在Android应用中集成AI:从ML Kit到设备端大语言模型
设备端AI不是要完全取代云端智能,而是提供了一种互补的选择。对于需要低延迟、高隐私的场景,设备端模型是理想选择;而对于需要最新知识或极强计算能力的任务,云端模型仍有优势。真正的智能应用,懂得在不同的场景下选择合适的智能——有时在云端,有时在掌心。随着Android 15的普及和设备硬件的进步,2024年将成为设备端AI的爆发之年。现在开始集成这些技术,不仅是为应用添加功能,更是为未来的智能体验打下
移动AI正在从云端走向设备端,这不仅改变了应用的功能边界,更重新定义了用户隐私和交互体验的标准。
AI在移动端的三次进化浪潮
Android生态中的机器学习发展经历了三个明显阶段:云依赖期、混合智能期和设备自主期。早期的AI功能几乎完全依赖网络连接,用户每次进行图像识别或语音转文字都需要将数据上传到云端,这不仅带来了延迟问题,更引发了隐私担忧。
如今,我们正站在第三次浪潮的起点——设备端大语言模型的时代。这种转变不仅仅是技术上的演进,更是对用户数据主权的一次重要回归。
ML Kit:让AI功能“开箱即用”
Google的ML Kit(现为Google AI SDK)降低了开发者集成AI能力的门槛。让我们看几个实际场景:
// 使用ML Kit进行文字识别的简单示例
val recognizer = TextRecognition.getClient()
val image = InputImage.fromBitmap(bitmap)
recognizer.process(image)
.addOnSuccessListener { result ->
val recognizedText = result.text
// 实时处理扫描到的文字
processScannedText(recognizedText)
}
.addOnFailureListener { e ->
Log.e("OCR", "识别失败", e)
}
ML Kit的核心优势:
-
设备端处理:大部分功能无需网络连接
-
预训练模型:涵盖常见使用场景
-
易于集成:几行代码即可添加复杂AI功能
但ML Kit有其局限性——它主要解决特定领域的问题。直到大语言模型的出现,移动AI才真正获得了“通用智能”的潜力。
Gemini API:云端大模型的强大能力
2023年,Google推出了Gemini系列模型,为Android应用带来了前所未有的自然语言处理能力:
// 集成Gemini API的简化示例
val generativeModel = GenerativeModel(
modelName = "gemini-pro",
apiKey = BuildConfig.GEMINI_API_KEY
)
// 与模型进行对话
val response = generativeModel.generateContent("解释量子计算的基本概念")
println(response.text)
Gemini为应用带来的新维度:
-
智能助手:真正的对话式交互
-
内容生成:从邮件草稿到创意写作
-
代码辅助:在IDE中直接获取编程帮助
-
多模态理解:同时处理文本、图像和音频
然而,云端模型有其固有缺点:延迟、成本和隐私风险。这正是设备端模型要解决的核心问题。
设备端大语言模型:隐私与性能的平衡点
Android 15引入的设备端大模型支持,标志着移动AI的新纪元。以Gemini Nano为例:
技术优势对比:
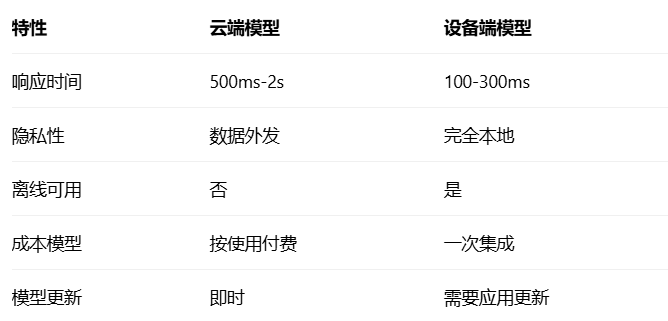
实际应用场景:
- 实时字幕的进化
// 设备端实时字幕生成
val onDeviceCaptioner = OnDeviceCaptioner.Builder(context)
.setModel(GeminiNanoModels.CAPTIONING)
.build()
// 处理视频流,实时生成字幕
val captions = onDeviceCaptioner.generateCaptions(videoFrame)
updateSubtitles(captions)
-
智能回复建议
在消息应用中,设备端模型可以:-
分析对话上下文
-
生成个性化的回复建议
-
完全保护私密对话内容
-
在飞行模式下依然工作
-
-
文档智能摘要
用户可以在离线状态下,让模型快速总结长文档的核心要点,而无需将敏感的商业文件上传到任何服务器。
实战:在Android应用中集成设备端AI
环境配置
// build.gradle
android {
defaultConfig {
// 启用设备端模型支持
buildConfigField "boolean", "ENABLE_ON_DEVICE_AI", "true"
}
}
dependencies {
// TensorFlow Lite与设备端模型支持
implementation "org.tensorflow:tensorflow-lite:2.14.0"
implementation "org.tensorflow:tensorflow-lite-support:0.4.4"
implementation "com.google.android.gms:play-services-tflite-gpu:16.2.0"
}
模型管理与优化
// build.gradle
android {
defaultConfig {
// 启用设备端模型支持
buildConfigField "boolean", "ENABLE_ON_DEVICE_AI", "true"
}
}
dependencies {
// TensorFlow Lite与设备端模型支持
implementation "org.tensorflow:tensorflow-lite:2.14.0"
implementation "org.tensorflow:tensorflow-lite-support:0.4.4"
implementation "com.google.android.gms:play-services-tflite-gpu:16.2.0"
}
模型管理与优化
class AIManager(context: Context) {
private val modelExecutor = Executors.newFixedThreadPool(2)
// 动态模型加载
suspend fun loadModel(modelType: ModelType): Result<AIModel> = withContext(Dispatchers.IO) {
return@withContext runCatching {
val modelFile = getModelFile(modelType)
// 根据设备能力选择优化策略
val options = when {
isGPUAvailable() -> ModelOptions(device = Device.GPU)
isNPUAvailable() -> ModelOptions(device = Device.NNAPI)
else -> ModelOptions(device = Device.CPU)
}
AIModel.load(modelFile, options)
}
}
// 内存敏感型推理
fun performMemoryAwareInference(
input: ModelInput,
memoryBudget: Long = 100 * 1024 * 1024 // 100MB
): ModelOutput {
// 监控内存使用
val tracker = MemoryUsageTracker(memoryBudget)
return tracker.track {
model.execute(input)
}
}
}
性能优化策略
-
模型量化与压缩
// 使用TFLite模型优化 val quantizedModel = ModelOptimizer.quantize( originalModel = originalModel, quantizationType = QuantizationType.INT8, // 减少75%模型大小 enablePruning = true // 剪枝优化 ) -
智能缓存机制
class ResponseCacheManager(context: Context) {
private val cache = LruCache<String, CachedResponse>(100)
private val diskCache = DiskLruCache(context, "ai_cache", 50 * 1024 * 1024)
fun getOrCompute(
query: String,
compute: suspend () -> ModelOutput
): Flow<ModelOutput> = flow {
val cacheKey = generateKey(query)
// 1. 内存缓存
cache.get(cacheKey)?.let {
emit(it.output)
return@flow
}
// 2. 磁盘缓存
diskCache.get(cacheKey)?.let {
val cached = deserialize(it)
cache.put(cacheKey, cached)
emit(cached.output)
return@flow
}
// 3. 重新计算
val result = compute()
val cachedResponse = CachedResponse(result, System.currentTimeMillis())
cache.put(cacheKey, cachedResponse)
diskCache.put(cacheKey, serialize(cachedResponse))
emit(result)
}
}
class PowerAwareAIProcessor(context: Context) {
private val powerManager = context.getSystemService(PowerManager::class.java)
fun scheduleAITask(task: Runnable) {
// 在设备充电时执行计算密集型任务
if (powerManager.isCharging) {
executeIntensiveTask(task)
} else {
// 电池模式下使用轻量级模型
executeLightweightTask(task)
}
}
}
用户体验设计原则
集成AI功能时,用户体验至关重要:
透明性:明确告知用户何时使用AI,以及数据处理方式
<!-- AI功能使用提示 -->
<com.google.android.material.card.MaterialCardView
android:id="@+id/ai_indicator"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:cardBackgroundColor="@color/ai_indicator_background">
<TextView
android:text="🔄 设备端AI处理中..."
android:drawableStart="@drawable/ic_device_ai" />
</com.google.android.material.card.MaterialCardView>
可控性:让用户随时可以关闭AI功能
// 用户偏好设置
val aiPreferences = AiPreferences(context)
// 检查用户是否启用AI功能
if (aiPreferences.isFeatureEnabled(AiFeature.SMART_REPLY)) {
showSmartReplies()
}
// 提供明确的开关
SwitchPreference(context).apply {
title = "设备端AI智能回复"
summary = "完全本地处理,保护隐私"
isChecked = aiPreferences.isFeatureEnabled(AiFeature.SMART_REPLY)
setOnPreferenceChangeListener { _, newValue ->
aiPreferences.setFeatureEnabled(AiFeature.SMART_REPLY, newValue as Boolean)
true
}
}
未来展望
-
多模态融合:设备端模型将能同时处理摄像头输入、麦克风音频和传感器数据,实现真正的环境感知。
-
个性化适应:模型将在设备上持续学习用户习惯,无需上传任何数据。
-
边缘协同计算:多个设备间的AI模型协同工作,如手机、手表、耳机共享计算负载。
-
标准化接口:Google正在推动统一的设备端AI API标准,简化开发者工作。
开始集成的最佳实践
-
渐进式采用:从简单的ML Kit功能开始,逐步增加复杂AI功能
-
A/B测试:对比AI功能与非AI版本的用户体验数据
-
隐私审查:确保所有AI处理符合隐私政策
-
性能监控:跟踪AI功能对应用启动时间、内存和电量的影响
结语
设备端AI不是要完全取代云端智能,而是提供了一种互补的选择。对于需要低延迟、高隐私的场景,设备端模型是理想选择;而对于需要最新知识或极强计算能力的任务,云端模型仍有优势。
真正的智能应用,懂得在不同的场景下选择合适的智能——有时在云端,有时在掌心。随着Android 15的普及和设备硬件的进步,2024年将成为设备端AI的爆发之年。现在开始集成这些技术,不仅是为应用添加功能,更是为未来的智能体验打下基础。
欢迎在评论区分享你在Android应用中集成AI的经验,或者关于设备端AI的思考。对ML Kit、Gemini API或设备端模型有任何疑问,也请随时提出!
作者:黄成康
原文链接:在Android应用中集成AI:从ML Kit到设备端大语言模型

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)