大模型推理中 IRQ 中断优化:从机制解析到性能调优实践
摘要:本文深入分析了大模型推理场景中IRQ中断分配对系统性能的影响。首先解析了中断机制的工作原理及其与NPU设备的交互特性,指出中断处理可能成为计算瓶颈。其次揭示了irqbalance服务的调度机制及其在大模型场景的局限性,包括调度目标不匹配、调整周期冲突等问题。最后提供了一套完整的NPU中断识别与分析方法,包括设备总线ID获取、中断映射建立以及实时监控脚本,为后续中断优化提供数据基础。研究表明,
在大模型推理场景中,系统性能瓶颈的排查往往需要深入到硬件与软件交互的底层细节。HostBound问题作为常见的性能障碍,其诱因复杂多样,其中IRQ中断的不合理分配是容易被忽视的关键因素。下面我将系统剖析中断机制的工作原理,详解irqbalance服务的调度策略,并通过实测数据验证中断绑核对大模型推理性能的影响,最终提供一套可落地的中断优化方案。
一、中断机制与大模型推理的性能关联
现代计算机系统中,中断机制是硬件与软件协同工作的核心技术。外围设备通过中断信号打破 CPU 正常执行流程以处理紧急事件,这在提升系统响应速度的同时,可能成为高性能计算场景的潜在瓶颈。
1.1 硬件中断的工作原理
中断是一种异步信号处理机制,当特定事件(如网络数据包到达、存储设备 IO 完成等)触发时,硬件设备通过中断控制器向 CPU 发送信号。CPU 会暂停当前任务、保存上下文,转去执行中断处理程序(ISR),完成后再恢复原任务。
在大模型推理中,NPU 与 CPU 交互频繁:Host 侧下发算子至设备队列时,底层驱动产生sq_send_trigger_irq中断;算子执行完成后,触发cq_update_irq中断。这些中断的处理效率直接影响推理流畅度,每一次中断都会使 CPU 暂时放下计算工作,可能造成显著性能波动。
1.2 中断管理的内核实现
Linux 内核通过中断号(IRQ ID)管理各类中断。设备驱动注册中断处理程序时,内核分配唯一 IRQ ID,并维护包含中断源、触发方式、处理函数等信息的映射表,可通过/proc/interrupts文件查看(记录各 IRQ ID 在不同 CPU 核心的触发次数)。
NPU 设备的中断信息在/proc/interrupts中特征如下:
- 中断控制器多为 ITS-MSI(PCIe 设备的消息信号中断)
- 触发方式以 Edge(边沿触发)为主,适用于高频事件快速响应
- 中断源名称含
devdrv_load_irq、sq_send_trigger_irq等,关联 NPU 驱动核心操作
1.3 大模型场景的中断特殊性
与通用计算场景不同,大模型推理的以下特征使中断管理更关键:
- 高频率交互:单次推理可能涉及数万次算子下发与结果回收,对应同等数量级中断
- 严格时序要求:Transformer 解码过程对时间抖动敏感,频繁中断可能导致延迟剧增
- 资源密集型:推理任务占用大量 CPU 核心进行预处理与后处理,中断与计算的资源竞争更激烈
当中断处理与推理计算共享同一 CPU 核心时,中断的高优先级会导致计算任务被频繁打断,形成 “空泡” 时间(CPU 既未执行有效计算,也未完成中断处理),直接降低计算效率。
二、irqbalance服务的调度机制与局限性
为优化中断在多核心CPU上的分布,Linux系统引入了irqbalance服务。该服务通过动态调整中断与CPU核心的绑定关系,试图实现系统资源的均衡利用,但在大模型推理等特殊场景中,其默认策略可能适得其反。
2.1 irqbalance的核心功能
irqbalance是运行在用户态的守护进程,其核心工作流程包括:
- 数据采集:定期读取
/proc/interrupts文件,统计各IRQ ID在不同CPU核心的触发频率 - 负载评估:分析中断分布是否均衡,识别存在中断密集的"热点"CPU
- 动态调整:通过修改
/proc/irq/<IRQ ID>/smp_affinity文件,将中断重新分配到负载较轻的CPU核心
在默认配置下,irqbalance每10秒执行一次调整,其调度策略遵循两个原则:
- 优先将中断分配到与设备同NUMA节点的CPU核心,减少跨节点访问延迟
- 尽可能使各CPU核心的中断处理负载保持均衡,避免单点过载
对于普通服务器场景,这种策略能够有效提升系统整体响应速度,但在大模型推理等计算密集型场景中,却可能引发新的性能问题。
2.2 服务配置与管理方式
irqbalance的安装与启动方式因操作系统而异:
- Debian/Ubuntu系统:

- CentOS/RHEL/openEuler系统:

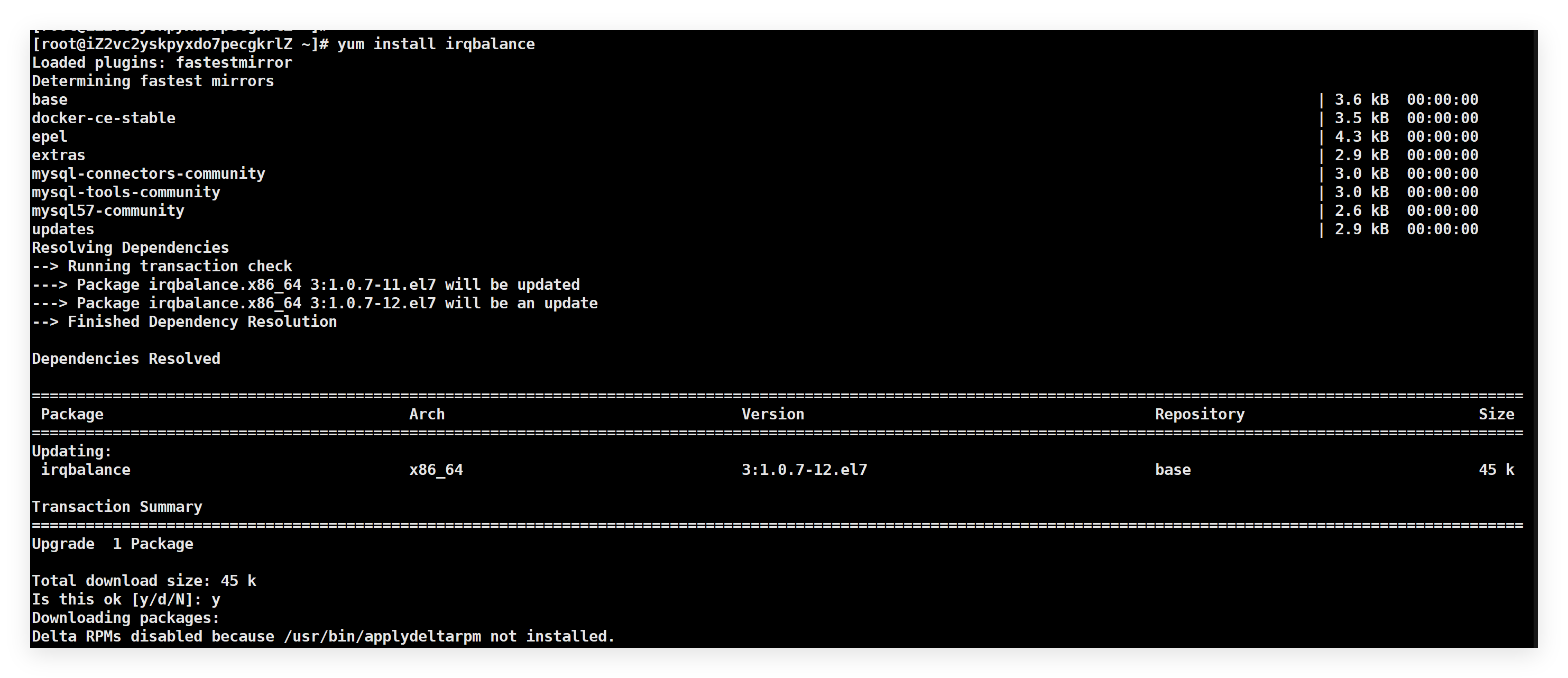
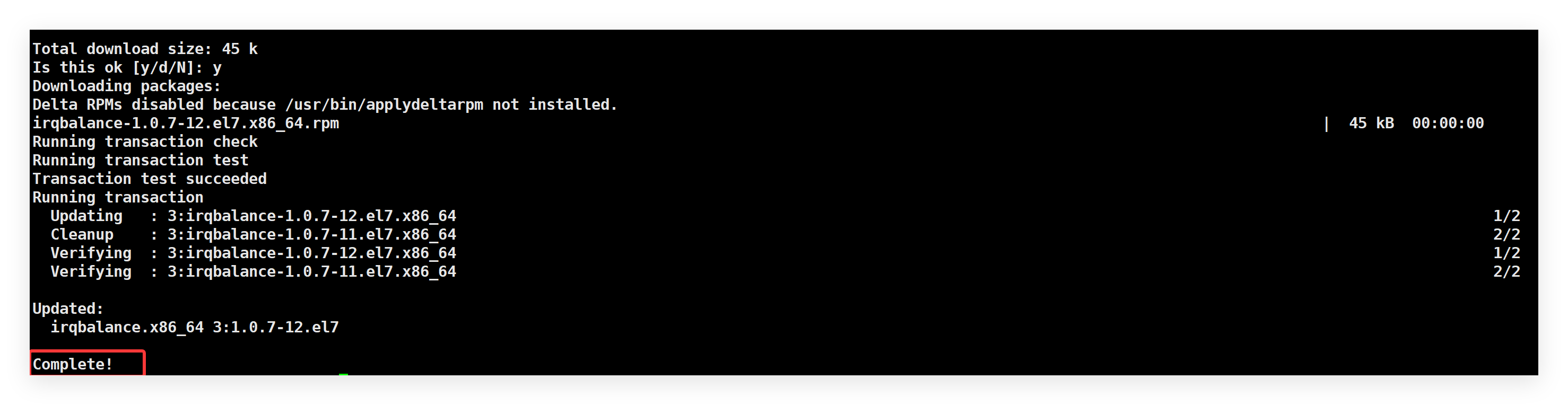

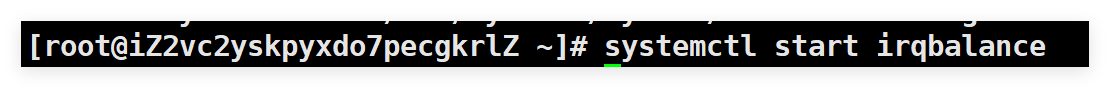
其核心配置文件位于/etc/sysconfig/irqbalance(RHEL系)或/etc/default/irqbalance(Debian系),通过修改配置参数可实现高级调度控制:
IRQBALANCE_BANNED_CPULIST:指定不参与中断分配的CPU核心列表IRQBALANCE_ARGS:通过命令行参数扩展功能,如--banirq禁止特定中断的自动调整
通过systemctl edit irqbalance命令可修改服务启动参数,例如将调整周期从默认10秒延长至300秒:
[Service]
ExecStart=
ExecStart=/usr/sbin/irqbalance --interval=300
2.3 大模型场景下的机制缺陷
irqbalance的设计目标是优化中断处理效率,而非为计算密集型任务让路,这导致其在大模型推理场景存在以下局限:
- 调度目标不匹配:irqbalance仅关注中断分布的均衡性,不考虑CPU核心上运行的任务类型,可能将高频中断分配到执行关键计算的核心上
- 调整周期冲突:默认10秒的调整周期与大模型推理的时间尺度不匹配,可能在一次推理过程中多次变更中断绑定,引入额外抖动
- NUMA感知不足:虽然考虑NUMA节点亲和性,但未区分计算任务与中断处理在NUMA内部的资源竞争关系
在800I平台(8卡A2-A+K架构)的测试中发现,当irqbalance将NPU中断随机分配到320个CPU核心时,约有30%的概率导致中断与推理任务核心重叠,此时推理延迟会增加15%-20%。
三、NPU中断的识别与分析方法
针对大模型推理场景的中断优化,首先需要准确识别与NPU相关的中断资源,建立中断与设备、CPU核心的映射关系,为后续调优提供数据基础。
3.1 设备与中断的关联映射
NPU设备的中断信息散落在系统日志与/proc文件系统中,需要通过以下步骤建立完整映射,以下为可直接落地的实操流程:
步骤1:获取设备总线ID(Bus ID)
- 执行
npu-smi info命令,筛选包含Bus ID的行:
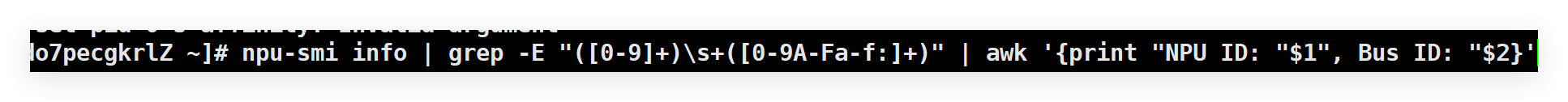
- 将结果记录到临时表格(可新建
npu_bus_id.csv):
NPU ID,Bus ID
0,0000:C1:00.0
1,0000:C2:00.0
2,0000:81:00.0
步骤2:追踪驱动注册日志,确定NPU注册顺序
- 过滤NPU驱动初始化日志,按时间戳排序:
dmesg | grep -i "devdrv_device_driver" | grep -E "([0-9A-Fa-f:]+)" | awk '{print $1" "$2" "$7" "$8}' | sort -n > npu_regist_order.log

- 结合Bus ID匹配注册顺序,生成映射:
# 读取Bus ID列表,匹配注册顺序
cat npu_bus_id.csv | grep -v "NPU ID" | while read line; do
npu_id=$(echo $line | cut -d, -f1)
bus_id=$(echo $line | cut -d, -f2 | tr 'A-F' 'a-f')
order=$(grep -n "$bus_id" npu_regist_order.log | cut -d: -f1)
echo "$npu_id,$bus_id,$order"
done >> npu_bus_order.csv
步骤3:提取中断起始ID(IRQ ID)
- 提取NPU中断起始IRQ ID,去重并排序:
grep "devdrv_load_irq" /proc/interrupts | cut -d: -f1 | awk '{print $1}' | sort -n > npu_irq_start_id.log
- 将IRQ ID与NPU ID关联(按注册顺序匹配):
# 读取注册顺序和IRQ ID,关联NPU ID
paste <(cat npu_bus_order.csv | sort -t, -k3) <(cat npu_irq_start_id.log) | awk -F, '{OFS=","; print $1,$2,$3,$4}' > npu_irq_mapping.csv
3.2 中断频率的量化分析
识别中断资源后,需量化分析中断频率及对推理性能的影响,以下为可直接执行的实操脚本与分析方法:
步骤1:实时监控中断频率(自动化脚本)
编写通用中断监控脚本(irq_monitor.sh),支持指定IRQ ID/监控时长/采样间隔:
#!/bin/bash
# 用法:./irq_monitor.sh <IRQ_ID> <采样间隔(秒)> <监控时长(秒)>
if [ $# -ne 3 ]; then
echo "用法:$0 <IRQ_ID> <INTERVAL> <DURATION>"
exit 1
fi
IRQ_ID=$1
INTERVAL=$2
DURATION=$3
END_TIME=$((SECONDS + DURATION))
# 初始化前一次计数
PREV_COUNT=$(grep "^$IRQ_ID:" /proc/interrupts | awk '{sum=0; for(i=2;i<=NF;i++) sum+=$i; print sum}')
echo "IRQ_ID,时间戳,总触发次数,每秒触发次数" > irq_${IRQ_ID}_stats.csv
while [ $SECONDS -lt $END_TIME ]; do
sleep $INTERVAL
CURRENT_COUNT=$(grep "^$IRQ_ID:" /proc/interrupts | awk '{sum=0; for(i=2;i<=NF;i++) sum+=$i; print sum}')
PER_SEC=$((CURRENT_COUNT - PREV_COUNT))
TIMESTAMP=$(date +"%Y-%m-%d %H:%M:%S")
echo "$IRQ_ID,$TIMESTAMP,$CURRENT_COUNT,$PER_SEC" >> irq_${IRQ_ID}_stats.csv
PREV_COUNT=$CURRENT_COUNT
echo "[$TIMESTAMP] IRQ $IRQ_ID: 每秒触发 $PER_SEC 次"
done
赋予执行权限并运行(以IRQ 1032为例,1秒采样,监控60秒):
chmod +x irq_monitor.sh
./irq_monitor.sh 1032 1 60
输出说明:实时打印中断频率,同时生成irq_1032_stats.csv,可用于后续可视化分析。
步骤2:推理负载关联分析(定位性能敏感中断)
准备推理测试脚本(infer_test.sh),以常见的大模型推理为例:
#!/bin/bash
# 启动推理任务并记录PID
python3 infer_demo.py > infer_log.log 2>&1 &
INFER_PID=$!
echo "推理任务PID: $INFER_PID"
# 并行启动多个中断监控(覆盖NPU主要中断)
IRQ_LIST=(2553 2554 2809 2810) # 替换为实际NPU中断ID
for irq in ${IRQ_LIST[@]}; do
./irq_monitor.sh $irq 1 300 > irq_${irq}_infer.log &
done
# 等待推理任务结束
wait $INFER_PID
echo "推理任务完成,中断监控日志已生成"
执行推理+中断监控:
chmod +x infer_test.sh
./infer_test.sh
分析中断频率与推理阶段的关联:
# 提取算子下发阶段的中断峰值
grep -A 10 "算子下发开始" infer_log.log | grep "时间戳" | awk '{print $2}' > infer_stage_time.log
for irq in ${IRQ_LIST[@]}; do
echo "IRQ $irq 算子下发阶段频率:"
grep -f infer_stage_time.log irq_${irq}_stats.csv | awk -F, '{print $4}' | sort -nr | head -5
done

四、中断绑核的优化实践与效果验证
针对大模型推理场景的中断优化,核心在于通过手动绑核实现计算任务与中断处理的资源隔离。
4.1 中断绑核的实施策略
中断绑核的核心思想是:将推理任务绑定到特定CPU核心,同时将高频NPU中断绑定到其他核心,实现资源隔离。具体实施步骤如下:
关闭irqbalance自动调整:为避免服务覆盖手动配置,先停止irqbalance服务:
systemctl stop irqbalance
systemctl disable irqbalance

对于需要保留部分自动调整功能的场景,可采用更精细的控制方式:
echo "IRQBALANCE_BANNED_CPULIST=\"10,11\"" >> /etc/sysconfig/irqbalance
echo "IRQBALANCE_ARGS=\"--banirq=1014,1271\"" >> /etc/sysconfig/irqbalance
systemctl restart irqbalance

确定绑核目标:根据NUMA拓扑,将推理任务与中断分别绑定到同NUMA节点的不同核心。例如在双路服务器中,可将NPU0的任务绑定到CPU10-15,对应的中断绑定到CPU20-25。
修改中断亲和性:通过smp_affinity文件设置中断的CPU亲和性,该文件使用十六进制掩码表示CPU核心:
# 将IRQ 1014绑定到CPU20(二进制10000000000000000000,十六进制0x100000)
echo 0x100000 > /proc/irq/1014/smp_affinity
对于连续的IRQ ID区间,可编写批量处理脚本:
#!/bin/bash
START_IRQ=1014
END_IRQ=1050
CPU_MASK=0x100000 # CPU20
for ((irq=$START_IRQ; irq<=$END_IRQ; irq++)); do
echo $CPU_MASK > /proc/irq/$irq/smp_affinity
done
绑定推理任务:通过环境变量或taskset命令将推理进程绑定到目标CPU:
taskset -c 10-11 python inference.py
export CPU_AFFINITY_CONF=1,npu0:10,npu1:11
4.2 实验结果与分析
实验数据显示,中断与任务的绑定关系对性能产生显著影响:
场景 1:算子与中断 “分核运行”(不在同核)
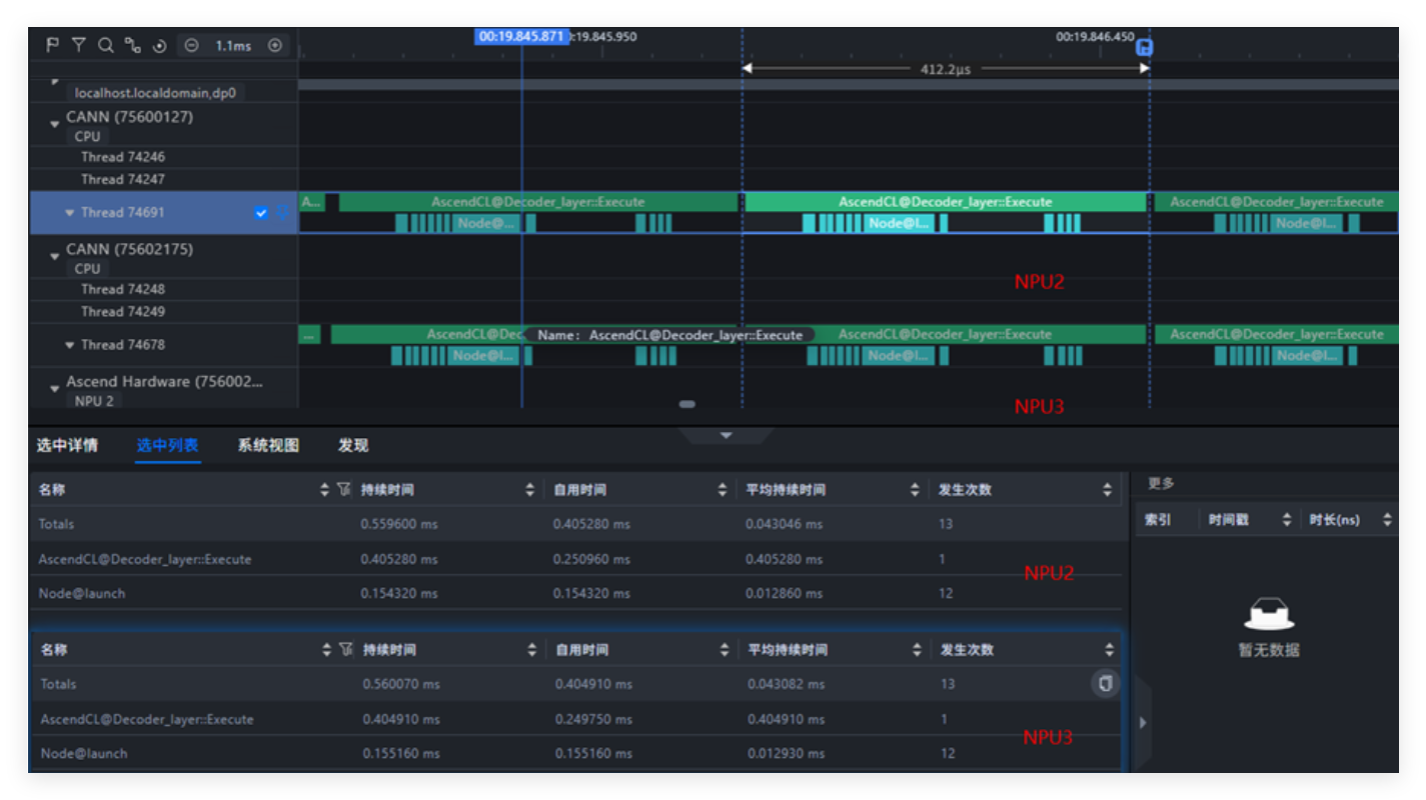
把中断和算子进程分别绑在不同的 CPU 核上,相当于 “各干各的活”。从 Profiling 的截图能看到:
- Node 启动(Node@launch)的时间很稳,没波动;
- CPU 的 “空闲空档”(气泡)很少,算力利用率高;
- 模型推理的耗时也很正常,各个阶段(比如 decode)的时间都比较稳定。
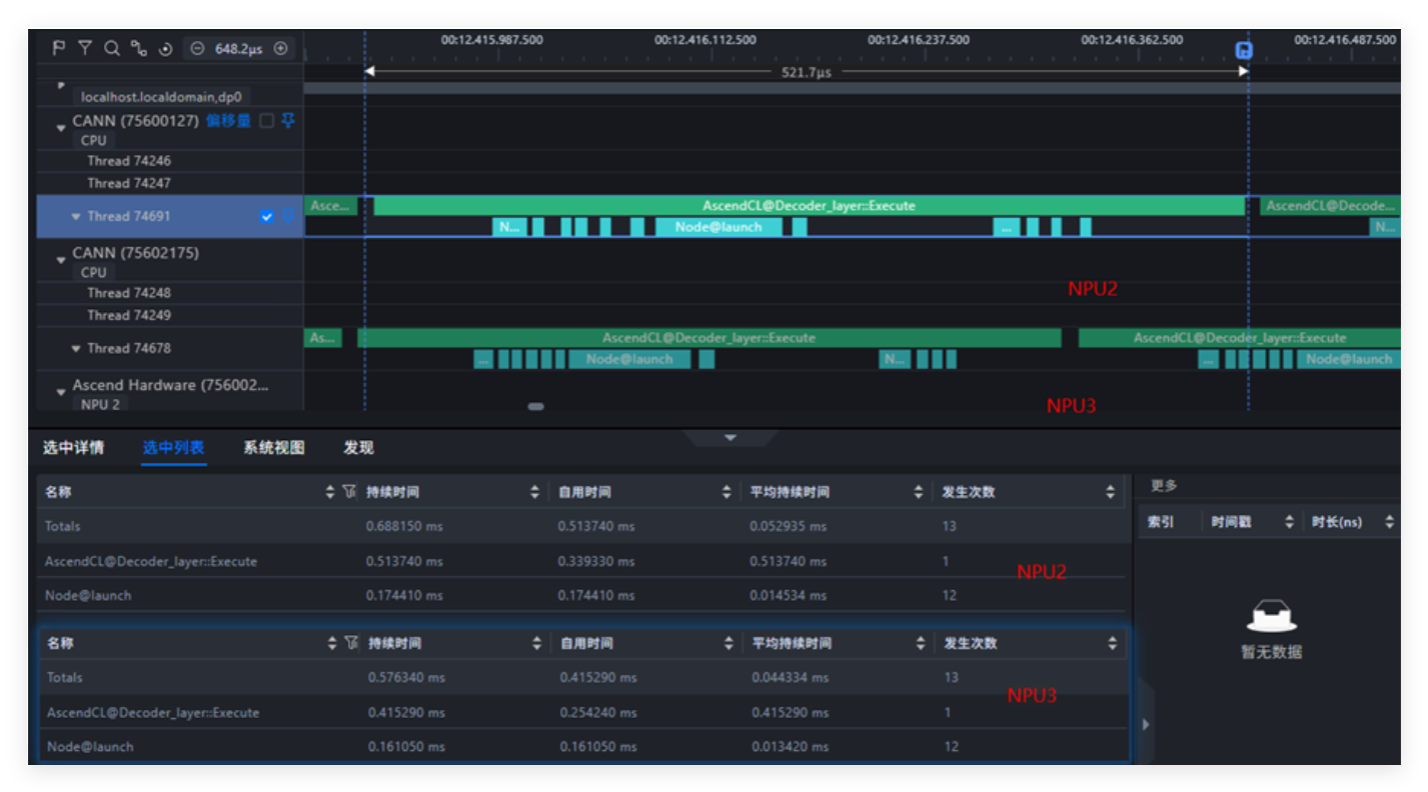
场景 2:算子与中断 “同核抢资源”(在同核)
硬把中断和算子进程都绑在 CPU10 这一个核上,相当于 “挤在同一张桌子干活”。Profiling 截图和数据直接反映出 “资源打架” 的问题:
- Node 启动时间明显变长了;
- CPU 气泡(空闲时段)肉眼可见地变多,算力浪费严重;
- 模型的 decode 阶段耗时直接拉长,推理效率下降;
- 中断频率离谱 —— 每秒能触发 2 万次以上。
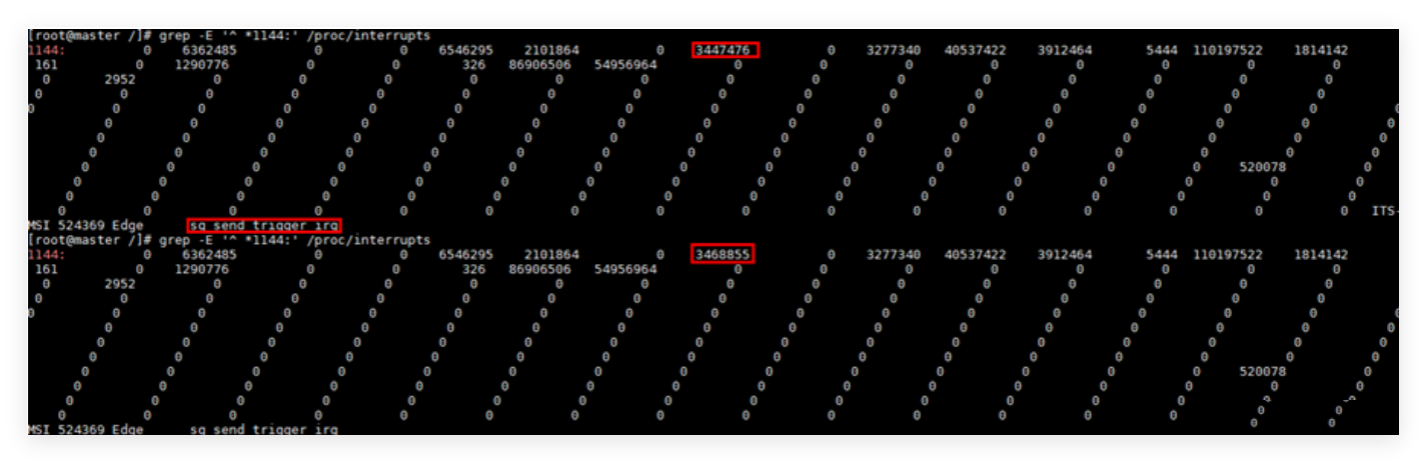
五、结论
irqbalance 服务的核心逻辑是基于 CPU 核上的中断密集程度进行动态分配,而不考虑该 CPU 核是否正在运行计算密集型任务。实验结果表明,当中断频率极高时(如大模型推理场景中每秒可达数万次),即便单次中断处理耗时仅为微秒级,仍会对同一 CPU 核上的推理任务产生显著干扰——通过 profiling 可观察到 CPU 侧“空泡”时间明显增加,单次 decode 耗时延长,最终导致整体推理性能下降。
因此,在大模型推理等计算密集型场景中,需通过中断绑核策略避免业务线程与高频中断共享 CPU 核。具体可通过以下方式优化:
- 识别 NPU 设备注册的高频中断(如
sq_send_trigger_irq、cq_update_irq),禁止 irqbalance 对其进行动态调整; - 手动将推理任务与高频中断绑定到不同的 CPU 核,且尽量保证二者处于同一 NUMA 节点以减少跨节点访问延迟;
- 对于简化配置场景,可直接通过
IRQBALANCE_BANNED_CPULIST限制中断分配范围,确保业务线程绑定的 CPU 核不被分配任何中断,由 irqbalance 管理剩余核的中断均衡。
通过上述措施,可有效减少中断对推理任务的频繁打断,降低 HostBound 问题发生概率,提升大模型推理的稳定性与效率。
注明:昇腾PAE案例库对本文写作亦有帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)