【AI量化投研】- Modeling(三, 从极简开始)
本文记录了AI量化投研建模过程中遇到的问题及优化过程。针对训练失败现象,作者从数据不平衡(正负样本比例92.8%:7.2%)入手,尝试了欠采样、样本加权(正样本权重14.6倍)等方法,但模型仍出现验证集准确率虚高(93.56%)、无法识别正样本的问题。实验显示:1)单纯提高正样本权重会导致模型预测全负;2)调整dropout正则化后,模型仍无法有效学习正样本特征。最终训练曲线呈现发散状态,表明当前
【AI量化投研】- Modeling(三, 从极简开始)
背景
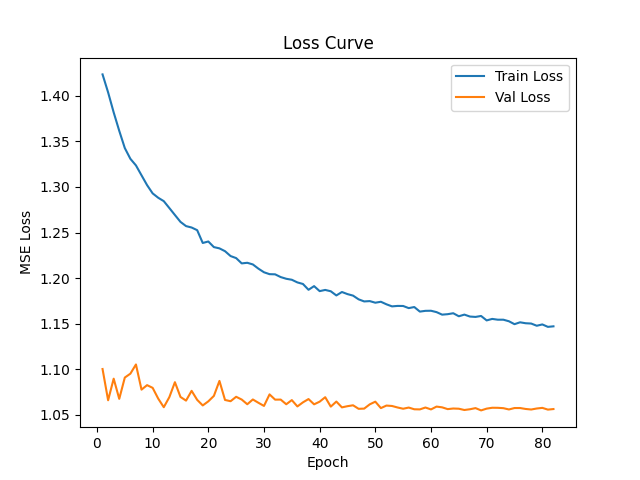
训练失败,原因尚未确定,只有猜测,需要斟酌排查。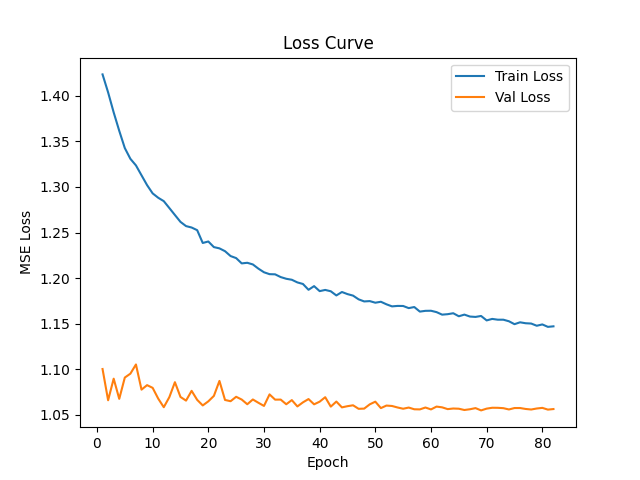
打算如何排查?
- 特征噪声问题、特征构建问题(从单平面开始; 换数据周期; 换特征形式);
- 网络参数应该暂时没有大的调整必要,只针对过度正则化做一些修正即可;
- ResNet 模型虽然可能不会非常好,但至少会有效,所以,模型不需要修改,参数可以往简单开始;
- 标签先用分类来处理;
标准化这个问题, 成交量 持仓量 波动率 没有直接的呈现,目前的这种特征平面应该是确实不太行. 要标准化吗? 还是不标准化 ?
步骤
1. 回归转分类
收益率 > 6/1000, 正类,1.
收益率 <= 6/1000, 负类,0.
抽样统计发现:
📈 标签0(跌): 1856 个 (92.8%)
📈 标签1(涨): 144 个 (7.2%)
比例过于悬殊,非常不利于训练.我在想之前回归问题训练失败是否与这个有关?
2. 预处理: 多数类欠采样 VS 少数类过采样
什么时候采用"多数类欠采样"?什么时候采用" 少数类过采样"?
少数类充足时,不要进行过采样;
多数类欠采样保留真实样本;
研究显示,当少数类样本充足时,优先欠采样以平衡数据集,同时降低存储和计算成本。但需注意可能丢失多数类信息,导致欠拟合风险。
潜在替代. 若正样本过少,可结合过采样(如SMOTE)生成合成数据,但需监控过拟合。
决策依据与最佳实践
选择采样方法需基于:
少数类样本量:若>100(如本例115),欠采样合适;若少,过采样(少数类充足:正样本115已足够模型学习,欠采样多数类不损关键信息)。
数据集规模:大数据欠采样节省资源;小数据过采样保留信息。
模型类型:弱学习器(如决策树)受益于采样;强模型(如XGBoost)可通过阈值优化或成本敏感学习替代。
最佳实践:交叉验证评估采样效果;结合方法(如SMOTETomek)平衡优缺点;优先加权损失(如代码中类别权重负0.54、正6.95)补充采样。
3. 样本加权
正样本权重 ≈ 93.6/6.4 ≈ 14.6
负样本权重 = 1
Epoch 011/2000: 100%|██████████| 1080/1080 [18:36<00:00, 1.03s/it, loss=0.5113, acc=18.75%]
📊 Epoch 011 结果:
训练损失: 0.532146 | 验证损失: 0.890110
训练准确率: 18.75% | 验证准确率: 6.44%
训练精确率: 0.1875 | 验证精确率: 0.0644
训练召回率: 1.0000 | 验证召回率: 1.0000
训练F1分数: 0.3158 | 验证F1分数: 0.1209
训练混淆矩阵:
[[ 0 14040]
[ 0 3240]]
验证混淆矩阵:
[[ 0 11777]
[ 0 810]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.8636
精确率提升: 0.0644
召回率提升: 1.0000
F1分数提升: 0.1209
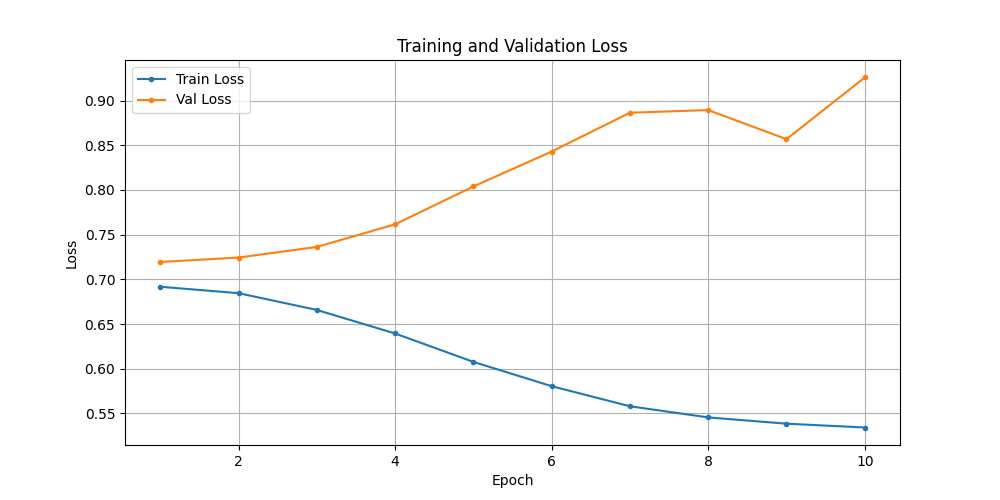
曲线发散了. 训练失败.
通过调整 dropout 增加正则化, 并把正负样本加权改回1:1. 构建 test014_train.py,启动训练.
/home/hyt/anaconda3/envs/tqsdk/bin/python /home/hyt/HYT/future_minutes/test014_train.py
使用设备: cuda
============================================================
🚀 开始二分类模型训练
============================================================
📂 加载数据集...
0%| | 0/62934 [00:00<?, ?it/s]正在扫描所有 .zst 文件...
100%|██████████| 62934/62934 [33:12<00:00, 31.58it/s]
📊 数据集统计:
✓ 有效文件: 62934 个
✗ 损坏文件: 0 个
📈 标签0(跌): 58884 个 (93.6%)
📈 标签1(涨): 4050 个 (6.4%)
📊 划分训练集和验证集...
- 训练集大小: 50347
- 验证集大小: 12587
🔄 创建数据加载器...
✅ 不平衡批采样器创建完成:
- 批次数量: 1620
- 每批大小: 16
- 每批正样本: 2 个 (15.0%)
- 每批负样本: 14 个
- 训练批次/epoch: 1620
- 验证批次/epoch: 787
🧠 创建二分类模型...
✅ 二分类模型创建完成:
- 输入通道: 10
- 输出类别: 2 (二分类)
⚙️ 配置训练参数...
📊 类别分布统计:
正样本: 3240 (6.4%)
负样本: 47107 (93.6%)
类别权重: 负样本=1.00, 正样本=1.00
============================================================
🔥 开始训练循环
============================================================
Epoch 001/2000: 100%|██████████| 1620/1620 [12:49<00:00, 2.11it/s, loss=0.6531, acc=57.28%]
📊 Epoch 001 结果:
训练损失: 0.682052 | 验证损失: 0.695076
训练准确率: 57.28% | 验证准确率: 48.09%
训练精确率: 0.1268 | 验证精确率: 0.0555
训练召回率: 0.4108 | 验证召回率: 0.4407
训练F1分数: 0.1938 | 验证F1分数: 0.0985
训练混淆矩阵:
[[13517 9163]
[ 1909 1331]]
验证混淆矩阵:
[[5696 6081]
[ 453 357]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.4471
精确率提升: 0.0555
召回率提升: 0.4407
F1分数提升: 0.0985
✅ 新最佳模型已保存!验证准确率: 48.09%
Epoch 002/2000: 100%|██████████| 1620/1620 [12:46<00:00, 2.11it/s, loss=0.6625, acc=61.63%]
📊 Epoch 002 结果:
训练损失: 0.670711 | 验证损失: 0.690227
训练准确率: 61.63% | 验证准确率: 60.98%
训练精确率: 0.1217 | 验证精确率: 0.0603
训练召回率: 0.3330 | 验证召回率: 0.3469
训练F1分数: 0.1783 | 验证F1分数: 0.1027
训练混淆矩阵:
[[14895 7785]
[ 2161 1079]]
验证混淆矩阵:
[[7395 4382]
[ 529 281]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: -0.3182
精确率提升: 0.0603
召回率提升: 0.3469
F1分数提升: 0.1027
✅ 新最佳模型已保存!验证准确率: 60.98%
Epoch 003/2000: 100%|██████████| 1620/1620 [12:37<00:00, 2.14it/s, loss=0.6016, acc=74.32%]
📊 Epoch 003 结果:
训练损失: 0.638491 | 验证损失: 0.669653
训练准确率: 74.32% | 验证准确率: 93.56%
训练精确率: 0.1281 | 验证精确率: 0.0000
训练召回率: 0.1815 | 验证召回率: 0.0000
训练F1分数: 0.1502 | 验证F1分数: 0.0000
训练混淆矩阵:
[[18677 4003]
[ 2652 588]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
✅ 新最佳模型已保存!验证准确率: 93.56%
Epoch 004/2000: 100%|██████████| 1620/1620 [12:40<00:00, 2.13it/s, loss=0.5715, acc=84.35%]
📊 Epoch 004 结果:
训练损失: 0.591118 | 验证损失: 0.635862
训练准确率: 84.35% | 验证准确率: 93.56%
训练精确率: 0.1276 | 验证精确率: 0.0000
训练召回率: 0.0432 | 验证召回率: 0.0000
训练F1分数: 0.0646 | 验证F1分数: 0.0000
训练混淆矩阵:
[[21723 957]
[ 3100 140]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 005/2000: 100%|██████████| 1620/1620 [12:39<00:00, 2.13it/s, loss=0.5361, acc=87.24%]
📊 Epoch 005 结果:
训练损失: 0.535945 | 验证损失: 0.609869
训练准确率: 87.24% | 验证准确率: 93.56%
训练精确率: 0.1458 | 验证精确率: 0.0000
训练召回率: 0.0043 | 验证召回率: 0.0000
训练F1分数: 0.0084 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22598 82]
[ 3226 14]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
📉 损失图已保存至: losses_20251223_010647_5.png
Epoch 006/2000: 100%|██████████| 1620/1620 [12:37<00:00, 2.14it/s, loss=0.4514, acc=87.50%]
📊 Epoch 006 结果:
训练损失: 0.482069 | 验证损失: 0.571718
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22679 1]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 007/2000: 100%|██████████| 1620/1620 [12:38<00:00, 2.14it/s, loss=0.4088, acc=87.50%]
📊 Epoch 007 结果:
训练损失: 0.437896 | 验证损失: 0.541917
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 008/2000: 100%|██████████| 1620/1620 [12:37<00:00, 2.14it/s, loss=0.4098, acc=87.50%]
📊 Epoch 008 结果:
训练损失: 0.408585 | 验证损失: 0.513535
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 009/2000: 100%|██████████| 1620/1620 [12:40<00:00, 2.13it/s, loss=0.3926, acc=87.50%]
📊 Epoch 009 结果:
训练损失: 0.393215 | 验证损失: 0.481069
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 010/2000: 100%|██████████| 1620/1620 [12:35<00:00, 2.14it/s, loss=0.4092, acc=87.50%]
📊 Epoch 010 结果:
训练损失: 0.384864 | 验证损失: 0.465046
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
📉 损失图已保存至: losses_20251223_010647_10.png
Epoch 011/2000: 100%|██████████| 1620/1620 [12:38<00:00, 2.14it/s, loss=0.4056, acc=87.50%]
📊 Epoch 011 结果:
训练损失: 0.382123 | 验证损失: 0.462286
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 012/2000: 100%|██████████| 1620/1620 [12:41<00:00, 2.13it/s, loss=0.4316, acc=87.50%]
📊 Epoch 012 结果:
训练损失: 0.383282 | 验证损失: 0.447907
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 013/2000: 100%|██████████| 1620/1620 [12:40<00:00, 2.13it/s, loss=0.3940, acc=87.50%]
📊 Epoch 013 结果:
训练损失: 0.380876 | 验证损失: 0.442356
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 014/2000: 100%|██████████| 1620/1620 [12:42<00:00, 2.13it/s, loss=0.3631, acc=87.50%]
📊 Epoch 014 结果:
训练损失: 0.381423 | 验证损失: 0.438894
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 015/2000: 100%|██████████| 1620/1620 [10:38<00:00, 2.54it/s, loss=0.3653, acc=87.50%]
📊 Epoch 015 结果:
训练损失: 0.379950 | 验证损失: 0.435554
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
📉 损失图已保存至: losses_20251223_010647_15.png
Epoch 016/2000: 100%|██████████| 1620/1620 [12:39<00:00, 2.13it/s, loss=0.3610, acc=87.50%]
📊 Epoch 016 结果:
训练损失: 0.380530 | 验证损失: 0.436488
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 017/2000: 100%|██████████| 1620/1620 [12:36<00:00, 2.14it/s, loss=0.3584, acc=87.50%]
📊 Epoch 017 结果:
训练损失: 0.380125 | 验证损失: 0.434108
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 018/2000: 100%|██████████| 1620/1620 [12:40<00:00, 2.13it/s, loss=0.3586, acc=87.50%]
📊 Epoch 018 结果:
训练损失: 0.379240 | 验证损失: 0.434494
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 019/2000: 100%|██████████| 1620/1620 [12:39<00:00, 2.13it/s, loss=0.3750, acc=87.50%]
📊 Epoch 019 结果:
训练损失: 0.378690 | 验证损失: 0.431077
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 020/2000: 100%|██████████| 1620/1620 [12:41<00:00, 2.13it/s, loss=0.3438, acc=87.50%]
📊 Epoch 020 结果:
训练损失: 0.379616 | 验证损失: 0.421235
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
📉 损失图已保存至: losses_20251223_010647_20.png
Epoch 021/2000: 100%|██████████| 1620/1620 [12:42<00:00, 2.13it/s, loss=0.3897, acc=87.50%]
📊 Epoch 021 结果:
训练损失: 0.378035 | 验证损失: 0.437543
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 022/2000: 100%|██████████| 1620/1620 [12:40<00:00, 2.13it/s, loss=0.3542, acc=87.50%]
📊 Epoch 022 结果:
训练损失: 0.378111 | 验证损失: 0.427978
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 023/2000: 100%|██████████| 1620/1620 [12:42<00:00, 2.12it/s, loss=0.3858, acc=87.50%]
📊 Epoch 023 结果:
训练损失: 0.377459 | 验证损失: 0.420075
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
Epoch 024/2000: 100%|██████████| 1620/1620 [12:39<00:00, 2.13it/s, loss=0.3148, acc=87.50%]
📊 Epoch 024 结果:
训练损失: 0.376770 | 验证损失: 0.437584
训练准确率: 87.50% | 验证准确率: 93.56%
训练精确率: 0.0000 | 验证精确率: 0.0000
训练召回率: 0.0000 | 验证召回率: 0.0000
训练F1分数: 0.0000 | 验证F1分数: 0.0000
训练混淆矩阵:
[[22680 0]
[ 3240 0]]
验证混淆矩阵:
[[11777 0]
[ 810 0]]
📈 验证集指标绝对提升值(相对于原始样本比例基线):
准确率提升: 0.0076
精确率提升: 0.0000
召回率提升: 0.0000
F1分数提升: 0.0000
损失函数竟出奇的平稳.
📉 训练结果评估:严重失败
核心问题分析
1. 模型完全失效
准确率假象:93.56%的准确率只是因为模型预测了全部为负类
分类能力为零:精确率=0,召回率=0,F1分数=0
实际性能:比简单猜负类(基线93.6%)还差0.04%
2. 损失曲线误导
虽然损失在下降,但模型学到了错误的解决方案:
训练损失从0.68→0.38(看似不错)
验证损失从0.69→0.42(看似不错)
但模型只是学会了"永远输出负类"
3. 关键转折点
Epoch 1-2:模型还在尝试分类(召回率40%左右)
Epoch 3+:模型彻底放弃,全部预测为负类
Epoch 6+:训练集也全部预测为负类
🔍 根本原因诊断
1. 类别不平衡处理完全失败
2. 批次采样器问题
批次内15%正样本 → 但损失函数权重没跟上
模型在"看到"15%正样本的批次中,仍然学到全部预测负类
3. 模型复杂度过高
ResNet18 + 512-256全连接层对极端不平衡问题来说太复杂
模型快速学会了"偷懒"的解决方案
立即止损建议
停止当前训练! 继续训练无意义,因为模型已收敛到错误解。
⚙️ 配置训练参数…
📊 类别分布统计:
正样本: 115 (7.2%)
负样本: 1484 (92.8%)
类别权重: 负样本=0.54, 正样本=6.95
看你这个设置 是负样本欠采样 而不是正样本过采样,为什么这样处理?
限汉字200
需要验证一下
训练集 验证集
二分类 的 样本站比
盈亏分布
“”
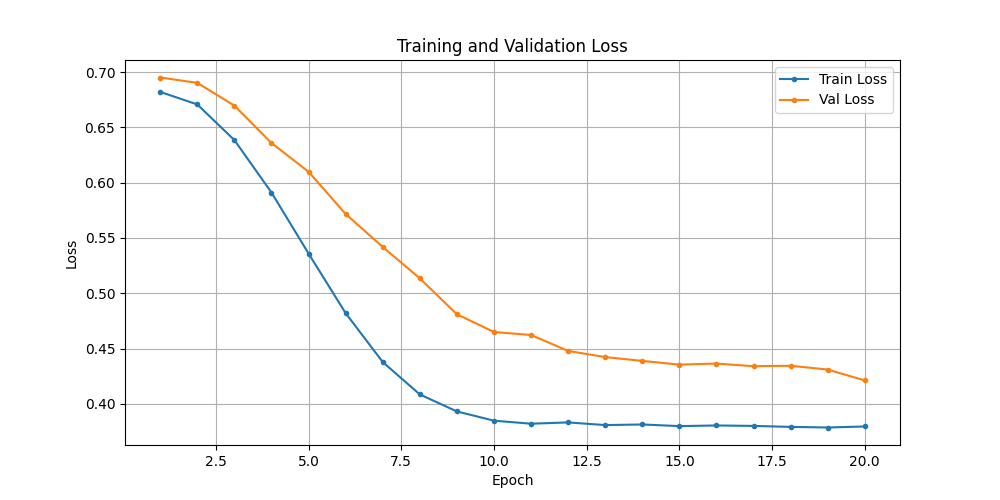
test012_train是第一个相对比较完整,修复比较完善的代码。但训练下来不成功。训练损失与验证损失无关。
本代码相比 test012_train ,一切从最简单开始:
数据特征(从单特征平面开始,重新校验标准化是否正确,标准化应该是基于所有样本中的最大值最小值去调节当前样本值,而不是只调节当前样本的最大最小值)
标签(从3分类开始)
损失函数(交叉熵开始)
网络结构(减层数、正则)
金融时序图像不应该做通道级归一化,因为:
价格数据的相对性:K线图的绝对数值有意义(如价格1000 vs 2000)
技术指标含义:均线、成交量等有特定数值范围
CNN的适应性:CNN的卷积核可以学习数据分布,不需要强制归一化
“”"
原本是:
model.fc = nn.Sequential(
nn.Dropout(0.5), # 🔥 高dropout开头,强制学习鲁棒特征
nn.Linear(in_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 1) # 无激活,纯回归输出
)
修改后
model.fc = nn.Sequential(
nn.Dropout(0.1), # 🔥 高dropout开头,强制学习鲁棒特征
nn.Linear(in_features, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 1) # 无激活,纯回归输出
)
总结
做了相当多的训练尝试,都失败了. 主要有以下失败类型:
- 验证集与训练集无关,训练损失可下降,但学到的东西没啥用,学到噪音上去了;
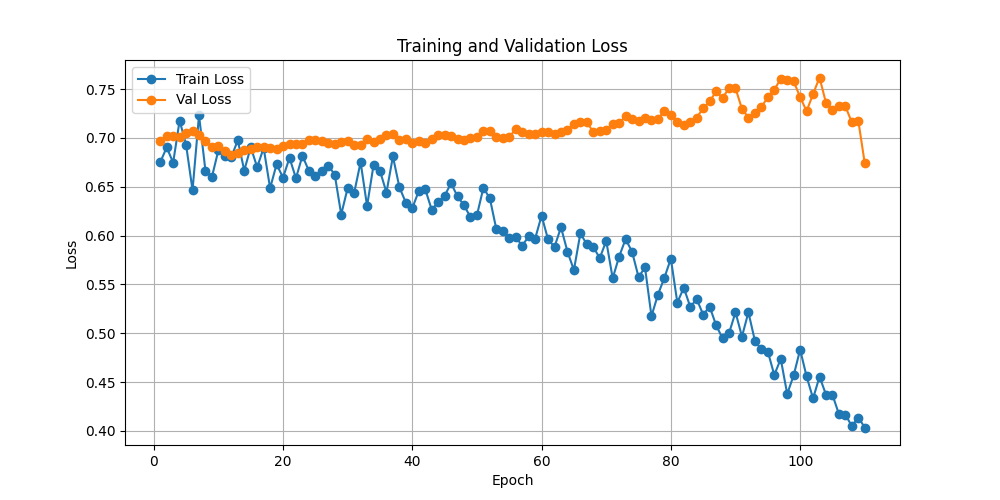
- 验证集与训练集都学不到什么东西,损失函数没下降;
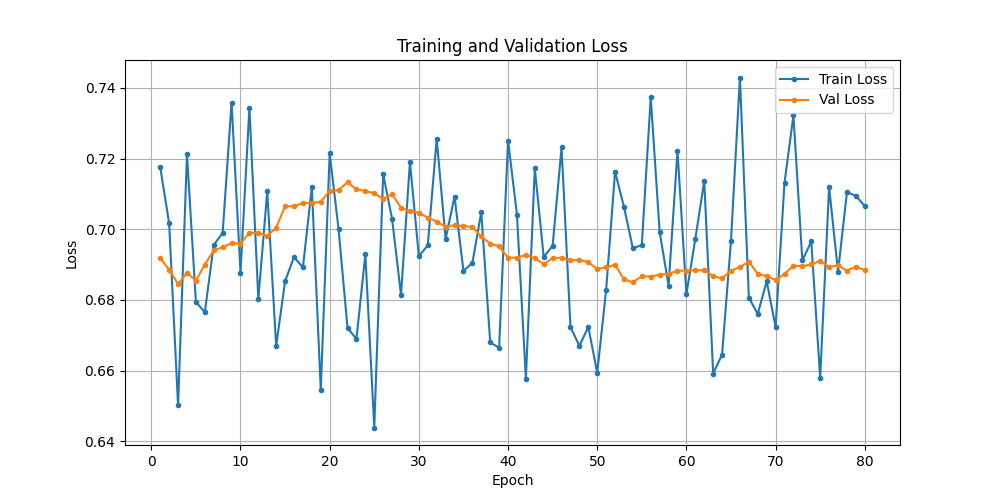
- 验证集与训练集反着来, 训练集越往下,验证集越往上翘头; 极端的,一开始就分道扬镳, 不太能理解是什么原因造成的;
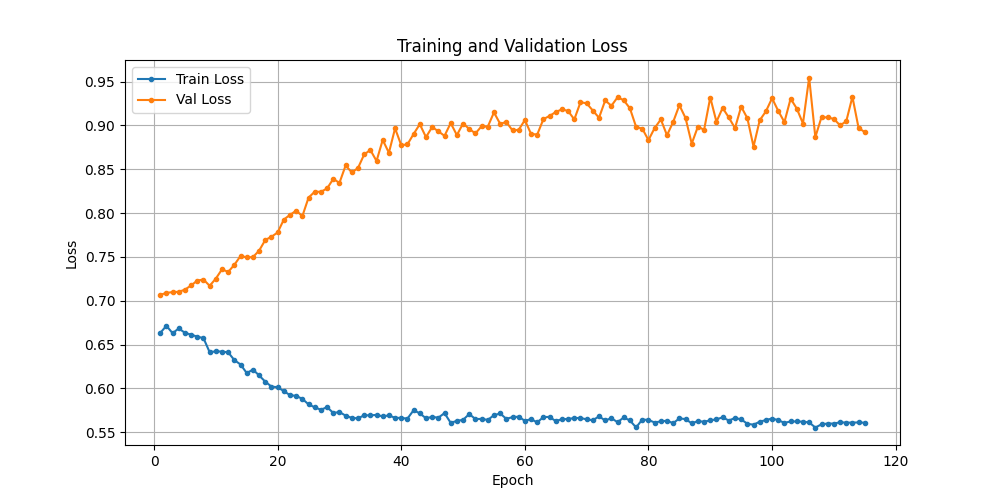
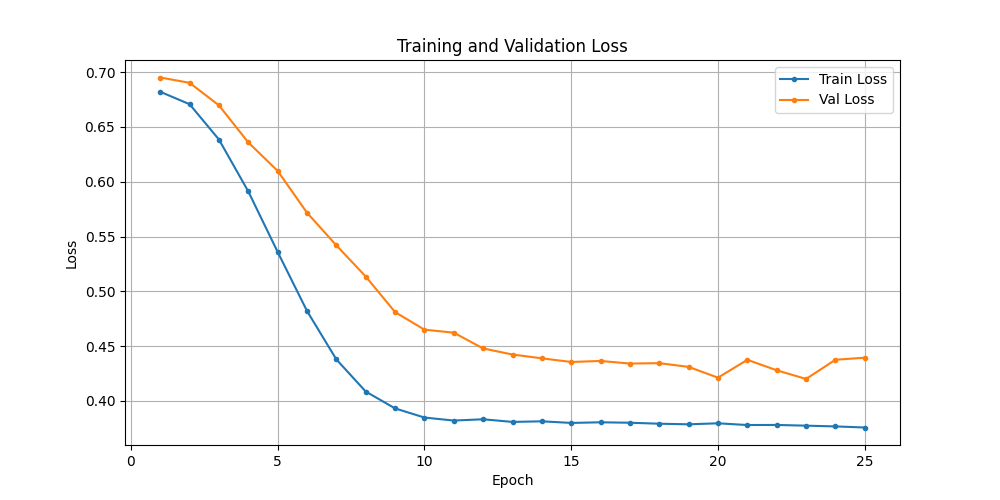
- 验证集和训练集都同步往下, 但精准率是0或者很低6%~9%,这相当于是模型趟平了,全部预测负类,收敛在了错误的方向;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)