零门槛体验 GPT-OSS:在 BitaHub 一键搭建专属 AI
GPT-OSS 是 OpenAI 推出的首个开源权重(open-weight)模型系列,开发者可以在本地计算机上直接运行,无需依赖外部 API。与许多封闭式大语言模型不同,GPT-OSS 以灵活性与透明性为核心设计,既能胜任复杂推理与智能体任务,也能为开发者提供高度的可定制化能力。它的一大亮点在于 可配置的推理深度(reasoning effort) 和 可选的透明思维链(chain-of-tho
GPT-OSS 是 OpenAI 推出的首个开源权重(open-weight)模型系列,开发者可以在本地计算机上直接运行,无需依赖外部 API。与许多封闭式大语言模型不同,GPT-OSS 以灵活性与透明性为核心设计,既能胜任复杂推理与智能体任务,也能为开发者提供高度的可定制化能力。它的一大亮点在于 可配置的推理深度(reasoning effort) 和 可选的透明思维链(chain-of-thought),这让它在研究、原型验证和教学演示中具有独特价值。
在本教程中,我将带你完成通过 BitaHub 平台运行 GPT-OSS 的完整流程。相比在本地自行配置环境,BitaHub 提供了即开即用的 GPU 算力环境,预装常用的 AI 框架,用户无需复杂的依赖安装即可直接运行 Ollama 和 GPT-OSS 模型,大幅降低了上手门槛。完成环境准备后,我们还会在 BitaHub 上构建一个 基于 Streamlit 的交互式应用,用于演示 GPT-OSS 的推理能力,并直观展示它的思维链路。整个过程无需额外的本地算力支持,完全可以在云端一站式完成。
通过本教程,你不仅能掌握如何在 BitaHub 平台上运行 GPT-OSS,还能快速上手开发属于自己的 LLM 小工具,实现从模型调用到应用原型搭建的完整流程。
一.创建开发环境
打开BitaHub工作台,创建开发环境。
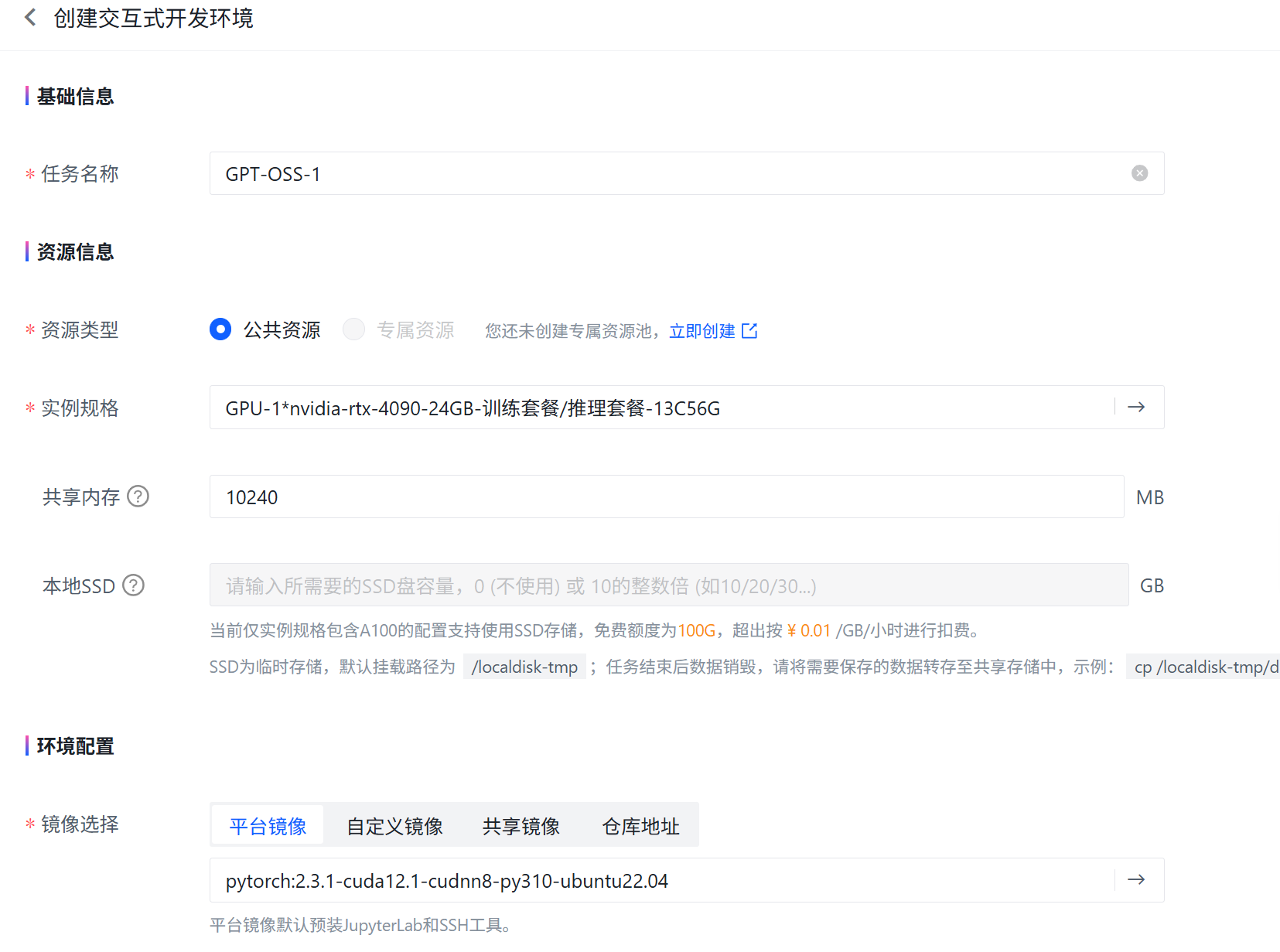
由于 Streamlit 默认运行在 8501 端口,因此在新建开发环境时,在端口设置中直接添加 8501。

二.在 BitaHub 上使用 Ollama 本地部署 GPT-OSS
打开 Ollama 官方网站(https://ollama.com) ,在首页即可找到不同操作系统的安装指令。复制对应的安装命令,打开你终端并执行。
curl -fsSL https://ollama.com/install.sh | sh
启动 Ollama 服务
ollama serve
OpenAI 提供了两个针对不同使用场景优化的 GPT-OSS 模型版本,但在本次演示中,我们只会拉取其中的 gpt-oss-20b 版本。
ollama pull gpt-oss:20b
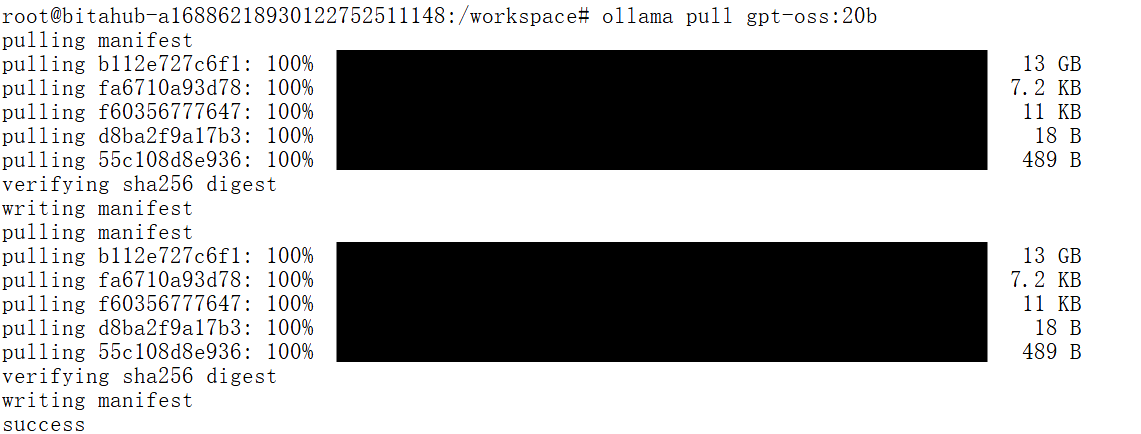
20B 模型非常适合本地开发,在内存 16GB 及以上的系统上即可运行;而 120B 模型功能更强大,但需要 80GB 以上内存才能支持。接下来,我们来验证一下前面的安装是否成功,确保一切正常运行:
ollama run gpt-oss:20b

三.基于 GPT-OSS 的本地智能对话机器人
1.安装依赖
在你的 Python 环境中执行:
pip install streamlit ollama
streamlit:用于快速搭建 Web 界面
ollama:Python 客户端,用于与本地 Ollama 服务通信(需先 ollama serve 并 ollama pull gpt-oss:20b)
2.创建应用 app.py
把下面完整代码保存为 app.py:
这段代码首先通过页面配置和 CSS 美化,使推理过程、最终答案、性能指标和对话消息在界面中直观分区显示;核心功能部分使用 Ollama Python 客户端调用 GPT-OSS 模型,并在响应中解析出推理链和最终结论,既展示了模型的“思维过程”,又给出了用户关心的最终回答。同时,借助 Streamlit 的 session_state 管理对话历史,使用户能够随时回顾之前的问答。侧边栏提供了灵活的配置选项,包括模型选择(20B/120B)、推理深度、Temperature 等,还可以选择是否显示推理链或性能指标。主界面允许用户直接输入问题或从示例中选择,点击按钮后,应用会生成回答,并根据配置展示推理和答案。历史对话区采用不同的样式区分用户与模型消息,并支持展开查看详细推理过程。
import streamlit as st
# 提交按钮
col1, col2 = st.columns([1, 4])
with col1:
submit_button = st.button("询问 GPT-OSS", type="primary")
if submit_button and question.strip():
# 系统提示词
system_prompts = {
'low': 'You are a helpful assistant. Provide concise, direct answers.',
'medium': f'You are a helpful assistant. Show brief reasoning before your answer. Reasoning effort: {effort}',
'high': f'You are a helpful assistant. Show complete chain-of-thought reasoning step by step. Think through the problem carefully before providing your final answer. Reasoning effort: {effort}'
}
# 信息历史
msgs = [{'role': 'system', 'content': system_prompts[effort]}]
msgs.extend(st.session_state.history[-6:])
msgs.append({'role': 'user', 'content': question})
with st.spinner(f"GPT-OSS thinking ({effort} effort)..."):
res = call_model(msgs, model_choice, temperature)
if res['success']:
parsed = parse_reasoning_response(res['content'])
st.session_state.history.append({'role': 'user', 'content': question})
st.session_state.history.append({'role': 'assistant', 'content': res['content']})
col1, col2 = st.columns([3, 1] if show_metrics else [1])
with col1:
if show_reasoning and parsed['reasoning'] != 'No explicit reasoning detected.':
st.markdown("### Chain-of-Thought Reasoning")
st.markdown(f"<div class='reasoning-box'>{parsed['reasoning']}</div>", unsafe_allow_html=True)
st.markdown("### Answer")
st.markdown(f"<div class='answer-box'>{parsed['answer']}</div>", unsafe_allow_html=True)
if show_metrics:
with col2:
st.markdown(f"""
<div class="metric-card">
<h4> Metrics</h4>
<p><strong>Time:</strong><br>{res['response_time']:.2f}s</p>
<p><strong>Model:</strong><br>{model_choice}</p>
<p><strong>Effort:</strong><br>{effort.title()}</p>
</div>
""", unsafe_allow_html=True)
else:
st.error(f"{res['content']}")
if st.session_state.history:
st.markdown("---")
st.subheader("对话历史")
recent_history = st.session_state.history[-8:] # Last 8 messages (4 exchanges)
for i, msg in enumerate(recent_history):
if msg['role'] == 'user':
st.markdown(f"""
<div class="chat-message user-message">
<strong>You:</strong> {msg['content']}
</div>
""", unsafe_allow_html=True)
else:
parsed_hist = parse_reasoning_response(msg['content'])
with st.expander(f"GPT-OSS Response", expanded=False):
if parsed_hist['reasoning'] != 'No explicit reasoning detected.':
st.markdown("**Reasoning Process:**")
st.code(parsed_hist['reasoning'], language='text')
st.markdown("**Final Answer:**")
st.markdown(parsed_hist['answer'])
st.markdown("---")
st.markdown("""
<div style='text-align: center;'>
<p><strong>Powered by GPT-OSS | Deployed on BitaHub</strong></p>
</div>
""", unsafe_allow_html=True)
在完成代码编写并保存为 app.py 文件后,只需要在终端中运行以下命令即可启动应用:
streamlit run app.py

执行后,Streamlit 会自动启动一个本地 Web 服务,回到开发环境复制完整的的访问地址在浏览器中粘贴打开,就能看到刚刚构建的 GPT-OSS × BitaHub 聊天应用界面,开始与模型进行交互了。
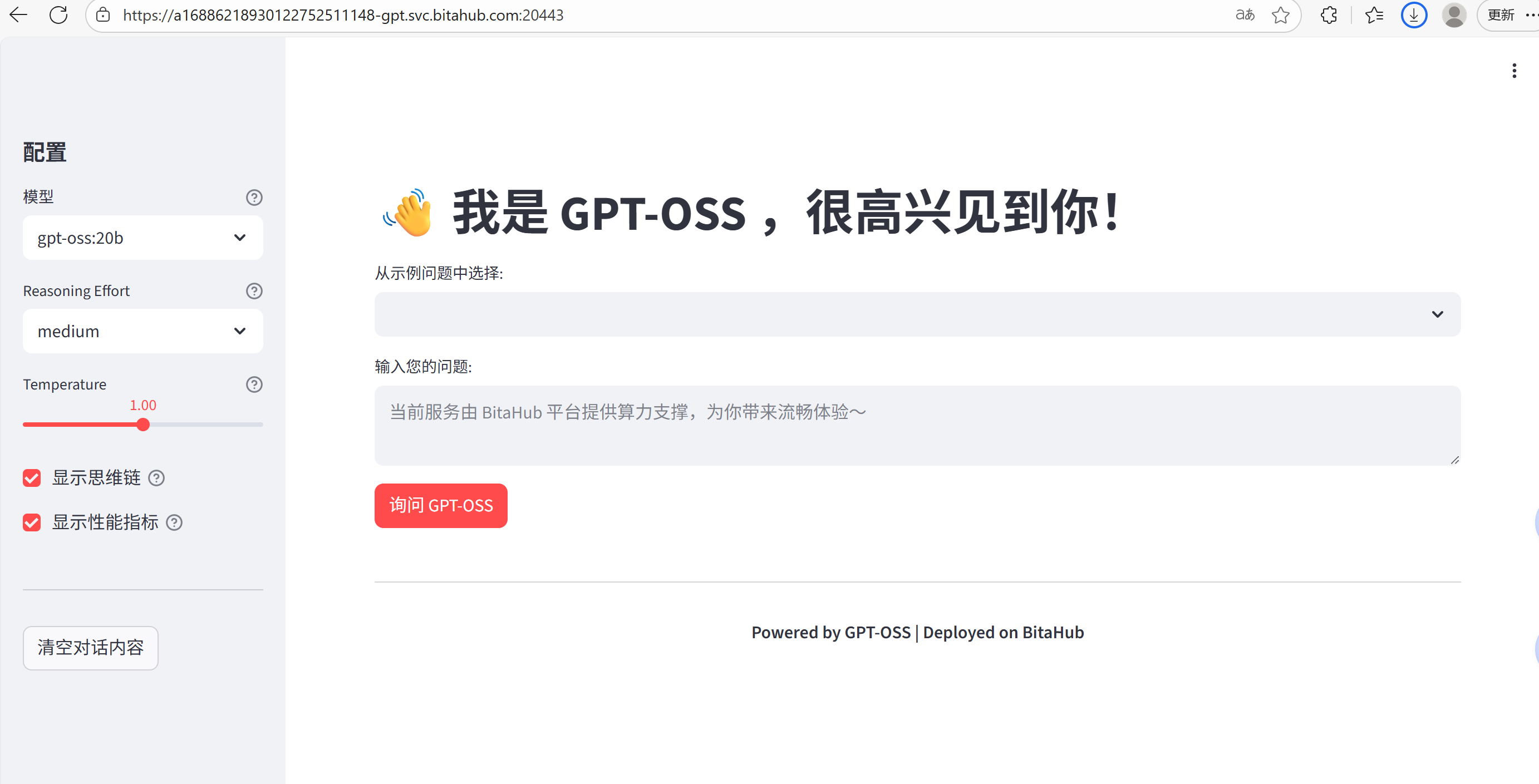

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)