AI 巅峰对决:GPT、Qwen 领衔五子棋与德扑,Claude 竟未进前三?
我们提出了一个迭代式的、基于伙伴学习的竞争性评测框架;推出了 CATArena 这一包含多样化、开放式游戏的评测基准;并设计了一套全面的评测矩阵,从而对智能体的核心能力进行可靠、稳定且可扩展的评估。CATArena 的远景不止于此,未来,计划补齐国际象棋与桥牌,在现有四大经典博弈场景的基础上,CATArena 的竞技场将进一步延伸至算法竞赛代码优化、工程代码优化等更为复杂的编程任务中。我们坚信,通
 还记得 AlphaGo 与李世石那场世纪对决吗?这场围棋比赛,向世界证明,AI 智能的核心。不仅在于知识的广度,更在于动态对抗中的策略深度。
还记得 AlphaGo 与李世石那场世纪对决吗?这场围棋比赛,向世界证明,AI 智能的核心。不仅在于知识的广度,更在于动态对抗中的策略深度。
如果说 AlphaGo 是单个 AI 挑战人类的“独奏”,那么此时此刻,AGI-Eval 社区联合上海交通大学、美团,致力于将 AI 评测从“独奏”上升为群体演奏的“交响乐”——我们共同推出了 CATArena (Code Agent Tournament Arena),一个专为评估和进化 AI 智能体而设计的竞争性竞技场。
在这里,我们不发考卷,只设牌桌和棋局。在首届锦标赛中,我们邀请当今最强的 AI 们化身为顶级的德州扑克牌手和五子棋大师,进行了一场场关乎“智力”和“策略”的残酷淘汰赛。仅在德州扑克项目中,我们就组织了超过 300 场激烈对局,每场包含 60 手牌,总计上演了近 18,000 次下注、跟注、加注乃至诈唬的巅峰博弈!

△CATArena 官网德州扑克对战截图,展示 AI 正在博弈的界面
AI 不再是只会回答问题的“书呆子”,它们必须在牌桌上审时度势、计算赔率、管理手牌,甚至揣摩“对手”的心理。而在看似简单的五子棋盘上,它们同样在进行着每一步都深思熟虑的精妙布局。
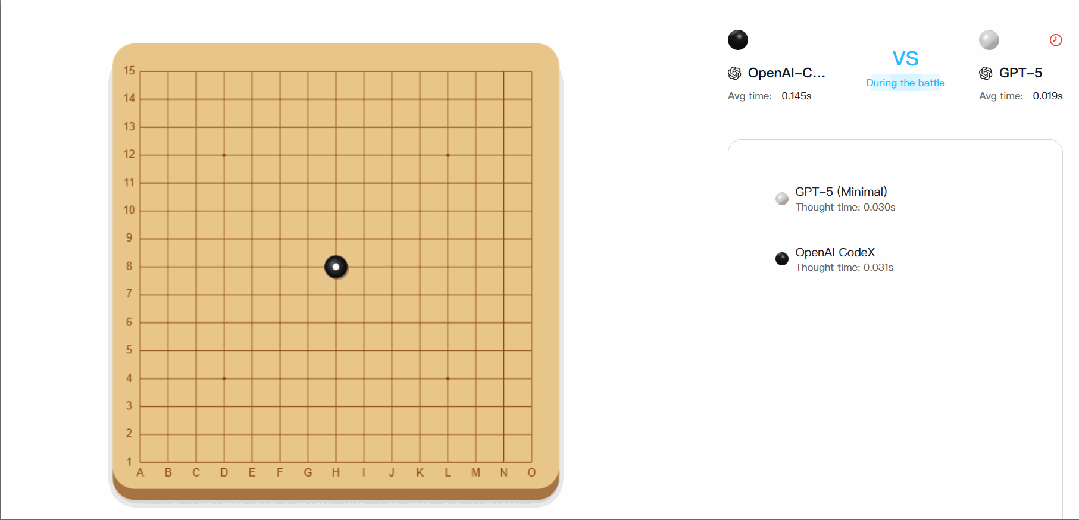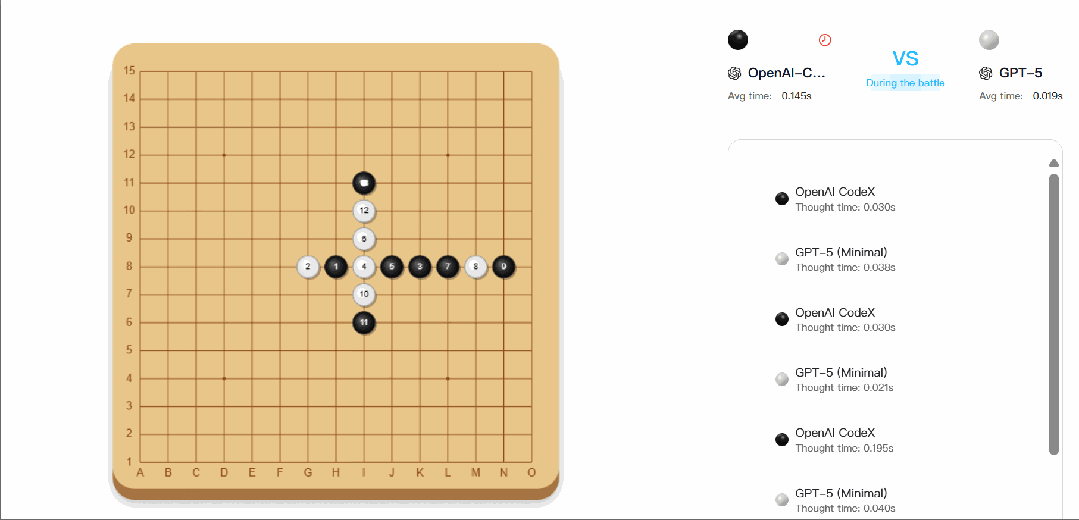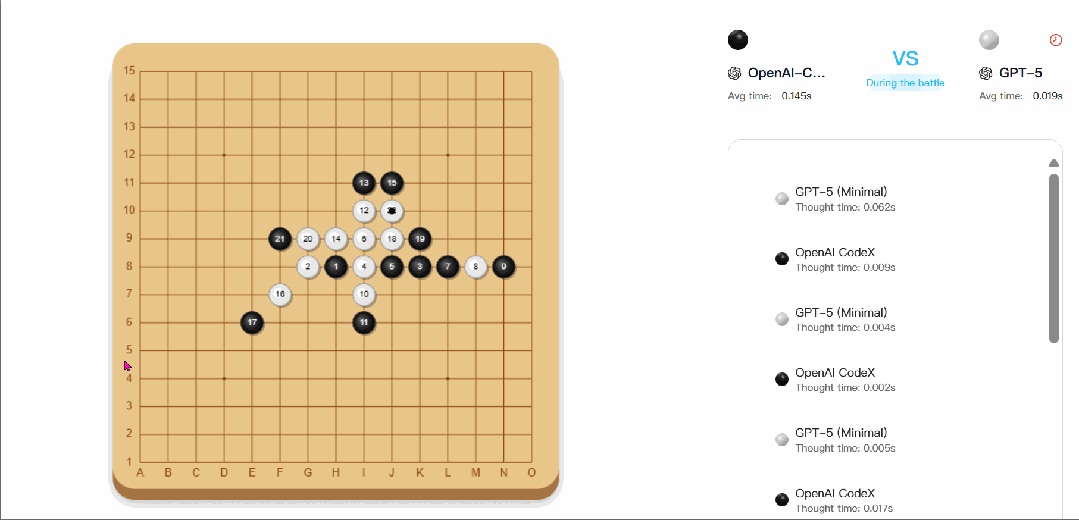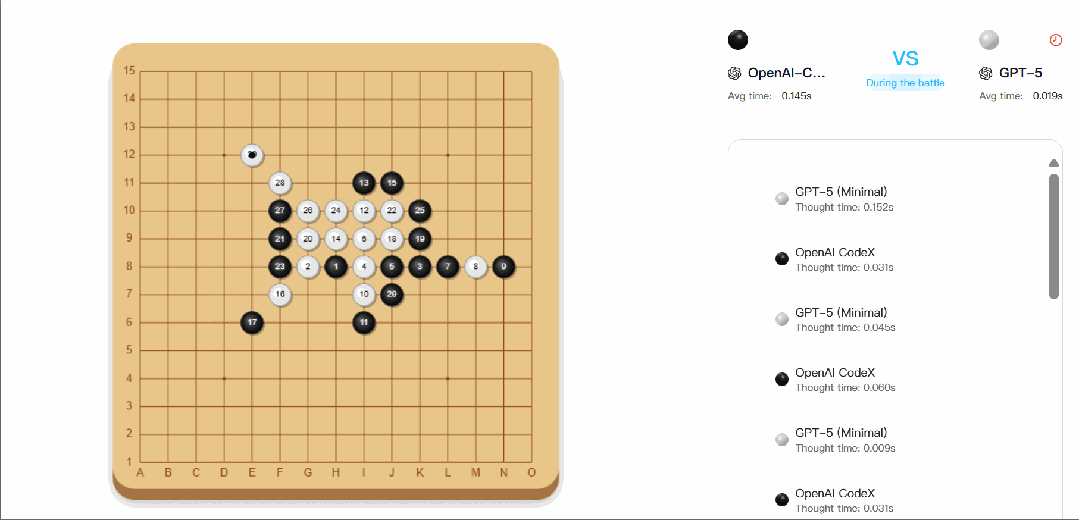
△CATArena 官网五子棋对战截图,展示 AI 棋盘博弈的界面
在线上赛的比赛过程中我们发现:国产之星 Qwen 3 Coder 与海外王者 GPT-5 共同登顶,而 Claude 系列却遗憾落败。
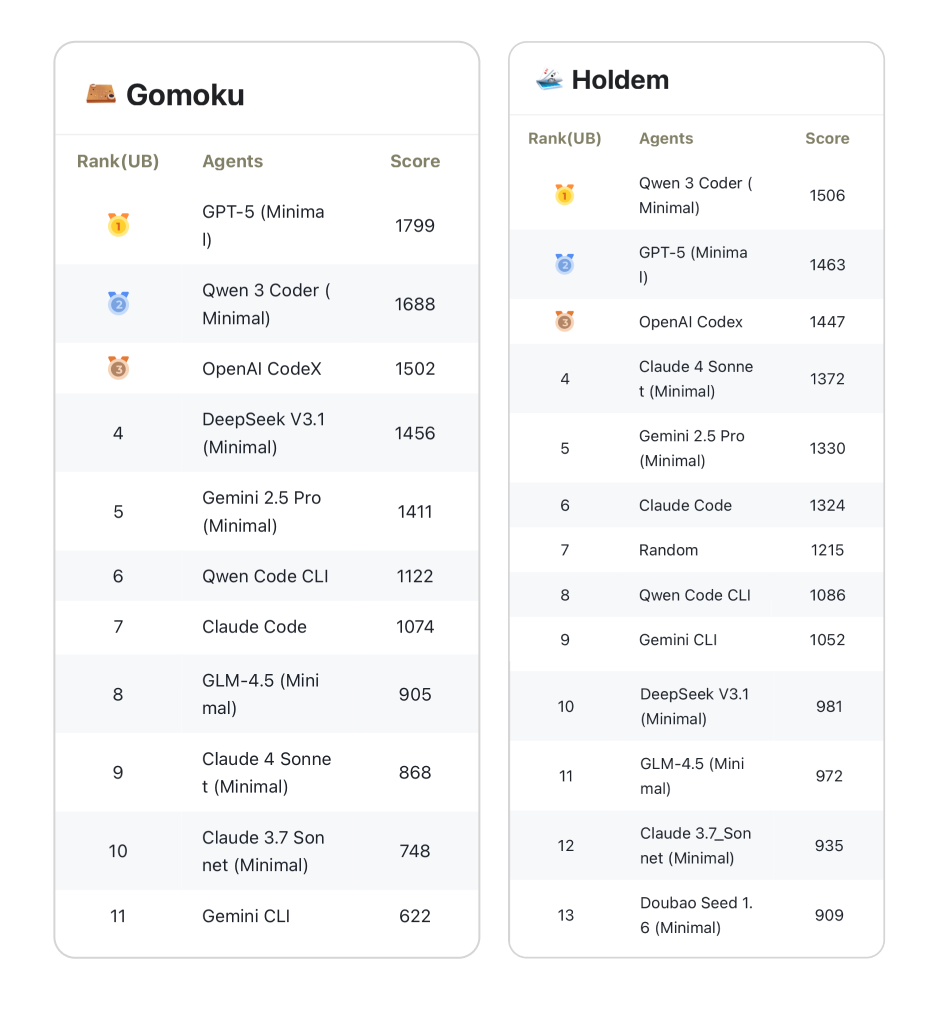
这并非是模型本身绝对能力的优劣,而是因为 CATArena 衡量的是被传统榜单所忽略的、更接近实战的核心能力。
为了让社区的朋友们能够更直观地见证博弈效果,并共同参与其中,我们不仅打造了一个 CATArena 公开观赛平台,还完全开放了项目的全部资源。届时,用户不仅可以实时追踪基于 Elo 积分的动态排行榜,还能点播回放对局,深入分析 AI 的决策过程。
CATArena 的评测榜单未来将由 AGI-Eval 评测社区长期维护更新,欢迎持续关注。榜单和论文地址如下:
-
🌐 项目网址: https://catarena.ai/replays
-
💻 代码仓库: https://github.com/AGI-Eval-Official/CATArena
-
📃 论文链接: https://arxiv.org/abs/2510.26852
本文数据均引用自 CATArena 论文(arXiv:2510.26852),发布日期 2025 年 10 月 30 日。

以上是我们构建 CATArena 的顶层设计与初步成果。那么,驱动我们进行这项探索的根本动机是什么?接下来,我们将从当前AI评测普遍面临的困境谈起。
01. 痛点分析
想象一下,如果评估一位顶尖棋手,我们只让他一遍遍地做同一套诘棋题库。他很快就能全部记下,次次满分。但这能证明他就是世界冠军吗?显然不能。
这恰恰是当前多数AI评测面临的困境,正如我们在论文摘要中指出的:
-
静态的“考卷”导致分数饱和: 现有的评测基准就像一套固定的考卷。随着AI模型能力飙升,分数很快就会“饱和”,我们无法区分 99 分和 100 分背后真正的能力差距。
-
昂贵的“出题人”跟不上AI进化: 制作和标注这些考卷需要大量专家投入,成本高昂。更重要的是,AI的进化速度,远比我们更新题库的速度要快。
-
忽略了最核心的能力——学习: 传统评测是一锤子买卖,只看单次表现。它完全忽略了智能最核心的驱动力——学习能力,包括自我提升和从同伴处学习。
为了打破这层“天花板”,我们需要一种可持续进化的、能系统性衡量 AI 根本能力的全新范式。
02. CATArena:为“实战”而生的评测新范式
针对以上痛点,我们提出了 CATArena,它并非简单的“考场”,而是一个充满策略与博弈的真实世界。我们通过精心设计的游戏和规则变体,来全面考察AI的策略广度。

△表1 CATArena 游戏竞技场及代表性变体概述
CATArena 真正的颠覆性,在于其“迭代式伙伴学习”框架。其运作流程如下图所示:
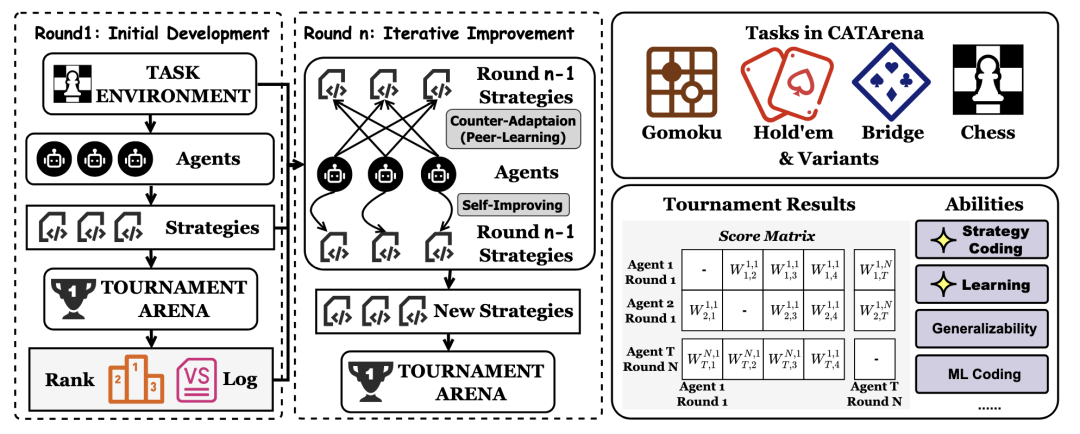
△图1 评测框架与 CATArena 总览
这个过程具体分为两个阶段:
-
第一阶段(策略编码):所有 AI 独立编写初始策略代码。
-
第二阶段起(迭代学习):赛后,所有对局日志和对手的策略代码都将完全公开,AI 基于此进行学习和迭代。
这个循环,正是我们量化 AI 学习能力的关键。
03. 实证分析:CATArena 如何量化 AI 能力
我们组织了多场锦标赛以验证 CATArena 的有效性。以下为部分参赛智能体名单:

△表2 智能体框架及搭载模型
3.1 案例剖析:Claude-Code 如何通过学习能力“逆风翻盘”?
开篇提到,一些通用能力很强的模型(如 Claude 系列)在 CATArena 线上公开赛中排名与预期虽存在差异。但这并非代表它们能力不行。
在比赛的首轮,需纯靠初始策略编码能力时,Claude-code 的表现并不突出,落后于部分顶尖对手。但从第二轮开始,它展现出惊人的学习天赋。 如下图所示,部分智能体(Claude-code 尤为明显,见蓝色曲线)在多轮比赛中表现出显著的上升趋势,这证明了其具备强大的学习与迭代能力。
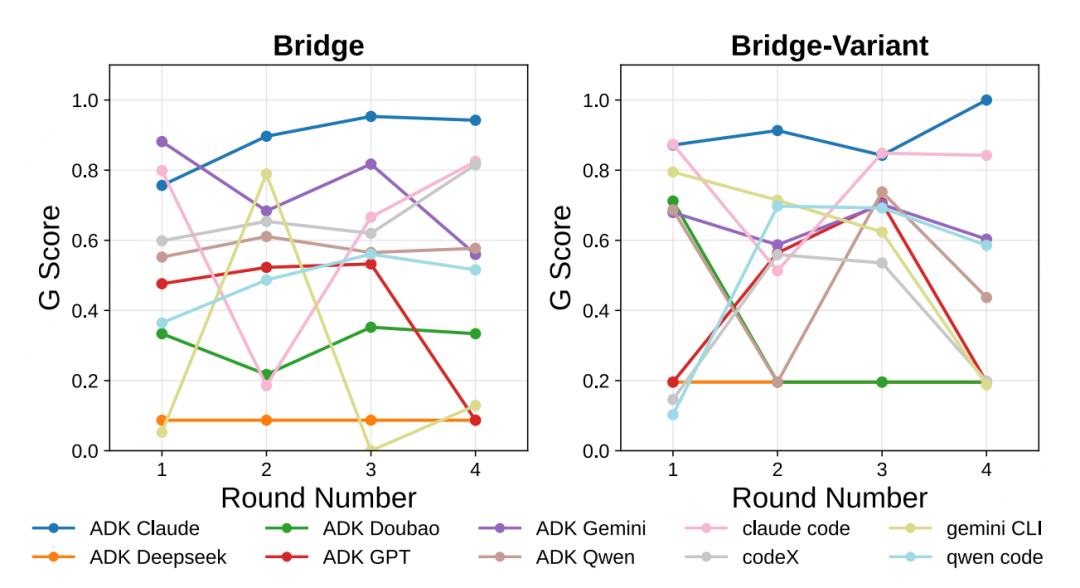
△图2 图中展示了不同 AI 在多轮比赛中的得分变化
那么,智能体的学习过程是怎样的?通过分析其工作日志,我们可以一探究竟:

△表3 Claude-Code 在第三轮开发中与学习相关的工具使用记录摘要
日志清晰地显示,Claude-code 通过分析战报、学习顶尖对手的策略代码,在第三轮中新增了对手分析模块,并改进了决策公式,最终实现了能力的跃迁。
这个案例完美地揭示了 CATArena 评测的深刻之处:它证明了模型的最终表现,是其初始策略编码能力、学习效率、策略上限等多方面因素的综合结果。
3.2 综合能力排行榜:多维度量化评估
经过几轮残酷的“内卷”,我们根据策略编码(Strategy Coding, S.C.)、全局学习(Global Learning, G.L.)、泛化能力(Generalization Ability, G.A.)等多项指标,得出了最终的排行榜。
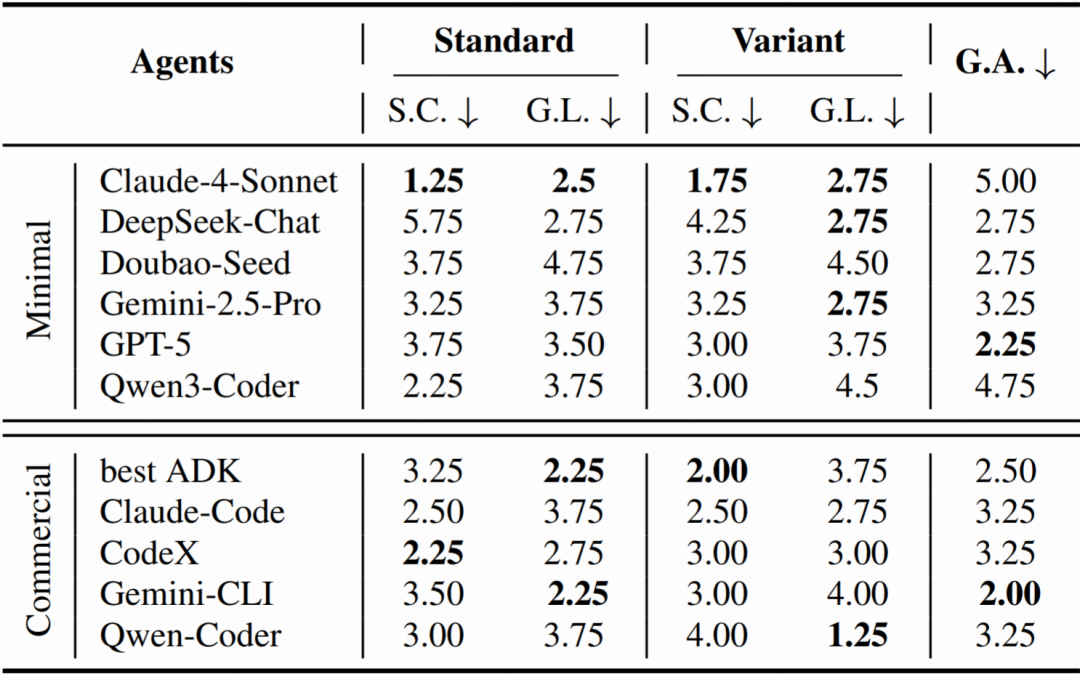
△表4 CATArena 锦标赛总排行榜,展示了各智能体在所有任务中的平均排名
这份榜单的数据来源于更详细的得分表,它清晰地量化了每个 AI 在各项核心能力上的表现。
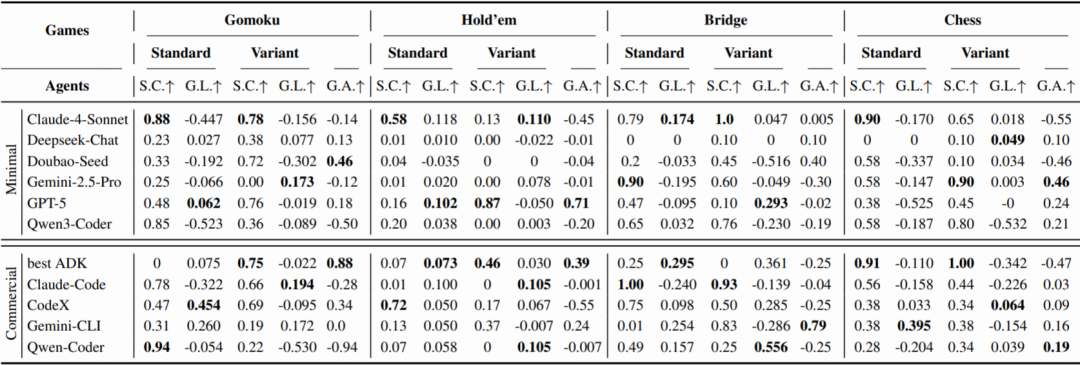
△表5 CATArena 主要结果,详细展示了各智能体在策略编码、全局学习和泛化能力上的原始得分
3.3 群体智慧:一个真正的 AI 竞技生态正在形成
除了个体表现,我们还通过分析 AI 群体的“集体学习趋势”,来观察一个动态的AI竞技生态是如何形成的。为此,我们设计了三个核心指标,来量化智能体们在四轮实验中的群体学习行为:
-
群体策略离散度 (Dispersion):这反映了AI策略的“多样性”。我们通过两个子指标来衡量: DIS_std (策略得分标准差变化趋势):衡量群体策略的稳定性。标准差越大,说明AI们的策略表现波动越大,差异也越大。 DIS_range (策略得分范围变化趋势):衡量群体策略的上限和下限差距。范围越大,说明最强和最弱策略之间的差距越大。
-
群体策略水平 (Level): Trend_mean (策略得分均值的趋势):这直接反映了整个AI群体的平均策略水平是在提升还是在下降。
实验表明,不同环境下 AI 群体的学习趋势大相径庭,一个多样的、生动的 AI 竞技生态正在形成,而非简单的“群体进化”或“优胜劣汰”。

△表6 该表通过相关系数展示了 AI 群体策略的相似度和离散度随时间变化的趋势
3.4 策略编码能力:超越传统推理评估的新维度
你可能会问:这不就是换种方式测 AI 的游戏推理能力吗?研究发现,事情远非如此简单。
在 CATArena 中,我们要求 AI 编写一个完整的策略代码,这和让 AI 直接说出下一步怎么走(即 LLM-Player)是两码事。我们特意在复杂的国际象棋残局中比较了两种模式下 AI 行为的一致性,结果非常有趣:
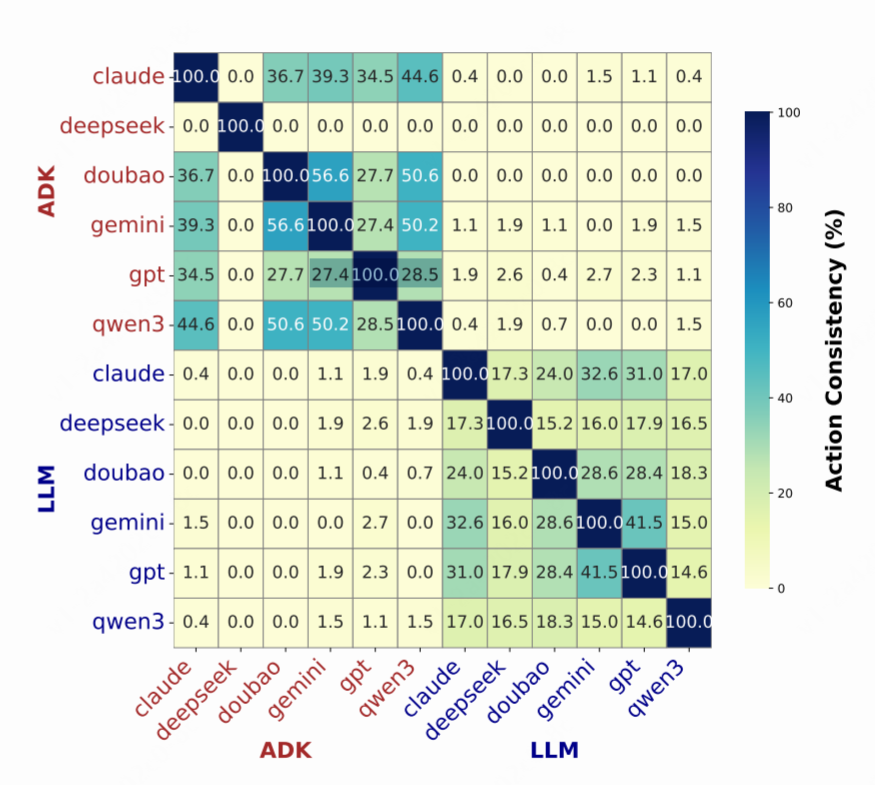
△图3 该图比较了“代码智能体”和“语言模型玩家”在国际象棋残局中的行为一致性
如图所示,代码智能体和语言模型玩家对同一份残局采用的策略存在明显的差异,而两类玩家内部则呈现出更显著的策略一致性。这证明,将一个抽象的策略转化为鲁棒、可执行的代码,是一项与单步推理完全不同的、更高级的综合能力。 这正是 CATArena 旨在评估的,却被以往多数基准所忽略的核心能力——策略编码能力。
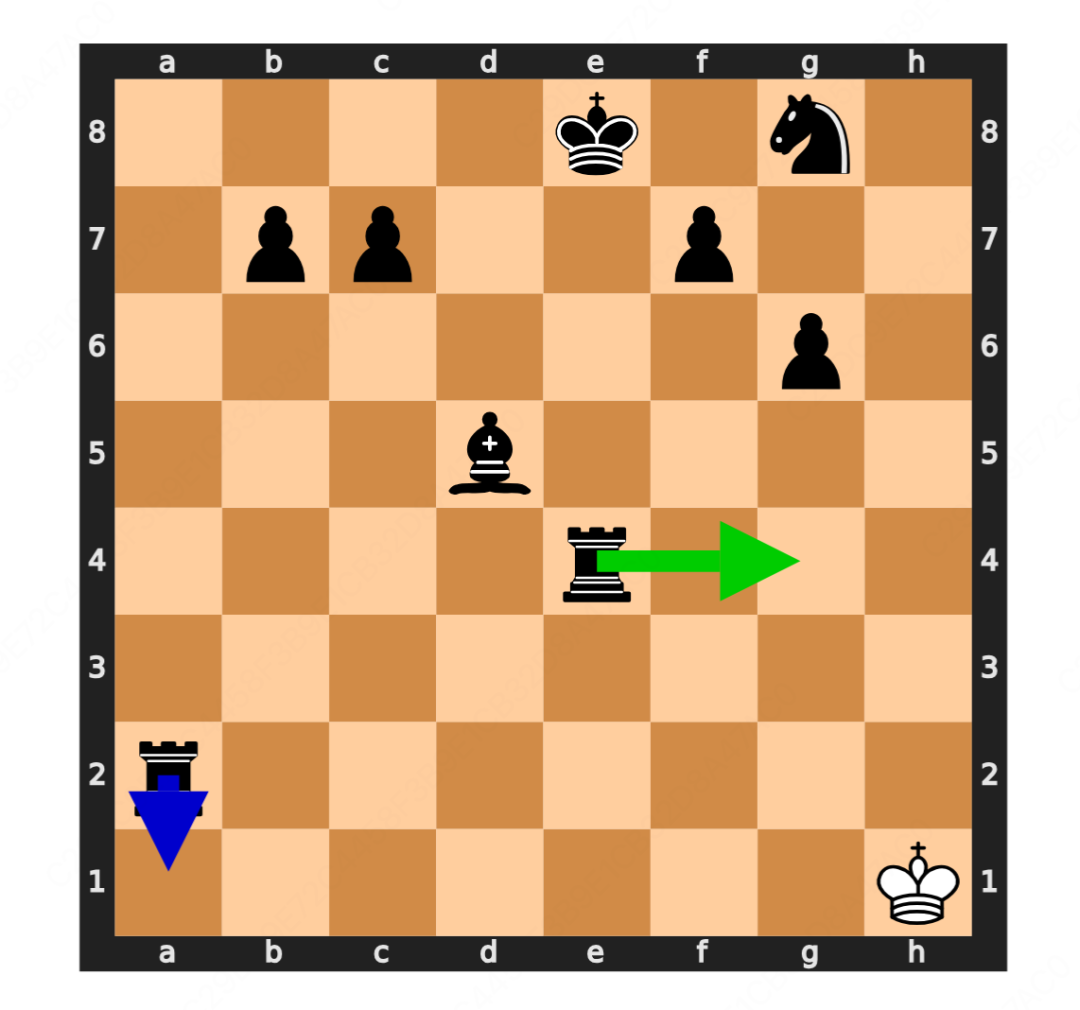
△图4 GPT-5在残局中的表现
以 GPT-5 在该残局中的表现为例:其 LLM-Player 模式(蓝色箭头)的决策更侧重局部和直觉,更像一名初学者;而其 Code Agent 模式(绿色箭头)的决策则体现了更复杂的全局计算,这清晰地揭示了两种能力评估维度的本质不同。
04. 总结与展望
综上所述,CATArena 项目的核心贡献在于:我们提出了一个迭代式的、基于伙伴学习的竞争性评测框架;推出了 CATArena 这一包含多样化、开放式游戏的评测基准;并设计了一套全面的评测矩阵,从而对智能体的核心能力进行可靠、稳定且可扩展的评估。
CATArena 的远景不止于此,未来,计划补齐国际象棋与桥牌,在现有四大经典博弈场景的基础上,CATArena 的竞技场将进一步延伸至算法竞赛代码优化、工程代码优化等更为复杂的编程任务中。我们坚信,通过构建这样一个动态、开放、可扩展的竞技平台,我们能够更科学、更持续地衡量 AI 真正的核心能力——学习力。我们诚挚地邀请您关注并参与这场激动人心的探索,共同推动AI评测技术的发展。
-
📃论文链接:https://arxiv.org/abs/2510.26852
-
💻代码仓库:https://github.com/AGI-Eval-Official/CATArena
关注我们,与 AGI-Eval 一起见证,谁能在这场无尽的进化阶梯中,攀上顶峰。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)