Yolov5训练自定义数据集的步骤
本文介绍了使用Yolov5训练自定义数据集并进行目标检测的全过程。主要内容包括:1)数据集制作,通过getframe.py提取视频帧图像,使用Labelme标注后转换为YOLO格式;2)训练阶段,配置yaml文件并运行train.py进行模型训练;3)推理测试,使用detect.py加载训练好的权重进行实时检测。文中提供了详细的代码实现和配置说明,展示了从视频帧提取到最终检测的全流程,包括Open
文章目录
1 前言
本博客记录的内容是通过Yolov5工程训练自制数据集并进行推理。
2 项目内容详细说明
2.1 数据集制作(原始视频图像帧的提取)
如下图为数据集制作文件夹内容,其中mp4视频即需要制作数据集的画面。
首先通过getframe.py将video1217.mp4按帧提取出图像到当前文件夹内的image文件夹内。
然后在当前文件夹内通过命令行打开Labelme。

然后在labelme中Open Dir定位到上面保存的Image文件夹。
由于按帧提取视频可能有大量相似图像的存在,没必要一张张地标注,可以跳着标(也可以修改提取代码,间隔一定时间再提取帧),将标注过的json文件直接放置在image文件夹(这样做的好处是方便想要补充数据的时候直接标)。
运行copySameName.py将已经经过标注的图片和json文件拷贝到datasets文件夹中去(通过判断image文件夹中哪些同名文件既有jpg格式也有json格式的)。
文件夹中有一个J8MoniCangSwitch名称的文件夹,里面放置的是一个datasets文件夹cabinswitch_parameter.yaml以及cabinswitch_yolov5s.yaml文件。
datasets文件夹内有image以及labels文件夹,每个文件夹内又分别有train和test两个文件夹。可以在labels文件夹内再放一个train_json文件夹用来先暂时存放标注的json文件(需要转化成txt格式)。
datasets通过jsonTotxt.py脚本将label里面的train_json标注全部转换成txt类型标注放入train文件夹。
下面是cabinswitch_parameter.yaml文件的内容,需要修改nc以及names字段的内容,按照自己的需求填写。
下面是cabinswitch_yolov5s.yaml文件的内容,需要修改nc字段的内容。其他内容默认了,不要轻易修改。
2.2 训练
将上一步做好的数据集放置在从github下载下来的yolov5官方工程文件夹yolov5-master文件夹内,修改train.py 文件下面红色箭头指向的项目为你需要的项目。
在你的环境下,直接python train.py。看到下面的内容则表明正常开始训练了。
2.3 推理
在你的环境下,运行python detect.py --weights yolov5s.pt --source 0这样就是加载当前目录下的yolov5s.pt权重文件以及将摄像头0作为输入数据源。
下图是检测到盒子为Close的状态。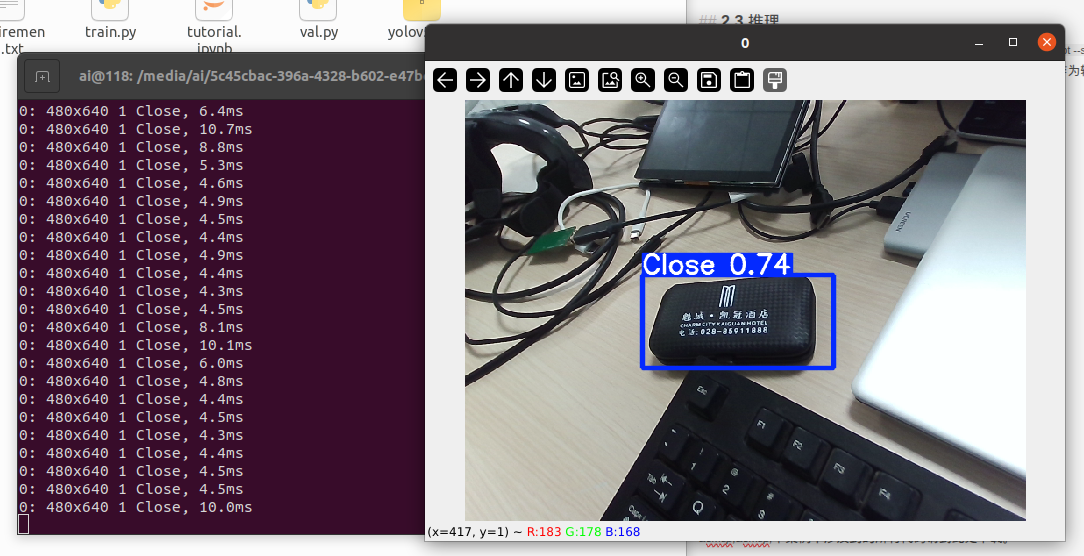
下图是检测到盒子为Open的状态。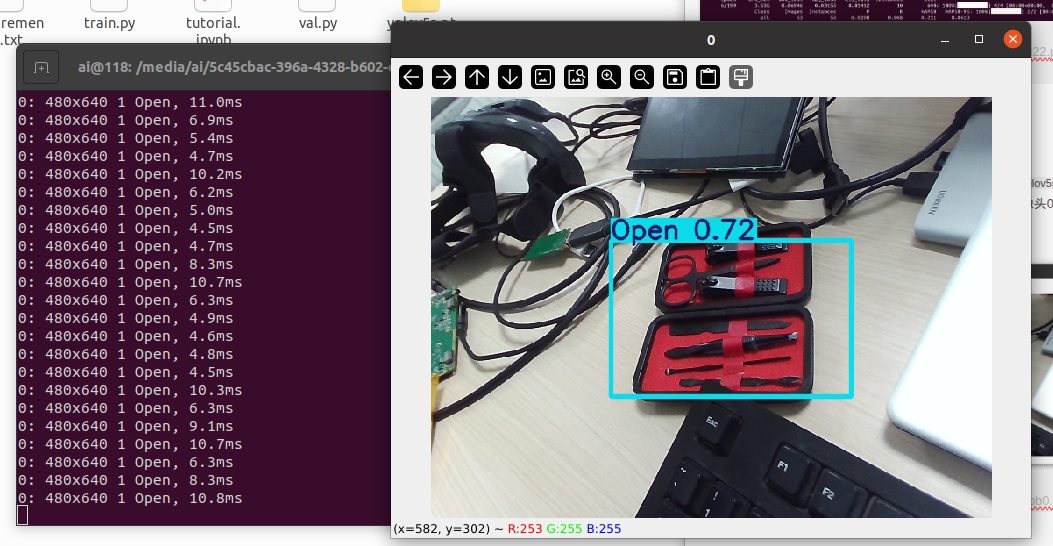
下图是图像中没有检测出目标物体的情况。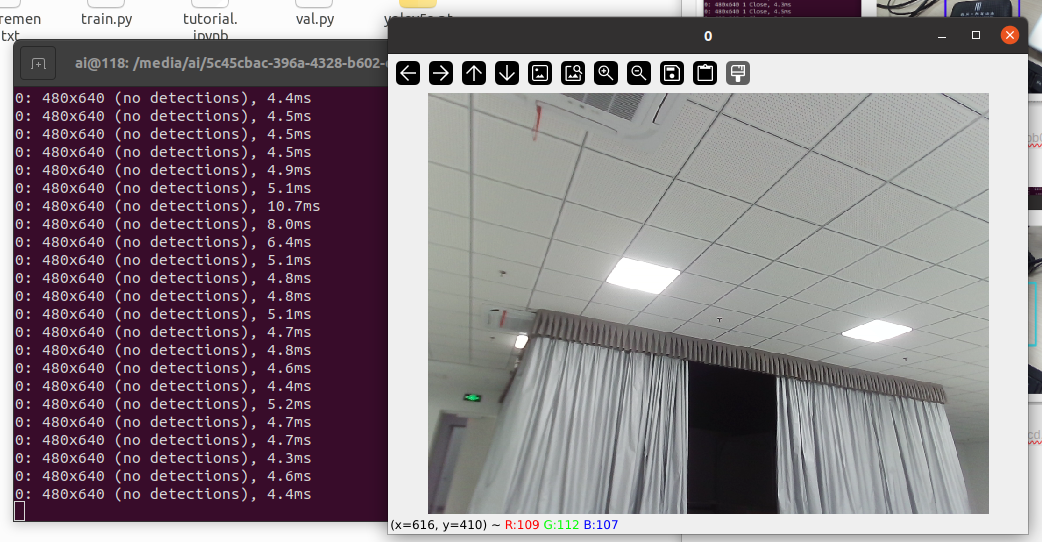
3 代码
3.1 getframe.py
getframe.py实现如下所示。
import cv2
import os
import sys
def extract_frames_to_image_folder(video_path, frame_interval=1, image_format='jpg', quality=95):
"""
从MP4视频中提取帧并保存到当前目录的image文件夹
参数:
video_path: 视频文件路径
frame_interval: 帧间隔,默认为1(提取每一帧)
image_format: 图片格式,支持'jpg', 'png'
quality: 图片质量(仅对jpg有效),1-100
"""
# 检查视频文件是否存在
if not os.path.exists(video_path):
print(f"错误:视频文件不存在 - {video_path}")
return False
# 创建image文件夹
current_dir = os.getcwd()
image_folder = os.path.join(current_dir, "image")
# 如果image文件夹不存在则创建
if not os.path.exists(image_folder):
os.makedirs(image_folder)
print(f"创建文件夹: {image_folder}")
print(f"图片将保存到: {image_folder}")
# 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("错误:无法打开视频文件")
return False
# 获取视频信息
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(f"\n视频信息:")
print(f" 文件名: {os.path.basename(video_path)}")
print(f" 分辨率: {width}x{height}")
print(f" 总帧数: {total_frames}")
print(f" 帧率: {fps:.2f}")
print(f" 图片格式: {image_format}")
print(f" 帧间隔: {frame_interval}")
print(f" 文件名格式: 0000.{image_format}, 0001.{image_format}, ...")
frame_count = 0
saved_count = 0
print(f"\n开始提取帧...")
try:
while True:
ret, frame = cap.read()
if not ret:
break
# 按间隔保存帧
if frame_count % frame_interval == 0:
# 生成文件名,使用4位数格式,如 0000.jpg
if image_format.lower() in ['jpg', 'jpeg']:
filename = f"{saved_count:04d}.jpg"
filepath = os.path.join(image_folder, filename)
cv2.imwrite(filepath, frame, [cv2.IMWRITE_JPEG_QUALITY, quality])
elif image_format.lower() == 'png':
filename = f"{saved_count:04d}.png"
filepath = os.path.join(image_folder, filename)
cv2.imwrite(filepath, frame)
else:
print(f"错误:不支持的图片格式 {image_format}")
return False
saved_count += 1
# 每处理100帧显示一次进度
if saved_count % 100 == 0:
print(f"已保存 {saved_count} 张图片...")
frame_count += 1
except KeyboardInterrupt:
print("\n\n用户中断,停止提取...")
except Exception as e:
print(f"\n\n发生错误: {str(e)}")
return False
finally:
# 释放资源
cap.release()
cv2.destroyAllWindows()
print(f"\n完成!")
print(f"处理总帧数: {frame_count}")
print(f"保存图片数: {saved_count}")
print(f"图片保存在: {image_folder}")
return True
def main():
if len(sys.argv) < 2:
print("使用方法: python extract_frames.py <视频文件> [帧间隔] [图片格式] [质量]")
print("示例:")
print(" python extract_frames.py video.mp4")
print(" python extract_frames.py video.mp4 1 jpg 95")
print(" python extract_frames.py video.mp4 5 png")
print("\n参数说明:")
print(" 视频文件: 要处理的MP4视频文件路径")
print(" 帧间隔: 可选,默认1(提取每一帧)")
print(" 图片格式: 可选,默认jpg")
print(" 质量: 可选,仅对jpg有效,默认95")
print("\n输出:")
print(" 图片保存在当前目录的image文件夹中")
print(" 文件名格式: 0000.jpg, 0001.jpg, 0002.jpg, ...")
return
# 获取参数
video_path = sys.argv[1]
# 设置默认值
frame_interval = 1
image_format = 'jpg'
quality = 95
# 解析可选参数
if len(sys.argv) >= 3:
try:
frame_interval = int(sys.argv[2])
except:
print(f"警告:无效的帧间隔参数,使用默认值1")
if len(sys.argv) >= 4:
if sys.argv[3].lower() in ['jpg', 'jpeg', 'png']:
image_format = sys.argv[3].lower()
else:
print(f"警告:无效的图片格式,使用默认值jpg")
if len(sys.argv) >= 5 and image_format in ['jpg', 'jpeg']:
try:
quality = int(sys.argv[4])
if quality < 1 or quality > 100:
quality = 95
print(f"警告:质量参数应在1-100之间,使用默认值95")
except:
print(f"警告:无效的质量参数,使用默认值95")
# 执行提取
extract_frames_to_image_folder(
video_path=video_path,
frame_interval=frame_interval,
image_format=image_format,
quality=quality
)
if __name__ == "__main__":
print("=" * 60)
print("MP4视频帧提取工具")
print("=" * 60)
# 检查OpenCV是否安装
try:
cv2_version = cv2.__version__
print(f"OpenCV版本: {cv2_version}")
except:
print("错误:未安装OpenCV!")
print("请先安装: pip install opencv-python")
sys.exit(1)
main()
3.2 copySameName.py
copySameName.py实现如下所示。
import os
import shutil
import argparse
# 在代码中直接指定路径
source_folder = "/media/ai/5c45cbac-396a-4328-b602-e47bc899eb89/ai/XR_SERVER/1222/video12221459/image" # 替换为你的源文件夹路径
target_folder = "/media/ai/5c45cbac-396a-4328-b602-e47bc899eb89/ai/XR_SERVER/1222/video12221459/datasets" # 替换为你的目标文件夹路径
def copy_matching_files(source_dir, target_dir):
"""
将源文件夹中所有同名的jpg和json文件复制到目标文件夹
Args:
source_dir (str): 源文件夹路径
target_dir (str): 目标文件夹路径
"""
# 创建目标文件夹(如果不存在)
os.makedirs(target_dir, exist_ok=True)
# 获取源文件夹中所有文件
all_files = os.listdir(source_dir)
# 分离jpg和json文件
jpg_files = [f for f in all_files if f.lower().endswith('.jpg')]
json_files = [f for f in all_files if f.lower().endswith('.json')]
# 获取不带扩展名的文件名
jpg_names = {os.path.splitext(f)[0] for f in jpg_files}
json_names = {os.path.splitext(f)[0] for f in json_files}
# 找到同名的文件(既有jpg又有json)
matching_names = jpg_names & json_names
print(f"找到 {len(matching_names)} 对匹配的jpg和json文件")
# 复制文件
copied_count = 0
for name in matching_names:
jpg_file = name + '.jpg'
json_file = name + '.json'
# 构建完整路径
jpg_src = os.path.join(source_dir, jpg_file)
json_src = os.path.join(source_dir, json_file)
jpg_dst = os.path.join(target_dir, jpg_file)
json_dst = os.path.join(target_dir, json_file)
# 复制文件
try:
shutil.copy2(jpg_src, jpg_dst)
shutil.copy2(json_src, json_dst)
copied_count += 2
print(f"已复制: {jpg_file} 和 {json_file}")
except Exception as e:
print(f"复制失败 {jpg_file}/{json_file}: {e}")
print(f"复制完成!共复制了 {copied_count} 个文件 ({len(matching_names)} 对)")
def main():
copy_matching_files(source_folder, target_folder)
if __name__ == "__main__":
main()
3.3 jasonTotxt.py
jasonTotxt.py如下所示。
import json
import os
name2id = {'AUTOPILOT_PATH': 0,
'AUTOPILOT_ALT/HDG': 1,
'AUTOPILOT_ALT': 2,
'EAC_ARM': 3,
'EAC_OFF': 4,
'FLAPS_UP': 5,
'FLAPS_MVR': 6,
'FLAPS_DN': 7,
'RDRALTM_NRM': 8,
'RDRALTM_DIS': 9
} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = abs(box[2] - box[0])
h = abs(box[3] - box[1])
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = '/media/ai/5c45cbac-396a-4328-b602-e47bc899eb89/ai/XR_SERVER/1222/video12221459/J8MoniCangSwitch/datasets/labels/train/' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
print(txt_name)
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = '/media/ai/5c45cbac-396a-4328-b602-e47bc899eb89/ai/XR_SERVER/1222/video12221459/J8MoniCangSwitch/datasets/labels/train_json'
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
print(json_name)
decode_json(json_floder_path, json_name)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)