Linux 基础命令大全(AI 运维版):文件 / 进程 / 日志操作必备
本文聚焦AI运维场景下的Linux核心命令,分为文件操作、进程管理和日志分析三大模块。针对AI运维高频需求,重点介绍了模型文件传输(rsync)、GPU监控(nvidia-smi)、日志分析(grep+awk)等关键命令,并提供组合技和避坑指南。文章强调场景化应用,如大模型文件同步、训练进程监控、日志指标提取等,帮助运维人员快速掌握生产环境必备技能。同时建议将常用命令组合保存为Shell脚本,提升
核心提要:本文聚焦 AI 运维场景下最常用的 Linux 基础命令,按“文件操作、进程操作、日志操作”三大核心模块分类,每个命令配套「AI 运维专属场景+实操示例+避坑点」,附命令组合技与可视化对比表,帮 AI 运维新手快速掌握“模型文件管理、GPU 进程监控、训练日志分析”必备技能,直接落地生产环境。
在 AI 运维工作中,Linux 是核心操作环境——模型文件的上传下载、训练/推理进程的监控启停、日志中故障与性能指标的提取,都离不开基础命令。与通用 Linux 命令大全不同,本文筛选的均是 AI 运维高频场景(如大模型文件同步、GPU 进程排查、训练日志指标提取),并补充专属用法,避免“学了用不上”的问题。下面按模块拆解实操技巧。
一、文件操作:AI 模型文件/数据的核心管理
AI 运维中,文件操作核心围绕“大模型文件(GB/TB 级)、训练数据集、配置文件”展开,重点关注“高效传输、权限控制、数据完整性”,以下是高频命令:
|
命令 |
功能描述 |
AI 运维专属场景 |
实操示例 |
注意点(避坑) |
|
ls |
列出目录文件/属性 |
查看模型目录结构、数据集文件数量 |
|
加 |
|
cd |
切换目录 |
进入模型训练目录、日志存储目录 |
|
路径用 Tab 补全,避免拼写错误;返回上级用 |
|
pwd |
显示当前路径 |
确认操作目录(避免在错误路径修改模型文件) |
|
远程操作服务器时,频繁用 |
|
mkdir |
创建目录 |
新建模型存储目录、训练日志目录 |
|
加 |
|
cp |
复制文件/目录 |
备份模型配置文件、复制数据集子集 |
|
复制目录必须加 |
|
rsync |
高效同步文件/目录 |
跨服务器传输大模型文件(如 20GB 的 PyTorch 模型)、备份训练数据 |
|
|
|
mv |
移动/重命名文件 |
重命名模型版本(如区分训练完成的模型)、移动日志文件归档 |
|
避免在模型训练中移动正在写入的文件(如训练中的 checkpoint),会导致文件损坏 |
|
rm |
删除文件/目录 |
删除过期模型、临时训练数据 |
|
高危命令!删除前用 |
|
chmod |
修改文件权限 |
授权模型执行文件、限制数据集访问权限 |
|
AI 模型文件建议设为 |
|
scp |
跨服务器传输文件 |
紧急传输小型模型配置文件、日志片段 |
|
大文件(>5GB)优先用 |
|
du |
查看文件/目录大小 |
排查数据集/模型文件占用空间(避免磁盘满) |
|
查看单个大模型文件用 |
|
df |
查看磁盘空间 |
监控 AI 数据盘使用率(防止训练中断) |
|
重点关注 |
AI 运维文件操作组合技(直接落地)
-
快速查看最大的 5 个模型文件:
du -ah /data/ai/models/ | sort -rh | head -n 5 -
批量重命名训练日志:
for i in log_*.txt; do mv "$i" "train_$(date +%Y%m%d)_$i"; done -
校验模型文件完整性(避免传输损坏):
md5sum model.pth > model.md5(本地),md5sum -c model.md5(服务器验证)
二、进程操作:AI 训练/推理进程的监控与管控
AI 运维中,进程操作核心是“监控 GPU/CPU 资源占用、定位模型进程、处理卡死/冗余进程”,尤其关注 GPU 相关进程(模型训练/推理的核心依赖):
|
命令 |
功能描述 |
AI 运维专属场景 |
实操示例 |
注意点(避坑) |
|
ps |
查看进程信息 |
查找模型训练进程(如 Python/TensorFlow 进程) |
`ps -ef |
grep python`(查找所有 Python 进程,AI 模型多为 Python 开发) |
|
top |
实时监控系统资源 |
查看 CPU/内存占用(判断模型训练是否资源不足) |
|
按 |
|
htop |
增强版资源监控 |
可视化查看多 CPU/GPU 进程分布(比 top 更清晰) |
|
需提前安装( |
|
nvidia-smi |
GPU 资源监控 |
查看 GPU 使用率、显存占用(AI 运维核心命令) |
|
显存占用>90% 易导致模型 OOM(内存溢出); |
|
kill |
终止进程 |
关闭卡死的模型训练进程、冗余推理进程 |
|
先通过 |
|
pkill |
按名称终止进程 |
批量关闭同名模型进程(如多个 Python 训练进程) |
|
|
|
pgrep |
按名称查找 PID |
快速获取模型进程的 PID(无需手动过滤) |
|
输出结果直接是 PID,可搭配 |
|
nohup |
后台运行进程 |
模型训练/推理进程后台执行(避免断开 SSH 后中断) |
|
末尾的 |
|
jobs |
查看后台进程 |
确认模型训练进程是否在后台运行 |
|
仅在当前 SSH 会话有效;断开连接后需用 |
AI 运维进程操作组合技(直接落地)
-
查找占用 GPU 0 的模型进程并终止:
nvidia-smi -i 0 | grep python | awk '{print $3}' | xargs kill -9 -
后台运行模型推理脚本并实时监控日志:
nohup python infer.py > infer.log 2>&1 & && tail -f infer.log -
查看模型进程的 CPU/GPU/内存综合占用:
ps -ef | grep train.py | awk '{print $2}' | xargs -I {} sh -c 'echo PID: {}; top -p {} -n 1; nvidia-smi | grep {}'
三、日志操作:AI 训练/推理日志的分析与提取
AI 运维中,日志是“问题排查、性能监控”的核心依据——训练日志中的损失值(loss)、准确率(accuracy),推理日志中的报错信息、响应延迟,都需要通过命令快速提取,以下是高频命令:
|
命令 |
功能描述 |
AI 运维专属场景 |
实操示例 |
注意点(避坑) |
|
tail |
查看文件尾部内容 |
实时监控模型训练日志、查看最新推理报错 |
|
|
|
head |
查看文件头部内容 |
查看模型训练的初始配置、日志开头的报错 |
|
适合快速确认模型启动参数(如学习率、批次大小)是否正确 |
|
grep |
过滤日志关键词 |
提取训练日志中的 loss/accuracy、排查报错(如 OOM) |
|
|
|
awk |
提取日志中的特定字段 |
提取训练日志中的 loss 数值(用于后续分析) |
`grep "loss" train.log |
awk '{print $8}'`(假设 loss 在日志第 8 列) |
|
sed |
替换/删除日志内容 |
清理日志中的冗余信息、提取关键片段 |
|
|
|
less |
分页查看大日志 |
查看超大训练日志(如 10GB 的训练日志) |
|
避免用 |
|
cat |
查看/合并小日志 |
合并多个碎片化的推理日志 |
|
仅用于小文件(<100MB);大文件禁止用 |
|
wc |
统计日志行数/字符数 |
统计训练日志总条数、确认日志完整性 |
|
结合 |
AI 运维日志操作组合技(直接落地)
-
实时监控训练日志中的 loss 变化:
tail -f train.log | grep -E "epoch|loss" --color=auto(高亮显示 epoch 和 loss) -
提取训练日志中所有 epoch 的准确率并保存到文件:
grep "accuracy" train.log | awk '{print $10}' > accuracy.txt -
排查模型训练报错的上下文:
grep -B 5 -A 5 "error" train.log(显示 error 前后 5 行日志,便于定位原因)
四、AI 运维命令可视化对比与快速索引
1. 命令功能分类树形图(快速找命令)

2. 高频命令场景匹配图(场景→命令)
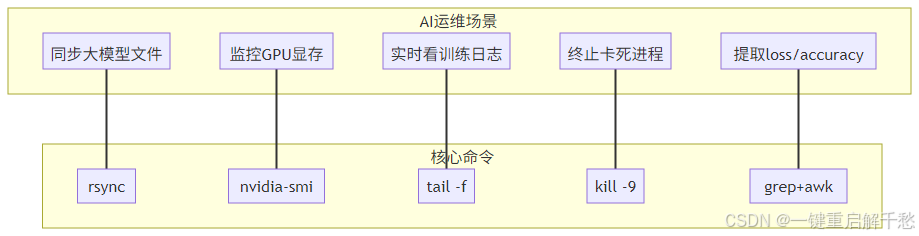
五、术语小词典(AI 运维专属)
-
PID:进程ID,Linux 中唯一标识进程的编号,AI 运维中用于精准管控模型进程;
-
OOM:内存溢出(Out of Memory),模型训练/推理时显存/内存不足导致的报错,需通过
nvidia-smi监控; -
后台进程:用
nohup或&启动的进程,断开 SSH 后仍能运行,适合长期模型训练; -
日志重定向:
>表示覆盖写入日志,>>表示追加写入,AI 运维中常用2>&1合并标准日志和错误日志; -
GPU 显存:显卡的内存,模型参数和数据都存储在显存中,
nvidia-smi中的Used GPU Memory是核心监控指标。
六、常见问题排查(AI 运维避坑指南)
-
问题:模型文件传输后无法加载,提示“文件损坏”?解决:用
md5sum校验文件完整性;大文件优先用rsync -avz传输,避免scp中断导致损坏。 -
问题:
nvidia-smi命令找不到?解决:未安装 NVIDIA 驱动或驱动版本不匹配;执行sudo apt install nvidia-driver-525(Ubuntu)或yum install nvidia-driver(CentOS),重启服务器后生效。 -
问题:查看 10GB 训练日志时系统卡顿?解决:禁止用
cat,改用less train.log分页浏览,或用grep过滤关键信息后查看。 -
问题:后台启动的模型进程断开 SSH 后消失?解决:必须用
nohup结合&启动,如nohup python train.py > train.log 2>&1 &,避免直接用python train.py &。 -
问题:无法删除模型文件,提示“Permission denied”?解决:用
ls -l查看文件权限,执行chmod 755 文件名或sudo rm -rf 文件名(谨慎使用 sudo)。
总结
AI 运维中的 Linux 命令,核心是“围绕模型、数据、日志”的场景化应用——不用死记所有命令,重点掌握“文件传输用 rsync、GPU 监控用 nvidia-smi、日志分析用 grep+awk”的核心逻辑,再结合本文的组合技和避坑点,就能高效解决生产环境中的大部分问题。
随着 AI 项目复杂度提升(如分布式训练、多 GPU 集群),这些基础命令会成为进阶技能的“地基”。建议将常用组合技保存为 Shell 脚本(如 monitor_gpu.sh extract_log.sh),进一步提升运维效率,让更多精力聚焦于模型稳定运行与性能优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)