参数震荡),中期用大LR快速收敛,后期用小LR精细调优
企业常用策略:
- 余弦退火(Cosine Annealing):LR随迭代次数按余弦曲线下降,后期缓慢收敛到最小值,适合大模型
- 带热身的余弦退火(Warmup Cosine):前N轮LR从0线性增至初始值(热身),再按余弦曲线下降,避免冷启动不稳定
企业案例:金融风控模型的Warmup Cosine调度
- 场景:某银行用XGBoost+NN融合模型训练反欺诈模型(10亿样本),初始LR=0.001时,前10轮梯度爆炸(Loss骤增)
- 方案:采用Warmup Cosine调度(热身5轮,初始LR=0.0001,热身至0.001,再按余弦曲线降至0.00001)
- 效果:训练稳定性提升,Loss波动从±20%→±3%,最终KS指标(风控模型核心指标)从0.42→0.45(行业优秀水平)
二、正则化与泛化增强(让模型“不死记硬背”)
正则化解决“模型过度拟合训练数据(死记硬背),在新数据上表现差”的问题,核心是增加训练难度,迫使模型学习通用规律
①、权重衰减(Weight Decay)与Dropout
- 权重衰减:训练中对模型参数施加“惩罚”(如L2正则化),限制参数绝对值过大(避免复杂模型过度拟合)
- Dropout:训练时随机“关闭”部分神经元(如关闭20%),强迫剩余神经元学习更鲁棒的特征(类似“团队中有人请假,其他人必须顶上”)
企业案例:医疗影像诊断模型的Dropout+权重衰减
- 场景:某医疗AI公司用ResNet-50训练肺部CT结节检测模型,训练集准确率98%,但测试集仅85%(严重过拟合)
- 方案:在全连接层添加Dropout(p=0.5),并在优化器中加入权重衰减(λ=0.0001)
- 效果:测试集准确率提升至92%,假阳性率(误诊正常为结节)从15%→8%,达到临床辅助诊断要求
②、Label Smoothing缓解“标签绝对化”导致的过拟合
原理:将硬标签(如“猫=1,狗=0”)改为软标签(如“猫=0.9,狗=0.1”),避免模型对单一标签“过度自信”,增强泛化
企业案例:自动驾驶感知模型的Label Smoothing
- 场景:某公司用YOLOv5训练车辆检测模型,训练中发现模型对“相似车型”(如SUV与MPV)易混淆(置信度>0.9但标错)
- 方案:对分类标签应用Label Smoothing(ε=0.1),将硬标签转为“正确类0.9,其他类0.1/(类别数-1)”
- 效果:混淆类别的mAP(平均精度)从75%→88%,误检率(将路牌误判为车辆)下降40%
三、数据相关优化(优化方向包括数据增强、清洗、采样)
①、高级数据增强:CutMix/MixUp,用“混合样本”提升泛化,模拟“现实中的模糊场景”(如遮挡、光照变化),让模型学习更鲁棒的特征
- CutMix:将两张图像的局部区域裁剪后互换,标签按区域面积加权(如A图占70%区域,则标签=0.7A标签+0.3B标签)
- MixUp:将两张图像像素级混合(如A图×0.6+B图×0.4),标签同样加权混合
企业案例:手机拍照AI修图模型的CutMix增强
- 场景:某手机厂商用CNN训练“夜景降噪模型”,训练集仅含清晰夜景图,实际用户拍摄常遇“手抖模糊+灯光过曝”,模型泛化差
- 方案:在数据增强中加入CutMix(随机裁剪2张夜景图局部互换)+高斯模糊(模拟手抖)
- 效果:用户实拍测试集PSNR(图像质量指标)从28dB→32dB(接近专业修图软件),用户满意度调研提升25%
②、难度挖掘:训练中自动识别“模型易错的样本”(如分类错误、边界模糊样本),对这些样本“重点学习”(增加其在训练集中的权重)
企业案例:安防监控人脸识别的难例挖掘
- 场景:某安防公司用人脸识别模型监控园区,发现“戴口罩+侧脸”的样本识别率仅60%(远低于正脸无遮挡的95%)
- 方案:用在线难例挖掘(训练中实时统计Top 10%错误样本),将这些样本复制3份加入当前批次
- 效果:难例识别率从60%→85%,园区漏检事件下降50%
四、模型结构优化
在不显著损失精度的前提下,通过简化模型结构、引入高效模块,降低训练/推理成本
①、MoE(Mixture of Experts):大模型“按需调用专家”
将模型拆分为“门控网络+多个专家子网络”,输入数据经门控网络分配给1-2个最相关的专家(其他专家不激活),实现“大模型容量+小计算成本”
企业案例:AI聊天机器人的MoE架构
- 场景:某AI公司训练千亿参数对话模型,全量激活时单卡显存需200GB(远超A100的80GB),推理延迟>5秒(用户体验差)
- 方案:采用MoE架构(16个专家子网络,门控网络动态路由),每次仅激活2个专家
- 效果:单卡显存占用降至40GB,推理延迟缩短至1.2秒,模型容量保持千亿级(专家总数16×60亿参数),对话流畅度评分提升18%
②、Adapter:大模型“即插即用”微调
原理:在预训练大模型(如BERT)的每层插入少量“适配器参数”(仅占原模型1-5%),冻结原模型参数,仅训练适配器
低成本适配新任务(如用预训练BERT微调电商评论分类,无需从头训练)
企业案例:多语言客服系统的Adapter微调
- 场景:某跨境电商用mBERT(多语言BERT)做客服意图识别(支持英/法/西语),从头训练需1000 GPU小时,成本高
- 方案:冻结mBERT主体参数,在每层插入Adapter模块(每层仅加2万参数),用5000条标注数据微调适配器
- 效果:训练成本从1000→50 GPU小时,意图识别准确率保持92%(与原模型持平),支持新语言时仅需加对应语言的适配器(无需重新训练全模型)
五、训练过程加速
通过分布式、混合精度、梯度优化等手段,压缩训练时间,降低硬件成本(核心是企业降本增效)
①、ZeRO优化(Zero Redundancy Optimizer)
将模型参数、梯度、优化器状态分片存储到多卡(而非每张卡存完整副本),消除冗余显存占用(如8卡训练时,单卡显存占用降至1/8)
企业案例:千亿参数大模型训练的ZeRO-3
- 场景:某AI实验室训练1750亿参数GPT-3级模型,单卡显存需1TB(远超现有GPU),无法训练
- 方案:用DeepSpeed ZeRO-3(参数/梯度/优化器状态全分片)+ 64张A100 GPU(80GB显存/卡)
- 效果:单卡显存占用降至12GB,总训练时间从预计6个月→2个月,硬件成本节省60%
②、梯度检查点(Gradient Checkpointing)
训练中只保存部分层的激活值(而非全部),反向传播时重新计算未保存的激活值,牺牲少量计算时间换取显存大幅节省
企业案例:视频理解模型的梯度检查点
- 场景:某视频公司用3D CNN训练“短视频内容分类模型”(输入为32帧视频片段),单卡显存需60GB(模型+激活值),无法加载
- 方案:启用梯度检查点(每4层保存一次激活值,其余反向传播时重算)
- 效果:显存占用降至25GB,模型成功在单卡V100(32GB)上训练,训练速度仅下降15%(可接受)
六、其他
①、早停(Early Stopping)
监控验证集指标(如Loss、Accuracy),若连续N轮无提升,则停止训练(防止过拟合+节省时间)
企业案例:广告CTR模型的早停策略
- 场景:某广告公司训练CTR模型,原训练50轮,后期验证集AUC不再提升(甚至下降),浪费算力
- 方案:设置早停(耐心=5轮,监控验证集AUC),当AUC连续5轮不升时停止
- 效果:平均训练轮次从50→32轮,单模型训练成本降低36%
②、知识蒸馏(Knowledge Distillation)
用“大模型(教师)”输出的软标签(如各类别概率分布)训练“小模型(学生)”,让学生模仿教师的“思考过程”,实现“小模型大智慧”
企业案例:移动端OCR模型的知识蒸馏
- 场景:某公司需在手机端部署OCR模型(识别身份证号),大模型(ResNet-101)精度95%但体积200MB(手机存储/速度不允许),小模型(MobileNet)体积10MB但精度仅85%
- 方案:用知识蒸馏(教师ResNet-101输出软标签,学生MobileNet学习),损失函数=学生Loss+蒸馏Loss(模仿教师输出)
- 效果:学生模型精度提升至92%,体积保持10MB,手机端识别速度<0.5秒(满足实时性)
五、模型评估迭代
①、自动化评测基准
- 通用能力:MMLU(57任务)、Big-Bench Hard
- 语言能力:GLUE、SuperGLUE
- 推理能力:GSM8K(数学)、HumanEval(代码)
②、人工评估
- 人类偏好评分(如MT-Bench对话质量评估)
- 安全性测试(对抗样本攻击)
③、持续迭代
分析错误案例 → 调整数据分布/模型结构 → 增量训练
六、部署与推理优化
①、模型压缩
量化:FP16→INT8/INT4(AWQ、GPTQ算法)
剪枝:移除冗余神经元(稀疏化训练)
蒸馏:用小模型模仿大模型输出(DistilBERT)
②、高效推理引擎
框架:vLLM(PagedAttention)、TensorRT-LLM
动态批处理(Dynamic Batching)提升吞吐量
七、伦理与安全对齐
①、对齐训练
监督微调(SFT):人工标注高质量指令数据
强化学习从人类反馈(RLHF):PPO算法优化奖励模型
宪法AI:规则约束生成内容(Anthropic方法)
②、安全机制
内容过滤:分类器拦截有害输出
不确定性校准:置信度阈值控制响应
传统业务系统集成:Java/C#/Go等为主
传统企业的核心业务系统(如ERP、CRM、生产管理系统)多采用Java(Spring生态)、C#(.NET)或Go开发,大模型需通过API接口或微服务与现有系统集成:
轻量级调用:通过HTTP API调用第三方大模型(如OpenAI API、阿里通义千问),或在本地部署开源模型(如LLaMA系列),封装为RESTful服务供Java系统调用
方案一:通过HTTP API调用第三方大模型 (如 OpenAI, 通义千问)
①、设计RESTful API
- Endpoint: POST /api/v1/{provider}/completions或 /api/v1/{provider}/chat/completions(区分提供商和任务类型)
- Request Body
{
"model": "gpt-3.5-turbo", // 或 "qwen-turbo"
"messages": [{"role": "user", "content": "解释一下量子计算"}], // Chat格式
// 或 "prompt": "解释一下量子计算", // Completion格式
"max_tokens": 500,
"temperature": 0.7,
"top_p": 1.0,
"n": 1,
"stream": false,
"stop": null,
"presence_penalty": 0,
"frequency_penalty": 0
}
- Response Body
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "量子计算是一种..." //choices[0].message.content生成的文本内容
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 150,
"total_tokens": 170
}
}
②、安全与配置管理
API Key存储: 绝对不要硬编码!使用:
- 云平台密钥管理服务 (AWS Secrets Manager, Azure Key Vault, GCP Secret Manager)
- 专用配置中心 (HashiCorp Vault, Spring Cloud Config Server)
- 环境变量 (相对简单,但管理不如前两者精细)
访问控制: 在网关层实现API Key或JWT/OAuth2认证,确保只有授权的内部服务可以调用
输入过滤: 在网关层对用户输入进行初步过滤(长度、敏感词),避免无效调用或潜在滥用
输出过滤 (可选): 根据企业政策,对模型输出进行敏感信息过滤或不适当内容检测
方案二:本地部署开源模型 (如 LLaMA, Mistral, Falcon) 封装服务
①、模型选择与获取
- 模型系列: LLaMA (及衍生版 Alpaca, Vicuna), Mistral, Falcon, MPT, Baichuan 等。注意许可证 (LLaMA要求申请)
- 量化: 使用量化模型 (GGUF, GPTQ, AWQ) 显著降低显存需求,提升推理速度
- 来源: Hugging Face Hub, ModelScope (国内), 官方发布渠道
②、部署模型推理服务器
- vLLM: 高性能,PagedAttention优化显存,支持连续批处理(Continuous Batching),吞吐量大。提供OpenAI兼容API
- Text Generation Inference (TGI): Hugging Face出品,支持流式输出、批处理、张量并行、量化。提供类似OpenAI的API
- FastChat: 支持多种模型,提供OpenAI兼容API和Web UI
- llama.cpp: 轻量级C++实现,支持GGUF格式和CPU/GPU混合推理,适合边缘设备或资源受限环境。可通过Python绑定或HTTP封装提供服务
- Hugging Face transformers+ api-inference: 官方库,灵活性高,性能需自行优化
③、创建模型网关服务
④、设计RESTful API
深度集成:若需高性能(如实时对话),可将大模型推理引擎(如vLLM、TGI)封装为Java可调用的SDK(通过JNI或gRPC);或通过消息队列(Kafka)实现异步交互(如客服系统接收用户问题→推送至大模型服务→返回结果)
方案一:封装推理引擎为Java SDK(gRPC/JNI)—— 面向实时高性能场景
①、将大模型推理引擎(如vLLM、TGI)作为独立服务部署,通过其原生高性能接口(如gRPC)暴露推理能力
②、Java封装为SDK(或直接集成gRPC客户端)实现低延迟调用
优先选gRPC(跨语言支持好、生态成熟、比JNI更易维护),JNI仅在对极致性能有苛刻要求且团队具备C++/Java混合开发能力时考虑
方案二:消息队列异步交互(Kafka)—— 面向高并发、解耦与复杂流程场景
①、Java系统将请求(用户问题)作为消息推送到Kafka Topic
②、大模型推理服务(消费者)异步消费并处理,结果通过另一Topic或回调返回

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)