【万字长文】深入解析生产级 Agentic AI 系统:七层架构详解与实际应用!
现代的 agentic AI systems(代理型 AI 系统),无论运行在 development、staging 还是 production 环境中,都应构建为一组职责明确的 architectural layers(架构层),而非单一服务。每一层分别负责 agent orchestration、memory management、security controls、scalability、
Service Layer、Middleware、Context Management 等
现代的 agentic AI systems(代理型 AI 系统),无论运行在 development、staging 还是 production 环境中,都应构建为一组职责明确的 architectural layers(架构层),而非单一服务。每一层分别负责 agent orchestration、memory management、security controls、scalability、fault handling 等具体关注点。一个面向生产的代理系统通常会组合这些层,以确保在真实工作负载下代理具备可靠性、可观测性与安全性。
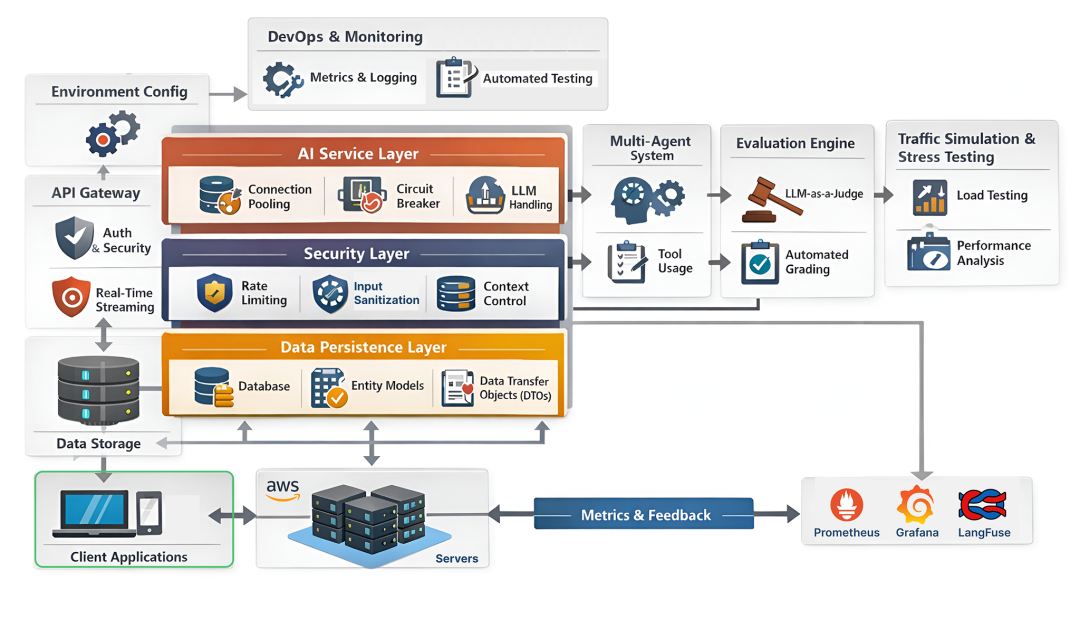
Production Grade Agentic System (Created by Fareed Khan)
在一个 agentic system 中,有两个关键方面需要持续监控:
- 第一是 agent behavior,包括推理准确性、工具调用正确性、记忆一致性、安全边界,以及在多轮交互与多代理间的上下文处理。
- 第二是 system reliability and performance,涵盖延迟、可用性、吞吐量、成本效率、故障恢复,以及整个架构中各依赖的健康状况。
两者对大规模可靠运行 multi-agent systems 同样重要。
在本文中,我们将搭建一个生产就绪的代理系统所需的核心架构各层,帮助团队自信地在自有基础设施或为客户部署 AI agents。
完整代码库在我的 GitHub 仓库:
https://github.com/FareedKhan-dev/production-grade-agentic-system
Creating Modular Codebase
通常 Python 项目从小做起,随着增长容易变得混乱。构建面向生产的系统时,开发者通常采用 Modular Architecture(模块化架构)方法。
这意味着将应用的不同组件拆分为独立模块。这样我们能更容易地维护、测试与更新各部分,而不影响整个系统。
让我们为这个 AI 系统创建一个结构化目录布局:
├── app/ # Main Application Source Code│ ├── api/ # API Route Handlers│ │ └── v1/ # Versioned API (v1 endpoints)│ ├── core/ # Core Application Config & Logic│ │ ├── langgraph/ # AI Agent / LangGraph Logic│ │ │ └── tools/ # Agent Tools (search, actions, etc.)│ │ └── prompts/ # AI System & Agent Prompts│ ├── models/ # Database Models (SQLModel)│ ├── schemas/ # Data Validation Schemas (Pydantic)│ ├── services/ # Business Logic Layer│ └── utils/ # Shared Helper Utilities├── evals/ # AI Evaluation Framework│ └── metrics/ # Evaluation Metrics & Criteria│ └── prompts/ # LLM-as-a-Judge Prompt Definitions├── grafana/ # Grafana Observability Configuration│ └── dashboards/ # Grafana Dashboards│ └── json/ # Dashboard JSON Definitions├── prometheus/ # Prometheus Monitoring Configuration├── scripts/ # DevOps & Local Automation Scripts│ └── rules/ # Project Rules for Cursor└── .github/ # GitHub Configuration └── workflows/ # GitHub Actions CI/CD Workflows
这套目录结构看起来可能有些复杂,但我们遵循的是通用的最佳实践模式,广泛应用于 agentic systems 或纯软件工程中。每个文件夹都有明确用途:
-
app/:主应用代码,包括 API 路由、核心逻辑、数据库模型与工具函数。
-
evals/:用于基于多种 metrics 与 prompts 评估 AI 性能的框架。
-
grafana/与
prometheus/:监控与可观测性工具的配置。
你会看到很多组件有自己的子目录(比如 langgraph/ 和 tools/),进一步实现关注点分离。接下来我们将一步步构建这些模块,并理解每一部分为何重要。
Managing Dependencies
构建面向生产的 AI 系统,第一步是制定依赖管理策略。小项目通常用简单的 requirements.txt,复杂项目建议使用 pyproject.toml,因为它支持更高级的依赖解析、版本管理与构建系统规范。
创建 pyproject.toml 并开始添加依赖与配置:
# ==========================# Project Metadata# ==========================# Basic information about your Python project as defined by PEP 621[project]name = "My Agentic AI System" # The distribution/package nameversion = "0.1.0" # Current project version (semantic versioning recommended)description = "Deploying it as a SASS" # Short description shown on package indexesreadme = "README.md" # README file used for long descriptionrequires-python = ">=3.13" # Minimum supported Python version
第一部分定义了项目元数据,如名称、版本、描述、Python 版本要求。当你发布到 PyPI 等索引时,这些信息会用到。
随后是核心依赖。由于我们要构建一个 agentic AI system(面向 ≤10K 活跃用户),需要覆盖 web 框架、数据库、认证、AI orchestration、observability 等多类库。
# ==========================# Core Runtime Dependencies# ==========================# These packages are installed whenever your project is installed# They define the core functionality of the applicationdependencies = [ # --- Web framework & server --- "fastapi>=0.121.0", "uvicorn>=0.34.0", "asgiref>=3.8.1", "uvloop>=0.22.1", # --- LangChain / LangGraph ecosystem --- "langchain>=1.0.5", "langchain-core>=1.0.4", "langchain-openai>=1.0.2", "langchain-community>=0.4.1", "langgraph>=1.0.2", "langgraph-checkpoint-postgres>=3.0.1", # --- Observability & tracing --- "langfuse==3.9.1", "structlog>=25.2.0", # --- Authentication & security --- "passlib[bcrypt]>=1.7.4", "bcrypt>=4.3.0", "python-jose[cryptography]>=3.4.0", "email-validator>=2.2.0", # --- Database & persistence --- "psycopg2-binary>=2.9.10", "sqlmodel>=0.0.24", "supabase>=2.15.0", # --- Configuration & environment --- "pydantic[email]>=2.11.1", "pydantic-settings>=2.8.1", "python-dotenv>=1.1.0", # --- API utilities --- "python-multipart>=0.0.20", "slowapi>=0.1.9", # --- Metrics & monitoring --- "prometheus-client>=0.19.0", "starlette-prometheus>=0.7.0", # --- Search & external tools --- "duckduckgo-search>=3.9.0", "ddgs>=9.6.0", # --- Reliability & utilities --- "tenacity>=9.1.2", "tqdm>=4.67.1", "colorama>=0.4.6", # --- Memory / agent tooling --- "mem0ai>=1.0.0",]
你会注意到我们针对每个依赖都指定了版本(使用 >= 运算符),这在生产系统极为重要,以避免 dependency hell(依赖地狱),即不同库对同一包的版本要求冲突。
然后是开发依赖。多人在同一代码库协作时,要保证代码质量与一致性,需要 linters、formatters、type checkers 等开发工具。
# ==========================# Optional Dependencies# ==========================# Extra dependency sets that can be installed with:# pip install .[dev][project.optional-dependencies]dev = [ "black", "isort", "flake8", "ruff", "djlint==1.36.4",]
接着我们为测试定义 dependency groups(依赖分组),便于逻辑归类,比如把所有测试相关库归为 test 组。
# ==========================# Dependency Groups (PEP 735-style)# ==========================# Logical grouping of dependencies, commonly used with modern tooling[dependency-groups]test = [ "httpx>=0.28.1", "pytest>=8.3.5",]# ... 其余工具配置保持不变 ...
来理解这些配置:
- Dependency Groups:创建逻辑依赖分组,例如
test分组。 - Pytest Configuration:定制 pytest 的测试发现与运行方式。
- Black:统一代码格式。
- Flake8:风格检查与潜在错误提示。
- Radon:监控圈复杂度保持可维护性。
- isort:自动排序 import。
我们还定义了 Pylint 与 Ruff 等其他检查工具。它们虽然可选,但强烈建议在生产系统使用,代码库会增长,没有它们将难以管理。
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

Setting Environment Configuration
现在设置最常见的配置,即 Settings Management(配置管理)。
小项目通常直接使用 .env 存储环境变量;更规范的是使用 .env.example 并提交到版本库:
# Different environment configurations.env.[development|staging|production] # e.g. .env.development
为什么不用一个 .env?因为这样可针对不同环境(如开发打开 debug,生产关闭)保留独立配置,而无需频繁修改同一个文件。
创建 .env.example,添加必要环境变量的占位值:
# ==================================================# Application Settings# ==================================================APP_ENV=developmentPROJECT_NAME="Project Name"VERSION=1.0.0DEBUG=true
接着是 API 设置与 CORS、Langfuse 观测性配置:
# ==================================================# API Settings# ==================================================API_V1_STR=/api/v1# ==================================================# CORS (Cross-Origin Resource Sharing) Settings# ==================================================ALLOWED_ORIGINS="http://localhost:3000,http://localhost:8000"# ==================================================# Langfuse Observability Settings# ==================================================LANGFUSE_PUBLIC_KEY="your-langfuse-public-key"LANGFUSE_SECRET_KEY="your-langfuse-secret-key"LANGFUSE_HOST=https://cloud.langfuse.com
API_V1_STR 方便进行 API 版本化;CORS 设置用于控制哪些前端域名可以访问我们的后端 API(从而集成 AI agents)。我们还将使用 Langfuse 标准化监控 LLM 交互,因此需要设置密钥与主机地址。
接着是 LLM、JWT 与数据库配置(PostgreSQL),以及连接池参数:
# LLM 设置OPENAI_API_KEY="your-llm-api-key"DEFAULT_LLM_MODEL=gpt-4o-miniDEFAULT_LLM_TEMPERATURE=0.2# JWT 设置JWT_SECRET_KEY="your-jwt-secret-key"JWT_ALGORITHM=HS256JWT_ACCESS_TOKEN_EXPIRE_DAYS=30# PostgreSQL 设置与连接池参数POSTGRES_HOST=dbPOSTGRES_DB=mydbPOSTGRES_USER=myuserPOSTGRES_PORT=5432POSTGRES_PASSWORD=mypasswordPOSTGRES_POOL_SIZE=5POSTGRES_MAX_OVERFLOW=10
最后是 Rate Limiting 与 Logging 设置:
# Rate Limiting Settings (SlowAPI)RATE_LIMIT_DEFAULT="1000 per day,200 per hour"RATE_LIMIT_CHAT="100 per minute"RATE_LIMIT_CHAT_STREAM="100 per minute"RATE_LIMIT_MESSAGES="200 per minute"RATE_LIMIT_LOGIN="100 per minute"# LoggingLOG_LEVEL=DEBUGLOG_FORMAT=console
现在我们已完成依赖与配置管理策略,接下来用 Pydantic Settings Management 在应用代码中加载它们(app/core/config.py)。后续的代码片段与逻辑保持不变(为避免冗长,代码块不再翻译,整体含义为:加载环境、解析列表/字典、定义 Settings 类、按环境覆写关键配置,并初始化全局 settings)。
Containerization Strategy
我们将创建 docker-compose.yml 来定义应用所需的全部服务。生产系统中,数据库、监控工具与 API 并非孤立运行,而是需要相互通信。Docker Compose 是编排多容器应用的标准方式。
我们使用带 pgvector 的 PostgreSQL,以支持 Long-Term Memory 所需的向量相似检索;定义健康检查,确保 App 在数据库就绪后再启动;再定义 FastAPI 应用服务,启用挂载本地代码实现热重载;配置 Prometheus 与 Grafana(收集与可视化度量),以及 cAdvisor(容器资源指标);最后定义共享网络与持久化卷。对应的 YAML 片段与说明如原文所示。
Building Data Persistence Layer
我们已有数据库,但还没有结构。AI 系统高度依赖 Structured Data(结构化数据):需要严格的 Users、Chat Sessions 与 AI State 之间的关系。我们使用 SQLModel(整合 SQLAlchemy 与 Pydantic)实现。
Structured Modeling
我们先定义 BaseModel,抽取公共字段(如 created_at),以遵循 DRY 原则。随后定义 User 实体(包含 email、hashed_password、verify_password/hash_password 封装),再定义 Session(代表特定会话,关联用户,使用 UUID 难以猜测)。代码与注释如原文所示。
Entity Definition
User、Session 的表结构与关系如原文图示。注意把密码哈希逻辑封装到模型中,防止安全误用。
Data Transfer Objects (DTOs)
为 LangGraph Persistence 定义 Thread 模型,用于校验线程存在。然后在 app/models/database.py 聚合导出,方便统一 import。最后定义 Schemas(DTOs)用于 API 输入/输出契约:auth.py(注册、Token、公共用户信息),chat.py(消息、请求/响应、流式响应)、graph.py(LangGraph 的 State 对象,包含 messages 与 long_term_memory)。这样实现数据库层与 API 层的类型安全,避免敏感字段外泄与坏数据污染。
Security & Safeguards Layer
生产环境下不能信任用户输入,也不能允许无限访问。类似 together.ai 等 API 提供方会对每分钟请求数限流以防滥用,保护基础设施并控制成本。
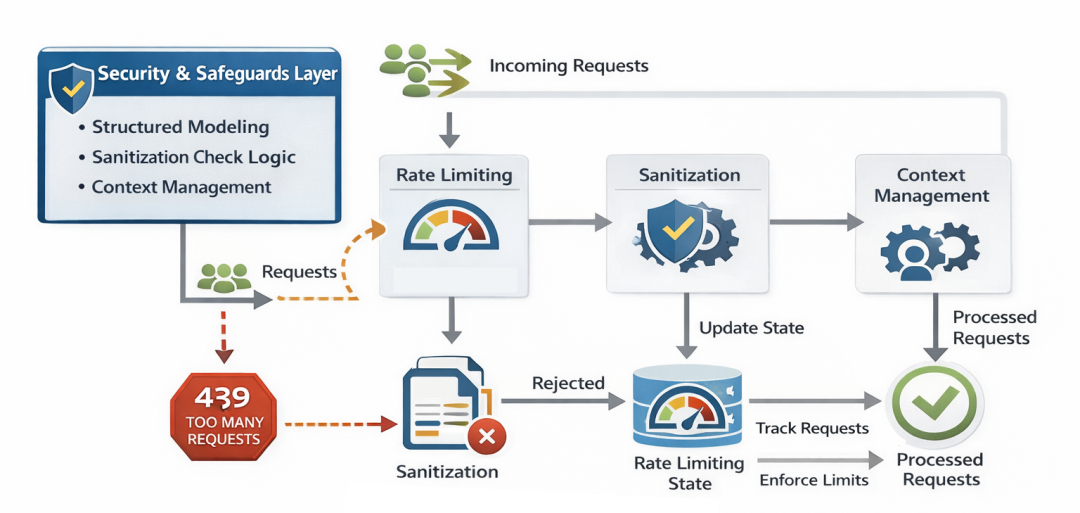
Securtity Layer (Created by Fareed Khan)
若没有防护会发生两件事:
- Abuse:爬虫/脚本狂刷 API,导致 OpenAI 账单飙升。
- Security Exploits:恶意用户尝试注入攻击。
Rate Limiting Feature
使用 SlowAPI 集成 FastAPI 进行限流,基于 IP 或按需改用 X-Forwarded-For。通过 @limiter.limit(...) 可对不同路由施加精细限额。配置与示例如原文。
Sanitization Check Logic
即使前端框架做了 XSS 防护,后端也不能盲信字符串。实现 sanitize_string 与 sanitize_email 等工具,做 HTML 转义、去除 script、校验格式等。具体逻辑参考原文代码。
接着实现 JWT(JSON Web Tokens)工具,用于无状态认证:create_access_token(签发),verify_token(验证)。这样无需每次命中数据库即可确认登录态。
Context Management
扩展 Context Window Management(上下文窗口管理)。随着消息累积,容易触发模型 token 上限或增加成本。实现 prepare_messages 智能裁剪历史,保留系统提示与最近消息;process_llm_response 规范化模型响应(合并 reasoning blocks 与文本)。这样即便历史消息达到 500 条,也不会溢出。
The Service Layer for AI Agents
合理架构下,API 路由(Controller)应保持简洁,复杂业务逻辑与数据库访问属于服务层(Services),便于测试、复用与维护。
Connection Pooling
我们实现数据库连接池(SQLAlchemy QueuePool),开启 pool_pre_ping 避免长时间空闲后连接被关闭导致的 “Broken Pipe”;设置 pool_recycle 以适应云数据库的连接空闲策略;提供用户与会话 CRUD。代码与要点如原文。
LLM Unavailability Handling
单一模型(如 GPT-4)存在风险:服务宕机或限流。我们实现 Resilience(韧性)与 Fallbacks:使用 tenacity 实现自动重试(指数退避)、Circular Fallback(例如从 gpt-4o 切换到 gpt-4o-mini),并封装在 LLMService 中。遇到 RateLimitError/APITimeoutError/APIError 则重试,重试耗尽后自动切换到下一个模型。这样保障高可用。
Circuit Breaking
在 LLM 层绑定 tools,使模型可在 Agent 场景中调用工具。创建全局 llm_service 实例便于全局复用。若提供方出现大规模故障,tenacity 会触发回退,尽量避免 500。
Multi-Agentic Architecture
使用 LangGraph 构建 Stateful Agents(有状态代理)。代理可循环、重试、调用工具、记忆历史、持久化状态(重启可恢复到中断位置)。用户也期望跨会话的长期记忆(Long-Term Memory)。
Long-Term Memory Integration
集成 mem0ai 作为 Long-Term Memory(向量存储 + 事实抽取)。将 prompts 作为资产与代码分离(如 app/core/prompts/system.md),使用变量注入 {long_term_memory} 与当前时间等。
Tool Calling Feature
将工具模块化(如 DuckDuckGo 搜索)。构建 app/core/langgraph/graph.py,包含:
- State Management:将对话状态持久化到 Postgres(
AsyncPostgresSaver)。 - Memory Retrieval:从 mem0ai 获取相关用户事实并注入系统提示。
- Execution Loop:调用 LLM、解析 tool calls、执行并反馈。
- Streaming:实时向用户推送 tokens(后文 API 中实现)。
核心方法 get_response:检索长记忆 → 执行图 → 异步更新记忆 → 返回消息列表。也添加了 Langfuse CallbackHandler 以追踪每一步。
Building The API Gateway
需要认证(Authentication)与授权(Authorization)。先构建认证端点(注册、登录、会话管理),用 FastAPI Dependency Injection(依赖注入)来统一校验。
定义 get_current_user 依赖:从 Authorization 头提取并验证 JWT,查询用户、绑定日志上下文;get_current_session 用于基于会话的校验(每个会话单独 token),统一审计与风控。
Auth Endpoints
实现 /register(注册,限流 + 严格校验 + 哈希密码 + 自动登录签 token)、/login(表单风格 OAuth2,返回 JWT)、/session(为用户创建会话并返回 session 专属 token)、/sessions(列出用户历史会话并重新签发 token)。通过这些设计,入口由限流、净化、加密校验全方位保护。
Real-Time Streaming
构建聊天 API。两类交互:
- 标准聊天:一次请求得到完整响应(阻塞)。
- 流式聊天:实时获取 tokens(非阻塞),用户体验更佳。
使用 SSE(Server-Sent Events)格式(text/event-stream),前端原生支持。/chatbot/chat 返回完整响应,/chatbot/chat/stream 使用异步生成器流式推送,尾部发送 done 标记。还提供 /messages 获取历史与清空历史的端点。
最后用路由聚合器 app/api/v1/api.py 整合模块化子路由,并提供 /health 健康检查。
Observability & Operational Testing
在服务 10,000 用户的系统中,我们需要可观测性(Observability):通过 Prometheus Metrics 与 Context-Aware Logging 跟踪性能、行为与错误。
Creating Metrics to Evaluate
在 app/core/metrics.py 定义并暴露 Prometheus metrics:HTTP 请求总数/延迟直方图、数据库连接数、LLM 推理耗时(自定义桶分布)。提供 setup_metrics(app) 注册 /metrics 端点。
Middleware Based Testing
通过中间件统一记录时延与状态码,并将用户/会话 ID 注入日志上下文(在 app/core/middleware.py):
- MetricsMiddleware:统计所有请求(除
/metrics与/health)的数量与耗时。 - LoggingContextMiddleware:从 JWT 中提取 subject 并绑定到日志上下文,确保即使是认证失败也能有一致的上下文。
Streaming Endpoints Interaction
前文已实现 /chat 与 /chat/stream。我们在流式端点中以 SSE 的 data: {json}\n\n 向前端持续推送。出错时返回结构化错误并结束。
此外提供获取/清理历史的端点,结合 LangGraph 的 checkpoint 恢复能力,支持刷新页面后仍能看到历史会话。
Context Management Using Async
app/main.py 负责应用装配与生命周期管理。使用 asynccontextmanager(现代方式)代替旧的 @app.on_event("startup"):启动时记录元数据,关闭时清理资源(如 flush Langfuse)。
配置中间件执行顺序(重要):
- LoggingContext(最外层,优先绑定上下文)
- Metrics(计时)
- CORS(安全)
并注册 SlowAPI 异常处理。自定义 RequestValidationError 返回更友好的 JSON。根路由 / 与 /health(探活)受限流保护,/health 会实际检查数据库健康并按需返回 200/503。
DevOps Automation
生产系统需要 Operational Excellence:如何部署、如何监控健康与性能、如何确保数据库先于应用就绪。
- Dockerfile:尽量小与安全,使用非 root 用户,构建虚拟环境,缓存依赖层,加入口令检查入口脚本(
scripts/docker-entrypoint.sh)确保关键环境变量存在。 - Prometheus:在
prometheus/prometheus.yml配置抓取 FastAPI 与 cAdvisor。 - Grafana:在
grafana/dashboards/dashboards.yml配置 Dashboards as Code(自动加载 JSON 仪表盘)。 - Makefile:封装常见命令(安装、开发热重载、Docker 启动、评测等)。
- GitHub Actions:在
.github/workflows/deploy.yaml配置 CI/CD,push 到 master 时自动构建并推送镜像到 Docker Hub(使用仓库密钥)。
通过这些,完成了部署、监控与运维自动化的“生产级”闭环。
Evaluation Framework
AI 系统是概率性的,不像传统单元测试那样确定。对 prompts 的更新可能修复一个边界问题,却引入更多回归。我们需要在接近生产的场景下持续评估 Agent 表现,尽早发现回归。
构建 Evaluation Framework,采用 LLM-as-a-Judge:由强模型基于 Langfuse traces 自动打分。
LLM-as-a-Judge
定义评价 rubric(评分标准),使用 Structured Output(结构化输出)模式,强制模型给出分数与理由(ScoreSchema)。为不同维度定义 metric prompts(如 hallucination.md、toxicity.md,还可扩展 relevancy/helpfulness/conciseness)。通过 evals/metrics/__init__.py 动态加载所有 .md 指标。
实现 evals/evaluator.py:
- 从 Langfuse 拉取近期 traces。
- 过滤尚未评分的。
- 对每个 trace,遍历所有 metrics,用强模型(如 GPT-4o)当评审打分。
- 将分数回传 Langfuse 以便趋势可视化与监管。
Automated Grading
evals/main.py 提供 CLI 入口(可人工触发或 CI/CD cron 定时任务)。这就形成了自我监控的反馈回路:如果一次 prompt 更新导致更多幻觉,第二天“Hallucination Score”会明显升高。
这也是区分“简单项目”与“生产级 AI 平台”的关键环节之一。
Architecture Stress Testing
原型与生产系统的重大区别在于负载承受能力。我们需要验证并发能力(concurrency),否则会面临数据库连接耗尽、OpenAI 限流碰撞、延迟飙升等问题。
我们将模拟 1,500 个并发用户同时命中聊天端点,类似营销活动后的流量峰值。
Simulating our Traffic
压测不应在本地笔记本上进行(网络/CPU 瓶颈会干扰结果)。选择云主机如 AWS m6i.xlarge(4 vCPU/16 GiB RAM),成本约 $0.192/小时。开放 8000 端口,安装 docker 与 docker-compose,使用 make docker-run-env ENV=development 启动开发环境以验证联通,然后编写 tests/stress_test.py 做完整登录 → 创建会话 → 聊天流程的并发压测脚本(1,500 用户)。
Performance Analysis
运行压测后,日志显示大量 200 成功响应,同时在高峰时看到 switching_model_fallback,说明主模型限流时自动切换到 gpt-4o-mini 保持请求不中断。整体成功率 98.4%,平均延迟 ~1.2s,失败多为 429(OpenAI 限流)。
随后用 Prometheus 查询每秒请求率(RPS),Grafana/Prometheus 展示 /auth/login、/chatbot/chat、/auth/session 的 RPS 峰值;再用 Langfuse 查看 traces(延迟与成本)。延迟在 0.98s~2.10s 合理区间内波动,成本可审计。
还可以进一步做 ramp-up(逐步加压)与 soak test(长时间高压)来检测内存泄漏等问题。更深入压测与监控可参考我的 GitHub 项目。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)