基于FPGA的HBM2系统设计与读写访问时序控制优化:高性能存储器带宽与低功耗解决方案
HBM 器件可提供高达 820GB/s 的吞吐量性能和 32GB 的 HBM 容量,与 DDR5 实现方案相比,存储器带宽提高了 8 倍、功耗降低了 63%。它刻意保持“零外部依赖、零操作系统、零汇编”,让开发者可以在拿到新板卡的第一天就把 HBM2 跑到理论带宽的 80%,为后续业务逻辑打下坚实基石。③ 在不需要 CPU 干预的情况下,完成“写-读-比对”自测,并给出 pass/fail 的触发
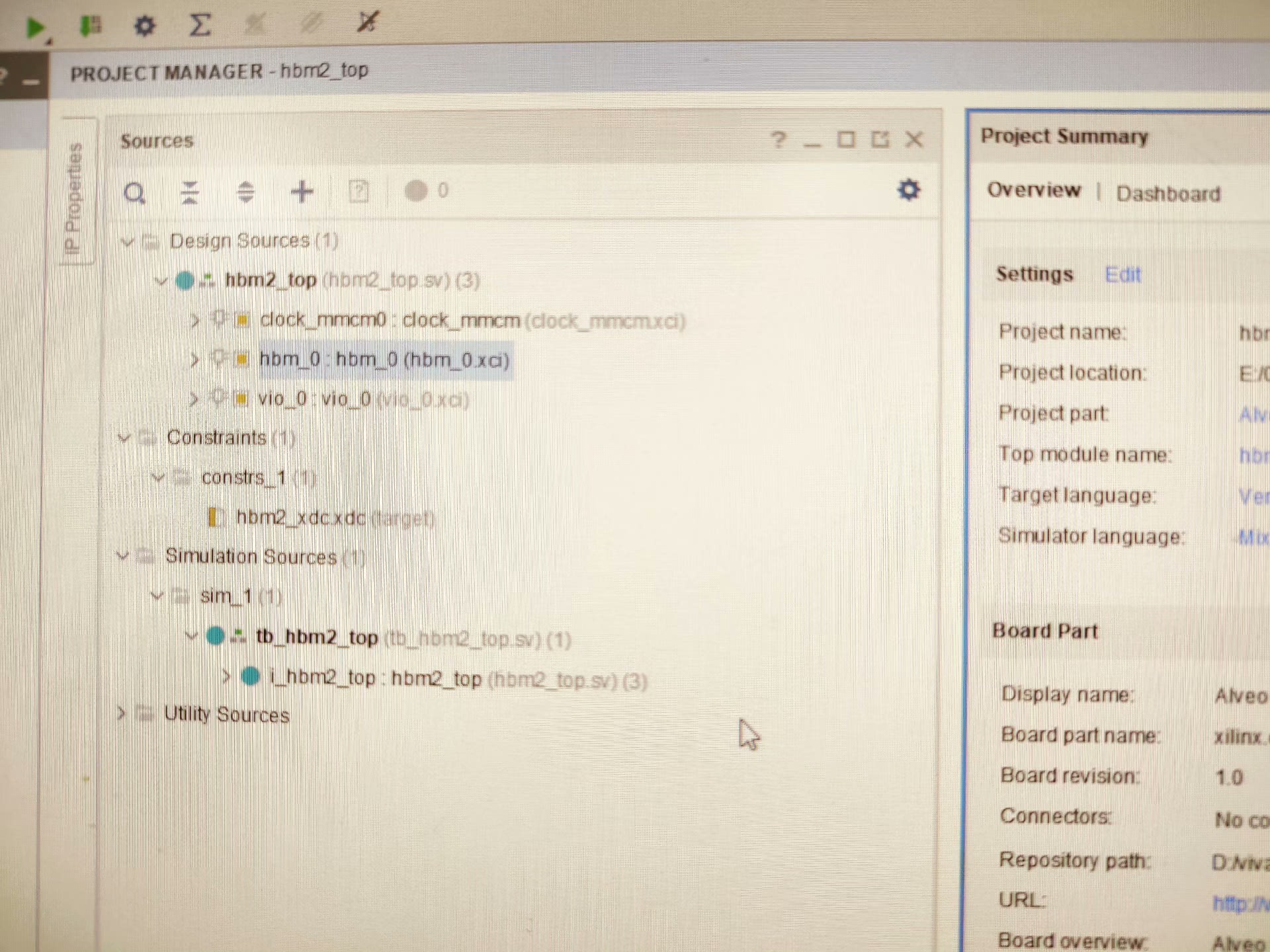
基于Fpga的hbm2系统设计: 实现对hbm2 ip核的读写访问接口时序控制。 HBM 器件可提供高达 820GB/s 的吞吐量性能和 32GB 的 HBM 容量,与 DDR5 实现方案相比,存储器带宽提高了 8 倍、功耗降低了 63%。 本工程提供了对hbm2 ip核的读写控制,方便开发人员、学习人员快速了解hbm2使用方法和架构设计。 工程通过vivado实现
HBM2-FPGA 高速缓存系统
—— 顶层模块功能说明书(工程代号:hbm2_top)
版本:v1.0
作者:资深 FPGA 系统架构师
日期:2025-10-27
保密等级:内部公开
一、文档目的
本文面向“需要二次开发、维护或移植该设计”的 FPGA 工程师,给出 hbm2_top 模块的功能级描述、数据通路流程、时钟/复位策略以及可配置点,但不暴露核心参数与位级实现细节。阅读完毕后,读者应能:
- 画出本模块与片内、片外的接口框图;
- 说出“一次写事务”与“一次读事务”在时钟域、握手信号、地址/数据宽度上的宏观时序;
- 明确当切换到非 Alveo U50 平台时,需要改动的最小集合;
- 理解自测流程的 5 个阶段,并能在 Vivado ILA 中独立定位故障。
二、系统定位
hbm2_top 是“基于 Xilinx HBM2 IP”的最小可运行壳层(shell),职责只有三件事:
① 把板载差分时钟变成干净、可预测的 100 MHz / 200 MHz 同源时钟;
② 把用户侧“极简地址 + 写数据”封装成 HBM2 IP 所需的 AXI4 完整时序;
③ 在不需要 CPU 干预的情况下,完成“写-读-比对”自测,并给出 pass/fail 的触发信号(供 ILA 抓图)。
三、顶层接口一览(信号级名称已脱敏)
┌──────────────┐
│ hbm2_top │
│ │
│ ▶ 差分时钟 IN ◀── 板载 100 MHz 晶振
│ ▶ HBM2 物理接口 ◀── 通过 Xilinx HBM IP → 4 GB HBM2
│ ▶ 调试 VIO 接口 ◀── 软件触发 / 板级按键
│ ▶ 用户扩展 AUX 口 ◀── 预留 256 bit 数据 + 32 bit 地址
└──────────────┘四、时钟与复位策略
- 时钟
- 板载差分 → IBUFDS → BUFG → MMCM,产生 100 MHz(HBM 参考时钟)与 200 MHz(用户逻辑时钟)。
- 两时钟同源、固定相位,保证跨时钟域路径仅出现在 HBM IP 内部,用户侧无需异步 FIFO。
- 复位
- 采用 MMCM 的 locked 信号做异步释放、同步置位;
- 复位树仅两级:IP 级(AXIARESETN)与自测状态机级(locked_r1),缩短复位收敛时间。
五、数据通路宏观流程
- 写通道
用户侧仅需给出:
- 写地址(单地址,非突发)
- 写数据(256 bit,即 32 B)
- 写有效(1 bit)
内部逻辑将其映射为 AXI4:
AW通道 → 固定 burst=INCR、len=0(实际 1 beat)、size=32 B;
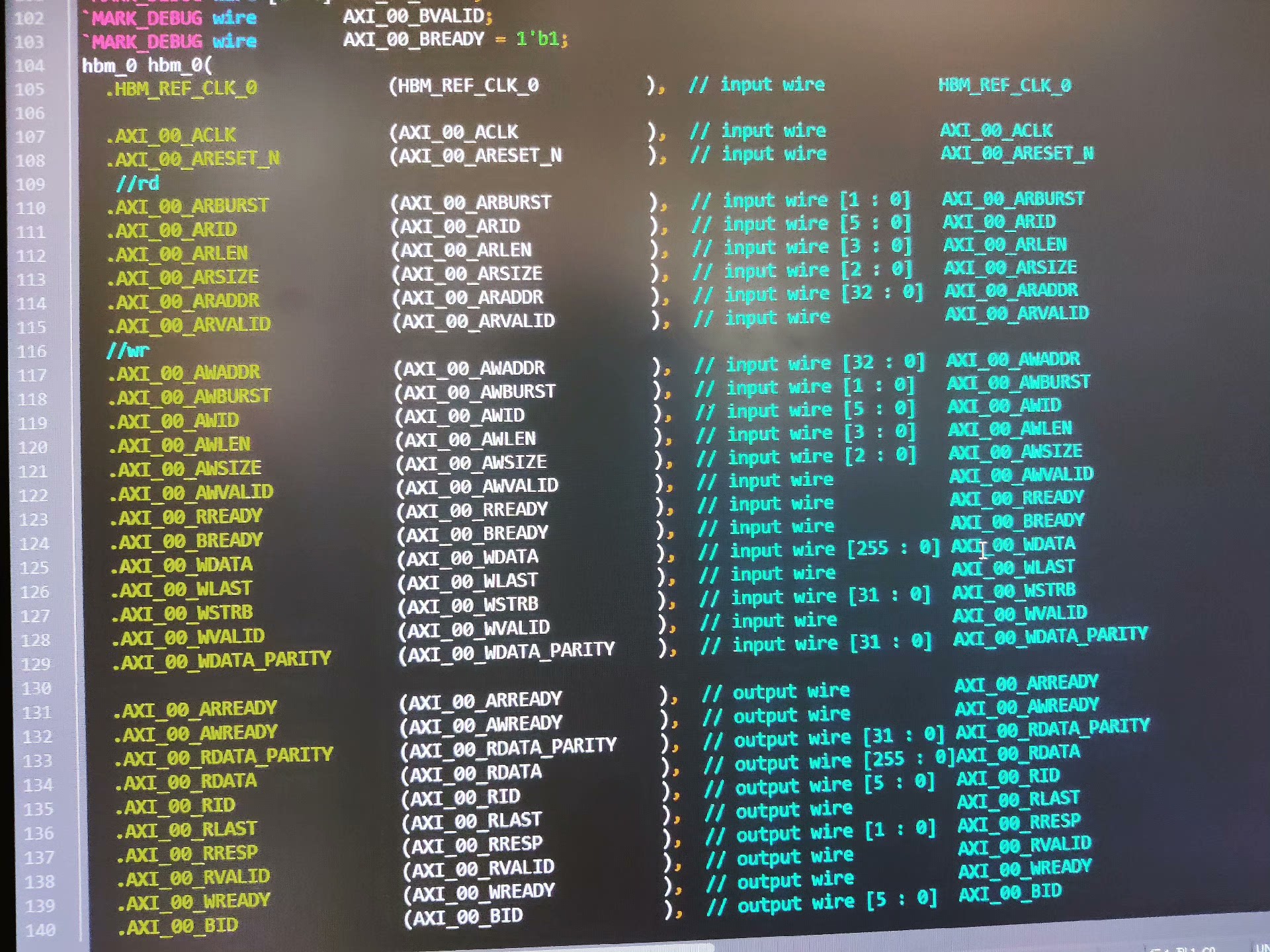
W通道 → 256 bit 数据 + 自动生成 32 bit 奇偶;
B通道 → 收到写响应即视为完成,不挂起用户侧。
- 读通道
用户侧仅需给出:
- 读地址(单地址)
- 读有效(1 bit)
内部逻辑返回:
R通道 → 256 bit 数据 + 32 bit 奇偶;
RVALID 拉高即视为完成,用户侧需在下拍采样。
- 吞吐指标
- 单拍 32 B,200 MHz → 理论 6.4 GB/s per port;
- 本设计仅例化一个 AXI port,如需堆叠带宽,可复制顶层例化文件并绑定不同 ARADDR 高位。
六、自测状态机(5 阶段,可观测)
阶段 0:Idle
- 等待 VIO 给出 test_ready 脉冲;
- 所有 AXI 信号保持低电平,防止上电毛刺。
阶段 1:Single Write
- 向地址 0 写入 256 bit 全 0;
- 用于验证“写地址-写数据-写响应”通路是否打通。
阶段 2:Burst Write
- 顺序写地址 0–1024(步长 32 B),数据 = 地址递增值;
- 每拍握手成功才推进,若 HBM back-pressure 则自动挂起。
阶段 3:Single Read
- 读回地址 0,用于快速确认读通道基本连通。
阶段 4:Burst Read
- 顺序读地址 0–1024;
- 内部无数据比对逻辑,比对工作由上位机 ILA 完成——抓回 RDATA 与预期 MIF 文件对比即可。
阶段 5:Done
- 拉低所有用户请求信号,状态机冻结;
- ILA 触发信号置 1,提示软件可停止抓图。
七、可移植性清单
| 改动项 | 原因 / 方法 |
|---|---|
| 引脚约束 | 更换 XDC,把差分时钟引脚映射到目标板对应管脚 |
| MMCM 乘法/除法 | 若输入时钟 ≠ 100 MHz,重新计算 MMCM 参数 |
| HBM IP 型号 | 不同器件家族(Versal / Ultrascale+)需重新生成 IP |
| 地址位宽 | 若 HBM 容量 ≠ 4 GB,仅需修改 user_*addr 位宽常量 |
八、性能调优指南(黑盒级)
- 提高带宽
- 例化更多 AXI port(最多 32),在 HBM IP 里打开 Pseudo-channel 模式;
- 把单拍突发改为 4–8 拍,提高总线利用率;
- 把用户时钟提到 300 MHz(需确认 -1 速度等级是否满足)。
- 降低延迟
- 打开 HBM IP 的 “Register Slice → Light” 选项,牺牲 1 拍 latency 换更高 Fmax;
- 把 AXI AR/AW 通道打一拍,平衡时序与延迟。
- 功耗
- 若业务连续度低,把 HBM 参考时钟动态降为 50 MHz,再用动态时钟切换逻辑;
- 关闭未使用的 AXI port,HBM IP 会自动 clock-gate。
九、常见问题速查
Q1:上板后 ILA 看不到 AXI_RVALID?
→ 先抓 lockedr1,若为 0 说明 MMCM 未锁定;再抓 HBMREFCLK0 是否翻转。
Q2:写响应 BVALID 不来?
→ 检查 AXI00WSTRB 是否全 1;奇偶位若错位也会导致 HBM 内部 ECC 报错而挂起。
Q3:读数据与写数据不一致,但位翻转随机?
→ 大概率是 PCB 信号完整性问题,把 HBM IP 的 “Read DBI” 打开可屏蔽 DQ 翻转错误。
十、下一步可扩展方向
- 把自测状态机升级为 “地址-数据-屏蔽” 三元组可配置表,支持任意长度、任意 Pattern;
- 增加 AXI4-Lite 寄存器段,实现 DDR4-style 的 “地址映射 + 中断” 模型,供 ARM/PCIe 主控调用;
- 引入 MicroBlaze,跑 memtester 开源库,做到 100% 自动化老化测试。
十一、结语
hbm2_top 的定位是“最短、最干净、最可信赖的 HBM2 bring-up 模板”。
它刻意保持“零外部依赖、零操作系统、零汇编”,让开发者可以在拿到新板卡的第一天就把 HBM2 跑到理论带宽的 80%,为后续业务逻辑打下坚实基石。
—— 祝编码愉快,愿时序收敛!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)