深度学习实验——Pytorch实现天气识别
本实验利用Pytorch实现天气识别数据集中有cloudy(多云) ,rain(雨天),shine(晴天), sunrise(日出)四种天气标签,各约有200-350张照片。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
1. 简介
本实验利用Pytorch实现天气识别
2. 环境
- 语言环境:Python 3.12.7
- 编译器:Jupyter Notebook
- 深度学习环境:torch—2.8.0 + cu126 / torchvision—0.23.1+cu126
3. 数据集介绍
数据集中有cloudy(多云) ,rain(雨天),shine(晴天), sunrise(日出)四种天气标签,各约有200-350张照片。
4. 优化对比
仅对分类头进行训练后,模型在准确性方面达到了约 93% 的稳定水平。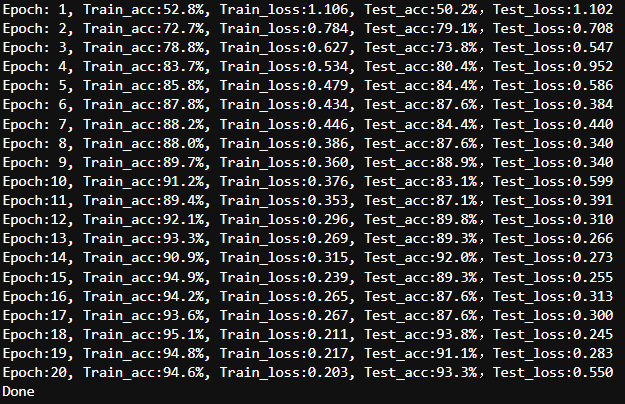
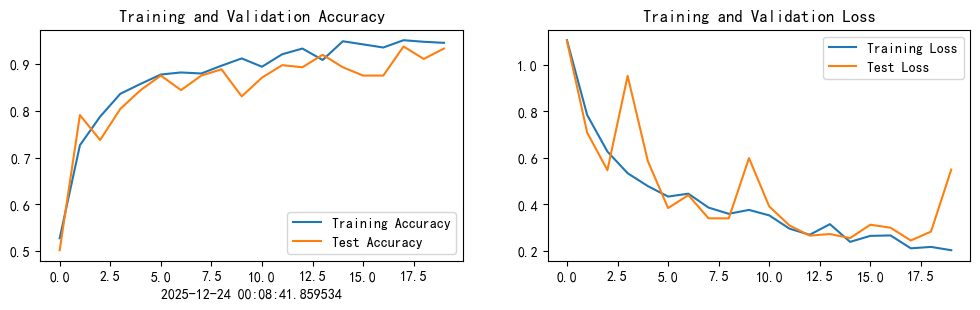
通过用较小的学习率微调 ResNet18 中的最后一个残差块,模型能够更好地适应与天气相关的视觉模式,从而进一步提升了性能,准确率提升至超过 95%。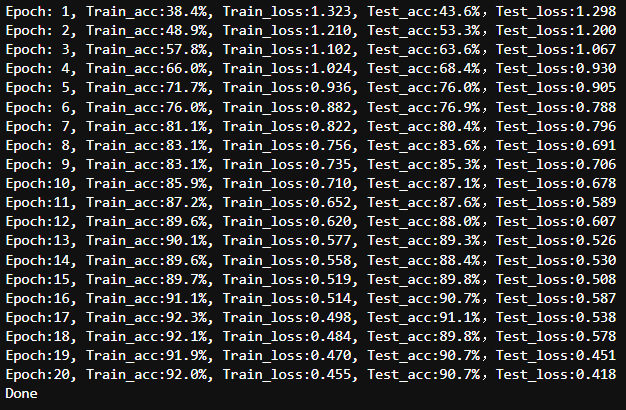
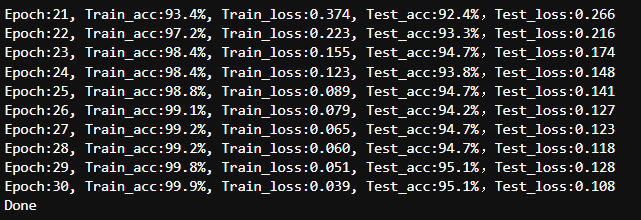
4. 代码实现
4.1 前期准备
4.1.1 设置GPU & 导入库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import os,PIL,pathlib,random
from PIL import Image
import torch.nn.functional as F
import warnings
from datetime import datetime
from torchvision import models
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

4.1.2 查看标签 & 可视化数据
- 使用pathlib.Path()函数将字符串类型的文件夹路径转换为pathlib.Path对象。
- 使用glob()方法获取data_dir路径下的所有文件路径,并以列表形式存储在data_paths中。
- 通过split()函数对data_paths中的每个文件路径执行分割操作,获得各个文件所属的类别名称,并存储在classeNames中
- 打印classeNames列表,显示每个文件所属的类别名称。
data_dir = './Data/Weather/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames

利用Matplotlib库,以及列表推导式加载和显示图像
image_folder = './Data/Weather/cloudy/'
image_files = [f for f in os.listdir(image_folder) if f.endswith((".jpg", ".png", ".jpeg"))]
fig, axes = plt.subplots(3, 8, figsize=(16, 6))
for ax, img_file in zip(axes.flat, image_files):
img_path = os.path.join(image_folder, img_file)
img = Image.open(img_path)
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()

4.2 CNN 模型
4.2.1 图片转换读取
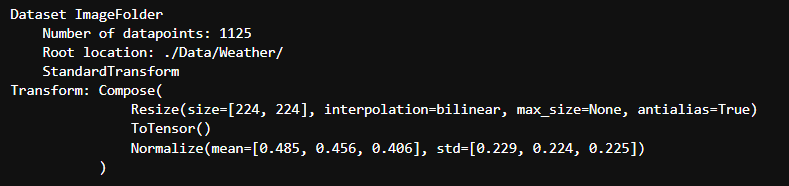
把磁盘上的“按文件夹分类的图片数据集”,包装成一个 PyTorch 可用的 Dataset 对象,并且规定每张图片在被取出来时要做哪些预处理(transform)。
其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。即遍历所有图像,分别计算每个通道(R、G、B)的像素值平均值和标准差。
total_datadir = './Data/Weather/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
4.2.2 数据集划分
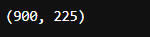
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset

train_size,test_size
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break

4.2.3 CNN 模型建立
在卷积层和全连接层之间,可以使用之前的torch.flatten(),也可以使用下面的x.view()亦或是torch.nn.Flatten()。torch.nn.Flatten()与TensorFlow中的Flatten()层类似,前两者则仅仅是一种数据集拉伸操作(将二维数据拉伸为一维),torch.flatten()方法不会改变x本身,而是返回一个新的张量。而x.view()方法则是直接在原有数据上进行操作。
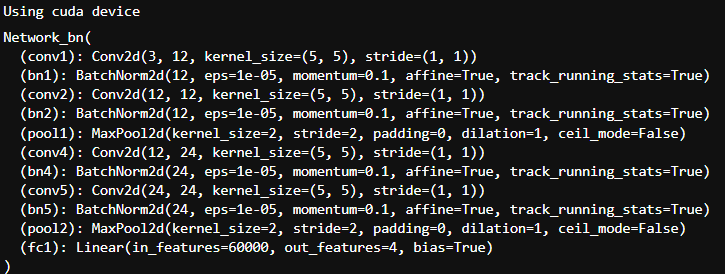
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool1 = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.pool2 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool2(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
print("Using {} device".format(device))
model = Network_bn().to(device)
model
4.2.4 训练 & 测试函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4.2.5 参数设定 & 正式训练
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
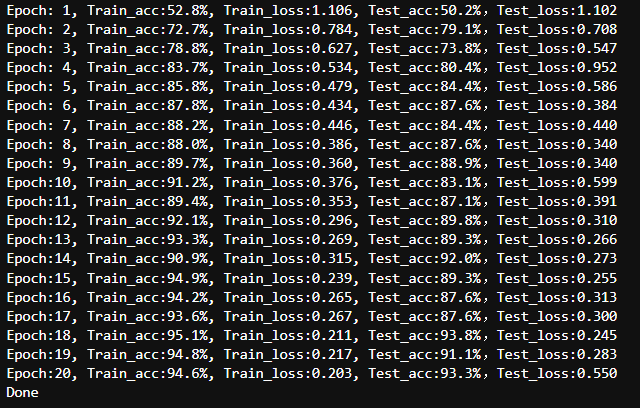
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
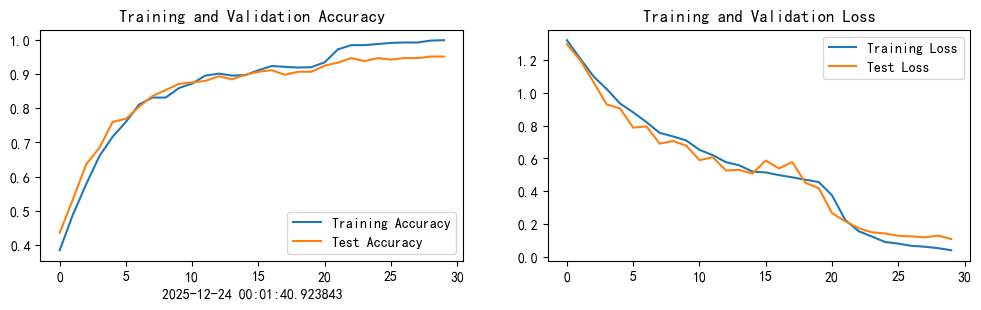
4.2.6 结果可视化
current_time = datetime.now()
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

4.3 ResNet18 模型
由于CNN表达能力有限,ResNet18 通过残差连接解决了深层网络的退化和梯度消失问题,使模型能够更深、更稳定地学习高层语义特征,因此在图像分类任务中显著提高了准确率。
4.3.1 图片转换读取
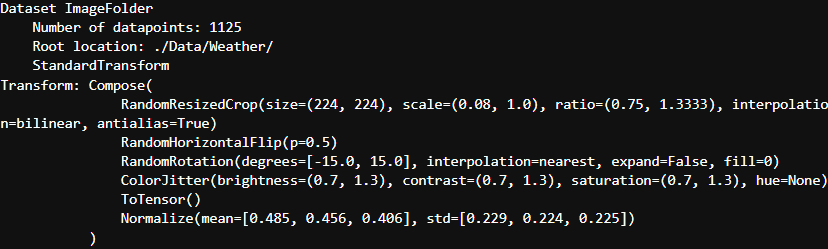
对数据进行增强
total_datadir = './Data/Weather/'
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ColorJitter(
brightness=0.3,
contrast=0.3,
saturation=0.3
),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
4.3.2 数据集划分
让 train / test 用不同 transform
full_dataset = datasets.ImageFolder(total_datadir)
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(
full_dataset, [train_size, test_size]
)
# 分别设置 transform
train_dataset.dataset.transform = train_transforms
test_dataset.dataset.transform = test_transforms
train_size,test_size

batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break

4.3.3 ResNet18 模型建立
num_classes = len(classeNames)
model = models.resnet18(pretrained=True)
# 冻结 backbone(小数据集关键)
for param in model.parameters():
param.requires_grad = False
# 替换分类头
model.fc = nn.Linear(model.fc.in_features, num_classes)
model = model.to(device)
print(model)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=4, bias=True)
)
Selection deleted
4.3.4 训练 & 测试函数
同4.2.4节
4.3.5 参数设定 & 正式训练
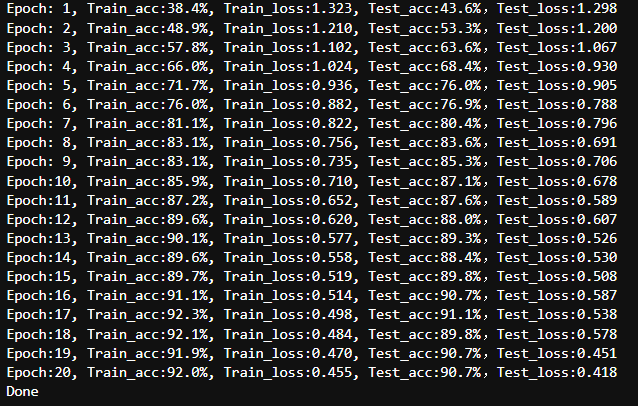
AdamW 将自适应学习率与解耦权重衰减相结合,从而在小数据集上对深度预训练模型进行微调时,能够比 SGD 更快地实现收敛并具备更好的泛化能力。
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4
opt = torch.optim.AdamW(
model.fc.parameters(),
lr=1e-4,
)
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
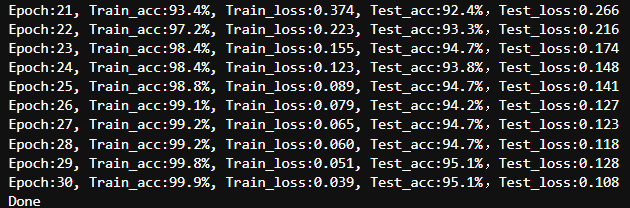
解冻 ResNet 的 layer4,降低学习率,再训练 8–10 个 epoch
for param in model.layer4.parameters():
param.requires_grad = True
opt = torch.optim.AdamW(
model.parameters(),
lr=1e-5,
weight_decay=1e-4
)
fine_tune_epochs = 10
for epoch in range(fine_tune_epochs):
model.train()
tr_acc, tr_loss = train(train_dl, model, loss_fn, opt)
model.eval()
te_acc, te_loss = test(test_dl, model, loss_fn)
train_acc.append(tr_acc)
train_loss.append(tr_loss)
test_acc.append(te_acc)
test_loss.append(te_loss)
print(template.format(epoch+epochs+1, tr_acc*100, tr_loss, te_acc*100, te_loss))
print('Done')
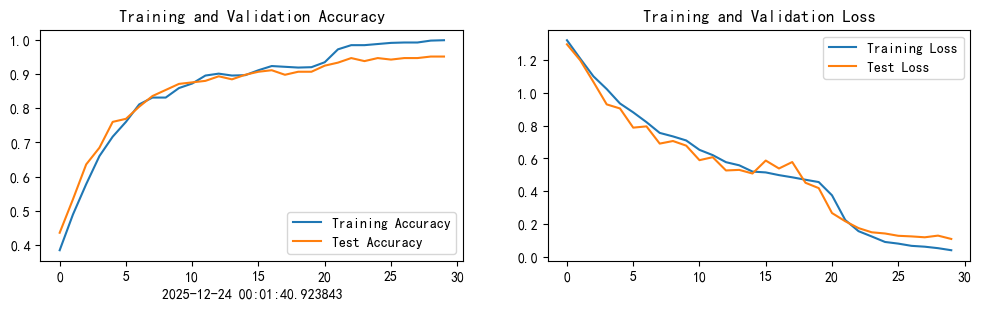
4.3.6 结果可视化
current_time = datetime.now()
total_epochs = epochs + fine_tune_epochs
epochs_range = range(total_epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
5. 调用 ResNet18 模型识别一张本地图片
# 首先保存模型
torch.save(model.state_dict(), "resnet18_weather.pth")
# 定义和测试集一致的 transform
infer_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载ResNet18和训练的权重
num_classes = 4
classeNames = ['cloudy', 'rain', 'shine', 'sunrise']
model = models.resnet18(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, num_classes)
model.load_state_dict(
torch.load("resnet18_weather.pth", map_location=device)
)
model = model.to(device)
model.eval()
# 读取并处理本地图片
img_path = "./Data/Weather/wps.png"
img = Image.open(img_path).convert("RGB")
img_tensor = infer_transform(img)
img_tensor = img_tensor.unsqueeze(0).to(device) # [1, 3, 224, 224]
# 推理 + 置信度
with torch.no_grad():
outputs = model(img_tensor)
probs = torch.softmax(outputs, dim=1)
pred_idx = torch.argmax(probs, dim=1).item()
confidence = probs[0][pred_idx].item()
# 显示图片和预测结果
plt.imshow(img)
plt.axis("off")
plt.title(f"Prediction: {classeNames[pred_idx]} ({confidence*100:.1f}%)")
plt.show()
print("预测类别:", classeNames[pred_idx])
print("置信度:", f"{confidence:.4f}")


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)