大模型应用开发介绍(概念,组件,技术)
快速原型验证Java企业级应用高并发生产环境私有化部署(数据隐私优先):Ollama + LangChain4j + 本地向量数据库(Chroma/Milvus)
大模型应用开发是一个多组件协同、多技术栈融合的体系,核心是围绕大语言模型(LLM) 构建“输入处理→模型调用→输出优化”的完整链路。以下是开发过程中涉及的核心概念、核心组件、主流技术框架的全面梳理。
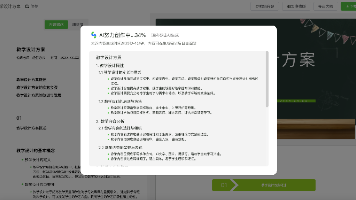
一、 核心概念
这些概念是理解大模型应用开发的基础,也是设计系统架构的关键:
-
大语言模型(LLM)
核心是基于Transformer架构的预训练语言模型,具备理解和生成自然语言的能力。- 分类:按部署方式分为闭源模型(OpenAI GPT-4o、Anthropic Claude 3、百度文心一言)和开源模型(Llama 3、Mistral、Qwen 2);按规模分为小模型(7B/13B)、中模型(70B)、大模型(175B+)。
- 核心能力:文本生成、对话交互、逻辑推理、代码生成、多模态理解(图文/语音)。
-
提示词工程(Prompt Engineering)
指通过设计结构化的文本指令,引导LLM生成符合预期的输出。是低成本提升模型效果的核心手段。- 关键技巧:指令明确化、角色设定、上下文注入、少样本示例(Few-shot)、思维链(CoT)。
- 核心目标:减少模型幻觉、提升输出准确性、匹配业务场景的格式要求。
-
检索增强生成(RAG)
结合信息检索与LLM生成的技术方案,解决LLM知识过时、幻觉、无法访问私有数据的问题。- 核心流程:知识库构建→文本向量化→语义检索→Prompt增强→生成回答。
- 价值:无需微调模型,通过更新知识库实现知识实时迭代,保障数据隐私。
-
智能代理(Agent)
具备“感知-决策-执行”能力的LLM应用,可自主调用外部工具完成复杂任务。- 核心逻辑:用户任务→LLM分析任务→选择工具→执行工具→整合结果→生成回答。
- 典型工具:计算器、搜索引擎、数据库查询、API调用、代码执行环境。
- 代表范式:ReAct(Reason+Act),让模型通过“思考-行动”循环完成任务。
-
文本嵌入(Embedding)
将文本转换为低维稠密向量的过程,向量的数值关系对应文本的语义关系。- 核心作用:支撑RAG的语义检索、文本相似度计算、聚类分析。
- 代表模型:Sentence-BERT、OpenAI Embeddings、Qwen Embedding。
-
对话记忆(Memory)
保存多轮对话上下文的机制,让LLM具备“长期记忆”能力,实现连贯的多轮交互。- 分类:短时记忆(Window Memory,仅保留最近N轮对话)、长时记忆(Persistent Memory,存储到数据库)、摘要记忆(压缩长对话为摘要)。
-
模型微调(Fine-tuning)
用特定领域的数据调整LLM的权重,让模型适配垂直场景(如医疗、法律、金融)。- 分类:全参数微调(成本高、效果好)、增量微调(LoRA/QLoRA,低成本、适配小算力)。
- 与RAG的区别:微调是让模型“记住”知识,RAG是让模型“参考”知识。
二、 核心组件
大模型应用的架构可拆分为6大核心模块,各组件分工明确、协同工作:
| 组件模块 | 核心功能 | 典型工具/技术 |
|---|---|---|
| 1. 模型层 | 提供LLM的推理能力,是应用的核心引擎 | 闭源模型:OpenAI API、Anthropic API、文心一言API 开源模型:Ollama、vLLM、llama.cpp、TensorRT-LLM |
| 2. 数据处理层 | 对输入/输出数据进行清洗、转换、分片 | 文本分片:Recursive Character Splitter、Markdown Splitter 数据加载:LangChain Document Loaders(支持PDF/Word/Excel) 数据清洗:正则表达式、文本去重、噪声过滤 |
| 3. 嵌入与检索层 | 实现文本向量化与语义检索,支撑RAG | 嵌入模型:Sentence-BERT、OpenAI Embeddings、Qwen Embedding 向量数据库:Chroma、Milvus、Redis、Pinecone、Weaviate 检索算法:余弦相似度、欧式距离、BM25混合检索 |
| 4. 编排层 | 串联各组件,实现复杂流程(RAG/Agent) | 核心能力:Chains(链式调用)、Agent(工具调用)、Memory(对话记忆) 典型工具:LangChain、LlamaIndex |
| 5. 交互层 | 提供用户与应用的交互入口 | 终端CLI、Web界面(Gradio、Streamlit)、API接口(REST/gRPC)、聊天机器人(微信/钉钉机器人) |
| 6. 部署与运维层 | 保障应用的稳定运行、性能优化、监控 | 部署工具:Docker、Kubernetes、FastAPI 性能优化:模型量化(4-bit/8-bit)、推理加速(vLLM) 监控运维:Prometheus、Grafana、日志收集 |
三、 主流技术框架
技术框架是串联各组件的“胶水”,大幅降低开发成本。按生态定位和功能侧重可分为以下几类:
1. 核心编排框架(应用开发的主力军)
负责串联模型、检索、记忆等组件,支持RAG、Agent等复杂场景的开发。
| 框架 | 生态 | 核心优势 | 适用场景 |
|---|---|---|---|
| LangChain | Python | 组件最丰富、社区最活跃,支持所有主流LLM/向量库,Agent能力强 | 复杂RAG、智能代理、多模态应用 |
| LlamaIndex | Python | 专为RAG设计,知识库管理能力强,支持复杂数据结构(如数据库、API) | 企业级知识库问答、结构化数据检索 |
| LangChain4j | Java/Kotlin | JVM生态的LangChain,原生支持Spring Boot,私有化部署友好 | Java后端项目集成AI能力、企业级RAG |
| Spring AI | Java | Spring官方AI框架,贴合Spring开发习惯,配置简单 | Spring Boot项目快速集成LLM、基础RAG |
2. 模型部署与推理框架(支撑开源模型落地)
负责开源模型的高效部署、推理加速,降低硬件资源消耗。
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| Ollama | 轻量级、跨平台,一键部署开源模型(Llama 3/Qwen 2),提供OpenAI兼容API | 本地开发测试、私有化部署、边缘设备 |
| vLLM | 高吞吐推理框架,支持动态批处理,大幅提升模型并发能力 | 高并发场景(如智能客服)、云服务部署 |
| llama.cpp | 纯C++实现的LLM推理引擎,支持模型量化,可在CPU/低配GPU运行 | 边缘计算、嵌入式设备、低资源环境 |
| TensorRT-LLM | NVIDIA官方推理框架,基于TensorRT优化,GPU推理性能极致 | 高性能GPU集群部署、大规模生产环境 |
3. 快速交互框架(快速构建演示原型)
无需前端开发经验,快速搭建可视化交互界面,适合demo验证。
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| Gradio | 代码量极少,支持实时调试,可一键分享 | 快速搭建AI应用原型、学术研究演示 |
| Streamlit | 基于Python脚本,支持数据可视化,界面更美观 | 数据驱动的AI应用(如数据分析助手) |
4. 向量数据库(RAG的核心存储)
专门用于存储和检索向量数据,支撑语义相似度匹配。
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Chroma | 轻量级、开源免费,无需复杂配置,适合快速测试 | 开发测试、小型RAG应用 |
| Milvus | 分布式、高可用,支持大规模向量数据 | 企业级大规模知识库、高并发检索 |
| Redis | 支持向量存储模块(Redis Stack),兼顾缓存与检索 | 已有Redis集群的项目、轻量化部署 |
| Pinecone | 托管式向量数据库,无需运维,支持混合检索 | 云原生应用、快速上线的商业项目 |
四、 技术栈选型总结
- 快速原型验证:LangChain(Python) + Ollama + Chroma + Gradio
- Java企业级应用:LangChain4j + Spring Boot + Ollama + Milvus
- 高并发生产环境:vLLM/TensorRT-LLM + Kubernetes + Milvus + FastAPI
- 私有化部署(数据隐私优先):Ollama + LangChain4j + 本地向量数据库(Chroma/Milvus)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)