AI超级智能体学习笔记day2-鱼皮
1)选择合适的接口实现,实现以下接口之一或同时实现两者(更建议同时实现):CallAroundAdvisor:用于处理同步请求和响应(非流式)StreamAroundAdvisor:用于处理流式请求和响应2)实现核心方法对于非流式处理 (CallAroundAdvisor),实现 aroundCall 方法对于流式处理 (StreamAroundAdvisor),实现 a
目录
Spring AI ChatClient / Advisor / ChatMemory 特性
阶段三
Prompt 工程基本概念/Prompt 优化技巧
总之就是多角度多方面描述,细致一点就对了。
AI 恋爱大师应用需求分析/AI 恋爱大师应用方案设计
MVP 最小可行产品策略
MVP 最小可行产品策略是指先开发包含 核心功能 的基础版本产品快速推向市场,以最小成本验证产品假设和用户需求。通过收集真实用户反馈进行迭代优化,避免开发无人使用的功能,降低资源浪费和开发风险。
Prompt可以ai生成,需求分析可以ai生成,方案设计可以ai生成
Spring AI ChatClient / Advisor / ChatMemory 特性
ChatClient
自己构造的 ChatClient,可实现功能更丰富、更灵活的 AI 对话客户端,也更推荐通过这种方式调用 AI。
两种构造方法:
@Service
public class ChatService {
private final ChatClient chatClient;
public ChatService(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是恋爱顾问")
.build();
}
}
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("你是恋爱顾问")
.build();
多种响应格式:
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();
//Java 16+ 引入的「记录(Record)」 定义,用于简洁地创建一个「不可变的数据载体类」
record ActorFilms(String actor, List<String> movies) {}
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);
//返回泛型集合
List<ActorFilms> multipleActors = chatClient.prompt()
.user("Generate filmography for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {});
//流式返回,文本是逐段实时输出的
//Flux是 Reactor 框架的核心类型,代表异步、非阻塞、可背压的流式序列:
Flux<String> streamResponse = chatClient.prompt()
.user("Tell me a story")
.stream()
.content();
Flux<ChatResponse> streamWithMetadata = chatClient.prompt()
.user("Tell me a story")
.stream()
.chatResponse();
设置默认参数
//设置可被替换的模板,动态注入
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
chatClient.prompt()
.system(sp -> sp.param("voice", voice))
.user(message)
.call()
.content());
Advisor/拦截器
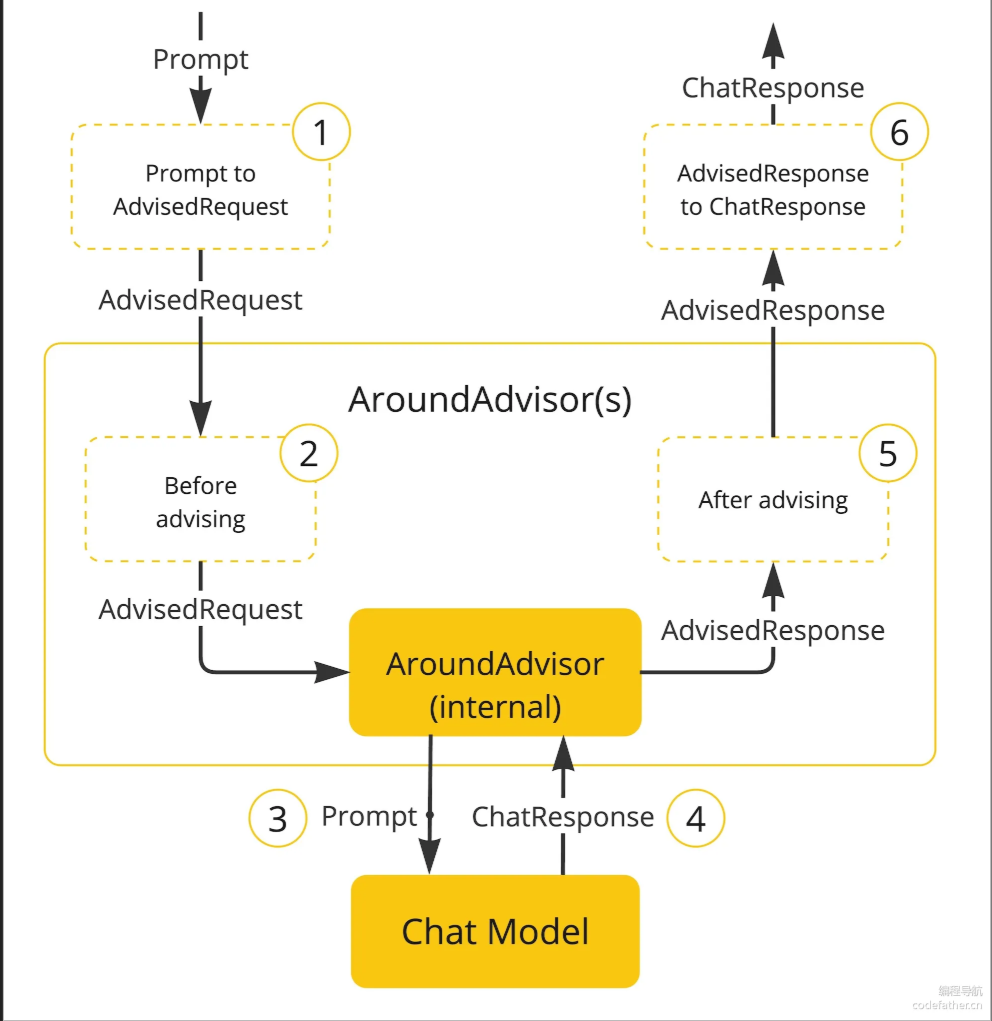
创建一个空的 AdvisorContext 对象,用于传递信息。责任链模式的设计思想。
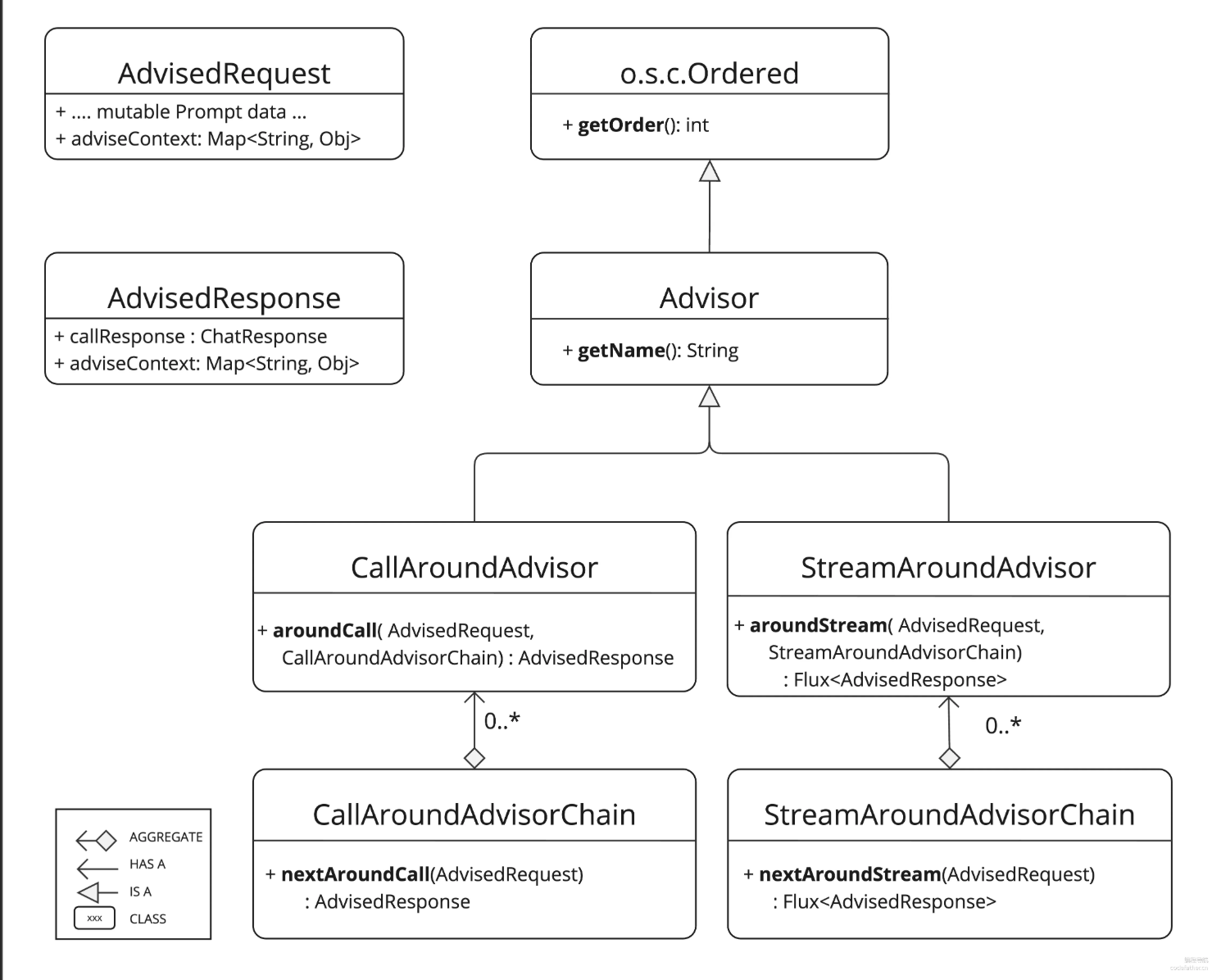
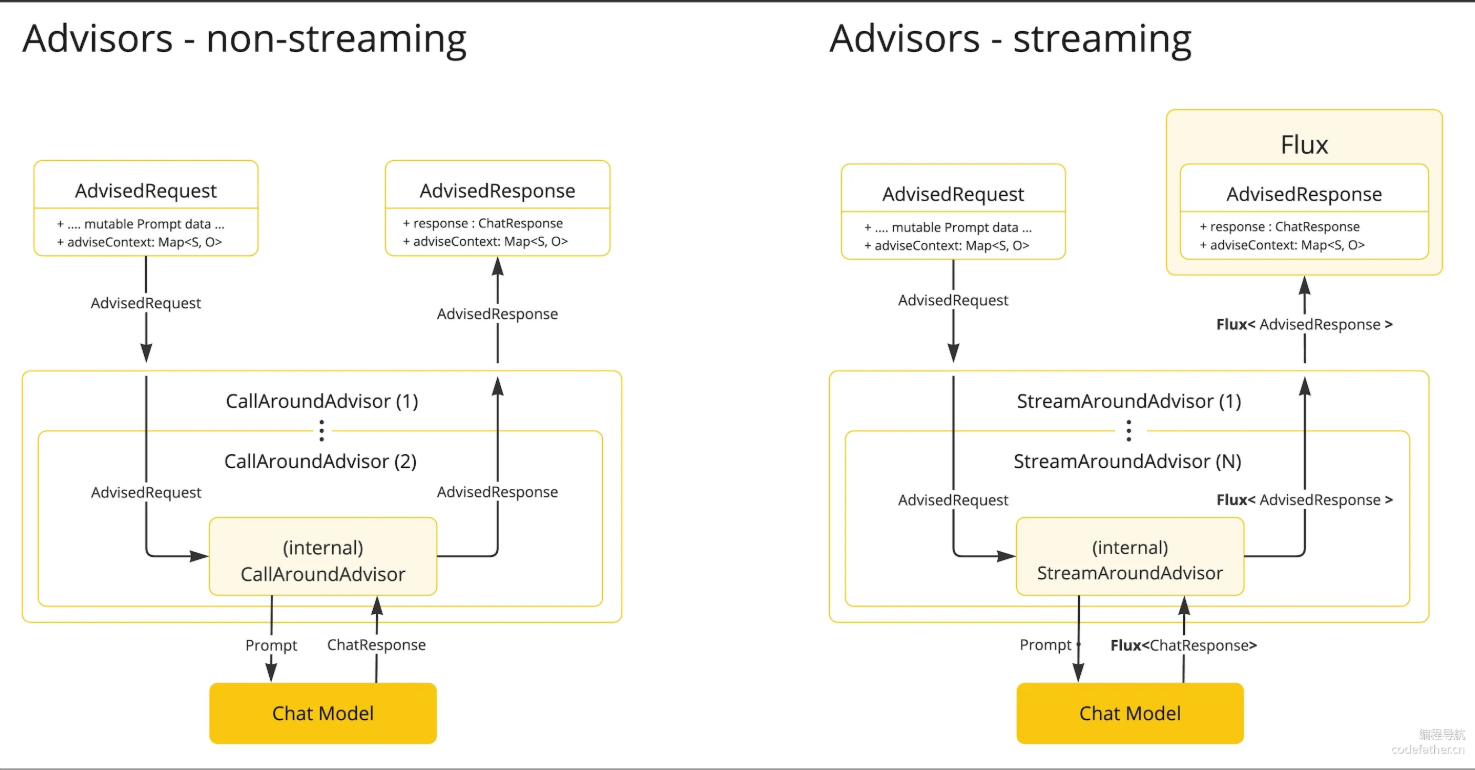
Advisors 分为 2 种模式:流式 Streaming 和非流式 Non-Streaming,二者在用法上没有明显的区别,返回值不同罢了。
示例代码:
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
new QuestionAnswerAdvisor(vectorStore)
)
.build();
String response = this.chatClient.prompt()
//绑定历史会话与限制会话长度
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(userText)
.call()
.content();
Chat Memory Advisor
三种实现:
- MessageChatMemoryAdvisor:从记忆中检索历史对话,并将其作为消息集合添加到提示词中(更结构化,常用)
- PromptChatMemoryAdvisor:从记忆中检索历史对话,并将其添加到提示词的系统文本中(可能会失去原始的消息边界)
- VectorStoreChatMemoryAdvisor:可以用向量数据库来存储检索历史对话
Chat Memory
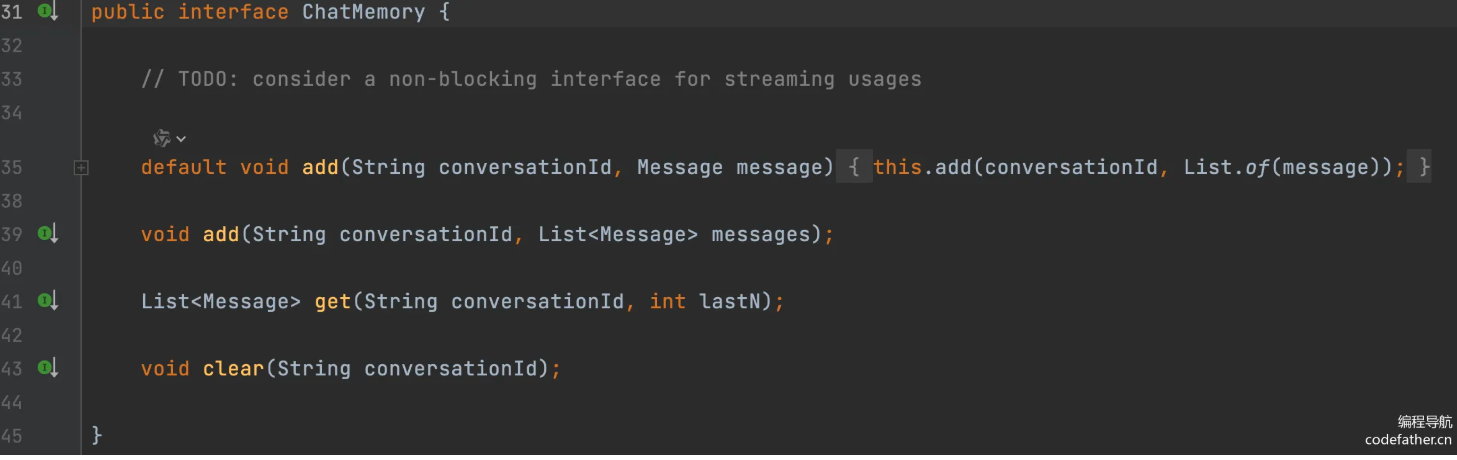
- InMemoryChatMemory:内存存储
- CassandraChatMemory:在 Cassandra 中带有过期时间的持久化存储
- Neo4jChatMemory:在 Neo4j 中没有过期时间限制的持久化存储
- JdbcChatMemory:在 JDBC 中没有过期时间限制的持久化存储
当然也可以通过实现 ChatMemory 接口自定义数据源的存储
多轮对话 AI 应用开发
CTRL+SHIFT+T创建测试类
引入Springai依赖
@SpringBootTest//启动完整的 Spring 上下文(ApplicationContext)
Assertions.assertNotNull(answer); 是 JUnit 测试框架中用于断言的核心方法,核心作用是「验证 answer 变量的值不是 null」,如果 answer 是 null,则测试会直接失败并抛出断言异常。
“断言”(Assertion)在编程(尤其是测试)中,是开发者对程序运行结果的 “预期声明”
简单说:断言 = 「我预判结果是这样」 + 「不符合预判就立刻提醒我」。
问题:缺失springai包导致无法导入org.springframework.ai.chat.model.ChatModel;
我先通过ai重新引入springai包,但又发生各种冲突。所以最后还是选择阶段二鱼皮用的包,仍然出现各种警告,我把springboot重新降为3.4.4版本,解决一大部分,少部分红色警告就没管了。
Spring AI 自定义 Advisor
自定义日志 Advisor
1)选择合适的接口实现,实现以下接口之一或同时实现两者(更建议同时实现):
CallAroundAdvisor:用于处理同步请求和响应(非流式)
StreamAroundAdvisor:用于处理流式请求和响应
2)实现核心方法
对于非流式处理 (CallAroundAdvisor),实现 aroundCall 方法
对于流式处理 (StreamAroundAdvisor),实现 aroundStream 方法
3)设置执行顺序
通过实现getOrder()方法指定 Advisor 在链中的执行顺序。值越小优先级越高,越先执行
4)提供唯一名称
为每个 Advisor 提供一个唯一标识符
更改springai日志输出级别:1.修改配置文件2.自定义日志 Advisor
logging:
level:
org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor: debug
Spring Boot 定义的 “通用日志配置语法”,最终由 Logback(默认)执行生效。
aroundStream 方法的返回,通过 MessageAggregator 工具类将 Flux 响应聚合成单个 AdvisedResponse。这对于日志记录或其他需要观察整个响应而非流中各个独立项的处理非常有用。
Re-Reading Advisor
.userParams(advisedUserParams):将包含re2_input_query的参数 Map 绑定到新请求 —— 这是模板变量替换的关键,Spring AI 会自动把 Prompt 中的{re2_input_query}替换为参数值;
可以使用 adviseContext 在 Advisor 链中共享状态
Spring AI 结构化输出 - 恋爱报告功能
知识前提
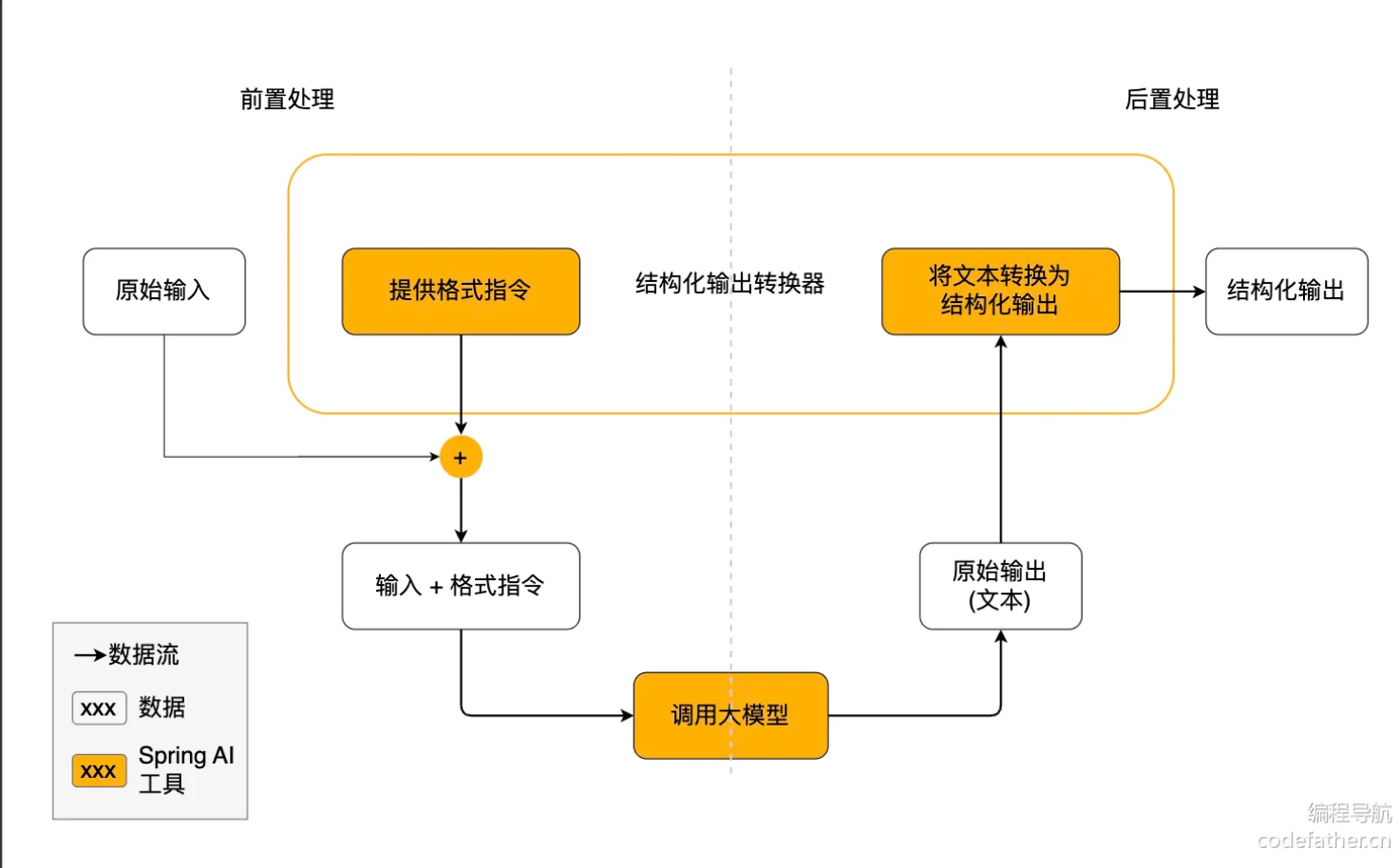
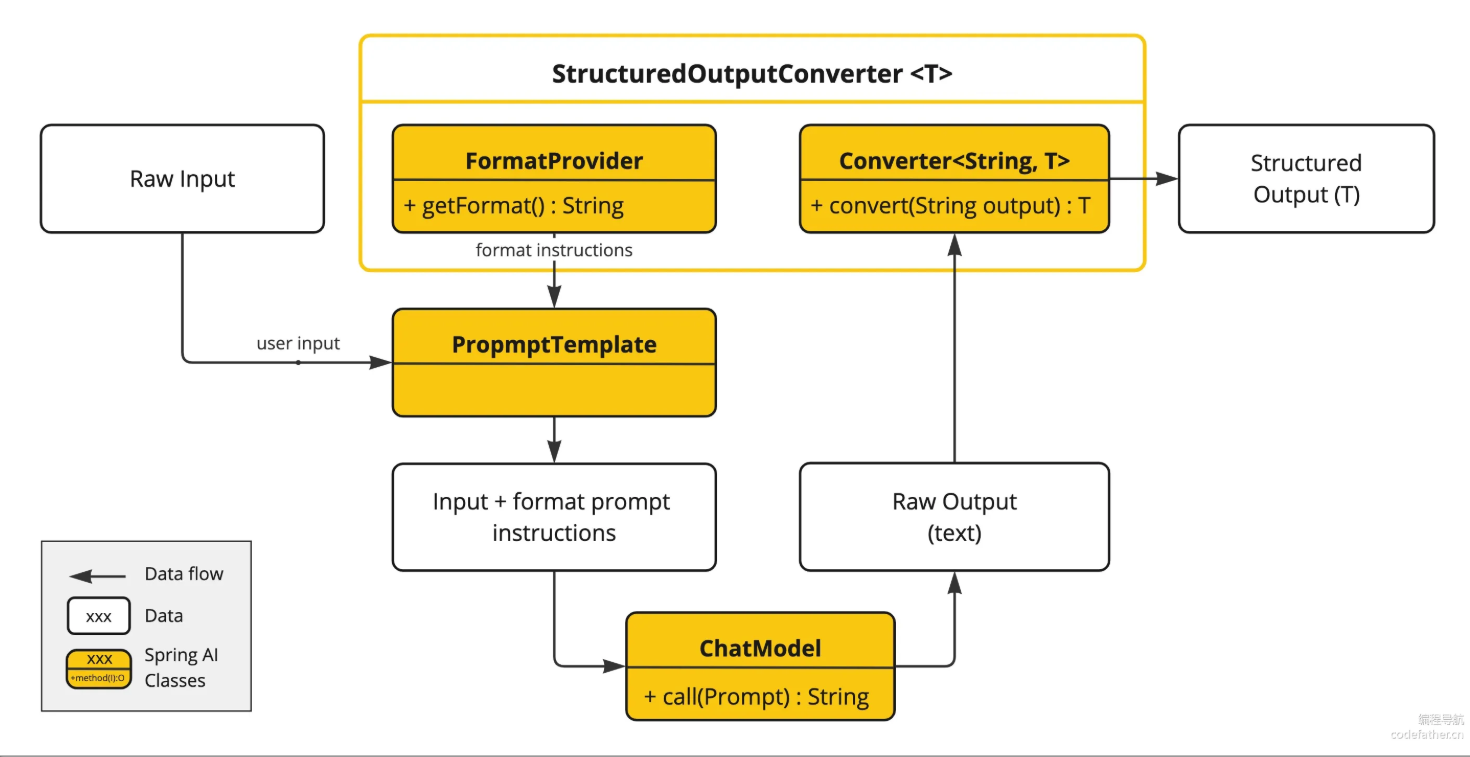
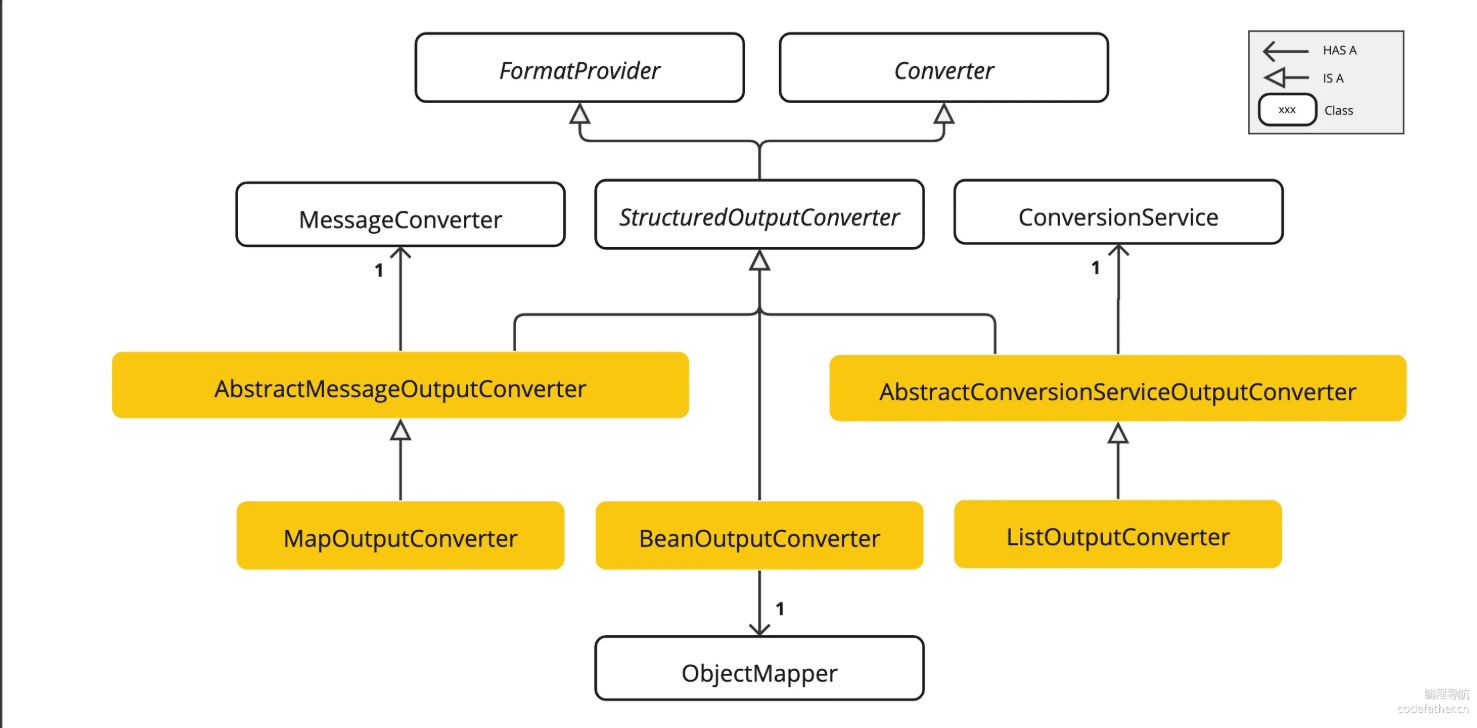
Spring AI 提供了多种转换器实现,分别用于将输出转换为不同的结构:
- AbstractConversionServiceOutputConverter:提供预配置的 GenericConversionService,用于将 LLM 输出转换为所需格式
- AbstractMessageOutputConverter:支持 Spring AI Message 的转换
- BeanOutputConverter:用于将输出转换为 Java Bean 对象(基于 ObjectMapper 实现)
- MapOutputConverter:用于将输出转换为 Map 结构
- ListOutputConverter:用于将输出转换为 List 结构
功能开发
依赖-record定义类-方法-测试代码(在实现中以上功能都由entity(LoveReport.class)实现)
1. 加工格式指令(对应流程图的「提供格式指令」)
entity(...) 会自动做以下操作:
- 扫描
LoveReport类的字段(比如标题、建议列表); - 用
jsonschema-generator生成对应的 JSON Schema(格式指令); - 把这个格式指令自动拼到你的
systemPrompt 里,告诉 AI “必须按这个格式输出”。
2. 结构化输出(对应流程图的「将文本转换为结构化输出」)
AI 返回文本后,entity(...) 会:
- 把 AI 输出的文本(符合格式指令的 JSON),自动解析为
LoveReport类的实例; - 最终返回这个实例(就是你代码里的
loveReport)。
Spring AI 对话记忆持久化
- InMemoryChatMemory:内存存储
- CassandraChatMemory:在 Cassandra 中带有过期时间的持久化存储
- Neo4jChatMemory:在 Neo4j 中没有过期时间限制的持久化存储
- JdbcChatMemory:在 JDBC 中没有过期时间限制的持久化存储
自定义实现 ChatMemory
我们本能地会想到通过 JSON 进行序列化,但实际操作中,我们发现这并不容易。原因是:
- 要持久化的 Message 是一个接口,有很多种不同的子类实现(比如 UserMessage、SystemMessage 等)
- 每种子类所拥有的字段都不一样,结构不统一
- 子类没有无参构造函数,而且没有实现 Serializable 序列化接口

选择高性能的 Kryo 序列化库
依赖-实现chatmemory的类-修改构造函数-测试
Spring AI Prompt 模板特性
Spring AI 提供了几种专用的模板类,对应不同角色的消息:
- SystemPromptTemplate:用于系统消息,设置 AI 的行为和背景
- AssistantPromptTemplate:用于助手消息,用于设置 AI 回复的结构
- FunctionPromptTemplate:目前没用
用Map替换
从文件加载模板
@Value("classpath:/prompts/system-message.st")
private Resource systemResource;
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);多模态概念和开发
1、Spring AI 多模态开发
2、平台 SDK 多模态开发
使用的通义千文-图像编辑功能
碎碎念:写的好糟糕,才发现有MD编辑器,格式乱成一坨了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)