agno v2.3.21版本发布详解:AgentOS全面支持Agent As Judge评测与多项稳定性增强
Agno v2.3.21版本是一次扎实的迭代,它没有引入颠覆性的变更,而是在现有强大的基础上进行打磨和增强。对于评估与监控:通过将Agent as Judge深度集成到AgentOS,它为团队提供了企业级的智能体性能评估工具,使得基于LLM的定性评估变得可配置、可触发、可追溯。对于框架稳定性:对RunInput序列化和MistralEmbedder超时的修复,解决了特定场景下的潜在bug,提升了框
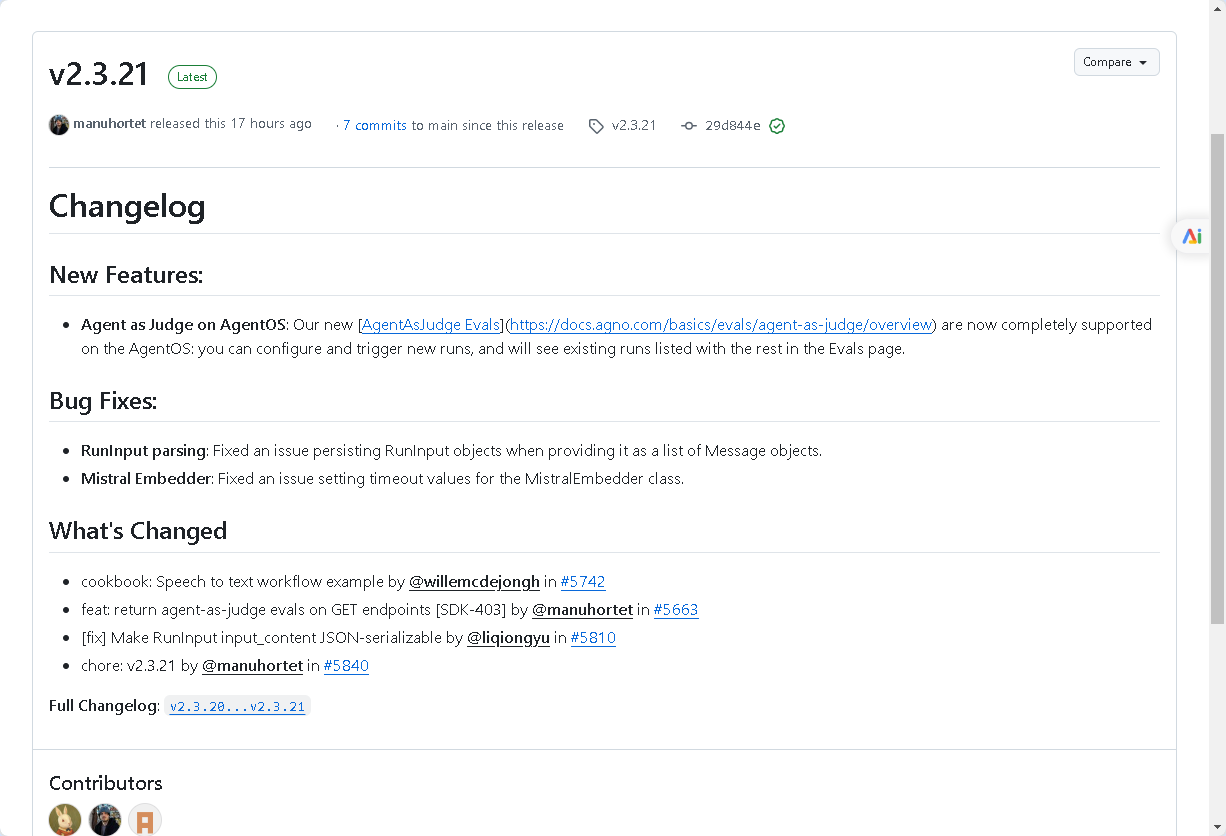

2025年12月23日,agno 官方发布了 v2.3.21 版本。本次更新在保持高性能和私有化架构优势的基础上,重点增强了 AgentOS 对评测体系的支持,同时修复了多个在实际生产和评测场景中可能遇到的问题,并补充了新的 Cookbook 示例。下面将基于本次发布内容,对 v2.3.21 的核心更新进行系统梳理。
一、核心新特性:AgentOS全面集成Agent-as-Judge评估
本次更新最核心的增强在于对“Agent as Judge”(智能体作为评判者)评估功能的全面支持,并将其深度集成到了AgentOS控制平面中。
1. 功能概述
“Agent as Judge”是一种先进的评估范式,它使用一个专门的智能体(Judge Agent)来评估另一个智能体(或团队)在给定任务上的输出质量。这通常用于衡量响应的准确性、相关性、完整性等主观性较强的指标。与传统的基于规则或简单字符串匹配的评估方式相比,Agent as Judge能够利用大语言模型的理解能力,进行更接近人类判断的评估。
2. 集成详情
在v2.3.21之前,开发者可能已经能够在Agno框架内创建Agent as Judge评估逻辑,但管理和运行这些评估可能不够便捷。本次更新后,这一功能在AgentOS中获得了完整的官方支持:
- 配置与触发:用户现在可以直接在AgentOS的Evals(评估)页面中,配置新的Agent as Judge评估任务并触发其运行。这为评估工作流提供了统一的图形化界面。
- 统一管理:Agent as Judge评估的运行记录将与现有的准确性、性能、可靠性等评估结果一同,集中展示在Evals页面中。这实现了对所有类型评估的集中监控和管理,极大地提升了操作效率。
- API端点增强:对应的GET API端点也已更新,现在可以返回Agent as Judge评估的相关数据,确保了控制平面与后端服务的数据一致性。
3. 开发者价值
这一集成意味着团队可以更系统化地对智能体的输出质量进行监控和迭代。例如,在产品上线后,可以定期用Agent as Judge评估客服智能体的回答是否恰当,或者审核内容生成智能体的输出是否符合安全规范。所有评估历史和结果都可在AgentOS中追溯,为模型优化和提示词工程提供了数据基础。
二、关键问题修复
v2.3.21版本修复了两个可能影响开发体验和生产稳定性的问题。
1. RunInput对象持久化修复
- 问题描述:当开发者将
RunInput对象的input_content属性设置为一个Message对象的列表时,框架在尝试持久化(例如存入数据库)该对象时会发生错误。RunInput用于封装单次智能体运行的输入信息,而Message是构成对话历史的基本单元。这个问题会导致包含复杂对话历史的运行记录无法正确保存。 - 修复内容:开发团队修复了
RunInput(及其对应的TeamRunInput)的to_dict()和input_content_string()方法中的序列化逻辑。现在,当input_content是一个混合了Message对象、字典或其他基础类型的列表时,框架能够正确地将所有元素递归地转换为可JSON序列化的字典结构。修复确保了无论输入内容多么复杂,都能被无歧义地转换为字符串或字典格式,从而顺利地进行网络传输或数据库存储。 - 影响:这个修复对于依赖会话历史、实现复杂对话逻辑或进行运行审计的应用至关重要。它保证了数据管道的可靠性。
2. MistralEmbedder类超时设置修复
- 问题描述:
MistralEmbedder类用于调用Mistral AI的嵌入模型,将文本转换为向量。在之前的版本中,其timeout参数(用于设置HTTP请求超时时间)的传递方式存在错误,导致设置可能未生效或格式不正确。 - 修复内容:修复了初始化Mistral客户端时的参数映射。现在,
timeout参数会被正确地转换并传递给底层的客户端库(timeout秒被转换为timeout_ms毫秒)。这保证了开发者可以有效地控制嵌入过程的等待时间,避免因网络问题或服务延迟导致进程无限期挂起。 - 影响:该修复提升了使用Mistral嵌入模型进行知识库构建(RAG)时的稳定性和可预测性。特别是在处理大量文档或网络环境不稳定时,合理的超时设置可以防止整个工作流阻塞。
三、新增实用示例:语音转文本工作流
本次更新在cookbook中添加了一个全新的、名为“Speech to Text”的示例目录,展示了如何利用Agno构建一个端到端的语音转文本应用。
1. 示例结构
该示例包含了多个独立的脚本和一个完整的工作流,演示了不同的实现方式和集成深度:
- 基础单智能体转录:
stt_openai_agent_simple.py:使用OpenAI的语音模型(gpt-audio)进行简单转录,返回纯文本。stt_openai_agent.py:同样使用OpenAI模型,但通过parser_model(如gpt-5-mini)将转录结果解析为结构化的Pydantic模型输出(包含说话人、每句话文本等字段)。stt_gemini_agent.py:使用Google Gemini模型进行结构化转录,展示了模型无关的特性。
- 高级工作流:
stt_workflow.py:演示了如何构建一个Agno Workflow,将音频URL获取、音频格式转换(如MP3转WAV)、智能体转录、结构化输出生成等多个步骤编排成一个自动化流程。该工作流可部署到AgentOS,提供一个完整的服务端点。
2. 技术亮点
- 多模态支持:示例核心利用了Agno智能体原生的多模态处理能力。通过
agno.media.Audio类,可以直接将音频字节数据或文件传递给智能体。 - 结构化输出:展示了如何通过定义Pydantic
output_schema,让智能体返回高度结构化的转录结果,而非杂乱文本,便于下游系统处理。 - 工作流编排:
stt_workflow.py是Agno Workflow能力的典型展示。它将不同的处理单元(函数、智能体)连接成有向无环图,管理状态传递和错误处理,适用于生产级复杂任务。 - 模型无关性:示例同时使用了OpenAI和Gemini的模型,强调了Agno可以轻松切换底层AI提供商。
3. 开发者价值
这个示例为开发者处理音频输入场景提供了即用的模板。无论是构建会议记录工具、客服录音分析系统,还是任何需要将语音转换为可分析文本的应用,都可以以此为起点快速开发。
四、其他重要变更与文档更新
除了上述核心内容,v2.3.21版本还包含了一系列细微但重要的调整。
1. 数据库集成调整
在agent_as_judge_basic.py示例中,数据库从SQLite切换为了PostgreSQL,并提供了标准的连接字符串示例。这引导开发者从开发环境(SQLite)更平滑地过渡到生产环境(PostgreSQL)。
2. 评估逻辑优化
在Agent as Judge评估运行后,将评估结果记录到数据库时,现在正确地将“评判者智能体”所使用的模型信息(model_id, model_provider)与“被评估智能体”的模型信息区分开来并分别存储。这使得评估元数据更加清晰,便于分析不同评判者模型对评估结果的影响。
3. README与文档优化
项目的主README.md文件以及Cookbook的说明文档cookbook/README.md都进行了大幅重写,风格更加简洁、指向性更强。
- 快速定位:新文档更明确地根据用户目标(“我想构建单个智能体”、“我想让智能体协作”、“我想部署和管理”)来引导读者前往相应的示例目录。
- 特性强调:更突出地强调了Agno“私有化部署”、“性能极致”、“生产就绪”的核心优势。
- 入门引导:将“入门指南”和“完整演示”作为最优先的路径,降低新用户的学习曲线。
4. 依赖项更新
- 将核心
agno包版本升级至2.3.21。 - 更新了
fastapi、fastapi-cli、yfinance等关键依赖的版本,以获取最新的功能和安全补丁。
五、总结与展望
Agno v2.3.21版本是一次扎实的迭代,它没有引入颠覆性的变更,而是在现有强大的基础上进行打磨和增强。
- 对于评估与监控:通过将Agent as Judge深度集成到AgentOS,它为团队提供了企业级的智能体性能评估工具,使得基于LLM的定性评估变得可配置、可触发、可追溯。
- 对于框架稳定性:对RunInput序列化和MistralEmbedder超时的修复,解决了特定场景下的潜在bug,提升了框架在处理复杂数据和外部服务调用时的鲁棒性。
- 对于开发者生态:新增的语音转文本示例是一个高质量、可直接复用的“菜谱”(Cookbook),丰富了Agno的应用场景库,展示了其在多模态和复杂工作流方面的强大能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)