《大模型应用系列|用LLama Factor微调Qwen、Deepseek等大语言模型,定制化你的专属大模型》
如果你希望打造一个「懂你、听你、按你要求说话」的专属大模型,那么你一定要了解今天的主角:LLama Factory:一站式大模型微调平台
近年来,大语言模型(Large Language Model, LLM)迅速走进普通开发者、科研人员与企业的工作流。但是,通用大模型往往并不能完全贴合你的业务需求——比如行业专术语理解不准、回答风格不符合品牌调性、对企业内部知识不了解等等。
如果你希望打造一个「懂你、听你、按你要求说话」的专属大模型,那么你一定要了解今天的主角:LLama Factory:一站式大模型微调平台
一、为什么要微调大语言模型
大模型非常强大,但不代表“无所不能”。例如,在以下场景中,它们都表现不够理想:
✓ 专业行业知识不足
例如:半导体、医疗、法律、工程设计、学术领域等。
✓ 风格不符合需求
例如:你希望是严谨科研风、轻松科普风、企业内部 SOP 风格。
✓ 对内部知识不了解
例如:企业产品、流程、术语、历史信息,通用模型无法提前知道。
✓ 需要提升某个任务的准确度
如分类、抽取、摘要、改写、对话式客服等。
微调就是为了解决这些问题,让模型更懂你的数据、更符合你的风格、更适合你的业务。
二、为什么选择 LLama Factory
⭐ LLama Factory:微调界的「傻瓜式神器」
它的优势非常明显:
- 支持 多种微调方式:全量微调、LoRA、QLoRA、Freeze
- 支持 丰富的模型:Qwen、Llama、Mistral、Baichuan……
- 支持 Web UI 可视化界面(不用敲命令也能调模型)
- 支持 数据预处理、训练、推理一站式操作
更关键的是:
⭐ 完美支持 Qwen 系列模型
Qwen2/Qwen2.5 是当前中文领域表现最强的一批开源模型,特点包括:
- 中文能力强
- 训练稳定性高
- 上下文理解优秀
- 可本地部署、可商用
- 开源、免费
三、LLama Factory介绍
核心功能
统一框架:支持 LLaMA/Qwen/Baichuan/ChatGLM 等100+模型
高效训练:集成 LoRA/QLoRA/全参数微调,支持多GPU、DeepSpeed
零编码:提供可视化Web UI,无需写代码即可启动训练
数据集智能处理:自动格式化instruction/input/output 三列数据
环境配置
# 创建环境
conda create -n llama_factory python=3.10
conda activate llama_factory
# 安装依赖
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
四、LLama Factory微调实战
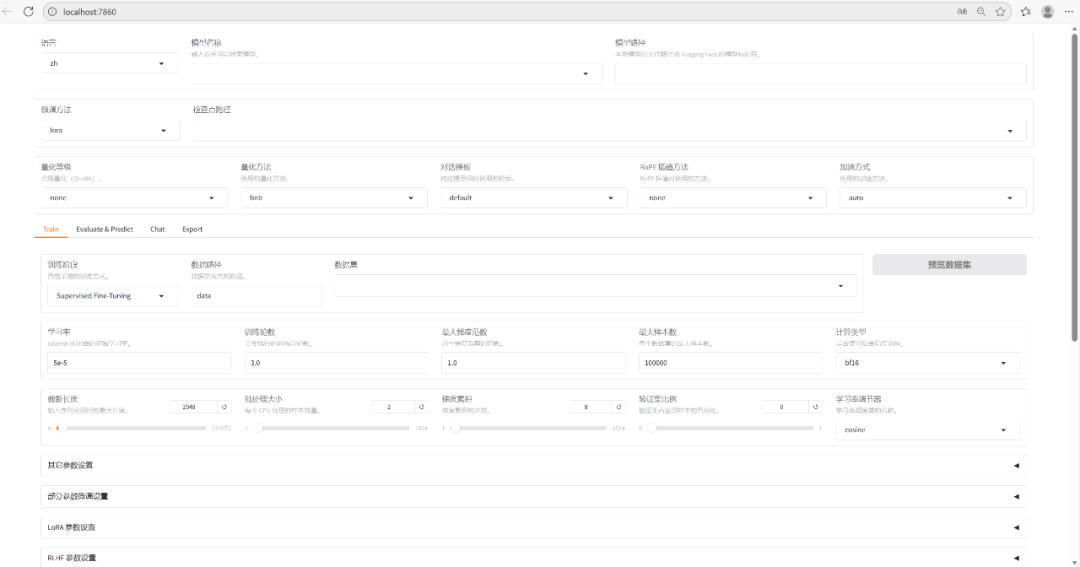
图 1 llamafactory本地微调界面
案例目标:训练医疗问答助手 | 数据集格式(JSON)
[
{
"instruction": "如何预防糖尿病?",
"input": "",
"output": "1. 控制饮食... 2. 定期运动..."
},
{
"instruction": "解释高血压成因",
"input": "患者年龄65岁",
"output": "高龄患者的血压升高主要与..."
}
]
通过Web UI配置(推荐)
- 启动Web服务
cd LLaMA-Factory
llamafactory-cli webui
- 界面配置关键参数 :
- Model Path:输入模型路径(如 Qwen/ DeepSeek)
- Dataset → 选择你的数据集(需提前按格式注册到 dataset_info.json )
- Fine-tuning Method → 选择 LoRA
- Quantization → 显存不足时开启QLoRA(如4-bit)
- Training Args → 设置学习率(建议 2e-5 )、批次大小(如
- per_device_train_batch_size=2 )、训练轮数( epochs=3 )
- Preview Command → 自动生成等效命令,可复制备用
- 直接点击“Start”开始训练
→ 无需手动创建配置文件,系统自动生成参数
五、LLama Factory微调后的模型如何实用(如果读者不会搭建,后期推出Streamlit等可视化方案)
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# 加载原始模型
model_path = "your_finetuned_qwen" # deepseek等模型
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 注入LoRA权重
model = PeftModel.from_pretrained(model, "saves/qwen_7b_medical/adapter_model")
# 医疗问答测试
input_text = "用户:糖尿病人可以吃什么水果?\n助手:"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
print(tokenizer.decode(model.generate(**inputs, max_length=128)[0]))
✓ 接入 RAG 系统
你可以让模型:
- 既拥有行业知识(来自微调)
- 又能查文档查 PDF(来自检索)
这是目前企业智能体的最佳实践。
总结
对绝大多数开发者和企业来说:
- 微调是提升大模型效果 成本最低、效果最显著 的方式;
- LLama Factory 让微调不再需要专业工程团队;
- Deepseek, Qwen 模型速度快、中文强、可商用,非常适合国内应用。
只需几百条数据,就能训练一个真正“懂你”的 AI。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献513条内容
已为社区贡献513条内容

所有评论(0)