【AI课程领学】第三课4/5:前馈运算(Forward Pass)——张量如何流动?线性层、卷积、激活、归一化与注意力的统一视角(含 NumPy + PyTorch 例子)
【AI课程领学】第三课4/5:前馈运算(Forward Pass)——张量如何流动?线性层、卷积、激活、归一化与注意力的统一视角(含 NumPy + PyTorch 例子)
·
【AI课程领学】第三课4/5:前馈运算(Forward Pass)——张量如何流动?线性层、卷积、激活、归一化与注意力的统一视角(含 NumPy + PyTorch 例子)
【AI课程领学】第三课4/5:前馈运算(Forward Pass)——张量如何流动?线性层、卷积、激活、归一化与注意力的统一视角(含 NumPy + PyTorch 例子)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
1. 前馈运算是什么?
前馈(forward pass)就是:
- 给定输入 x x x,模型计算输出 y ^ \hat{y} y^ 的过程。
它决定了:
- 模型表达能力
- 输入输出维度如何变化
- 中间特征(representation)是什么样的
2. 最基本前馈:线性层 + 激活
- 线性层:
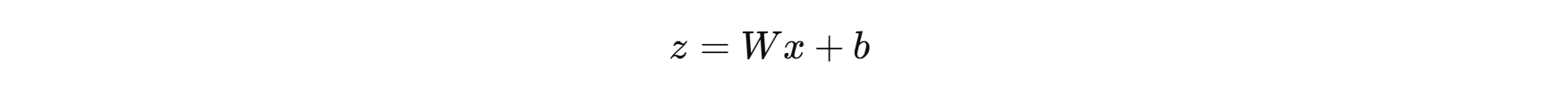
- 激活(以 ReLU 为例):
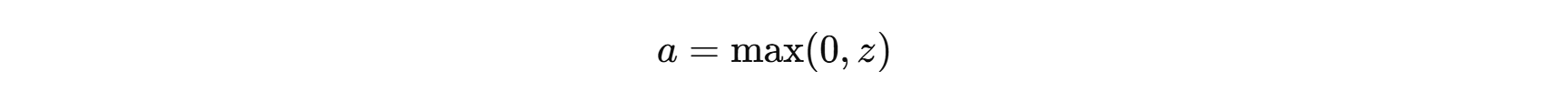
2.1 NumPy 演示(看清形状变化)
import numpy as np
np.random.seed(0)
batch, in_dim, out_dim = 4, 3, 5
X = np.random.randn(batch, in_dim)
W = np.random.randn(in_dim, out_dim)
b = np.random.randn(out_dim)
Z = X @ W + b # (4,5)
A = np.maximum(0, Z) # ReLU
print("X:", X.shape, "Z:", Z.shape, "A:", A.shape)
3. 卷积层前馈(CNN 的核心)
- 二维卷积可以理解为“带共享权重的局部线性变换”。
卷积输出:
- 输入: (B, C_in, H, W)
- 输出: (B, C_out, H’, W’)
3.1 PyTorch 一眼看懂维度
import torch
import torch.nn as nn
x = torch.randn(2, 3, 64, 64) # B=2, RGB=3
conv = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
y = conv(x)
print(x.shape, "->", y.shape)
卷积的意义(直觉):
- 低层卷积学边缘/纹理
- 中层学结构
- 高层学语义
4. 归一化(BatchNorm / LayerNorm)前馈
归一化的作用:
- 让激活分布更稳定
- 让训练更快、更不容易梯度爆炸/消失
4.1 BatchNorm2d 示例
bn = nn.BatchNorm2d(16)
y_bn = bn(y)
print(y.mean().item(), y_bn.mean().item())
5. 注意力机制(Attention)前馈:统一公式视角
自注意力的核心是:
- 让每个 token/像素动态地“看”其他 token/像素。
公式(简化):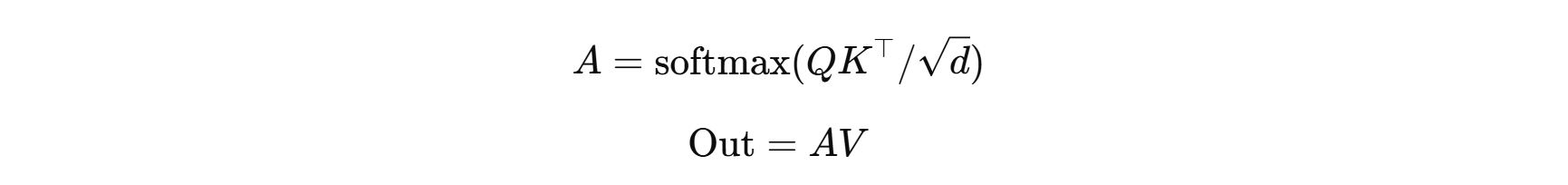
5.1 用 PyTorch 张量实现最小注意力
import torch, math
B, T, d = 2, 8, 32
x = torch.randn(B, T, d)
Wq = torch.randn(d, d)
Wk = torch.randn(d, d)
Wv = torch.randn(d, d)
Q = x @ Wq
K = x @ Wk
V = x @ Wv
scores = (Q @ K.transpose(-1, -2)) / math.sqrt(d) # (B,T,T)
attn = torch.softmax(scores, dim=-1)
out = attn @ V # (B,T,d)
print(out.shape)
6. 前馈运算的常见坑
- 张量维度错(尤其 CNN/Transformer)
- 忘记 model.eval() 导致 BN/Dropout 不稳定
- 数值不稳定(softmax 溢出、log(0))
- 未标准化输入导致训练很难收敛
7. 小结
前馈运算是“模型表达”的载体:
- 线性层决定基本映射
- 激活提供非线性
- 卷积/注意力提供结构归纳偏置
- 归一化保证训练稳定
下一篇我们进入关键:反馈运算(反向传播)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)