强化学习 PPO、DPO和GRPO 加上例子辅助理解
核心思想:PPO是OpenAI提出的强化学习算法,通过来保证训练稳定。
ps:这个帖子主要是为了对强化学习的几种实现方式做一个大概的了解,然后用简单容易理解的例子来辅助解释,主要是为了速成一下各种八股知识以准备面试,如果需要对公式和原理更深入的了解的话,这个帖子可能不太适合。

1.PPO(Proximal Policy Optimization)
核心思想:PPO是OpenAI提出的强化学习算法,通过限制策略更新幅度来保证训练稳定。
1.1 前置知识

策略梯度目标

1.2. 从PG到PPO的演进
1. 2.1引入Baseline减少方差

Advantage的含义:
- A > 0:这个回复比平均好,应该增加它的概率
- A < 0:这个回复比平均差,应该减少它的概率
1.2.2. TRPO:限制更新幅度

1.3. PPO的核心机制

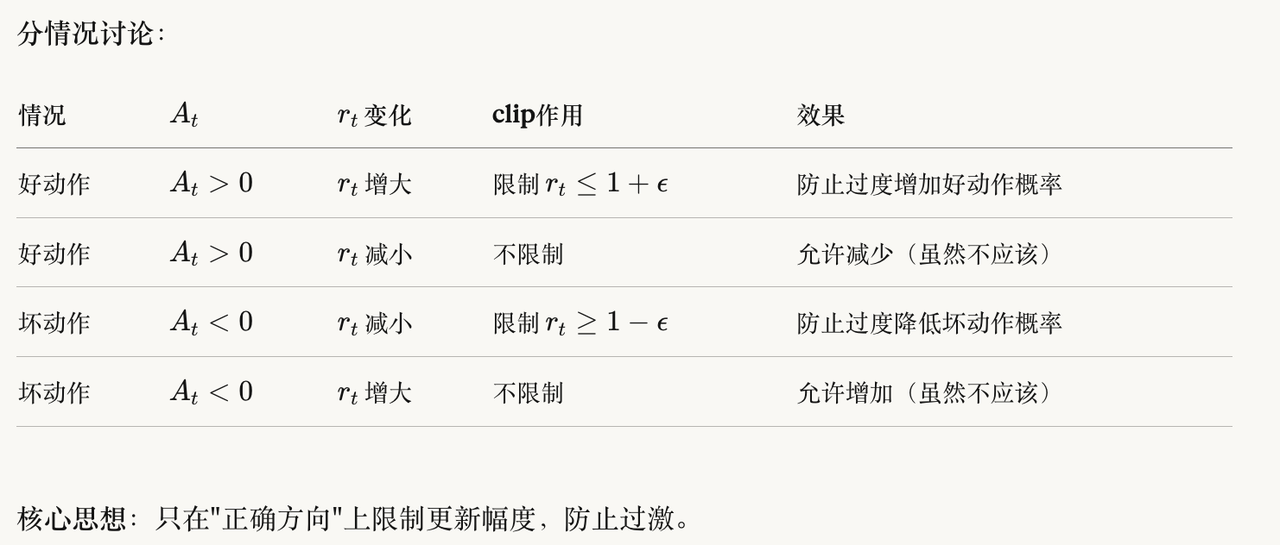
好动作:增加概率,但不要增太多(r ≤ 1.2)坏动作:减少概率,但不要减太多(r ≥ 0.8)
1. 4 PPO在RLHF中的应用
整体架构:
┌─────────────────────────────────────────────────────────────┐
│ PPO-RLHF 四个模型 │
├─────────────────────────────────────────────────────────────┤
│ 1. Policy Model (π_θ) 要优化的模型,生成回复 │
│ 2. Reference Model (π_ref) SFT模型,冻结,用于KL约束 │
│ 3. Reward Model (RM) 打分模型,评估回复质量 │
│ 4. Value Model (Critic) 估计状态价值,计算Advantage │
└─────────────────────────────────────────────────────────────┘

KL散度衡量新策略和原始SFT模型的差异。如果差太远,就扣分。
1.5 关键组件详解
1.5.1 GAE(Generalized Advantage Estimation)

1.5.2 Value Model
通常和Policy共享底座,加一个value head:
class PolicyWithValueHead(nn.Module):
def __init__(self, base_model):
self.base = base_model # LLM
self.value_head = nn.Linear(hidden_size, 1)
def forward(self, x):
hidden = self.base(x).last_hidden_state
logits = self.base.lm_head(hidden) # 策略输出
values = self.value_head(hidden[:, -1]) # 价值输出
return logits, values
1.5.3 KL散度计算
在token级别计算:
def compute_kl_penalty(policy_logprobs, ref_logprobs):
"""
policy_logprobs: [batch, seq_len] 当前策略的log概率
ref_logprobs: [batch, seq_len] 参考策略的log概率
"""
# KL(π||π_ref) ≈ log(π) - log(π_ref) 当两者接近时
kl = policy_logprobs - ref_logprobs
return kl # 逐token的KL
1.6 图解
┌─────────────────────────────────────────────────────────────────┐
│ PPO训练一轮 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Step 1: 采样阶段 │
│ ┌─────────────┐ │
│ │ Policy模型 │ 输入: "如何学习Python?" │
│ │ (旧参数) │ 输出: "多写代码,从项目开始..." │
│ └─────────────┘ │
│ │ │
│ └──→ 记录 log P_old = -2.3 (整个序列的log概率) │
│ │
│ Step 2: 计算奖励 │
│ ┌─────────────┐ │
│ │ Reward模型 │ ──→ R = 0.8 │
│ └─────────────┘ │
│ │
│ Step 3: 计算KL惩罚 │
│ ┌─────────────┐ │
│ │Reference模型│ ──→ KL = 0.2 │
│ └─────────────┘ │
│ │ │
│ └──→ 调整后奖励 = R - β×KL = 0.8 - 0.1×0.2 = 0.78 │
│ │
│ Step 4: 计算Advantage │
│ ┌─────────────┐ │
│ │ Value模型 │ ──→ V = 0.3 (预测的平均水平) │
│ └─────────────┘ │
│ │ │
│ └──→ A = 调整后奖励 - V = 0.78 - 0.3 = 0.48 │
│ (正数,说明这是个好动作!) │
│ │
│ Step 5: PPO更新(重复多次) │
│ ┌─────────────┐ │
│ │ Policy模型 │ 重新计算 log P_new = -2.1 │
│ (新参数) │ │
│ └─────────────┘ │
│ │ │
│ ├──→ r = exp(P_new - P_old) = exp(-2.1-(-2.3)) = 1.22 │
│ │ │
│ ├──→ 原始目标: r × A = 1.22 × 0.48 = 0.586 │
│ │ │
│ ├──→ 裁剪目标: clip(1.22, 0.8, 1.2) × A │
│ │ = 1.2 × 0.48 = 0.576 ← 被裁剪了! │
│ │ │
│ ├──→ Loss = -min(0.586, 0.576) = -0.576 │
│ │ │
│ └──→ 反向传播,更新参数 │
│ 但因为被clip了,梯度会阻止r继续增大 │
│ │
└─────────────────────────────────────────────────────────────────┘
PPO的策略:样本复用
一批样本采样一次,然后复用多次更新。
但是复用有风险——如果参数变化太大,旧样本就不能代表新策略了。
Clip机制正是为了解决这个问题:限制参数变化幅度,保证旧样本在多次更新后仍然有效。
1.7 归纳PPO
- 完整版(适合详细解释):
PPO是RLHF中经典的强化学习算法,包含四个模型。Policy Model是我们要训练的目标模型,希望它能生成符合人类偏好的回复。Reward Model对Policy生成的回复打分,评估回复质量,分数越高表示越符合人类期望。Reference Model是SFT阶段得到的模型,参数冻结不更新,用于计算KL散度来衡量Policy与它的差异,防止Policy为了追求高奖励而输出奇怪内容(reward hacking),同时保持语言流畅性等基本能力;KL散度会作为惩罚项从奖励中扣除,偏离越大扣得越多。Value Model预测当前状态的平均回报作为baseline,用于计算Advantage(优势函数),即调整后奖励减去Value预测值,正数表示这个回复比平均水平好、应该增加其概率,负数表示比平均差、应该降低其概率。有了Advantage后,PPO通过Clip机制更新Policy:首先计算概率比r(新策略生成该回复的概率除以旧策略的概率),然后将r裁剪到一个范围内(比如0.8到1.2),最后用裁剪后的r乘以Advantage计算Loss进行反向传播。Clip机制的作用是限制每次更新的幅度——好动作可以增加概率但不能超过上限,坏动作可以降低概率但不能低于下限,从而保证训练过程稳定,避免策略剧烈变化导致崩溃。
- 精简版(适合快速回答)
PPO包含四个模型:Policy是要优化的模型,Reward给回复打分,Reference通过KL散度约束Policy不要偏离Reference太远,防止reward hacking,Value预测平均水平用于计算Advantage表示动作好坏。更新时,PPO计算新旧策略的概率比r,用Clip机制将r限制在一定范围内(如0.8到1.2),再与Advantage相乘得到Loss进行反向传播。Clip的作用是防止单次更新幅度过大,保证训练稳定。
2. DPO(Direct Preference Optimization )
2.1 DPO的动机:PPO太复杂了

2.2 DPO的核心思想

2.3 偏好数据张什么样
DPO使用成对偏好数据:

2.4 直觉理解 & 数学公式

DPO的数学公式: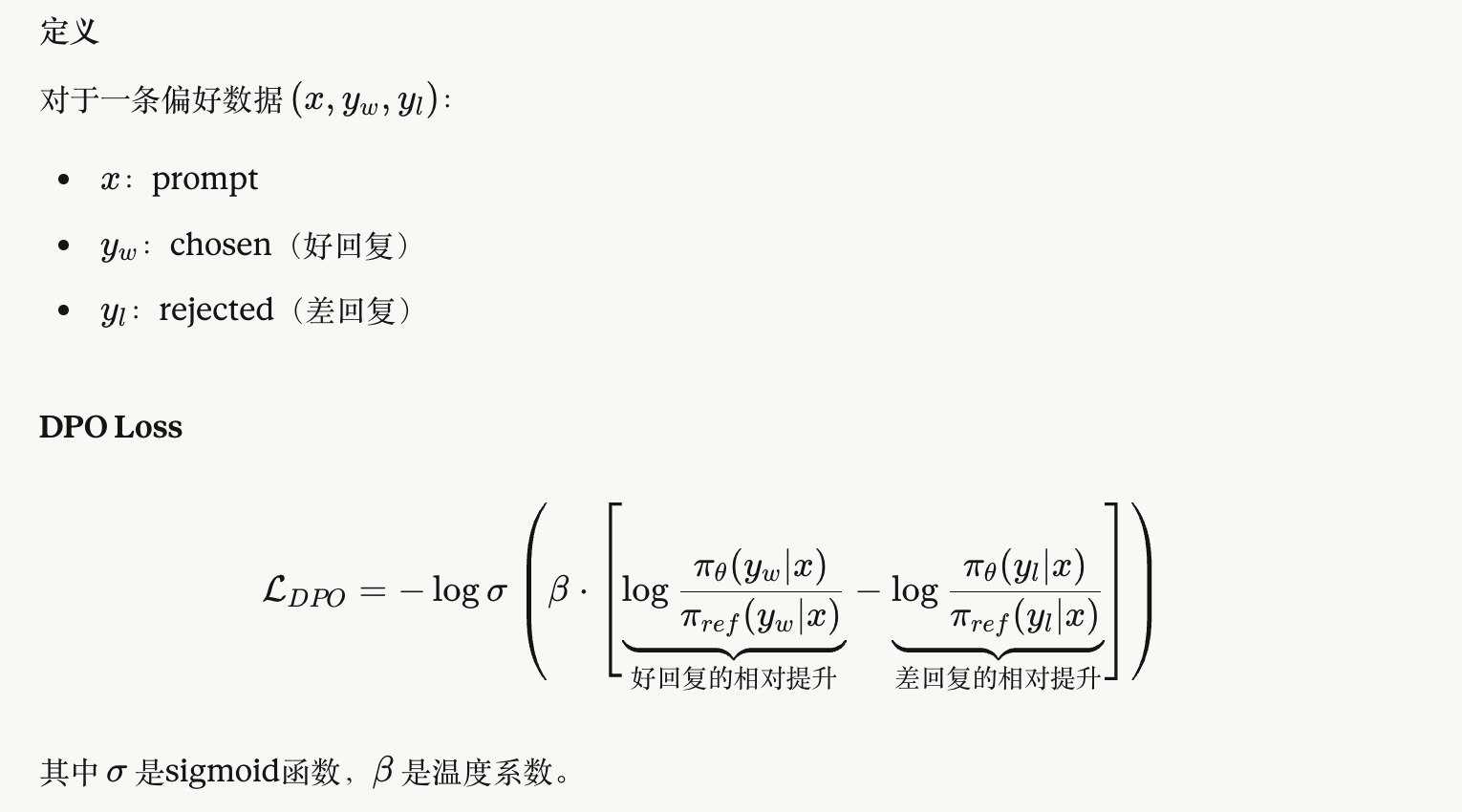
用具体数值理解:

2.5 DPO vs. PPO
- 在线生成:PPO训练时要实时用Policy生成回复,计算量大但能探索新策略。 离线学习:DPO用预先准备好的数据,计算量小但只能学数据集覆盖的内容。
- 训练流程对比
# PPO
┌─────────────────────────────────────────────────────────────┐
│ 1. Policy生成回复 │
│ 2. Reward Model打分 │
│ 3. Reference Model算KL │
│ 4. Value Model算Advantage │
│ 5. PPO更新(clip机制) │
└─────────────────────────────────────────────────────────────┘
需要:在线生成、4个模型、复杂的RL循环
# DPO
┌─────────────────────────────────────────────────────────────┐
│ 1. 读取偏好数据 (prompt, chosen, rejected) │
│ 2. Policy算chosen和rejected的概率 │
│ 3. Reference算chosen和rejected的概率 │
│ 4. 算DPO Loss,反向传播 │
└─────────────────────────────────────────────────────────────┘
需要:离线数据、2个模型、简单的分类Loss
2.6 归纳DPO
- 详细版本:
DPO(Direct Preference Optimization)是一种简化的RLHF算法,核心思想是绕过Reward Model,直接从偏好数据优化策略。DPO只需要两个模型:Policy Model是要训练的目标模型,Reference Model是SFT后冻结的参考模型。训练数据是成对的偏好数据,每条包含一个prompt、一个好回复(chosen)和一个差回复(rejected)。DPO的目标是让Policy相对于Reference更倾向于生成好回复、更不倾向于生成差回复。具体做法是计算Policy和Reference对两个回复的概率比,然后最大化好回复的相对提升与差回复的相对提升之差。DPO的数学基础是RLHF最优解的闭式形式——Reward可以用策略概率比隐式表示,因此不需要显式训练Reward Model。相比PPO,DPO更简单稳定(只需2个模型、无需在线生成、是简单的分类Loss),但缺点是离线学习没有探索能力,效果依赖偏好数据的质量。
- 精简版:
DPO绕过Reward Model,直接从偏好数据优化Policy。只需要Policy和Reference两个模型,训练数据是成对的好/差回复。DPO让模型更倾向好回复、更不倾向差回复,通过最大化两者概率比之差实现。数学上,DPO利用了RLHF最优解的闭式形式,把强化学习问题转化为简单的分类问题。优点是简单稳定,缺点是离线学习没有探索能力。
3. GRPO (Group Relative Policy Optimization)
3.1 GRPO的目标
保留PPO的在线探索能力,但去掉Value Model。

3.2 回顾:Value Model在PPO中的作用
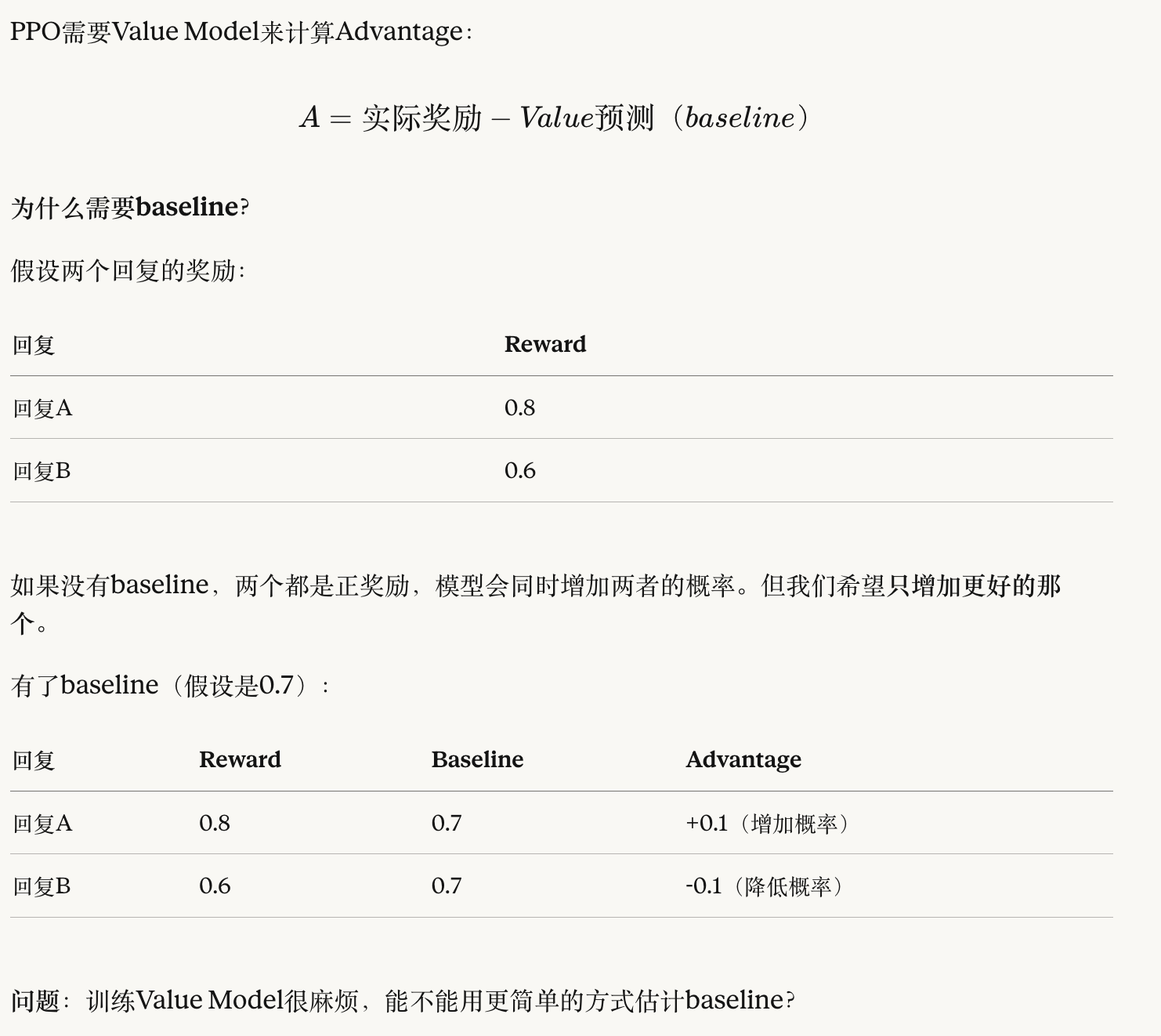
3.3 GRPO的核心思想
对同一个prompt生成一组回复,用组内平均奖励作为baseline。
不需要训练额外的Value Model!
用例子理解GRPO:
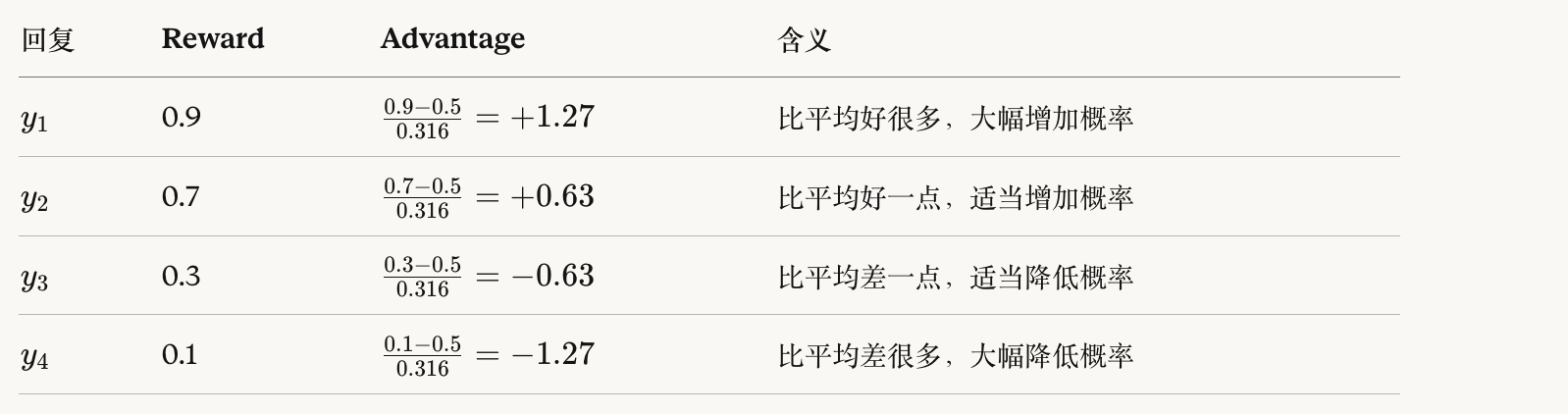
关键洞察:
- 不需要Value Model:用组内均值代替
- 相对排名:只关心组内谁好谁差,不关心绝对分数
- 自动标准化:Advantage有正有负,梯度方向明确
3.4 GRPO的完整流程
┌─────────────────────────────────────────────────────────────┐
│ GRPO 训练一轮 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Step 1: 对每个prompt生成一组回复 │
│ ┌─────────────┐ │
│ │ Policy模型 │ prompt: "如何学Python?" │
│ │ │ ──→ 生成G个回复(如G=4) │
│ └─────────────┘ y₁, y₂, y₃, y₄ │
│ │
│ Step 2: 获取每个回复的奖励 │
│ ┌─────────────┐ │
│ │ Reward模型 │ ──→ r₁=0.9, r₂=0.7, r₃=0.3, r₄=0.1 │
│ │ (或规则) │ │
│ └─────────────┘ │
│ │
│ Step 3: 组内标准化得到Advantage │
│ │
│ mean = (0.9+0.7+0.3+0.1)/4 = 0.5 │
│ std = 0.316 │
│ │
│ A₁ = (0.9-0.5)/0.316 = +1.27 │
│ A₂ = (0.7-0.5)/0.316 = +0.63 │
│ A₃ = (0.3-0.5)/0.316 = -0.63 │
│ A₄ = (0.1-0.5)/0.316 = -1.27 │
│ │
│ Step 4: 计算KL惩罚 │
│ ┌─────────────┐ │
│ │Reference模型│ ──→ 计算每个回复的KL散度 │
│ └─────────────┘ │
│ │
│ Step 5: PPO风格更新(带Clip) │
│ │
│ 对每个回复: │
│ r = P_new / P_old │
│ loss = -min(r × A, clip(r) × A) + β × KL │
│ │
│ 反向传播,更新Policy参数 │
│ │
└─────────────────────────────────────────────────────────────┘
3.5 为什么DeepSeek-R1用GRPO?
因为数学推理的特殊性。数学问题有明确的对错,不需要学习Reward Model。
def math_reward(prompt, response):
"""规则奖励:答案对就是1,错就是0"""
predicted_answer = extract_answer(response)
correct_answer = get_ground_truth(prompt)
if predicted_answer == correct_answer:
return 1.0 # 答对了
else:
return 0.0 # 答错了
3.6 GRPO的特点& 比较
GRPO的优势:
| 特点 | 对数学推理的好处 |
|---|---|
| 在线生成 | 能探索不同的推理路径 |
| 组内对比 | 同一题目多个解法,保留好的、淘汰差的 |
| 不需要Value Model | 简化训练,规则奖励足够 |
| 不需要学习RM | 数学对错是客观的,不需要学 |
GRPO的局限性:
| 局限 | 解释 |
|---|---|
| 需要在线生成 | 比DPO计算量大 |
| 组内方差问题 | 如果所有回复都差不多,标准化后梯度很小 |
| 需要奖励信号 | 必须有RM或规则奖励,不像DPO只需要偏好数据 |
| 组大小权衡 | 组太小则baseline估计不准,组太大则计算量大 |
三种方法总结对比图:
┌─────────────────────────────────────────────────────────────┐
│ RLHF 三种方法对比 │
├─────────────────────────────────────────────────────────────┤
│ │
│ PPO: 最完整,4个模型,在线生成,探索能力强 │
│ └─→ 适合:通用场景,资源充足 │
│ │
│ DPO: 最简单,2个模型,离线学习,无探索 │
│ └─→ 适合:有高质量偏好数据,追求简单稳定 │
│ │
│ GRPO: 折中方案,3个模型,在线生成,组内对比 │
│ └─→ 适合:有规则奖励(如数学),需要探索但想简化 │
│ │
│ 复杂度: PPO > GRPO > DPO │
│ 探索性: PPO ≈ GRPO > DPO │
│ 稳定性: DPO > GRPO > PPO │
│ │
└─────────────────────────────────────────────────────────────┘
3.7 归纳GRPO
- 详细版本:
GRPO(Group Relative Policy Optimization)是DeepSeek提出的强化学习算法,核心思想是用组内相对排名代替Value Model来估计baseline。GRPO需要三个模型:Policy Model是要训练的目标模型,Reference Model用于KL约束防止策略偏离太远,Reward Model(或规则函数)对回复打分。训练时,对每个prompt用当前Policy生成一组回复(比如4-8个),获取每个回复的奖励后,用组内均值作为baseline、组内标准差做归一化,得到每个回复的Advantage。Advantage为正表示这个回复比组内平均好,应该增加概率;为负则应该降低概率。最后用PPO的Clip机制更新参数,限制每次更新幅度保证稳定。相比PPO,GRPO去掉了Value Model,简化了训练;相比DPO,GRPO保留了在线生成的探索能力。GRPO特别适合有明确规则奖励的场景(如数学推理),DeepSeek-R1就是用GRPO训练的,因为数学答案的对错可以直接判断,不需要学习Reward Model。
- 简洁版本:
GRPO用组内相对排名代替Value Model:对同一个prompt生成多个回复,用组内均值作为baseline计算Advantage,好于平均的增加概率、差于平均的降低概率。相比PPO少了Value Model,相比DPO保留了在线探索能力。特别适合有规则奖励的场景,如数学推理(答案对错可直接判断)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)