DeepSearchQA:填补深度研究代理全面性差距的基准测试
《DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents》
DeepSearchQA:填补深度研究代理全面性差距的基准测试
大家好!我是AI领域的爱好者,今天想和大家分享一篇来自Google DeepMind等团队的论文:《DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents》。这篇论文于2025年发布(注意,当前日期是2025年12月25日),它介绍了一个全新的基准测试——DeepSearchQA,旨在评估AI代理在复杂信息搜索任务上的表现。论文作者包括Nikita Gupta、Riju Chatterjee等多人,强调了当前AI代理在“全面性”方面的不足。如果你对AI代理、基准测试或信息检索感兴趣,这篇文章绝对值得一读。下面,我将重点介绍为什么创建这个基准、数据集是怎么构建的、它与其他基准的区别,以及一些其他亮点。

为什么创建DeepSearchQA?
在AI领域,大语言模型(LLM)正从静态工具向自主代理转型,这些代理能通过网络搜索、规划和工具使用来完成复杂任务。然而,现有的评估基准大多停留在“单答案检索”或“事实性检查”上,比如问“法国的首都是什么?”这样的简单问题。这导致了一个关键问题:全面性差距(Comprehensiveness Gap)。
论文指出,许多真实世界的信息搜索任务不是找一个答案,而是生成一个完整的答案列表。例如:“列出所有半导体公司中P/E比率低于20且在东南亚有业务的那些。”这类任务要求代理:
- 系统收集碎片信息:从多个来源拼凑完整列表,没有单一来源能覆盖全部。
- 实体解析和去重:识别相同实体(如不同表述的同一公司),避免重复或错误。
- 停止标准推理:在开放搜索空间中判断何时停止,避免过少检索(漏掉答案)或过多检索(添加无关项)。
当前基准忽略了这些,导致AI代理在实际应用中表现不佳,如过早停止或“对冲”行为(输出过多低置信答案来提升召回率)。DeepSearchQA的创建就是为了填补这个差距,推动AI代理向更robust的“深度研究”能力发展。它强调从精密检索转向全面答案生成,并提供一个客观、可验证的评估框架。
论文还提到,这是一个“代理革命”的时代,代理需处理长时规划和上下文保留。DeepSearchQA作为诊断工具,能揭示先进模型的局限性,并维持一个Kaggle上的实时排行榜,鼓励新模型提交。
与其他基准的区别
传统基准测试大多聚焦于单答案或事实性:
- 单答案验证:如TruthfulQA(2022)、HaluEval(2023)、FELM(2023),或SimpleQA(2025)、Facts(2025),这些适合评估事实准确性,但忽略了多步、全面检索。
- 长形式事实性:如FActScore(2023)、LongFact(2024b),需要人类验证或复杂评判,成本高。
- 代理导向基准:如Humanity’s Last Exam(HLE, 2025)、GAIA(2023)、BrowseComp(2025),虽引入专家级问题和动态搜索,但仍以单答案为主,便于客观评分。
- 实时基准:如FreshLLMs(2023)、RealTime QA(2024),关注原子答案,不捕获广义信息收集的复杂性。
DeepSearchQA的独特之处在于:
- 从单答案到集合答案:任务要求生成完整、可验证的答案集(如列表),而非单一数据点。
- 强调全面性和精确性权衡:使用F1分数(precision和recall的调和平均)作为主要指标,惩罚“对冲”或漏检。
- 因果链结构:每个任务是因果链,后一步依赖前一步,测试长时规划。
- 开放web grounding:所有任务基于真实网络,客观 verifiable,避免合成数据。
- 严格分类:响应分为完全正确、完全错误、部分正确、正确但有额外答案,突出失败模式如分类漂移或关联幻觉。
总之,DeepSearchQA不是“找针在 haystack”,而是“绘制完整地图”,更贴近真实用户需求,如流行分析或临床试验列表。

(上图是论文中Table 1的截图,展示了不同领域的代表性prompt示例,如流行游戏硬件分析。)
数据集是怎么构建的?
DeepSearchQA数据集包含900个prompt,每个配有ground-truth答案集。构建过程注重多样性和严谨性:
- 来源和 curation:由专家数据注解者手工制作,从各种真实用户查询中过滤,选择客观、信息搜索任务。避免主观或生成性问题,确保ground truth definitive。
- 领域分布:跨越17个领域,包括政治与政府(16.4%)、金融与经济(14.7%)、科学(10.0%)、健康(10.2%)、历史(10.0%)、地理(10.0%)、教育(4.7%)等。分布均衡(如图1所示),测试代理对不同web结构和内容的泛化。

- 时间锚定:所有prompt引用静态数据源(如“根据2020年人口普查……”),最小化web漂移。
- 答案类型:
- 单一答案:独特实体(如日期、名称),但需深度研究以处理模糊或冲突信息。
- 集合答案:枚举(列出所有匹配项)或复合(多子问题)。
- 质量验证协议:三阶段过程:
- 独立研究:三位审阅者独立搜索答案,无访问ground truth。
- 验证比较:与原curator的答案交叉参考。
- 冲突解决:解决分歧,更新ground truth或过滤模糊prompt。
- 任务复杂性分类(Table 2和3):
- 结构化检索(Search):多步策略,检索晦涩信息。
- 上下文管理(Assembly):处理大量信息,管理上下文窗口。
- 逻辑推理(Thinking):分析、合成、约束求解。
这个构建过程确保了数据集的多样性、难度和可靠性,总页数16页的论文详细描述了这些。
(上图是Figure 1的截图,展示了prompt类别的分布饼图。)
评估方法和结果亮点
评估采用信息检索标准:F1分数作为主要指标,结合precision和recall。分类包括完全正确(S = G)、完全错误(S ∩ G = ∅)等。使用LLM-as-Judge(Gemini 2.5 Flash)自动评估语义等价。
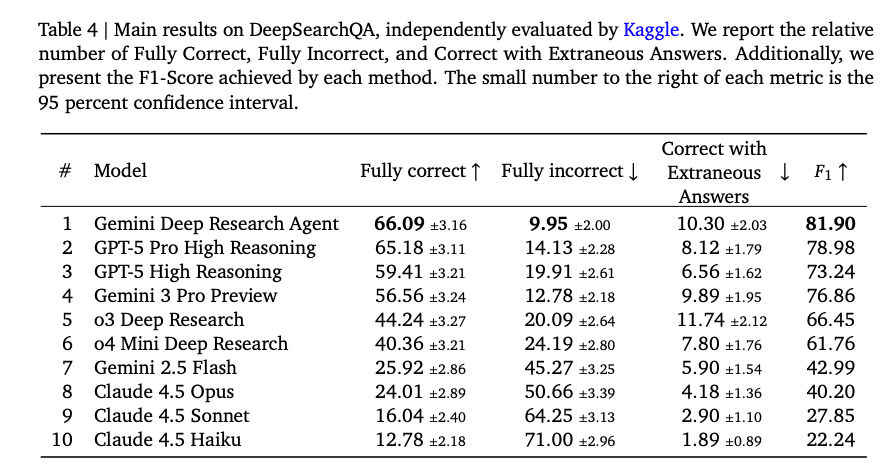
结果显示,即使顶级模型如Gemini Deep Research Agent(F1: 81.90%)和GPT-5 Pro High Reasoning(F1: 78.98%)也仅达到66%左右的完全正确率,暴露了过早停止或对冲问题。中层模型如o3 Deep Research迅速下降,强调了“推理阈值”的重要性。失败模式包括量化估计错误、工具调用限制和停止标准失败(Table 5)。
未来意义
论文讨论了局限(如黑盒评估、静态假设),并建议扩展如过程指标、动态列表。DeepSearchQA将推动代理架构创新,如系统探索策略和动态停止标准。
总之,这是一个推动AI代理从“回答问题”向“掌握主题”转型的里程碑。感兴趣的朋友可以访问Kaggle leaderboard:https://www.kaggle.com/benchmarks/google/dsqa/leaderboard。欢迎评论讨论你的看法!
(参考论文PDF:DeepSearchQA_benchmark_paper.pdf)
后记
2025年12月25日于上海,在grok 辅助下完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献227条内容
已为社区贡献227条内容

所有评论(0)