小米MiMo-V2-Flash技术解析:混合滑动窗口与MTP技术,让大模型推理如闪电般快速,附部署攻略
小米LLM团队发布的MiMo-V2-Flash模型采用MoE架构,总参数309B但激活参数仅15B。其核心技术包括混合滑动窗口注意力机制和轻量化多Token预测(MTP),实现2.7倍推理加速。模型通过三阶段预训练和MOPD多老师在线蒸馏范式进行后训练,在SWE-Bench软件工程榜单上登顶开源模型第一梯队,性能对标Kimi-K2-Thinking和DeepSeek-V3.2-Thinking,展
简介
小米LLM团队发布的MiMo-V2-Flash模型采用MoE架构,总参数309B但激活参数仅15B。其核心技术包括混合滑动窗口注意力机制和轻量化多Token预测(MTP),实现2.7倍推理加速。模型通过三阶段预训练和MOPD多老师在线蒸馏范式进行后训练,在SWE-Bench软件工程榜单上登顶开源模型第一梯队,性能对标Kimi-K2-Thinking和DeepSeek-V3.2-Thinking,展示了高效大模型的新范式。
在推理能力内卷的下半场,我们似乎习惯了“参数量越大模型越强”的逻辑。但就在刚刚,小米 LLM 团队发布了 MiMo-V2-Flash,用一组震撼的数据打破了这一常识:
- 参数仅 1/3,战力却对标 Kimi-K2 和 DeepSeek-V3 ;
- 2.6 倍推理加速,让 LLM 真正拥有“闪电”般的响应速度;
- 在 SWE-Bench 软件工程榜单上,更是直接问鼎开源模型第一梯队。
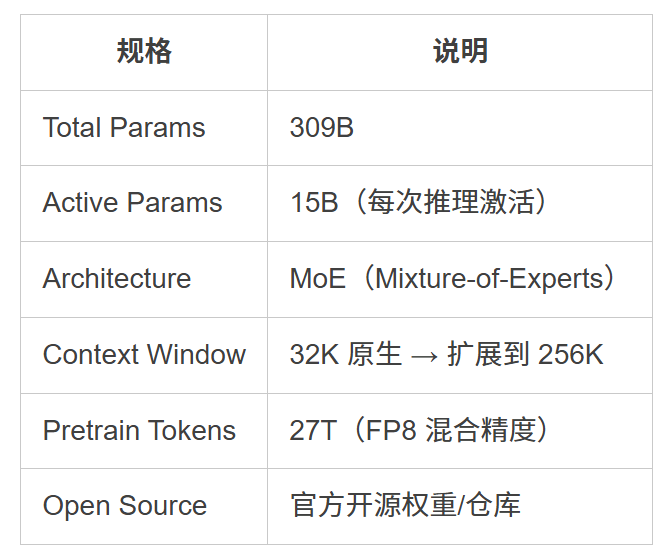
这个总参数 309B、激活参数仅 15B 的 MoE 模型,是如何在极低成本下实现“跨级反杀”的?小米的这份技术报告,或许藏着大模型高效推理的下一代答案………………
一、什么是MiMo-V2-Flash?
MiMo-V2-Flash 是小米 MiMo 团队发布的 MoE开源大模型,主打两件事:推理/Agent 能力要强,同时推理要快、成本要低。它不是“把模型做小”,而是通过 MoE 让每次推理只激活少量参数,从而在保持质量的同时提升吞吐。。它代表着小米进入竞争激烈的开放 LLM 领域的重要一步,将自己定位为 DeepSeek V3.2 和 Claude Sonnet 4.5 等模型的高性能且高效的替代品。
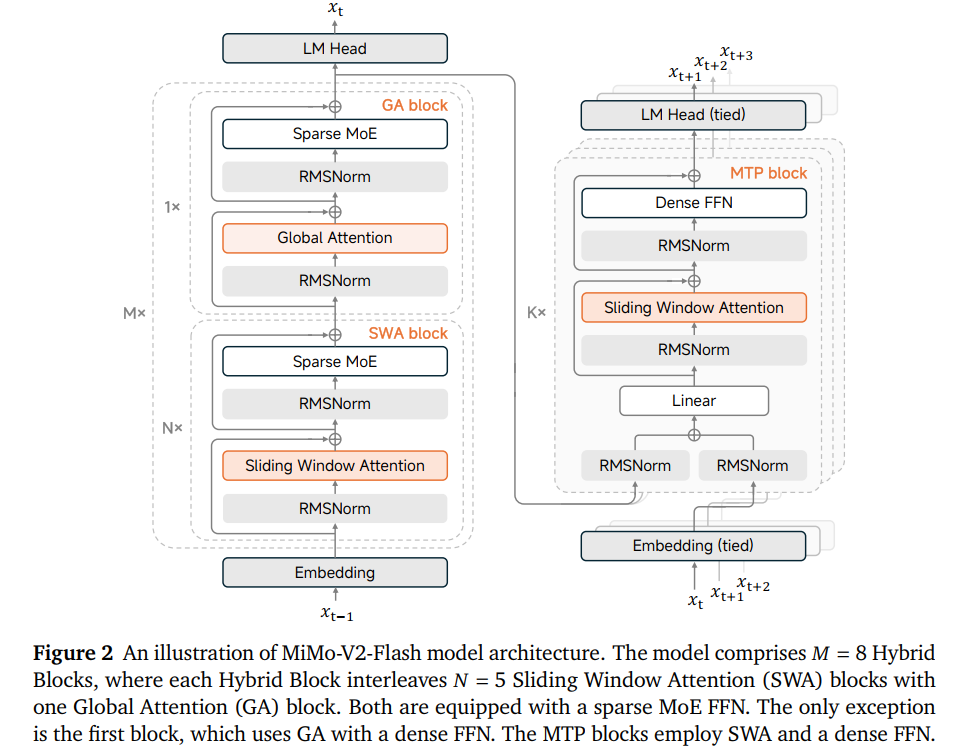
MiMo-V2-Flash 基于标准的 Transformer 架构,并深度集成了 Sparse MoE(稀疏专家混合) 设计 :
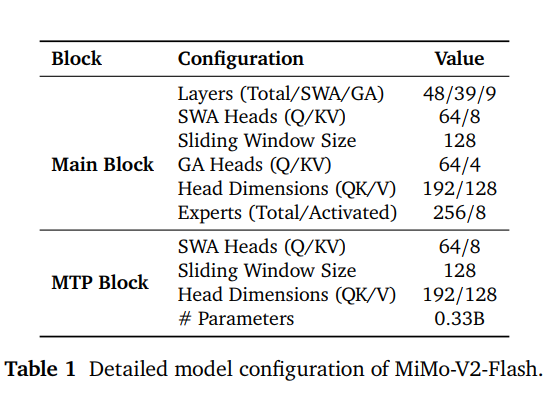
每个 MoE 层包含 256 个专家,推理时通过 Router 激活其中的 8 个专家 ,层内不设共享专家,全模型共 48 层 Transformer block。
1.1 混合滑动窗口注意力机制
为了突破长文本处理的算力瓶颈,小米引入了混合注意力架构,在局部和全局感知之间取得了黄金平衡。
- 5:1 黄金比例:模型将 48 个 Block 分为 8 个混合组(Hybrid Blocks),每组由 5 层滑动窗口注意力 (SWA) 和 1 层全局注意力 (GA) 组成 。
- SWA (39 层) :每层窗口大小仅为 128 个 token,极大降低了 KV-cache 存储压力 。
- GA (9 层) :负责捕捉跨越全局的长程依赖关系。
相比全全局注意力(All GA)模型,这种架构将 KV-cache 存储和注意力计算开销降低了约 6 倍。其中,注意力槽偏移在 softmax 中引入可学习的偏置项,有效解决了小窗口 SWA 可能导致的性能退化,确保在 256k 长度下仍有近乎 100% 的检索成功率。
为了验证架构的有效性,小米团队在 32B Dense(稠密)模型上做了四组对照实验。
- 方案 A(传统派): All GA(全全局注意力)——所有层都能看到所有信息。
- 方案 B(激进派): Hybrid SWA(128 窗口,无 Sink Bias)——精简了,但没加补丁。
- 方案 C(改良派 - 最终选择): Hybrid SWA(128 窗口 + Attention Sink Bias)。
- 方案 D(保守派): Hybrid SWA(512 窗口 + Attention Sink Bias)。
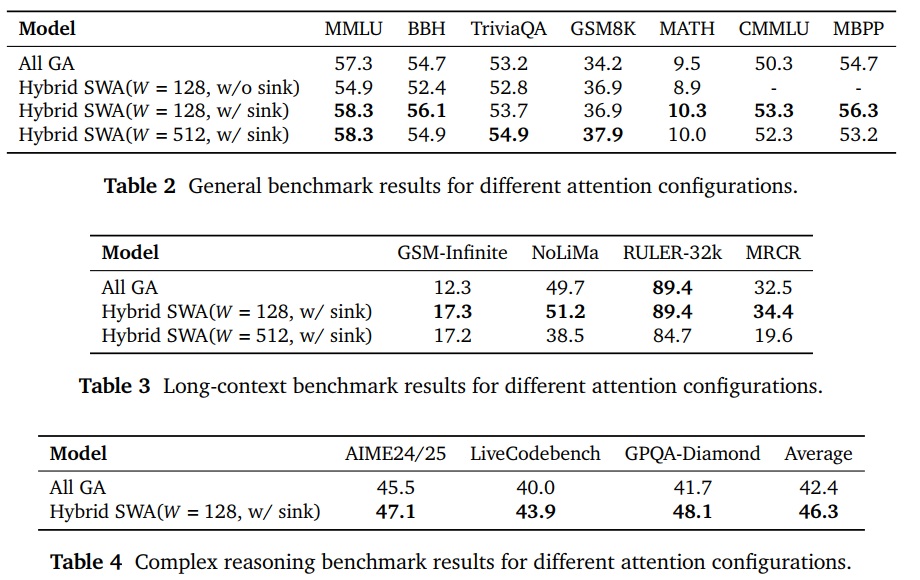
实验结果发现:
- Attention Sink Bias 是“救命稻草”:当窗口只有 128 时,如果不加 Attention Sink Bias,模型在 MMLU、BBH 等通用榜单上会出现明显的性能退化。一旦加上这个“偏置项”,性能不仅止跌,甚至反超了全全局注意力的 Baseline。
- 128 窗口竟然比 512 窗口更强?:这是整篇报告最有趣的发现。按照常理,窗口越大(512 > 128),模型看到的局部信息越多,应该更强。但实验结论恰恰相反,在长文本扩展后,128 窗口的模型在 GSM-Infinite、MRCR 等榜单上大幅超越了 512 窗口模型。在 AIME24/25、LiveCodeBench 等硬核逻辑题上,128 窗口模型的平均分(46.3)也高于全全局模型(42.4)。
为什么“小窗口”反而赢了呢?
小米团队给出了见解,认为原因有三个:
- 明确的分工逻辑: 128 的极小窗口强制模型进行“任务剥离”。SWA 层只负责处理邻近的局部逻辑,而跨度巨大的长程依赖则完全交给那 1/6 的全局层(GA)。这种清爽的分工比模糊的 512 窗口效率更高。
- 更强的正则化: 小窗口实际上起到了一种“约束”作用,防止模型在训练中过度拟合那些虚假的、随机的长程模式,从而提高了泛化能力。
- 推理的“减负”: 128 窗口意味着 KV-Cache 极小,这不仅是速度快,更让模型在推理长逻辑链(Reasoning)时更加专注。
1.2 轻量化多 Token 预测(MTP)
MiMo-V2-Flash 原生集成了 MTP 模块,这不仅提升了训练质量,更成为其“闪电”速度的秘密 。
1.2.1 为什么一定要做 MTP?
如果把大模型推理比作写文章,传统模型是一个字一个字往外蹦,而 MTP(多 Token 预测) 则是让模型具备了“未卜先知”的能力,一次吐出好几个词,由主模型快速确认。小米团队强调了两个核心价值:
- 突破“显存墙”的推理加速: 大模型推理慢,本质是因为“读取模型参数的时间”远超“计算时间”。MTP 通过生成多个“草稿 Token”,让主模型在一次计算中同时校验多个词。由于主模型不需要为这些草稿加额外的 KV Cache 读取,计算效率直接拉满。
- 强化学习(RL)训练的“催化剂”: 现在的 RL 训练最耗时的就是模型自己生成回答的过程。传统的 RL 依赖超大批次来填满 GPU 算力,但 MTP 允许在小批次下也能通过并行预测填满 GPU,让更稳定的“在线策略”训练变得可行。而在生成快结束时,有些长序列还在跑,GPU 往往很闲。MTP 能让这些“长尾任务”跑得更快,不让整个集群等几个“慢学生”。
1.2.2 极致轻量化的设计
很多模型也做预测模块,但如果模块太重,预测本身就耗电耗时,反而拖累速度。小米的 Lightweight MTP 设计非常精妙:
- 拒绝 MoE,拥抱 Dense:主模型是 MoE(专家混合),但 MTP 模块采用小型、稠密(Dense)的 FFN 层。这保证了参数量极小(仅 0.33B),读取速度极快。
- 弃用全局注意力,改用 SWA:MTP 模块不看全文,只用滑动窗口注意力(SWA)。这样 KV Cache 占用极低,几乎不增加推理负担。
- 从“1”到“K”的演进:只挂一个 MTP 头,不增加训练负担。克隆出 个头(-step),联合训练多步预测。这种设计兼顾了预训练的效率和推理时的多步预测能力。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、模型的预训练
MiMo-V2-Flash 的预训练数据量达到了惊人的 27T!!!不只是堆量,团队刻意增加了“长程依赖”数据的比例,除了普通代码,还加入了仓库级代码、PR、Issue 和提交历史。
这解释了为什么它在后文的 Agent 任务中表现如此出色,因为它在“娘胎里”就读过完整的项目逻辑,而不只是零散的代码片段。
2.1 三阶段进化论
MiMo-V2-Flash 的训练不是一蹴而就的,而是分为三个“升级”阶段:
- 第一阶段:筑基 (0-22T)
在 32K 上下文下进行全才教育,建立强大的通用语言能力。 - 第二阶段:强化学霸 (22-26T)
大幅提升代码比例,并加入 5% 的合成推理数据,定向爆破逻辑推理和程序编写能力。 - 第三阶段:极限拉伸 (26-27T)
将上下文直接从 32K 扩展到 256K,训练模型在极端长文本下的“专注力”。
在参数配置上,小米给出了一组硬核数据。48 层 Transformer,由 39 层 SWA(局部)和 9 层 GA(全局)组成,每层 MoE 拥有 256 个专家,每次仅激活 8 个。虽然总参数 309B,但跑起来时只动用 15B 激活参数。这种“精锐部队”模式是其低延迟、高性能的关键。
2.2 评估结果
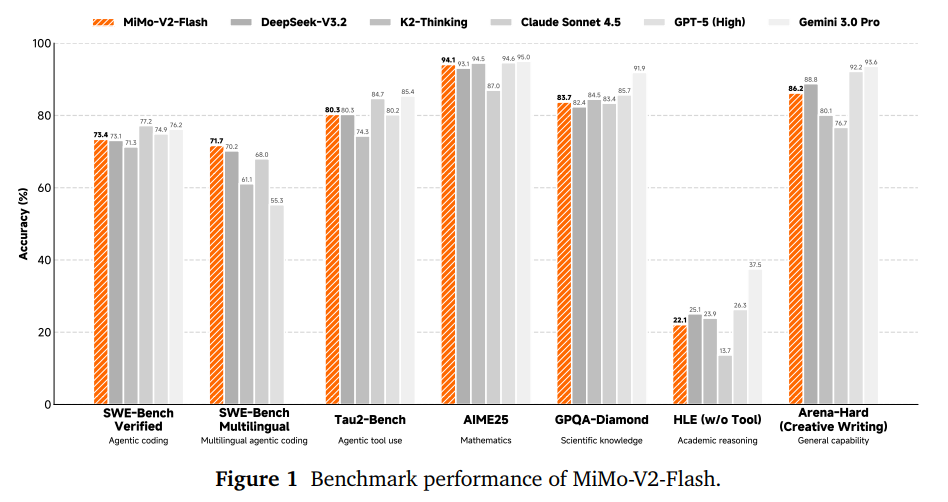
在数学(AIME)和科学推理(GPQA-Diamond)任务中,MiMo-V2-Flash 表现极为稳健。在 SWE-Bench 上,MiMo-V2-Flash 竟然超越了参数量是其三倍多的 Kimi-K2-Base。
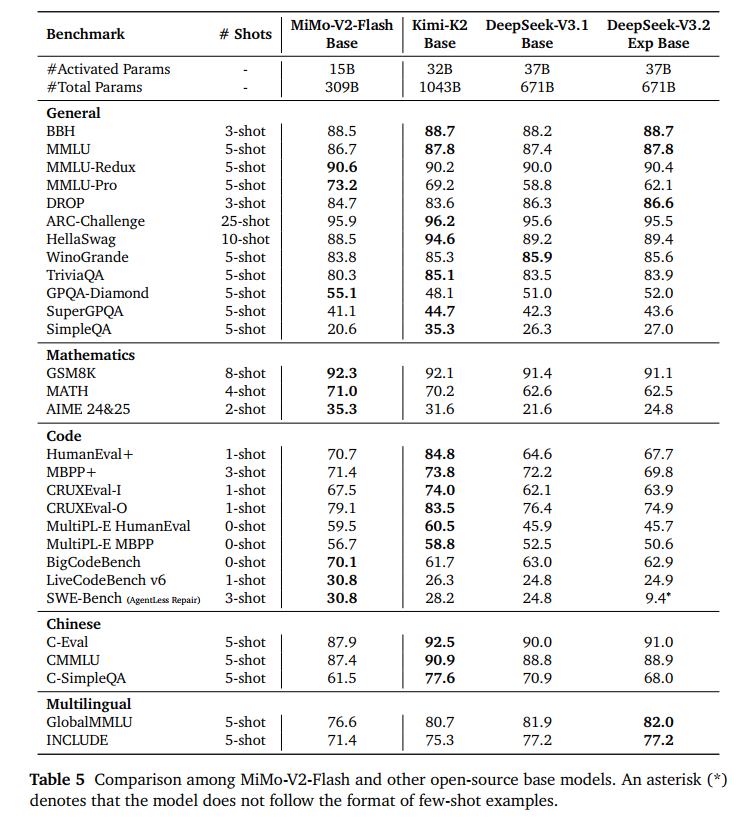
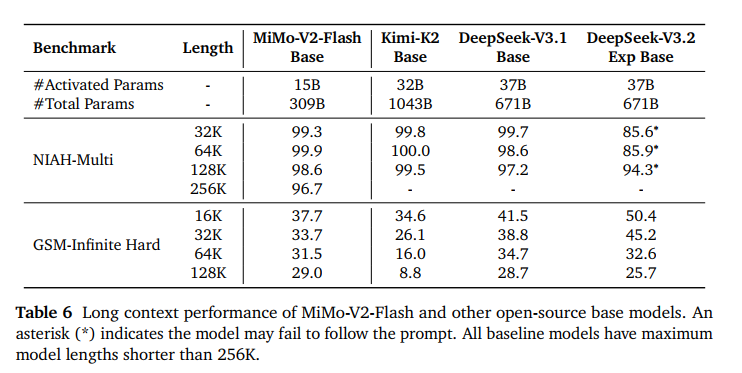
在 32K 到 256K 范围内,检索成功率接近 100% 。在极端压力测试 GSM-Infinite 中,随着文本变长(从 16K 到 128K),性能几乎不衰减。相比之下,某些竞争对手在 64K 之后性能会出现断崖式下跌,证明了小米 Hybrid SWA 架构 的优越性。
三、模型的后训练
小米团队首先指出了当前大模型微调的痛点:能力不平衡。你想增强模型的代码能力,结果它的文学创作能力掉队了;想加强逻辑推理,结果安全对齐出问题了。这种“顾此失彼”被报告称为“跷跷板效应”。MiMo-V2-Flash 引入 MOPD(Multi-Teacher On-Policy Distillation,多老师在线蒸馏) 范式。
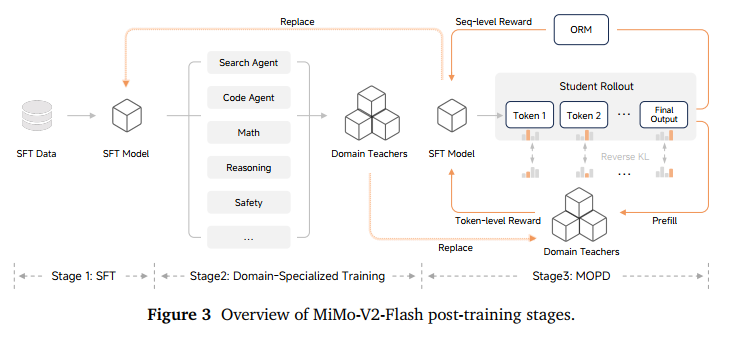
它把训练分成了三个阶段:
- SFT打底:用数百万高质量指令对进行微调,激活模型在预训练时学到的潜能。小米黑科技通过监控 num-zeros(梯度为零的参数数量)判断,如果这个数增加,说明模型负载不均;如果减少,说明模型在死记硬背(过拟合)。小米通过精调 AdamW 的参数,确保了 MoE 专家们各司其职。
- 专家炼成:训练一群“偏科老师”。比如有的老师专攻数学,有的专攻 Agent 搜寻,有的专攻安全,让每一个分身老师都在各自的领域达到天花板水平。
- 多师在线蒸馏:不是参数融合,也不是离线学习。而是把SFT模型当做学生模型,让其自己产生回答(On-policy),然后同时接受多个领域老师的“Token 级”监督。
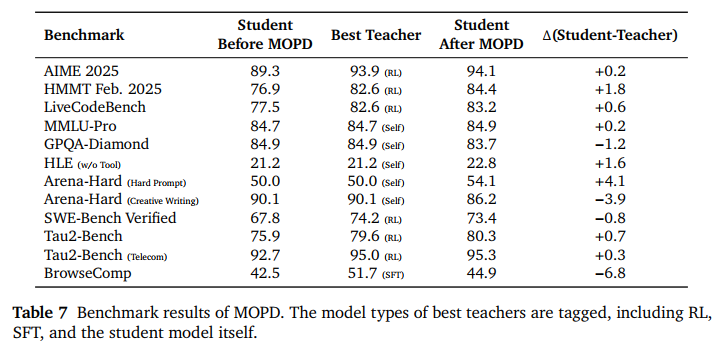
结果表明,学生模型在 AIME 数学、代码等榜单上,不仅保住了老师的最高水平,甚至在某些项目上超越了最好的老师(如 AIME 2025 达到 94.1 分)
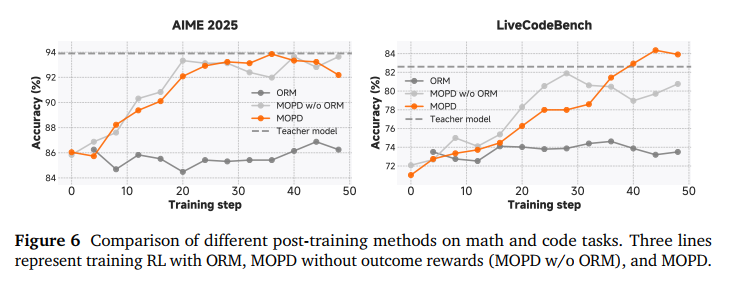
3.1 强化学习的美学
MiMo-V2-Flash 最大的特色是其Agent能力,这得益于极其硬核的强化学习环境。
3.1.1 非智能体强化
这部分主要解决模型的“脑力”问题。通过在可验证领域(数学、代码)建立了一套混合验证系统,实现用程序工具直接检查答案对不对;另外,建立了一套基于 Rubric(评分细则) 的架构。由高级别 LLM 充当“裁判”,对照详细的准则给出细颗粒度的奖励信号,确保模型在变聪明的同时,三观也要正。
3.1.2 智能体强化
非智能体强化学习专注于单回合推理和生成,而智能体强化学习训练模型在交互式、多回合环境中运行,需要基于反馈的规划、行动执行和适应。因此,该技术沿着两个关键维度扩展代理强化学习:环境多样性和计算资源。
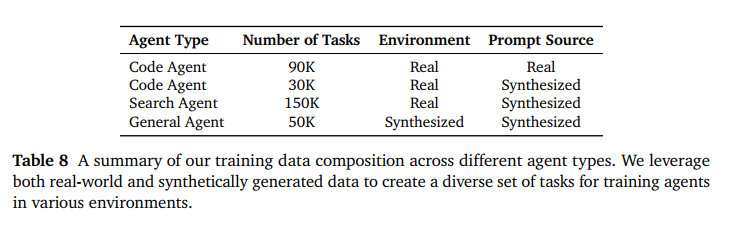
- 代码智能体: 小米基于 GitHub 真实 Issue 库,构建了超过 10 万个代码任务,并搭建了一个由 10,000 个 Kubernetes Pod 组成的集群。模型不是在写伪代码,而是在真实的 Docker 容器里运行 Bash 命令、编辑文件、跑单元测试。通过只给模型提供了三个原子工具(bash, str_replace, finish),不预设任何工作流,逼模型自己探索出解决问题的最优路径。
- Web 开发智能体:网页写得好不好,代码通过了不算,还得看长啥样。模型生成的代码会被 Playwright 渲染成视频,然后由多模态模型去“看”视频打分。这样可以极大地减少“视觉幻觉”(代码跑通了但页面一团糟的情况)
- 终端与搜索智能体:基于 Stack Overflow 任务,训练模型处理复杂的 Linux 命令和环境配置。并通过事实图谱扩展,训练模型自主网页搜索、信息检索和事实核查。
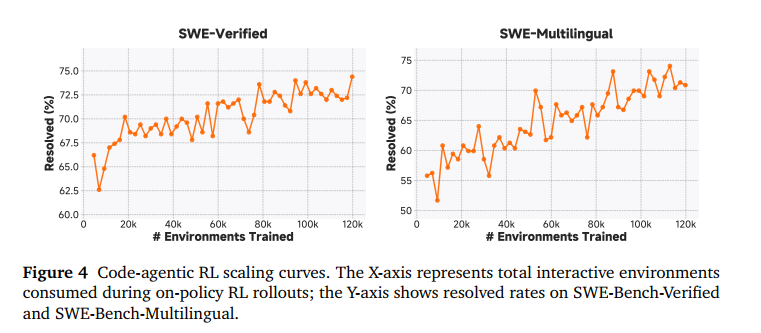
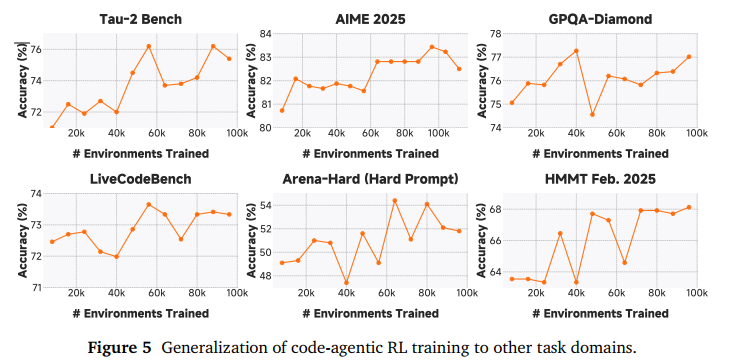
此外,小米团队通过实验发现,在多样化的 Agent 环境(如代码、搜索、终端等)中增加强化学习的计算量,带来的收益远超想象。在约 120,000 个(12万) 真实环境中让模型进行在线采样和更新,让模型在 SFT 的基础上,在 SWE-Bench(软件工程考试)上实现了性能的二次飞跃。
报告还指出,大规模的代码 Agent RL 训练不仅提升了修代码的能力,还产生了一种“泛化”效应。虽然模型是在修 Bug,但它的数学、通用代码和逻辑推理能力也随之大幅提升。
这证明了 Agent 训练不仅仅是教模型用工具,更是在开发模型通用的解决复杂问题的能力。
3.2 性能评估
在 AI 圈,数据从不说谎。
先说核心结论,MiMo-V2-Flash性能全面对标“Thinking”系列。
- 在 MMLU-Pro、GPQA-Diamond、AIME 2025 等硬核推理榜单上,它的表现与 Kimi-K2-Thinking 和 DeepSeek-V3.2-Thinking 旗鼓相当。
- 在开放式任务(General Writing)中性能直逼DeepSeek-V3.2-Thinking
此外,登顶开源 SWE-Bench!!!!
- SWE-Bench Verified 成绩:73.4% 。这个分数不仅领跑所有开源模型,甚至已经逼近了闭源巨头 GPT-5-High(预览版) 的水平。
- SWE-Bench Multilingual 成绩:71.7% 。标志着它成为了目前全球开源界解决真实软件工程问题最强的模型。
报告中还提到一个非常关键的对比点:在长文本评测中,MiMo-V2-Flash 的表现甚至超过了 Kimi-K2-Thinking。Kimi-K2 采用的是全全局注意力(Full Global Attention),而小米采用的是混合滑动窗口。这一事实证明,针对长文本进行“稀疏化”和“分工化”设计的架构,在处理长逻辑链任务时,不仅更省资源,性能上限也更高。
在 BrowseComp(搜索 agent 榜单)中,通过独家的“上下文管理”技术,得分从 45.4 飙升至 58.3。在 τ -Bench 工具使用测试中,它在电信(95.3)、零售(79.5)和航空(66.0)等领域展现了极高的任务成功率。
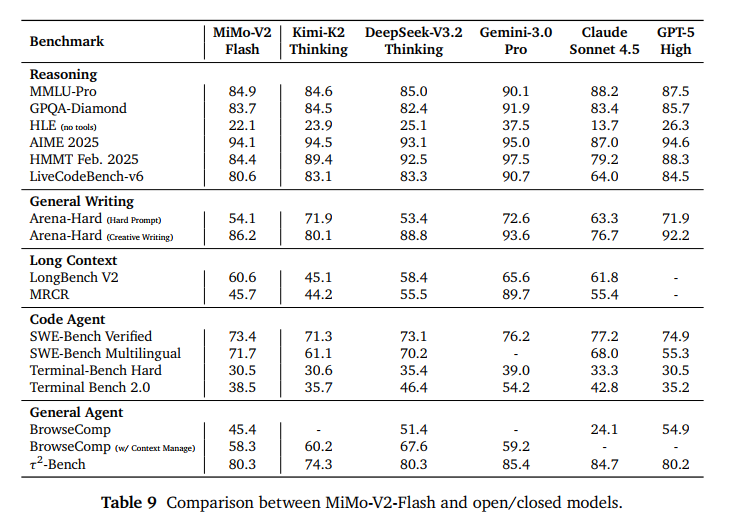
总得来说,MiMo-V2-Flash 用 73.4% 的 SWE-Bench 成绩告诉我们:小米不仅造出了一款大模型,更训练出了一个能在 8 种语言下自主修 Bug 的‘顶级工程师’。在长文本领域,它更是凭借 Hybrid SWA 架构,完成了对多倍参数规模模型的‘跨级超越’。”
四、MTP 加速
为什么 MiMo-V2-Flash 能快得像闪电?因为它不只靠主脑思考,还带了 3 个轻量化的‘预言家’(MTP 层)。在代码编写等任务中,它能以 2.7 倍的惊人速度疯狂输出。
小米团队发现,模型的**不确定性(熵)**越低,MTP 预判就越准,提速就越快。
- Web 开发:代码结构相对固定,熵值低,平均一次能预判 3.6 个词。
- 硬核逻辑题:思考过程复杂,不确定性高,预判长度会缩短。
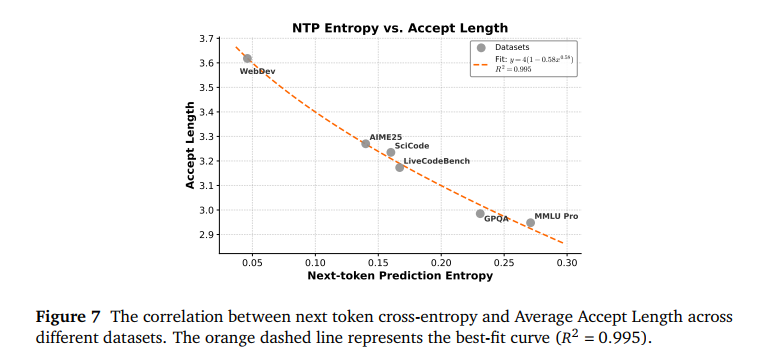
在 16K 输入和 1K 输出的长文本场景下,开启 3 层 MTP 后,**主流批次(Batch Size 64/96)**下,加速比稳稳超过 2.5 倍。而在 Batch Size 96 且接受长度达到 3.8 时,速度提升高达 2.7 倍。
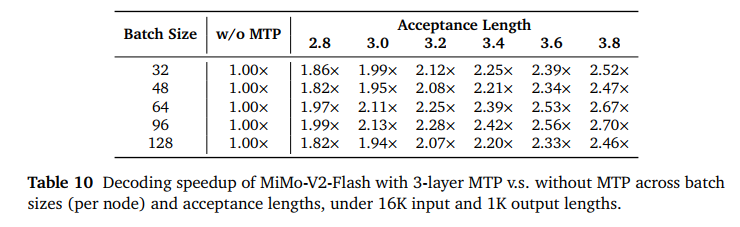
而这种提速是 **“白嫖”**来的,不需要更贵的显卡,只需要合理的软件架构优化!
五、MiMo-V2-Flash 实操指南
为了让这尊 309B 的“巨兽”平稳运行,我们提供了两种配置建议:
- 最低硬件门槛(针对 Q4 量化版本):
- 显存: 2x RTX 5060 Ti (16GB) = 32GB VRAM
- 内存: 128GB System RAM
- 预期速度: 约 8 tokens/秒
- 推荐高性能配置:
- 算力: 8x H100 或 A100 GPU(实现完整 FP8 精度)
- 互联: 高带宽互联(NVLink/InfiniBand)
- 量化建议
- Q3 / IQ3_XS: 仅需 32GB 显存即可运行,质量损失极小。
- Q4: 32GB 显卡的压轴表现,可能需要进一步优化。
- FP8: 完整模型需要 160GB+ 显存。
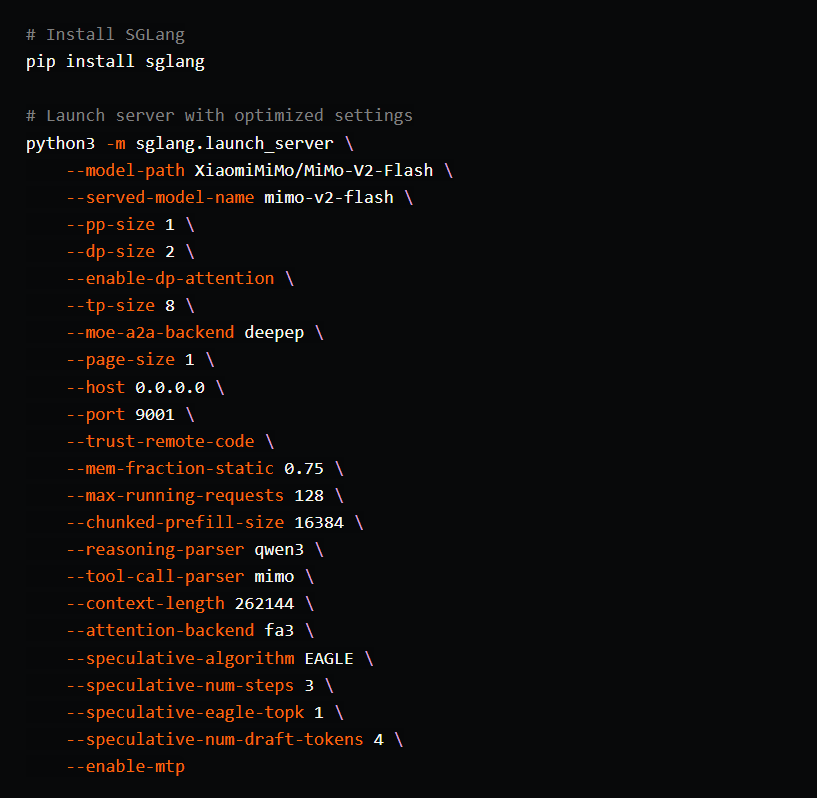
5.1 使用 SGLang 进行安装(官方推荐)
SGLang 是目前运行 MiMo-V2-Flash 最理想的引擎,支持 MTP 加速。
5.2 API 调用示例
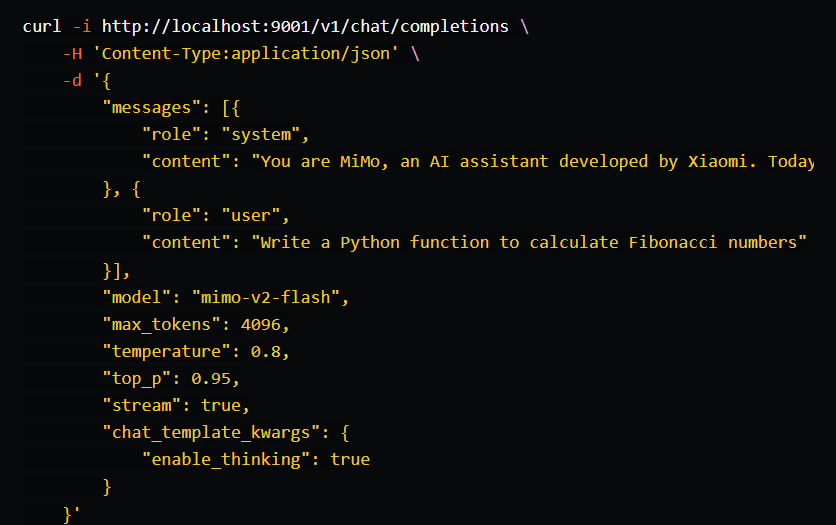
部署完成后,你可以通过标准的 OpenAI 格式进行调用。注意:开启 enable_thinking 即可激活模型的深度推理模式!
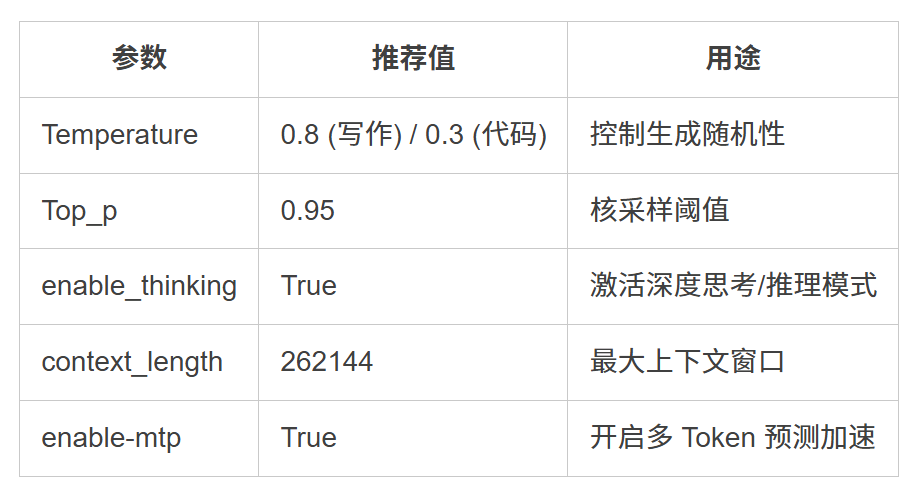
- 关键配置参数一览
特别提醒:系统提示词(System Prompt)至关重要
官方测试表明:在 Prompt 中包含身份声明(你是 MiMo)和当前日期信息,能显著提升模型在复杂逻辑任务中的表现。请务必在调用时附带官方 System Prompt。
五、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)