APMPlus:重新定义 AI 时代的全景全栈观测
在人工智能浪潮席卷千行百业的今天,大型语言模型(LLM)正以前所未有的深度重塑应用架构。然而,这种技术变革也带来了新的运维挑战。现代 AI 应用,尤其是基于 LLM 的应用,其内部结构日益复杂,往往由多个业务服务、AI 框架和模型调用链交织而成,形成了一个难以捉摸的“黑盒”。大模型推理结果的随机性让传统的确定性监控失效Token 消耗波动、推理延迟抖动、会话上下文丢失等问题频发智能体决策链路复杂,
在人工智能浪潮席卷千行百业的今天,大型语言模型(LLM)正以前所未有的深度重塑应用架构。然而,这种技术变革也带来了新的运维挑战。现代 AI 应用,尤其是基于 LLM 的应用,其内部结构日益复杂,往往由多个业务服务、AI 框架和模型调用链交织而成,形成了一个难以捉摸的“黑盒”。开发者和运维团队也面临着前所未有的观测挑战:
智能应用的"不可预测性":
-
大模型推理结果的随机性让传统的确定性监控失效
-
Token 消耗波动、推理延迟抖动、会话上下文丢失等问题频发
-
智能体决策链路复杂,问题溯源如同在迷宫中寻路
多层架构的"可见性盲区":
-
从用户输入到智能体决策,再到模型推理,链路跨越多个系统边界
-
LangChain、OpenAI SDK、MCP 协议等框架调用深度嵌套,调用关系错综复杂
-
推理引擎(sglang、vllm、dynamo)内部状态不透明,性能瓶颈难以定位
运维成本的"指数级增长":
-
传统 APM 工具无法理解 AI 应用的语义,只能提供基础的 HTTP/RPC 监控
-
手动埋点成本高昂,且难以覆盖快速迭代的 AI 框架
-
问题排查需要跨越业务逻辑、框架调用、模型推理三个层面,效率低下
这些挑战并非某个产品的缺陷,而是 AI 原生时代的共性难题——当应用逻辑从确定性转向概率性,当系统架构从单体演进为智能体+推理引擎的分布式协作,传统监控方法论已然力不从心。
如何让 AI 应用的运行状态透明化?如何快速定位智能应用的性能瓶颈?火山引擎可观测平台推出 AI 应用监控产品,为这个时代的技术挑战给出了答案。
火山引擎 AI 观测解决方案
火山引擎推出的 AI 应用监控产品,聚焦破解 AI 应用“黑盒”难题,提供从代码到模型的全链路监控。除传统指标(QPS、延迟、错误率)外,聚焦 AI 特有指标(Token 消耗、TPOT、TTFT),并整合 Metrics、Trace、Log 数据,实现一体化监控:
-
AI 监控看板
-
模型视角:监控模型调用次数、耗时、Token 使用排行等。
-
服务视角:展示 LLM 性能(耗时、TPOT、调用排行)及 Token 用量(总量、单次消耗)。
-
-
AI Trace 分析
-
链路追踪:支持 Trace 列表查询与单链路详情分析,标记 LLM 调用类型(如 tool、task),展示 Token 消耗。
-
多维视图:提供调用列表、服务拓扑图、火焰图、Span 详情,精准定位性能瓶颈。
-
-
MTL 一体化关联
-
打破数据孤岛,实现 Metrics、Trace、Log 联动查询。例如:日志关联 TraceID、Trace 反向查询日志、Span 关联实时指标。
-
-
端到端全链路观测
-
覆盖从用户终端(App/Web)→网关→后端服务→AI 框架(如 LangChain)→推理引擎(如 vLLM)的全链路追踪。
-
通过自动化注入(字节码增强等)和 OpenTelemetry 标准,实现零代码侵入式监控。
-
-
AI 框架与推理引擎深度支持
-
兼容 Python/Java/Node.js 等语言,支持 LangChain、OpenAI 等框架,自动识别 Chain/Agent 调用。
-
监控推理引擎(如 vLLM)核心指标(QPS、TTFT、TPOT)及运行时数据(CPU、内存)。
-
-
LLM 会话观测
-
以会话为单位追踪全生命周期,支持按会话 ID、用户等维度检索,关联每轮对话的 Token 消耗与调用链路,实现下钻分析。
-
通过全链路、多维度、低侵入的监控能力,AI 应用监控可以助力用户精准洞察 AI 应用性能,优化资源消耗与用户体验。下面,我们以两个客户场景为例,介绍其在生产场景的具体表现。
AI 观测在实际业务中的价值体现
案例一:Agent 应用性能问题诊断与优化
某客户在火山上搭建了一个智能体应用,应用部署在火山引擎的 veFaaS 上,同时开启了应用监控(需开启 APMPlus 服务),推理引擎使用的是火山引擎提供的推理引擎镜像,自带了 APMPlus 埋点信息,客户无需做任何改造就实现了零开发成本接入。
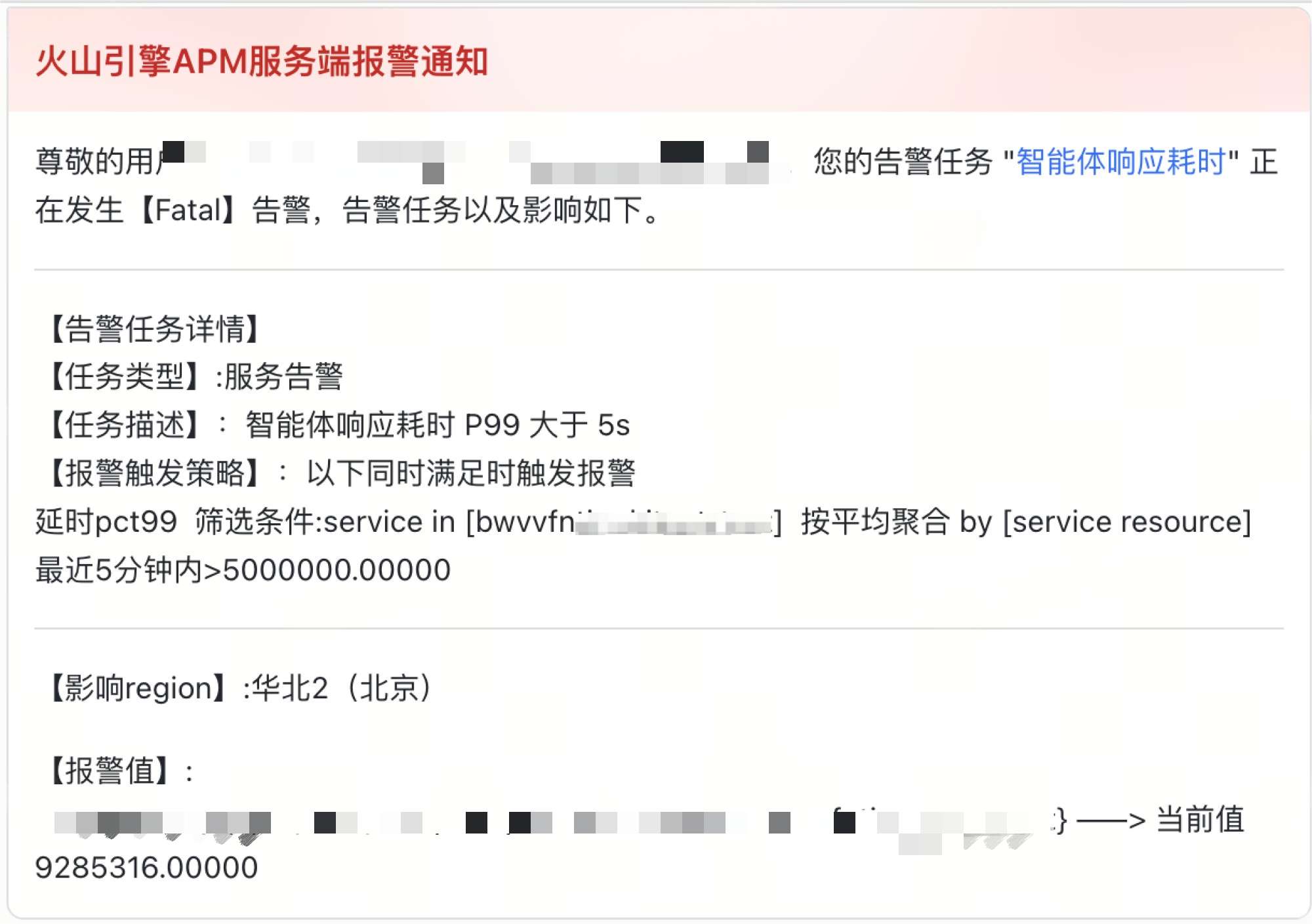
发现问题 - 告警洞察,即时响应
在晚高峰时段客户突然收到 AI 应用监控通过飞书发出的告警,发现该智能体应用耗时 P99 大于 5 秒。告警信息不仅清晰地指出了问题服务和异常指标,还附带了直达监控面板的链接,让客户无需任何手工查找,第一时间进入了“战场”。
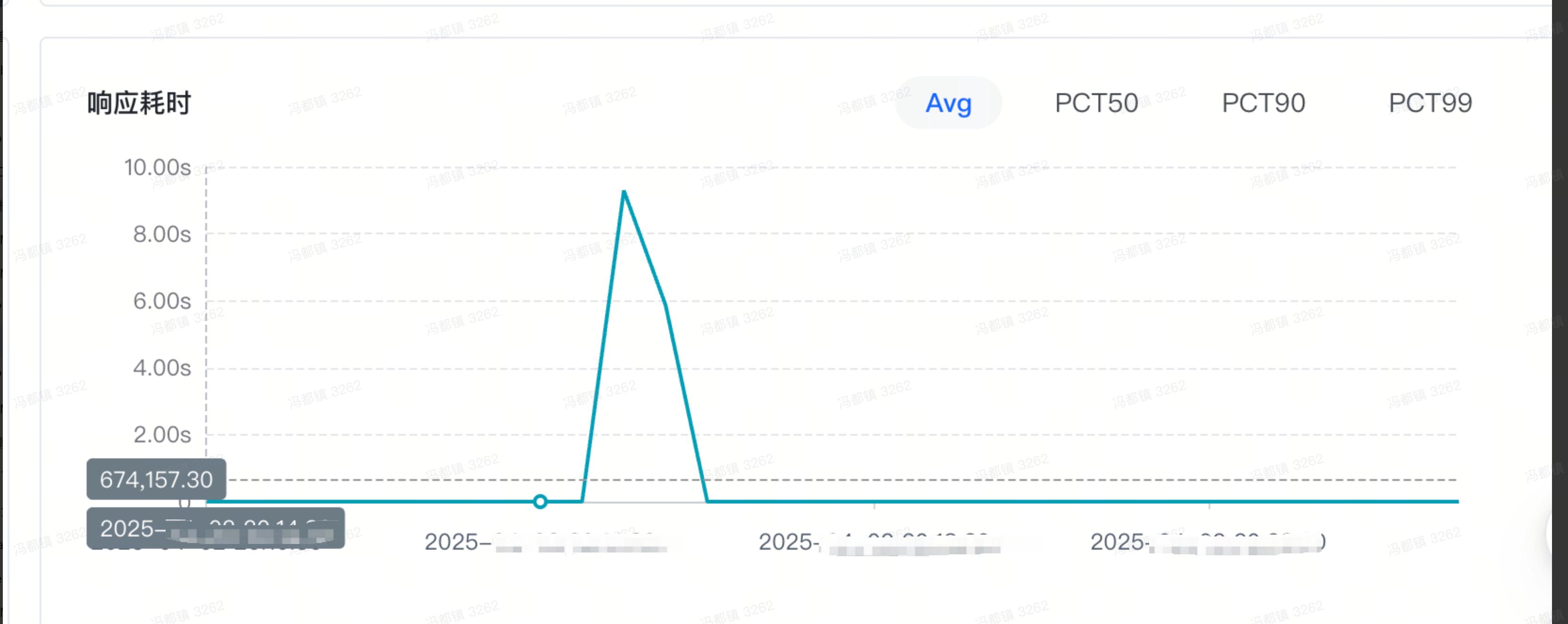
定位问题 - 层层下钻,直抵根因
通过报警卡片信息,我们可以发现定位到耗时增加的服务,进入AI 应用监控对应服务的详情页,可以看到响应耗时的情况。
再通过 Trace 分析界面,查找对应 trace 的火焰图
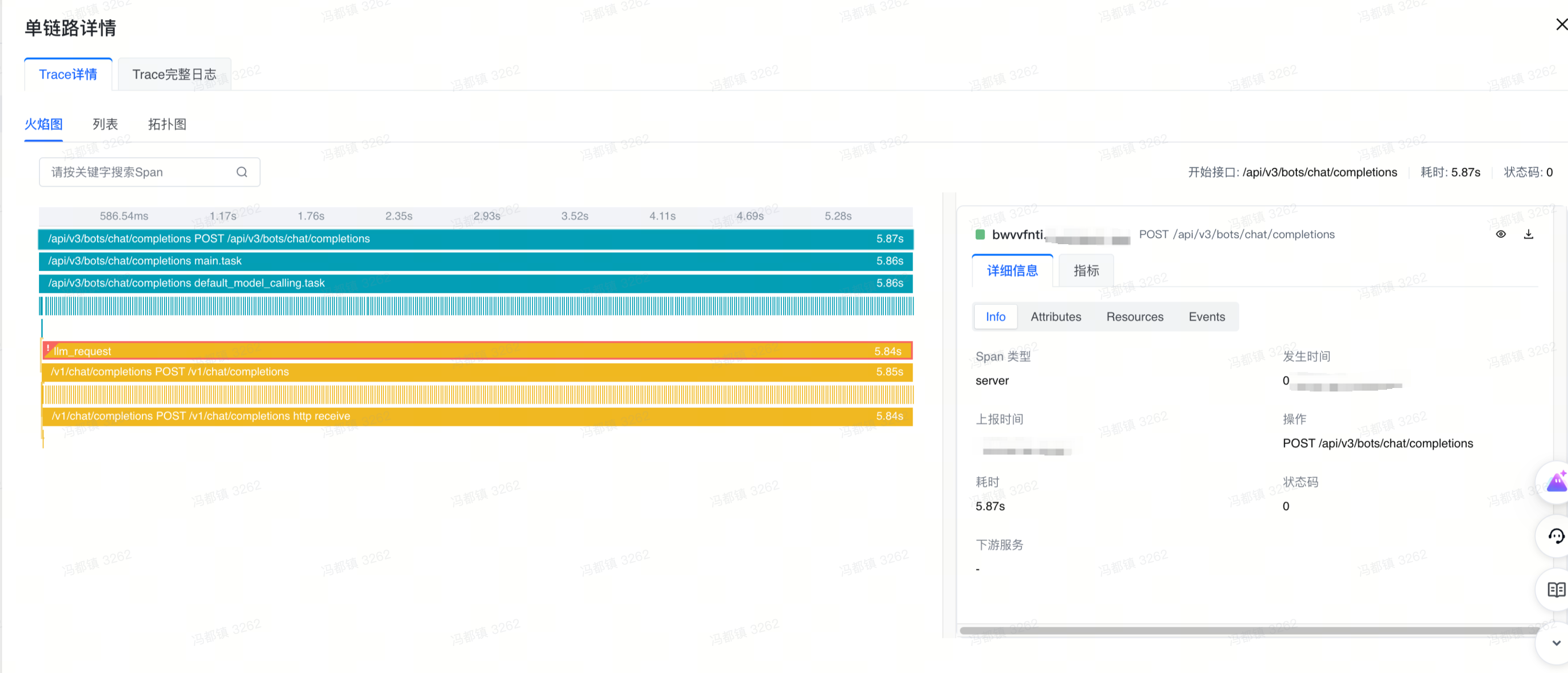
火焰图里,不同服务对应的火焰图颜色会不一致。而客户此时发现,llm_request 这个 span 有感叹号标识,说明这个 span 有报错。切换到 列表页和拓扑图页,也能够同样看到这个 span 和感叹号标识
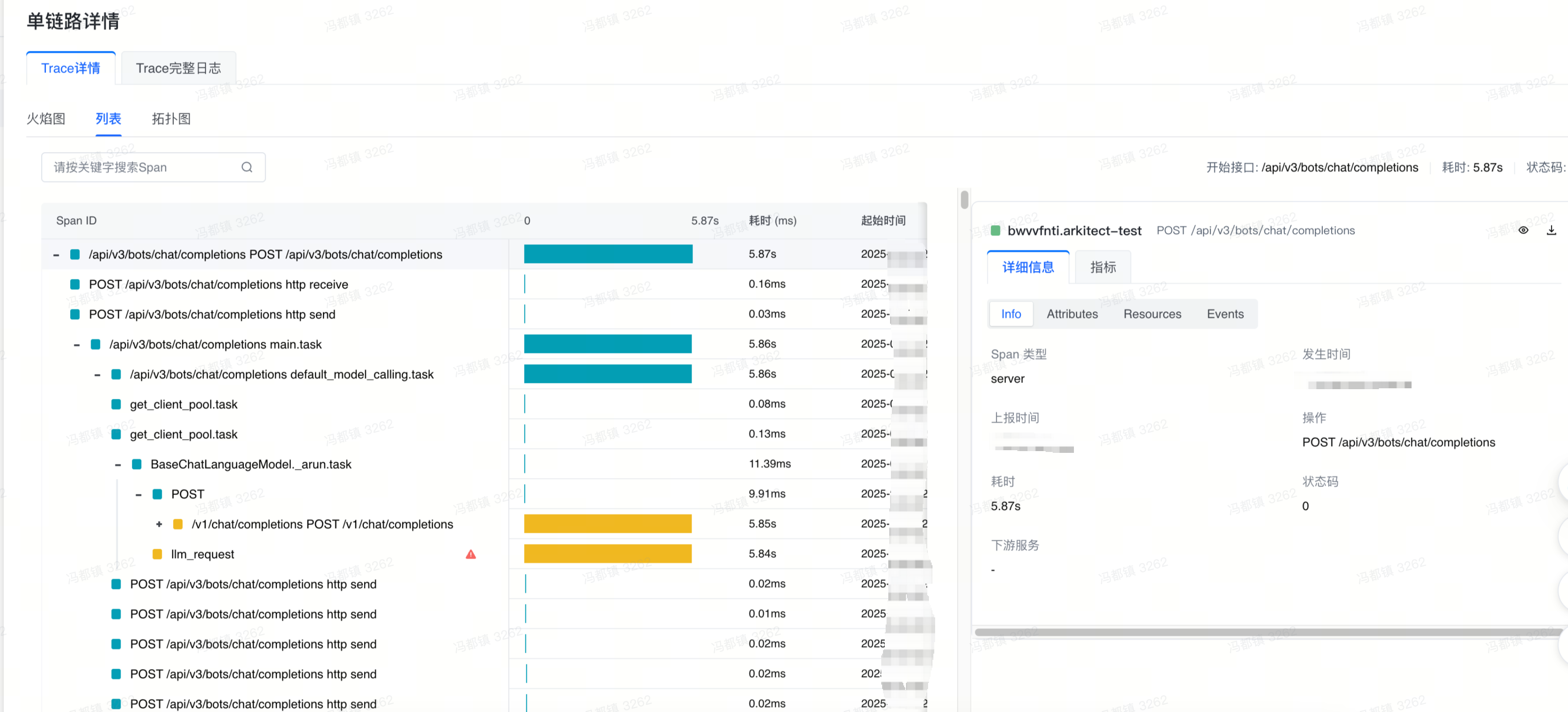
点击 llm_request span,在右侧可以看到这个 span 的详细信息,可以发现他是属于 dynamo 推理引擎的服务,切换到 Events 列,能够看到这个 span 所发生错误的详细堆栈信息。
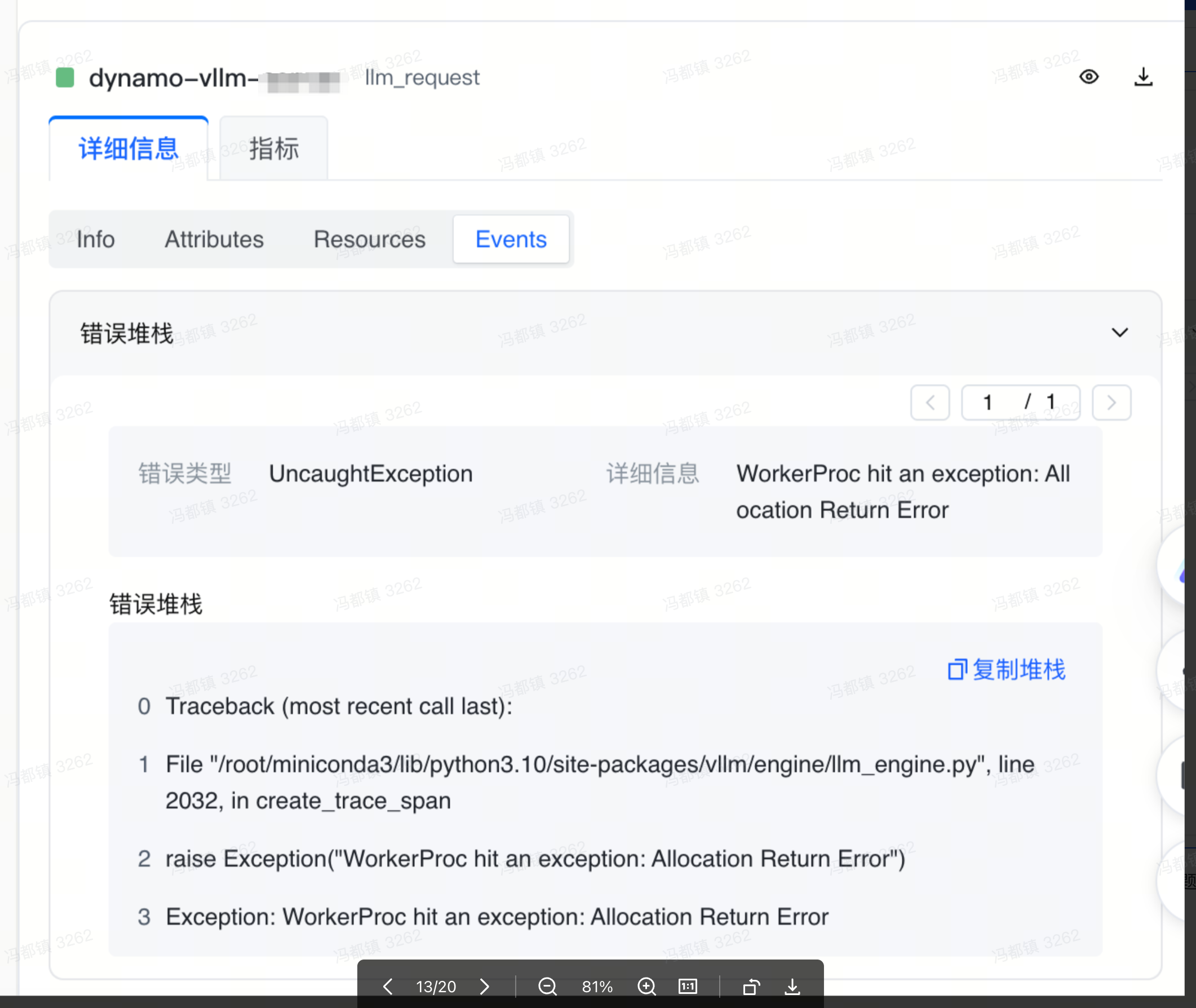
根据错误堆栈信息,可以可以发现这个错误是因为 vllm 引擎内存分配出现问题。从而可以是推理侧引擎的问题导致了智能体响应耗时增加,至此,问题就定位到了。
解决问题 - 对症下药,闭环验证
根因明确,解决路径也变得清晰。客户立即联系开发团队,对推理引擎内存分配进行了优化。部署更新后,客户回到 AI 应用监控的服务监控大盘观察效果。根据观测大盘数据,服务响应的 P99 延迟迅速回落到 2s 以内,问题得到圆满解决。
最终成果
-
通过报警系统,及时发现异常。
-
通过快速筛选异常的推理 span,5 分钟内发现问题。治理问题能力大幅提升。
-
客户自助解决问题,节约 3 人力排查问题,排查时间大大缩短。
案例二:Token 消耗监控,成本优化
业务背景
某企业在火山引擎上部署了一款 AI 写作助手,该应用需要处理大量文本生成任务,Token 消耗量巨大。随着业务规模扩大,如何实现精准的成本控制成为客户面临的核心挑战。
解决方案
客户通过 AI 应用监控提供的 Token 监控能力,建立了完整的成本管理体系:

-
实时监控:基于 AI 应用监控记录的 Token 消耗指标,设置了精细化报警规则,实现对 Token 使用的实时监控
-
对比分析:利用 Token 用量看板,从模型类型、使用场景等维度进行多角度对比分析
-
数据驱动:通过 Token 使用量排行功能,清晰识别不同模型在消耗量上的显著差异
实施效果
通过数据对比和成本分析,客户发现部分模型的 Token 消耗与成本效益存在明显差异。基于 AI 应用监控提供的精准数据支撑,客户最终选择了成本更优的模型方案,实现了:
-
成本显著降低:整体 Token 消耗成本下降 30%
-
监控体系完善:建立实时监控和预测机制,实现成本可控
-
决策效率提升:数据驱动的决策模式取代经验判断,优化效率大幅提高
这一案例表明,火山引擎 AI 应用监控不仅提供了基础监控能力,更通过深度数据洞察助力企业实现精细化的成本管控,为 AI 应用的大规模商业化落地提供了重要支撑。
小结
人工智能正在深刻改变世界,而这一变革的实现,离不开可观测、可预测、可控制的技术环境作为支撑。在这一背景下,火山引擎 AI 观测解决方案应运而生——它不仅是一套监控工具,更是 AI 时代不可或缺的技术基础设施:让每一个 Token 的消耗有据可查,每一次推理的延迟有迹可循,每一个智能决策有根可溯。
面向未来,火山引擎可观测团队将持续深耕 AI 观测领域,致力于成为 AI 原生时代的观测标准,具体从以下三个方向持续进化:
构建更深层的 AI 理解能力
-
持续扩展对 Dify、ADK 等主流及新兴 AI 框架的兼容支持
-
深化多模态 AI 应用的监控能力,实现对视觉、语音、文本等模态的统一观测
-
增强对 AI Agent 协作模式的监控,支持多 Agent 系统中复杂交互行为的分析与追溯
打造更智能的排障流程
-
提供覆盖典型 AI 场景的预置看板与报警规则,大幅降低用户使用门槛
-
基于实时可观测数据,在故障发生时自动进行根因分析,并主动推送诊断结论,辅助用户快速定位问题
推动更开放的生态建设
-
提供标准化的 AI 观测 API,支持与各类第三方工具和平台无缝集成
-
建立行业通用的 AI 观测数据标准格式,促进不同系统之间的互操作与数据共享
通过以上路径,火山引擎可观测团队将持续赋能 AI 技术落地,让智能系统的运行更透明、更可靠,真正推动人工智能在业务中创造价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)