源码运行RagFlow并实现AI搜索(文搜文档、文搜图、视频理解)与自定义智能体(一)
RagFlow是一款开源的AI知识库构建与智能体编排工具,支持通过源码方式在本地运行。本文详细介绍了如何在Windows系统下通过WSL安装Ubuntu环境,并使用PyCharm配置RagFlow的开发环境。内容包括WSL安装步骤、RagFlow源码克隆、依赖安装(包括pipx、uv等工具),以及如何启动必要的中间件(MySQL、ElasticSearch等)。最后展示了如何运行RagFlow的后
0. RagFlow简介
众所周不知,RagFlow是由国内一家公司开源的一款软件,在AI知识库构建、智能体编排等场景中深受全球开发者的喜爱。
快速体验地址为:https://ragflow.io/
RagFlow的版本有开源版和商业版,我们在github上看到的RAGFlow就是开源版,如需在本地快速体验RAGFlow的功能,可根据官方提供的docker compose脚本快速启动它。
而如果要在它的基础上进行二次开发,使用RAGFlow的源码启动,则是我们这些开发人员所必须要掌握的。
在本文中,跟着笔者的步骤,我们可以快速了解如何使用源码方式运行RAGFlow,并通过几个示例快速领略一下RAGFlow的功能。
1.RagFlow源码启动(pycharm)
RagFlow的运行需要Linux系统,考虑到许多开发者使用的是Windows系统,这时我们就可以在Windows系统中通过安装wsl的方式来运行它。
1.1 wsl安装
wsl安装详细步骤如下:
- 安装wsl。打开powershell,运行:
wsl --install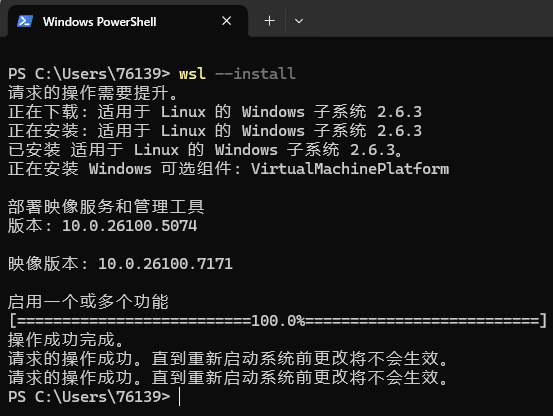
- 重启,再打开powershell,在wsl中安装ubuntu,运行:
wsl.exe --install ubuntu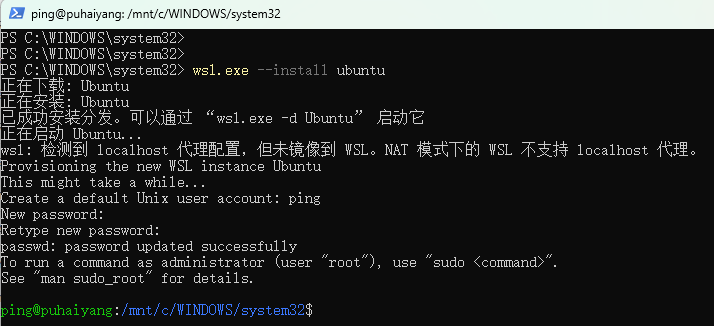
之后,在电脑中就会有一个Linux的图标,通过它就可以直接访问wsl的ubuntu系统目录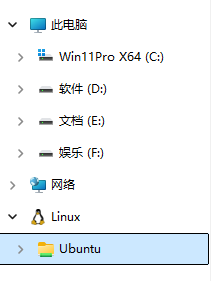
至此,wsl就已成功安装ubuntu系统成功了,需要注意的是它会默认安装到C盘。
1.2 RagFlow源码与依赖安装
在wsl中切换到用户目录,克隆代码。在wsl中输入以下命令:
注:为了避免后续不必要的麻烦,推荐在wsl系统中克隆代码
cd ~
git clone https://github.com/infiniflow/ragflow.git
目前的RagFlow提交非常活跃,为了稳定性,这里使用目前最新的v0.22.1版本
git checkout v0.22.1
如果由于网络克隆不了github的代码,可以尝试给系统配上网络代理。如:
export https_proxy=http://192.168.1.66:7078;
export http_proxy=http://192.168.1.66:7078;
export all_proxy=socks5://192.168.1.66:7078
笔者这里使用的IDE为PyCharm 2025.3.1。
点击 [文件] 中的 [远程开发],选择WSL实例中的Ubuntu,并指定刚刚clone的项目路径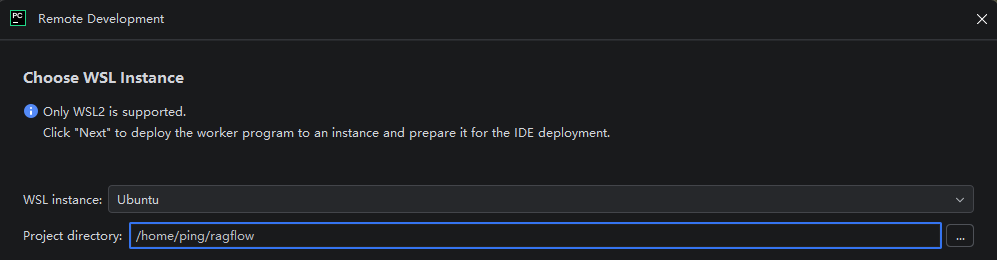
点击打开
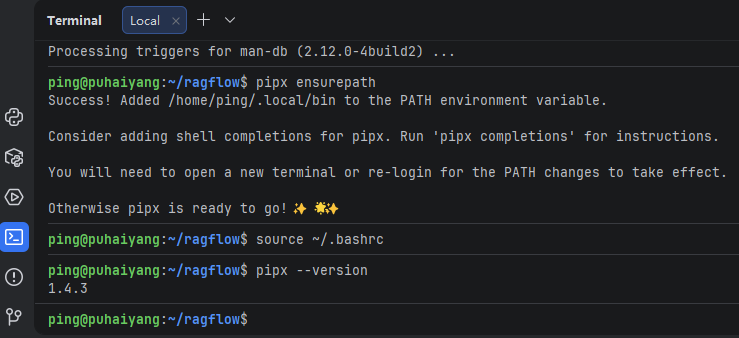
再输入以下命令安装pipx
sudo apt update
sudo apt install -y pipx
pipx ensurepath
source ~/.bashrc
pipx --version
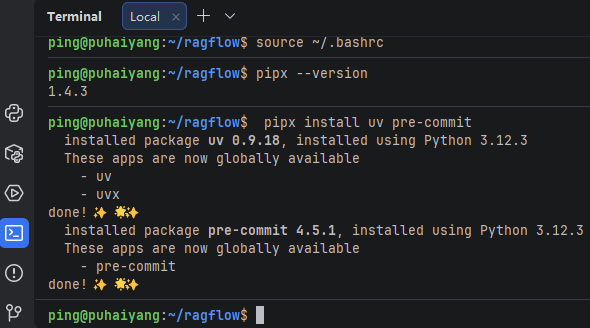
再安装ux和pre-commit:
pipx install uv pre-commit
再安装编译所需要的依赖库:
sudo apt install -y libicu-dev pkg-config build-essential python3.12-dev
uv安装好了后,再使用uv命令安装项目所需要的依赖:uv sync --python 3.12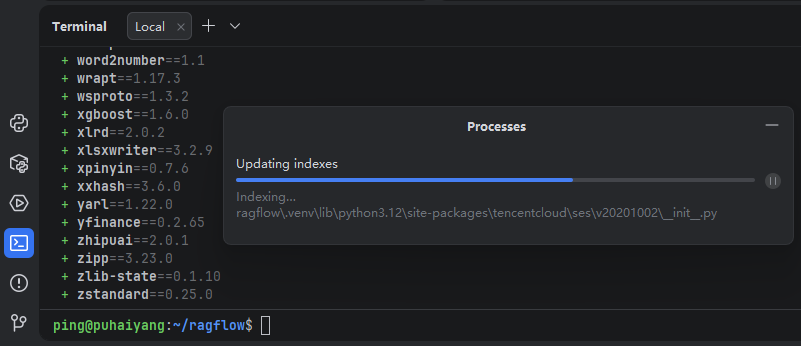
等uv的依赖安装完之后,在PyCharm里就会自动对依赖创建源码索引,这个过程根据电脑配置不同可能会花个几分钟。
1.3 RagFlow依赖组件启动
我们知道RagFlow不生产模型,它只是模型的搬运工,且RagFlow的运行还需要一些外部数据库和中间件:mysql、es、redis、MinIO。
上面几个中间件可以提前准备好,或直接使用RagFlow提供的docker compose脚本一键启动:
docker compose -f docker/docker-compose-base.yml up -d
为了不和RagFlow在同一台机器上,这里笔者在其他机器启动上面几个组件。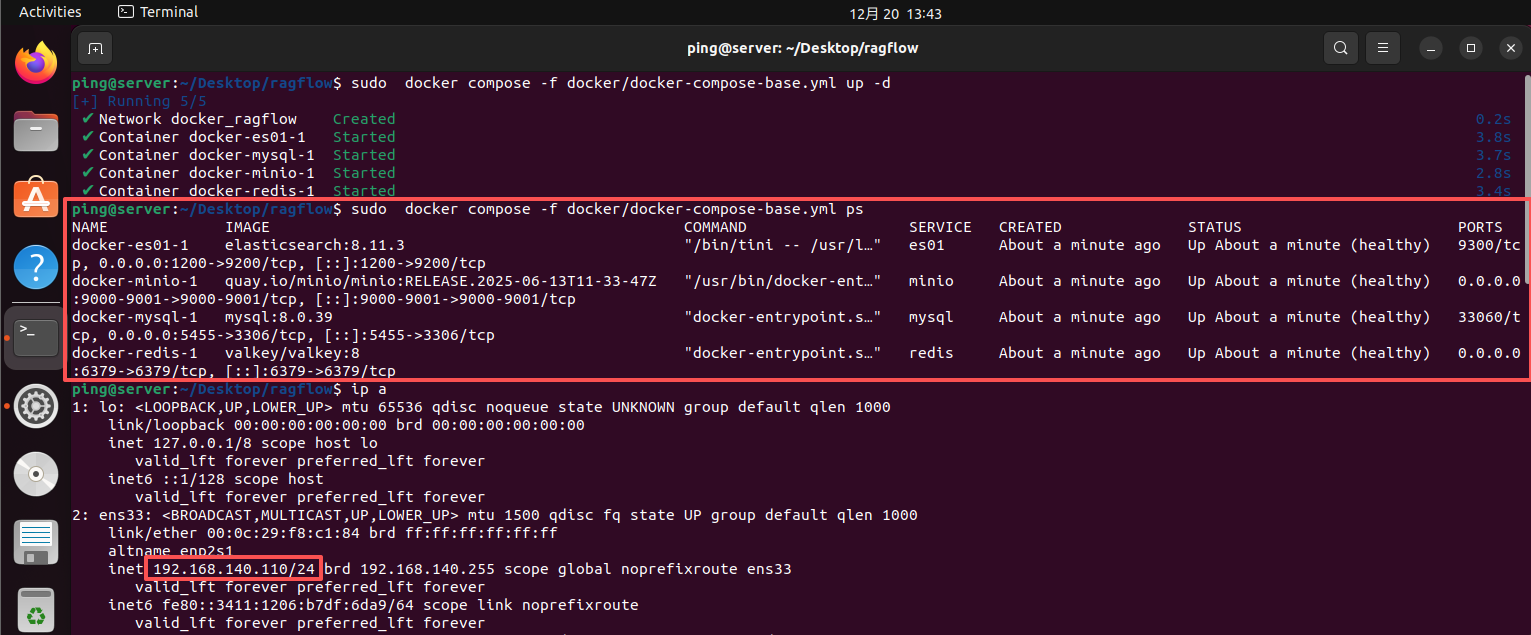
会占用的端口(tcp)及描述如下:
- 1200(映射的9200)。ElasticSearch,数据检索、向量存储
- 9000,9001。 MinIO,文件存储
- 5455(映射的3306)。Mysql,关系型数据库
- 6379。valkey(redis),内存KV数据库
我上面部署的节点ip都为192.168.140.110,所在还需要在wsl系统中将对应服务的域名映射都修改为192.168.140.110。(在RagFlow的docker/.env文件中均有体现)
sudo vi /etc/hosts
192.168.140.110 es01 mysql minio redis

1.4 RagFlow源码运行(后端)
通过前面的步骤,我们已经完成了RagFlow的依赖安装,之后就可以运行RagFlow了。
RagFlow需要运行的程序有以下3个:
- ragflow/api/ragflow_server.py,后端api接口,python运行
- ragflow/rag/svr/task_executor.py,后端task任务消费者,python运行
- ragflow/web,前端web界面,使用npm运行
后端程序可以参考docker/launch_backend_service.sh脚本启动。
为了后期开发过程中更方便的调试运行RagFlow,建议单独运行每个后端程序。
在PyCharm中运行python项目需要有一个python解释器,这里我们选择ragflow/.venv下的python程序: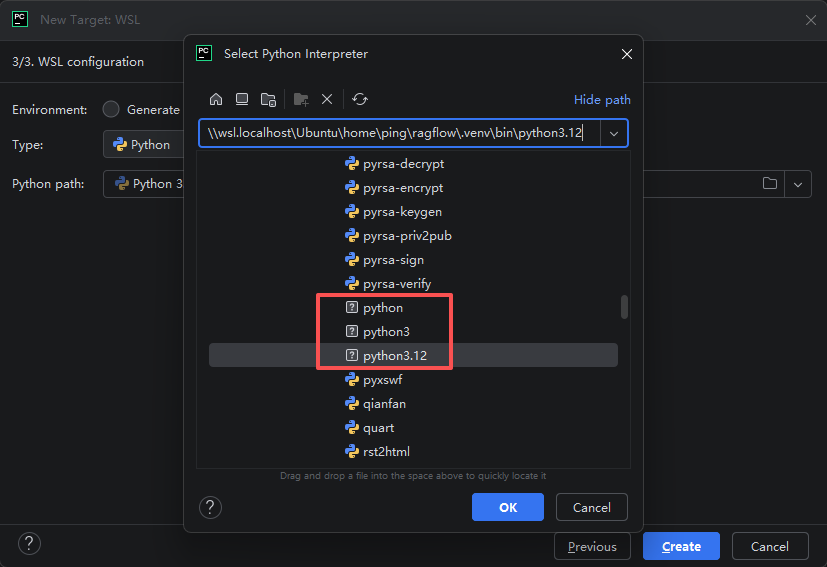
再打开python程序的运行配置框,在里面手动填入所需要的环境变量信息(ragflow/docker/.env)。
需要注意的是,PyCharm无法直接读取ragflow/docker/.env中的内容,为此我们可以单独写一个文件代替下,如写一个 .env_pycharm文件,内容为:
DOC_ENGINE=elasticsearch
NLTK_DATA="./nltk_data"
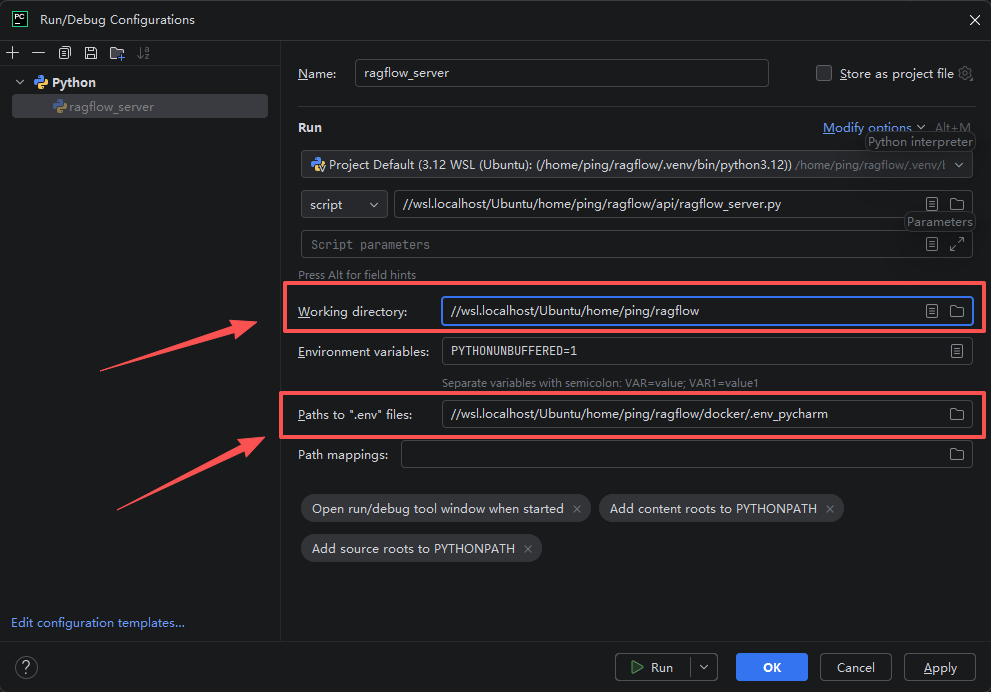
最后,再确保Working directory为代码根目录,.env文件为我们新创建的 .env_pycharm文件,之后点击运行: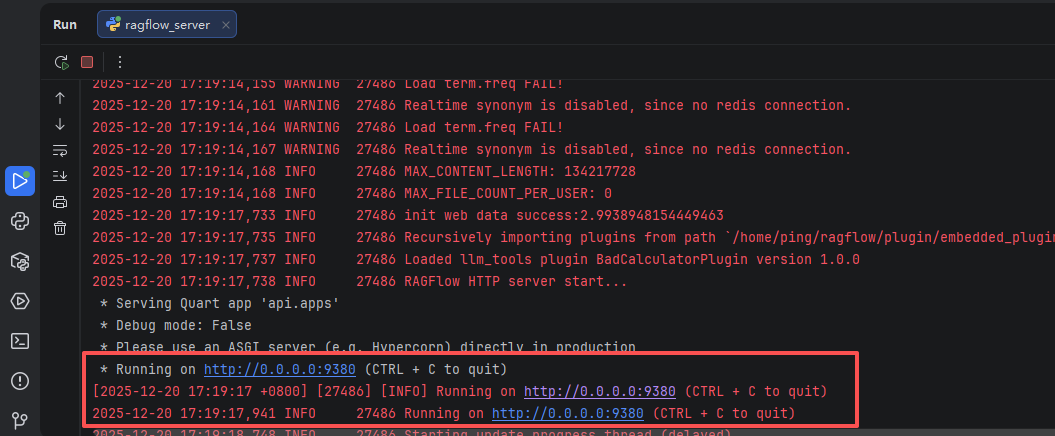
提示9380端口监听成功,就代表ragflow_server.py程序启动成功了。
curl试一下:
curl http://127.0.0.1:9380/

有json信息返回了,就代表测试成功了。
ragflow_server.py在任务提交时,会将所需要执行的任务写入到redis中,之后再由task_executor.py异步拉取待处理的任务并执行。
task_executor.py的启动方式与ragflow_server.py一样,这里不再复述。运行成功时,截图大致长这样: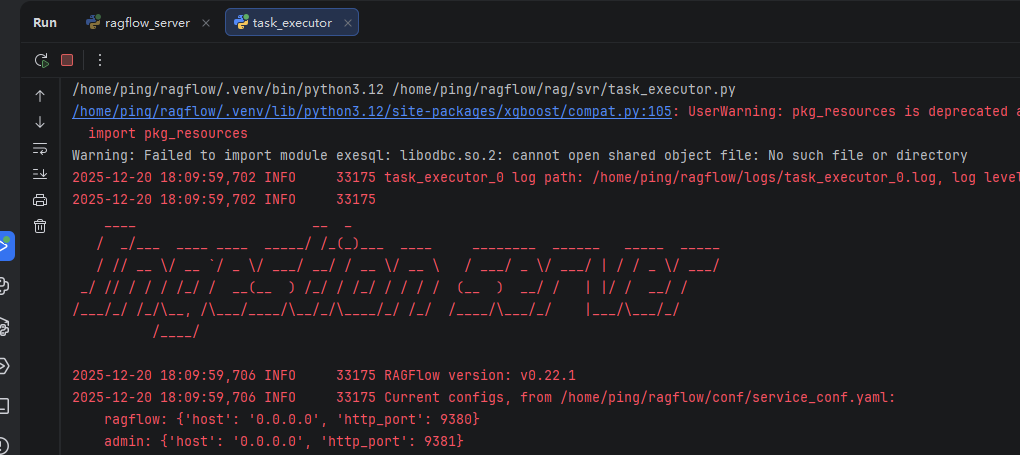
另:RagFlow的ragflow_server.py和task_executor.py这两个启动程序均会读取此配置文件ragflow/conf/service_conf.yaml,这里面会配置RagFlow所需要连接的中间件,我这里的配置内容如下:
ragflow:
host: 0.0.0.0
http_port: 9380
admin:
host: 0.0.0.0
http_port: 9381
mysql:
name: 'rag_flow'
user: 'root'
password: 'infini_rag_flow'
host: 'mysql'
port: 5455
max_connections: 900
stale_timeout: 300
max_allowed_packet: 1073741824
minio:
user: 'rag_flow'
password: 'infini_rag_flow'
host: 'minio:9000'
es:
hosts: 'http://es01:1200'
username: 'elastic'
password: 'infini_rag_flow'
redis:
db: 1
password: 'infini_rag_flow'
host: 'redis:6379'
task_executor:
message_queue_type: 'redis'
user_default_llm:
default_models:
embedding_model:
api_key: 'xxx'
base_url: 'http://localhost:6380'
1.5 RagFlow源码运行(前端)
上面我们运行了RagFlow的后端程序,并成功监听了9380端口,只有http接口没有web界面,接下来我们将web界面也运行起来。
切换到ragflow源码的web目录,依次运行以下命令安装前端项目所需要的依赖:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
source ~/.bashrc
nvm install 20
nvm use 20
node -v
npm install
执行npm run dev启动web项目:
export NODE_OPTIONS=“–max-old-space-size=4096”
npm run dev
执行完后,会有以下输出: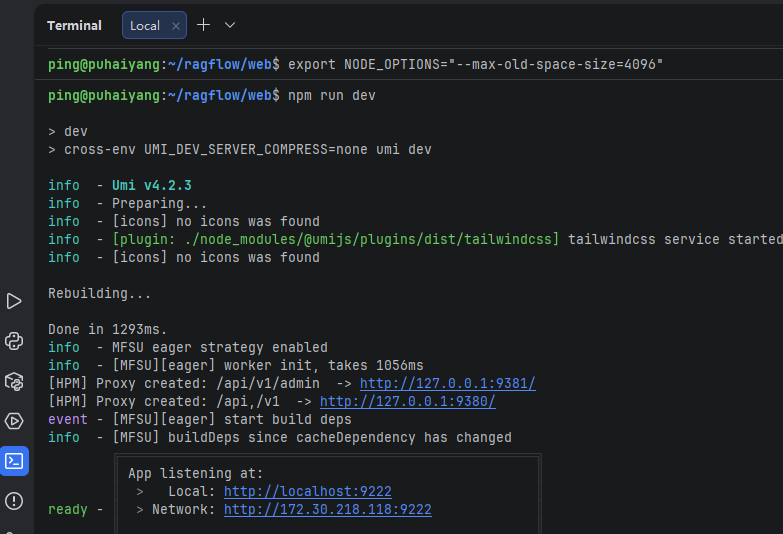
到这里,我们就可以在浏览器中访问RAGFlow了:http://localhost:9222
2. RAGFlow示例-文搜文档
如果仅想在本地运行RAGFlow,只需要切换到RAGFlow的docker目录,使用docker compose启动整个服务就可以了。命令为:
cd docker
docker compose -f docker-compose.yml up -d
之后输入对应的ip访问。比如我这里的:http://192.168.140.110/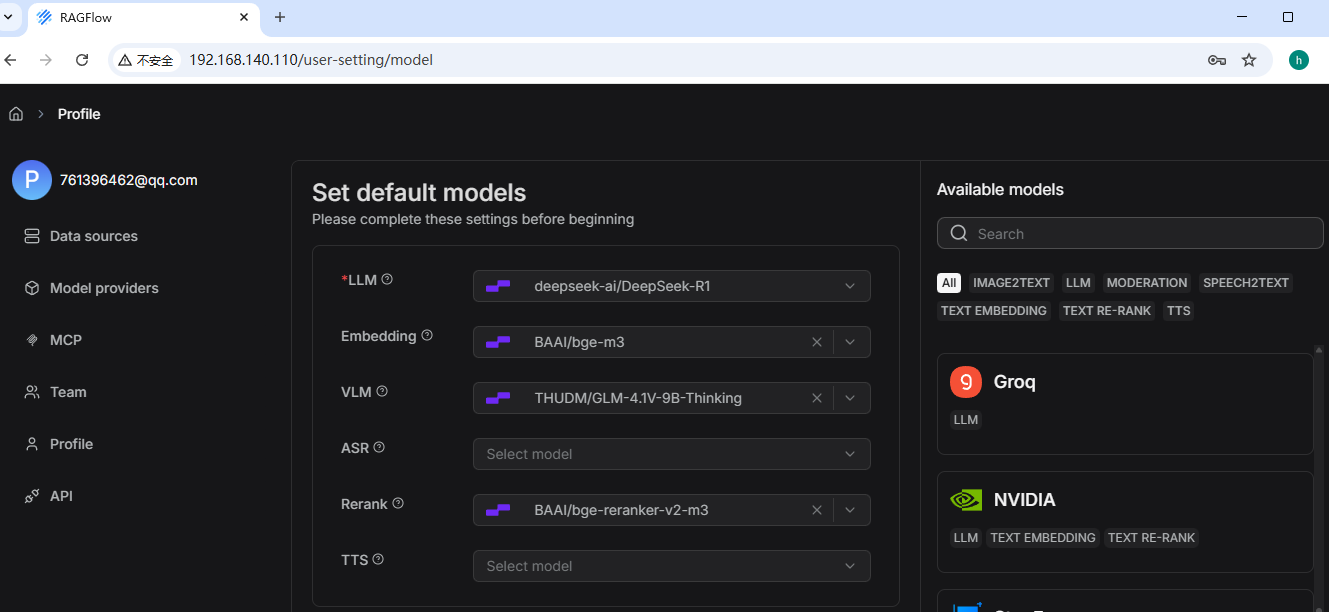
注册登录一个账号后,配置好默认的基础模型,我这里使用的是硅基流动平台提供的模型。
有了大模型的配置后,我们就可以体验RagFlow中的常用功能了。这里以先以RAG场景中常见的文档搜索为例,和大家一起体验下。
2.1 DeepDoc解析
在RAGFlow中默认的文档解析器为DeepDoc,是RAGFlow自研的解析器。同时,RAGFlow在启动时,也会自动加载DeepDoc相关的模型到系统中,可以在download_deps.py中看到这样的代码片段:
repos = [
"InfiniFlow/text_concat_xgb_v1.0", # 文本分块拼接决策模型(Chunk 合并/切分优化)
"InfiniFlow/deepdoc", # 复杂文档结构理解(Layout-aware 文档解析)
"InfiniFlow/huqie", # 胡切,中文文本智能切分(语义级切块)
]
本文中不对DeepDoc的实现细节详细展开,仅如何快速使用进行了解。
此处以大名鼎鼎的Transformer架构论文:《Attention Is All You Need》为例,试一下我们用RAGFlow可以如何检索这篇PDF文档。
首先,我们创建一个Dataset,并在其中上传《Attention Is All You Need》的PDF论文到其中,并点击解析按钮进行解析。
待解析完成后,再次点击文件,会弹出解析后的切片结果,截图如下: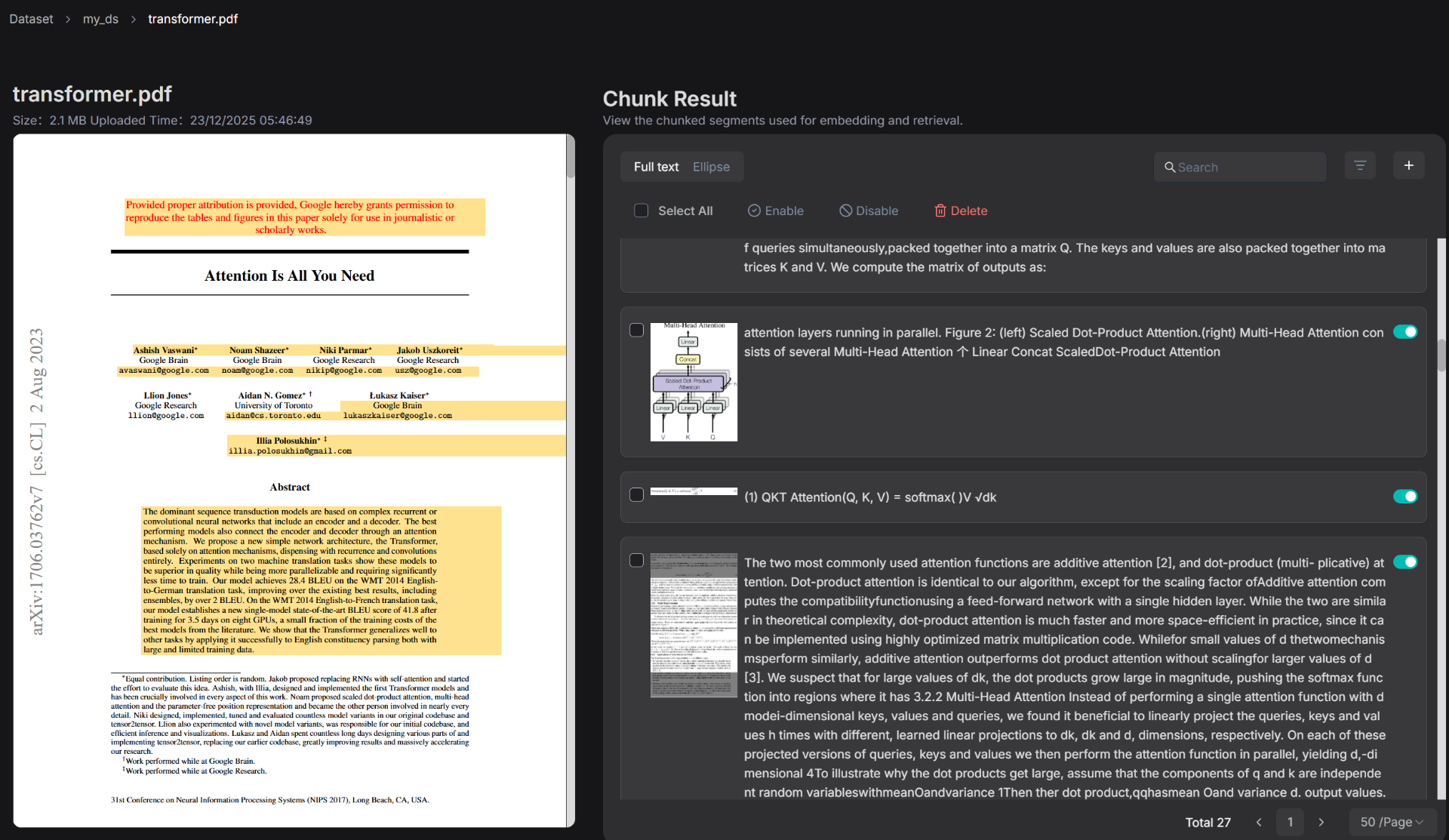
点击某一个切片(Chunk),RagFlow也允许我们对它进行内容的二次编辑,左边的原文黄色高亮部分也会体现出所对应的解析原文,这种UI界面的操作也正是RAGFlow的强大之处。来个截图: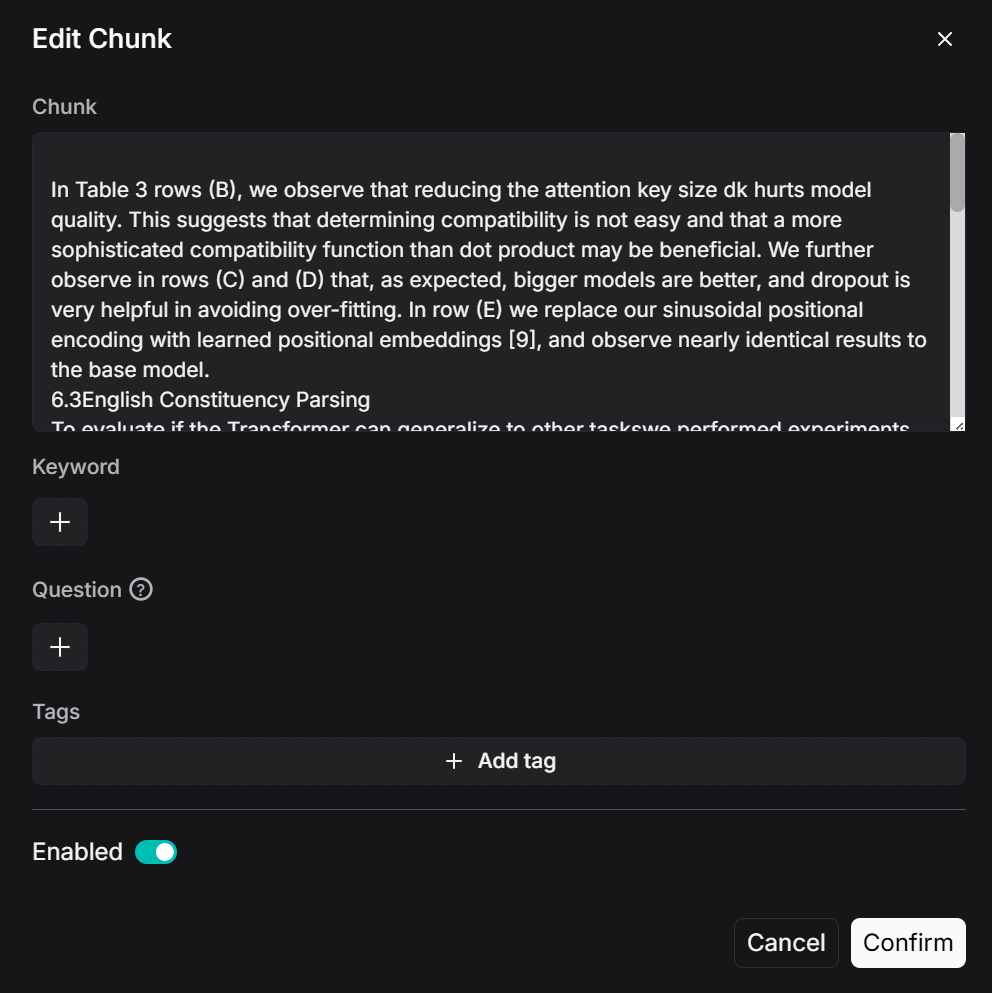
当RagFlow完成文档的解析切片后,我们便可以对它进行检索了。RagFlow中提供了多种方式可以让我们对文档搜索,可以直接用的有以下两种方式:
- Chat(LLM对话方式)
- Search(AI检索)
我们分别发起一个问题:什么是Transformer?
RagFlow的chat则会根据Transformer的文档切片内容进行LLM汇总概括。点击每一个 【小感叹号】 也会弹出对应的文档片段引用。
再试下将同样的问题发给RagFlow中的Search看一下效果: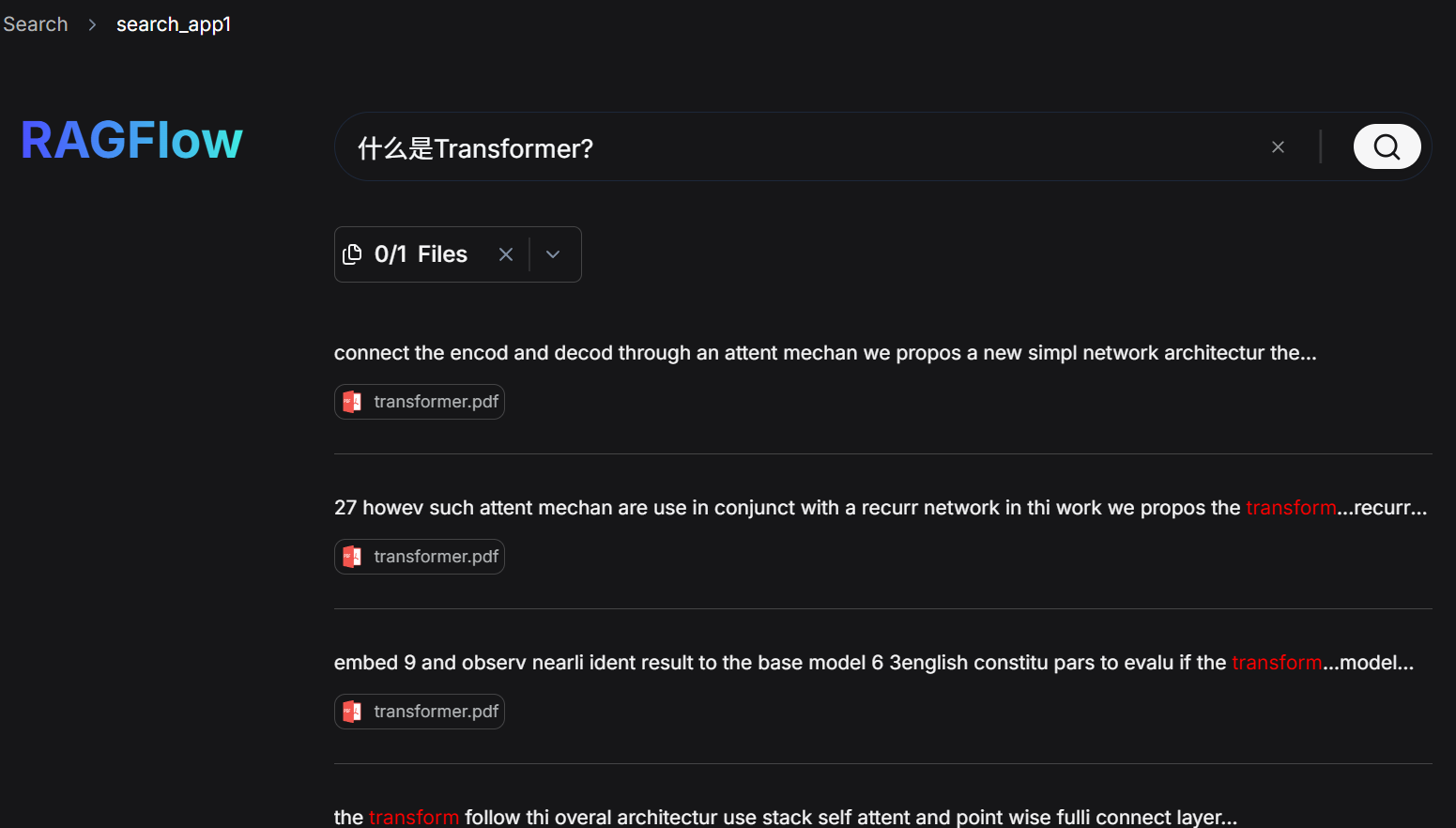
这部分则更像是文档搜索,它会列出对应的文档,以及搜索出来的top文档片段。
2.2 MinerU解析(api方式接口)
上面使用DeepDoc对文档处理时,对于某些公式提取的还不够完美,比如对于Attention(Q、K、V)的计算公式解析的还不够完善。DeepDoc解析结果截图如下: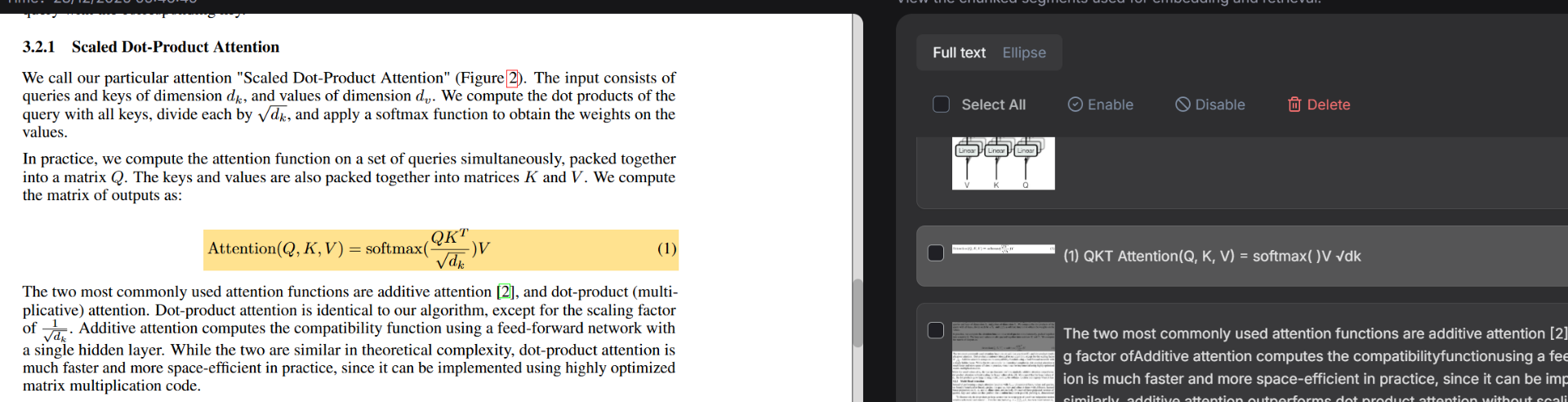
这时,我们就可以将RagFlow自带DeepDoc替换为MinerU,在RagFlow的官方文档中也提供了使用http接口的方式调用MinerU解析pdf文档的步骤,这里实践一下:
-
编译MinerU镜像。笔者这里以docker方式部署它,有gpu更佳(笔者这里没有用gpu仅有cpu,也能跑只是点有慢)
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@mineru-2.6.8-released/docker/china/Dockerfile
#CPU运行,使用FROM docker.m.daocloud.io/vllm/vllm-openai:v0.10.2,不使用v0.10.1.1
docker build -t mineru:latest -f Dockerfile .上面我所使用的MinerU版本为当前的最新版2.6.8。
2.启动MinerU。待上面的docker镜像打包完成,再输入以下命令启动MinerU:
docker run -d --name mineru \
--shm-size 32g \
-p 8000:8000 \
mineru:latest \
mineru-api --host 0.0.0.0 --port 8000
之后访问映射出来的地址,上面暴露的mineru的api端口是8000端口,我这里就访问对应的IP+Port:http://192.168.31.174:8000/docs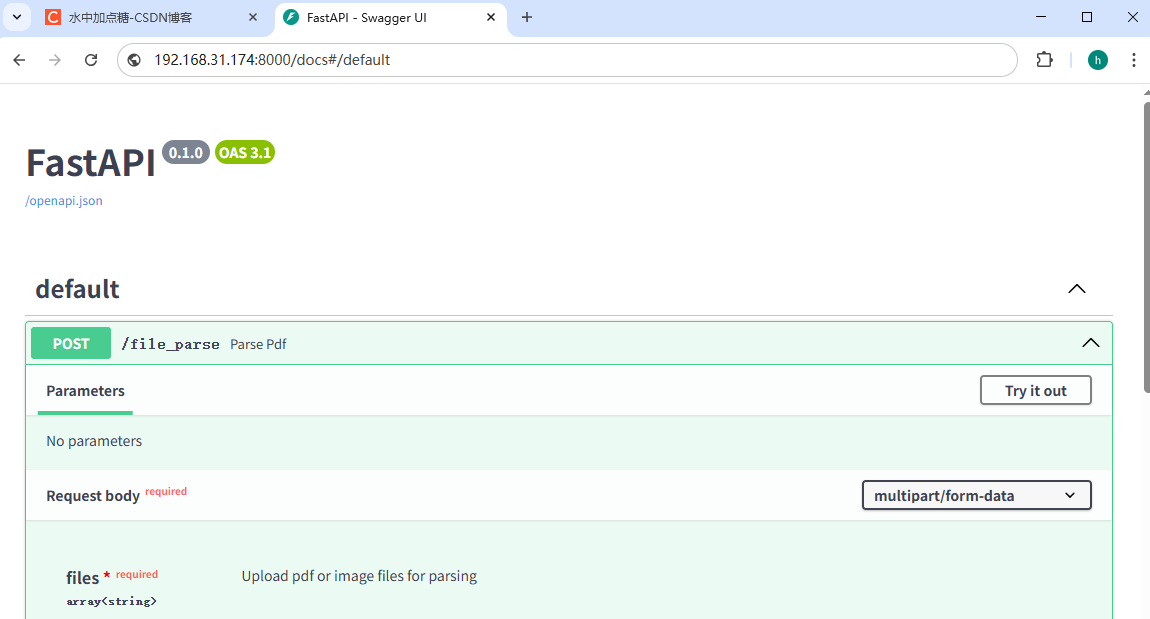
打开它,我们会发现,它其实是一个swagger的接口页面,我们也可以直接在此页面中进行接口验证对pdf文件进行解析。
- 集成到MinerU中。确保MinerU的http接口没问题后,接入RagFlow也很简单,仅需在ragflow/docker的 .evn 环境变量中加入一行配置:
MINERU_APISERVER=http://192.168.31.174:8000
也就是将上面部署的MinerU的api地址,再重启ragflow的docker compose,使其容器内的环境变量生效果,我们就可以使用MinerU来解析文档了。
再来RagFlow使用MinerU解析文档效果图: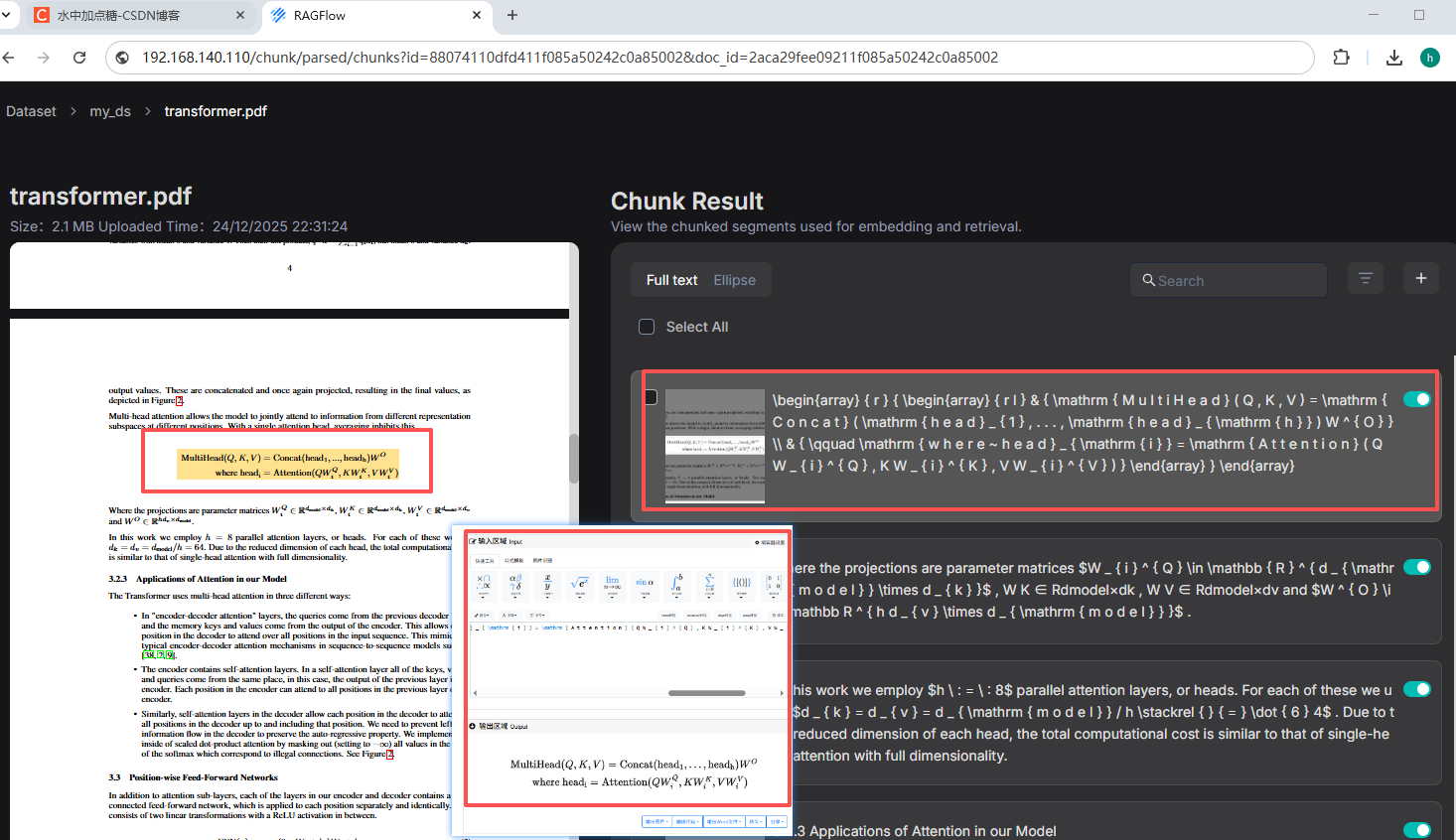
右边的解析公式结果为LaTeX格式,我们可以找一个在线LaTeX编辑器看效果。
在RagFlow调用MinerU的接口解析文档的时候,在MinerU的docker容器中也会有对应的日志输出。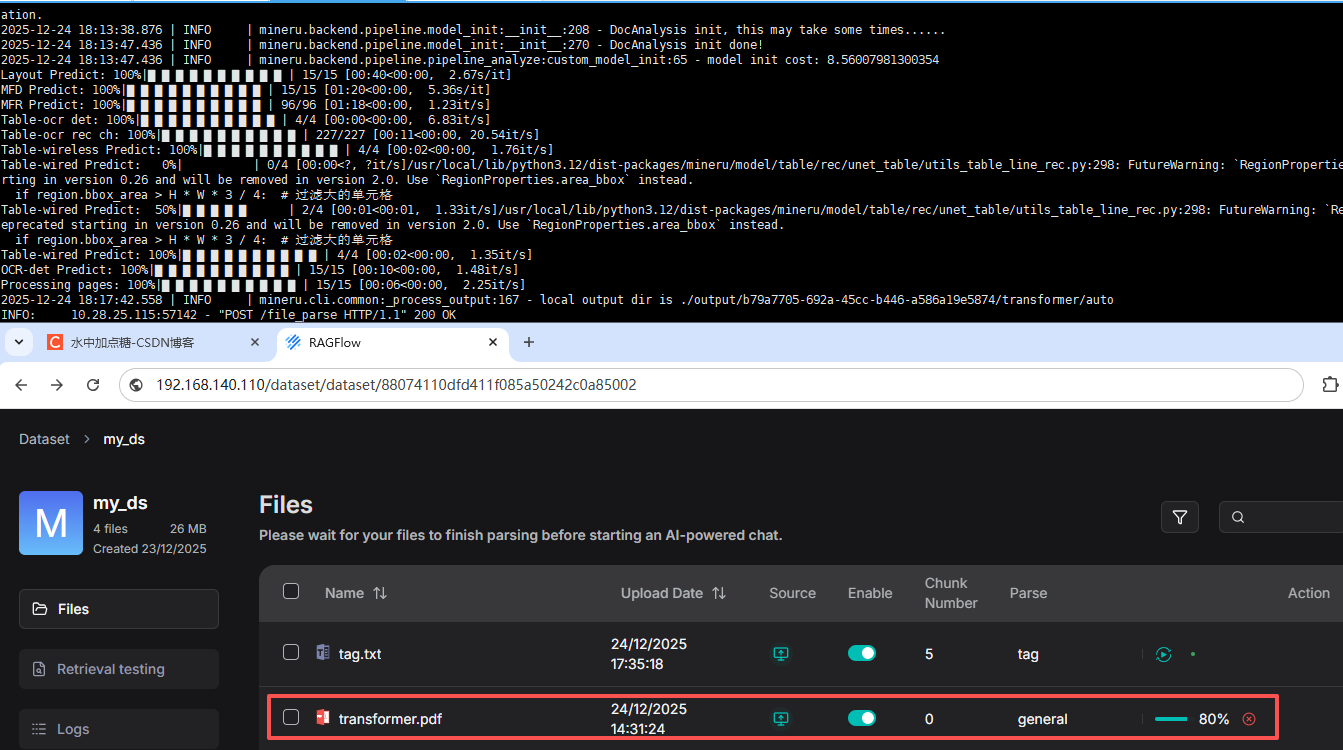
为了对比MinerU和DeepDoc在公式解析的差异,我们也可以访问MinerU官网上传对比一下。以下是我上传同一个PDF对公式解析的结果:
从公式解析的结果来看,MinerU的解析效果与原文相比不能说非常相似,只能说一模一样。
没有对比就没有伤害,强的可怕~。
更多关于MinerU接入RagFlow的详细配置,可参考:how-to-use-mineru-to-parse-pdf-documents。
3. RagFlow文搜图/视频/自定义智能体
一不小心,这篇文章就超篇幅了。后续关于文搜图/视频/自定义智能体这部分见我的另一篇文章。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)