n8n+Ollama+Qwen3构建企业级RAG检索系统-知识库
本文介绍了如何利用n8n、Ollama和Qwen3构建企业级RAG检索系统。主要内容包括:Qwen3-Embedding模型的介绍与本地部署方法,Ollama的安装配置及模型下载路径修改,n8n的安装过程及常见问题解决方案,以及最终通过n8n创建RAG工作流的步骤。文章详细说明了从环境搭建到系统集成的完整流程,为构建企业级知识库检索系统提供了实用指南,适合AI大模型应用开发人员参考。
n8n+Ollama+Qwen3构建企业级RAG检索系统-知识库
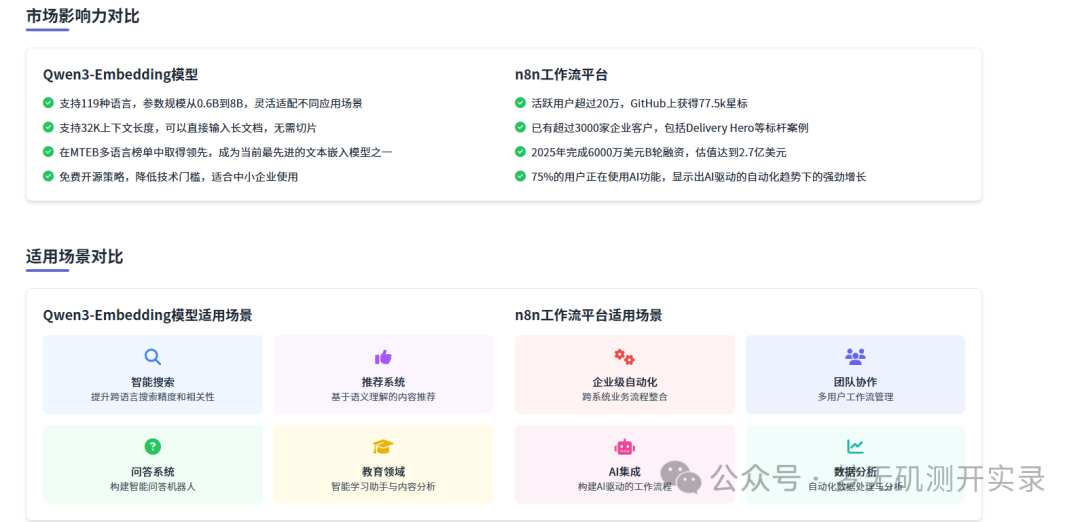
1、Qwen3-Embedding介绍

最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2、Ollama安装下载
Ollama官方地址
我的Ollama安装路径:E:\S_Software\Ollama
① 手动创建Ollama安装目录
我手动创建的文件夹目录为:E:\S_Software\Ollama
② 运行安装命令
创建好之后,把Ollama的安装包exe放在这个目录下,接着再到这个目录下运行cmd命令:
OllamaSetup.exe /DIR=E:\S_Software\Ollama
DIR后面的路径是之前手动创建的文件夹路径。
输入命令后直接回车,Ollama就会进入安装程序,这个时候可以看到安装的路径变成了我们刚刚创建的文件夹。
③ 安装完毕
安装好了之后,在控制台输入ollama,可以正常显示ollama版本则表示安装成功。

2.1、修改模型下载目录
① 创建models目录&修改默认模型下载目录
在之前的安装目录下创建一个models文件夹:E:\S_Software\Ollama\models。
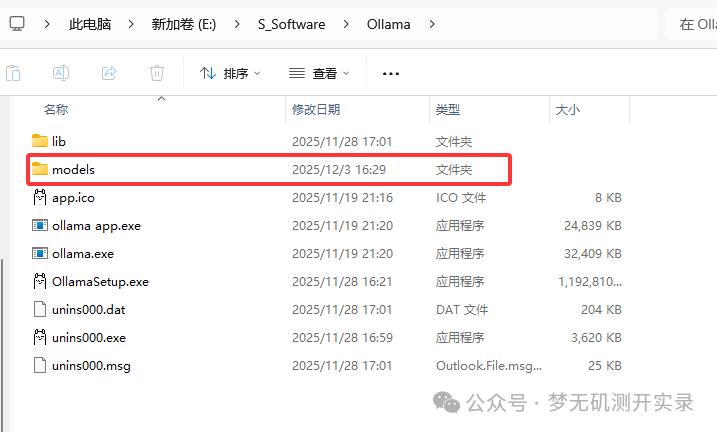
打开ollama软件,点击settings,找到Model location,把路径修改成上面创建好的这个。

② 模型转移
在命令行输入ollama list,如果发现有模型,则进行这一步操作。

先退出ollama,接着进入C盘-->用户-->你自己的电脑名称-->.ollama-->剪切整个models下的内容到刚刚上面新建的存储目录下,之后删掉C盘的这个models文件夹。
如果之前修改过存储目录,那就自己找到再去复制。
这个时候就是正常的了。

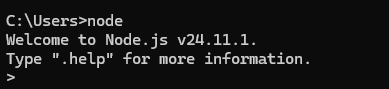
2.2、安装nodejs
如果想用nodejs安装n8n,可以安装nodejs,推荐安装v22以上的版本,这里我安装的是v24.11.1。
一路默认安装就行,有其他想法的自行AI搜索。 使用如下命令下载即可:
npm install -g n8n # -g表示全局安装,可在任意目录运行,整个过程大概需要5-10分钟
- Windows报错
gyp ERR! find VS:需安装Visual Studio的C++桌面开发工具(勾选Windows SDK)。 - Linux/macOS报错
distutils缺失:安装Python 3.x并确保distutils可用。
解决gyp ERR! find VS报错
1、报错内容
npm error gyp ERR! stack Error: Could not find any Visual Studio installation to use
原因是:n8n 依赖的 sqlite3 模块需要本地编译,但你的系统缺少 Visual Studio 的 C++ 编译工具链。而Visual Studio几乎是必备工具,因为支持:
- C++ 开发工具链
- .NET 框架
- Windows SDK 和系统库
2、解决方案
下载对应的工具
下载2022版本,最新版2026的VS在npm没兼容无法识别
-
① 选择 “C++ 桌面开发”,勾选windows sdk(我的是win11,勾选的是win11的sdk)注意要是2022
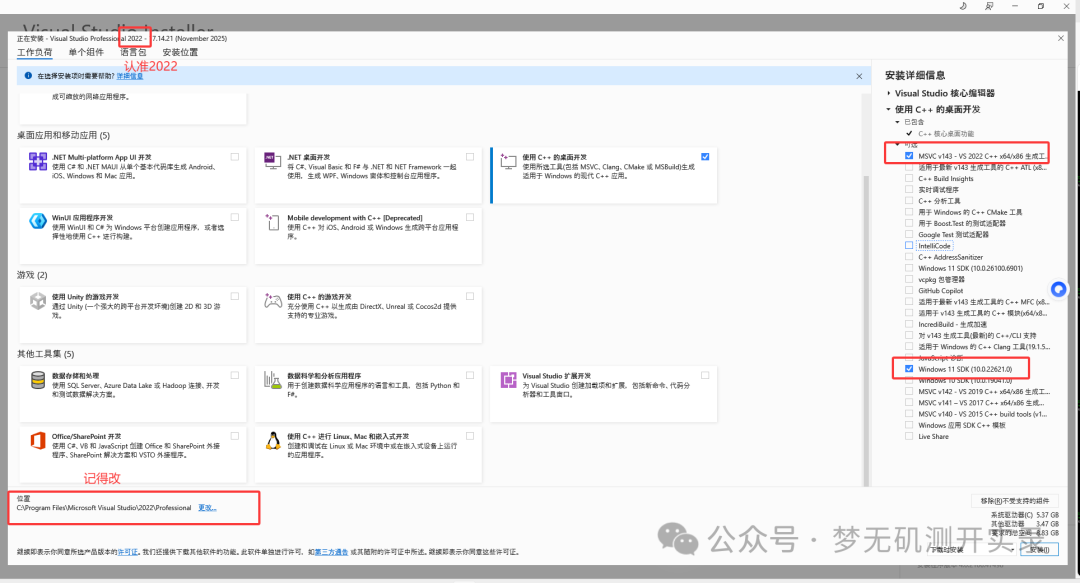
-
② 自定义安装目录
安装需要十几个G的空间,建议更改盘符,另外一个windows11的sdk也勾上,win10那个也勾上,我在这踩了好多坑,我也不知道为什么我win11的电脑装win11还是报错找不到windows sdk,建议还是用docker安装,一个命令就结束。

这是后面我补充安装好的配置。
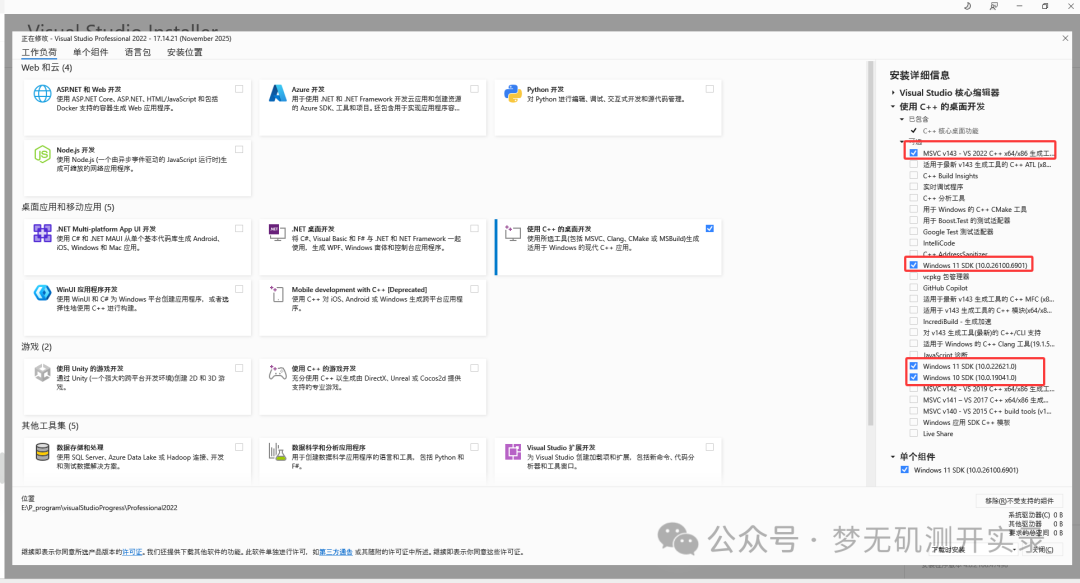
等待安装完毕即可,安装完成之后重启电脑。
3、重新安装n8n
# 1、卸载全局安装的 n8n 包
npm uninstall -g n8n
# 2、强制清理 npm 缓存文件
npm cache clean --force
# 3、验证缓存完整性并优化空间
npm cache verify
# 4、全局安装 n8n 包
npm install -g n8n
# 5、查看全局安装的 n8n 版本和依赖
npm list -g n8n
4、启动n8n
配置好环境变量后,在命令行中输入n8n即可启动。
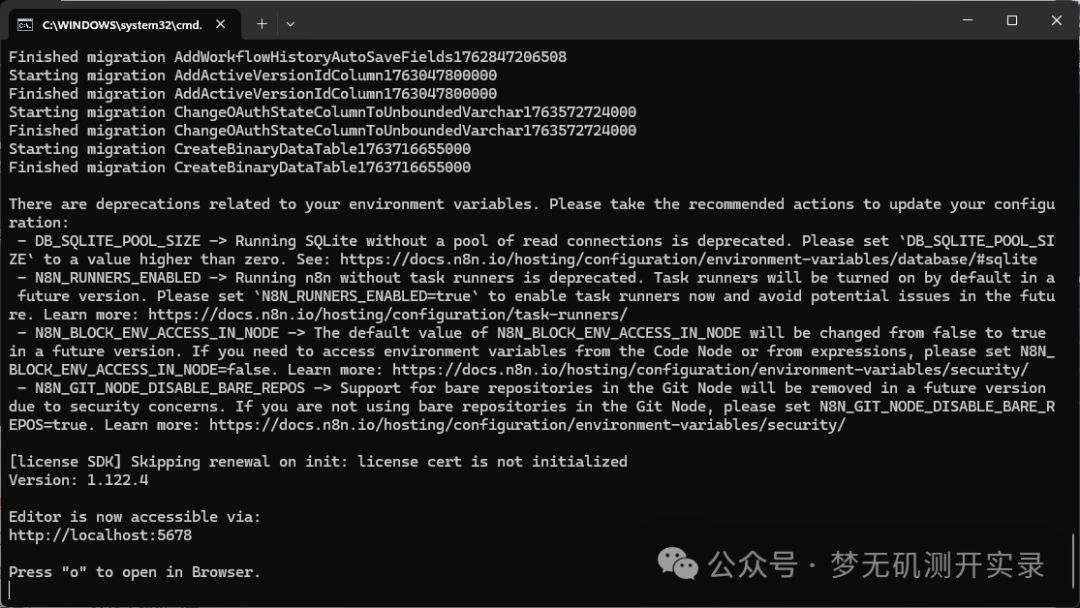
3、Qwen3-Embedding本地模型下载及配置
① 模型下载
方式一:在HuggingFace里面下载下载量化之后的GGUF格式的模型
如果使用这种方法下载的模型,需要使用ollama再创建嵌入模型,推荐使用方式二。
Ollama创建嵌入模型
- 创建最简Modefile
echo FROM 上一步你下载的模型路径 > Modelfile
# 示列
echo FROM E:\Ollama\Qwen3-Embedding-4B-Q4_K_M.gguf > Modelfile
-
创建模型
ollama create qwen3_embedding -f Modelfile
方式二:使用Ollama命令直接下载模型
ollama run hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M
② 测试嵌入模型
**方式一的测试方法:**命令行输入(注意windows需要双引号裹住json,所以需要转义)
curl http://localhost:11434/api/embed -d "{\"model\":\"qwen3_embedding\",\"input\":\"Hello\"}"
model的名称要看ollama list输出的name,需要一致,方式一只做展示,推荐方式二。
**方式二的测试方法:**在命令行中输入:
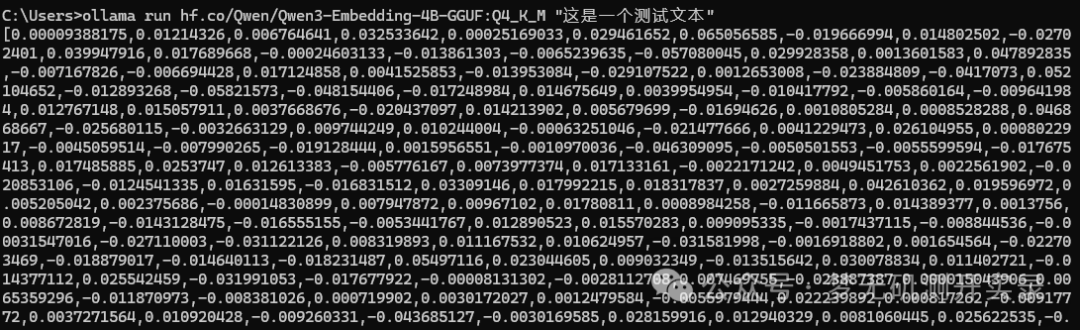
ollama run hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M "这是一个测试文本"
效果就是会输出一堆向量化的内容。
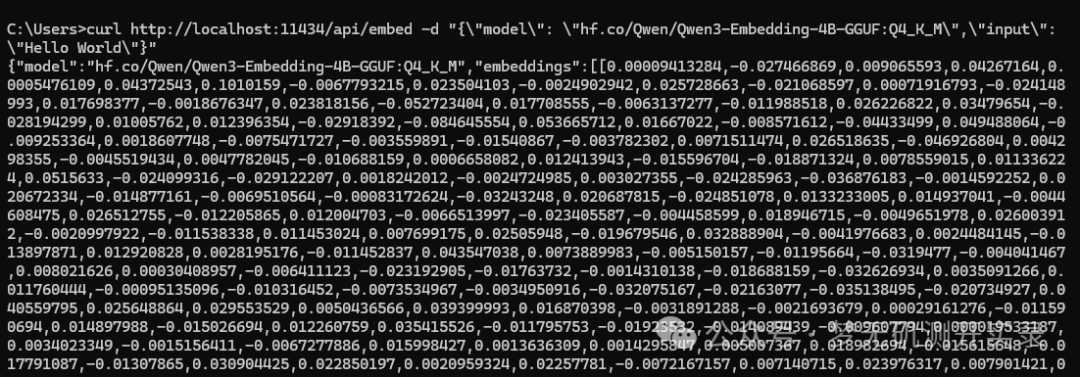
方式二用curl命令测试:
curl http://localhost:11434/api/embed -d "{\"model\": \"hf.co/Qwen/Qwen3-Embedding-4B-GGUF:Q4_K_M\",\"input\": \"Hello World\"}"
效果如下。
4、n8n创建RAG工作流
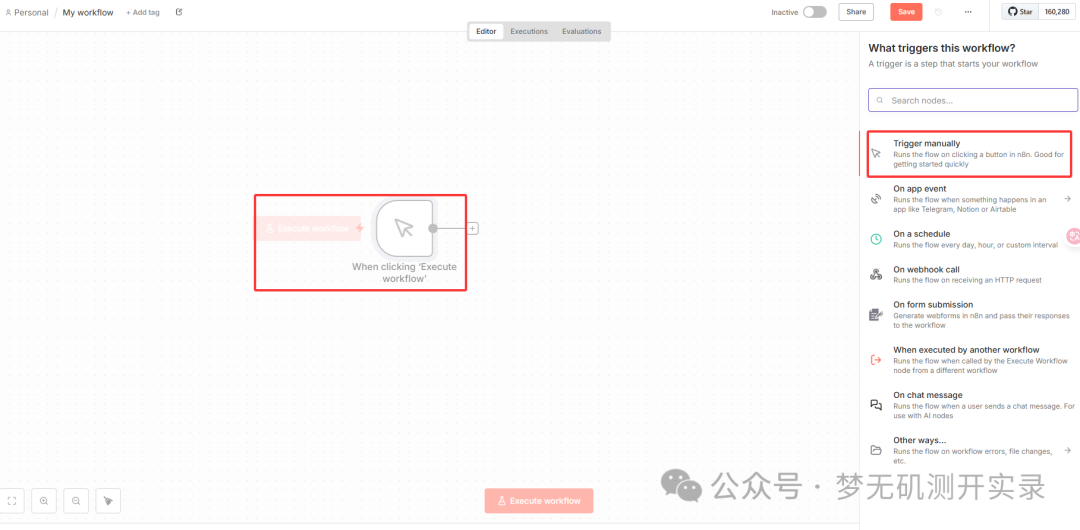
1、选择触发方式
这里暂时选择的是Trigger manually。
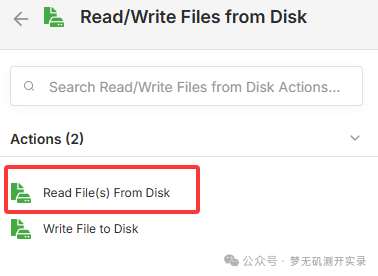
2、添加步骤,搜索file
找到Read/Write Files from Disk,选择Read即可(因为是本地知识库,所以选的这个,还有其他方式)。

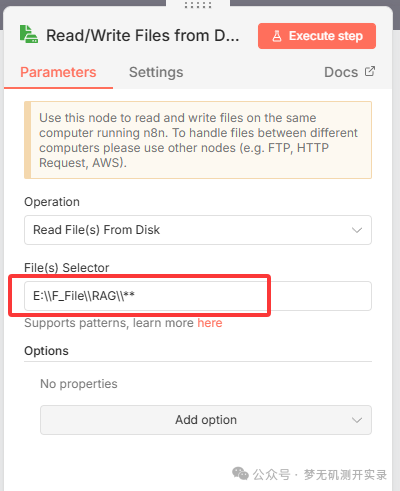
填入的E:\\F_File\\RAG\\**,表示读取RAG文件夹下的所有文件。
点击测试,提示成功则表示通过了。


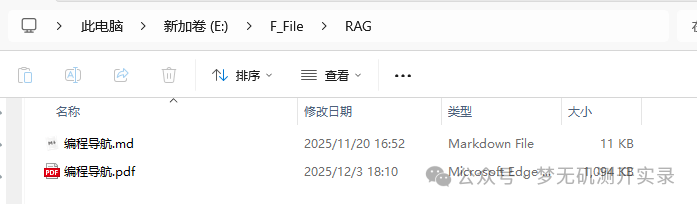
也可以直接在这一个步骤里面运行,在右侧可以看到输出,这里可以看到直接输出了我在这个文件夹下面的两个文件,一个md格式,一个pdf格式。

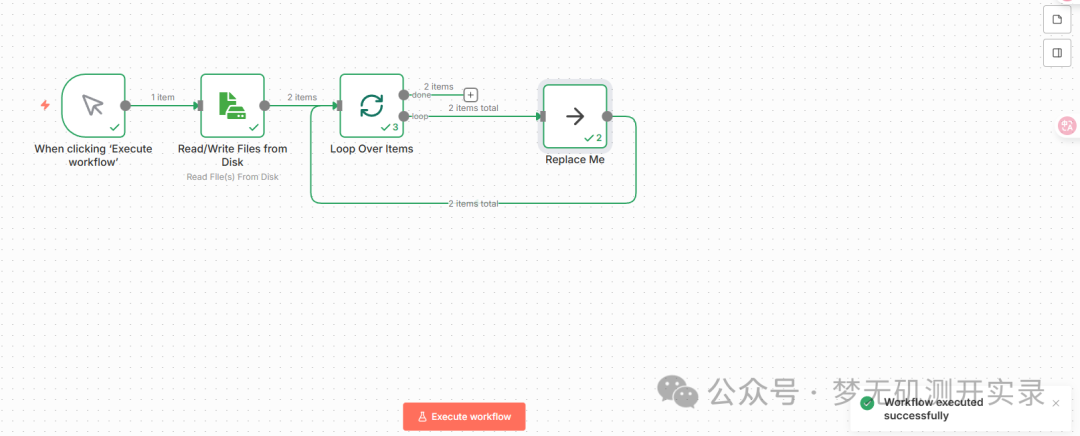
3、添加循环组件Loop over Items
循环组件loop,这个步骤是为了一直读取文件夹下的文件,循环读取。

Batch Size表示输入每次调用要返回的项目数。

执行当前整个业务流。
4、加入向量数据库
-
在loop的节点中加入
Vector,这里我们作为学习演示,选择Simple Vector Store即可。
-
选择第二个
Add documents from vector store,将文档转换为向量。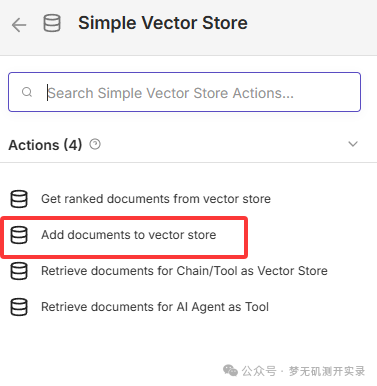
-
Memory key这里直接使用的是默认的,也可以自己进行修改添加,后续将会使用到。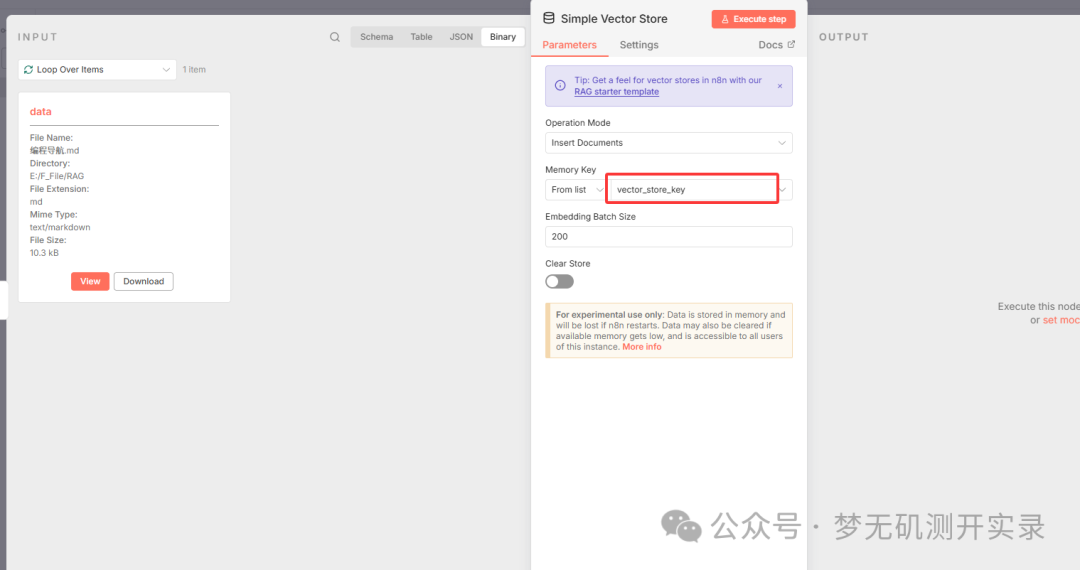
-
发现有红色感叹号,是因为还需要配置两个组件,一个是Embedding模型配置,一个是Document。

5、配置文件解析模型&语义分割
1、Embedding模型配置
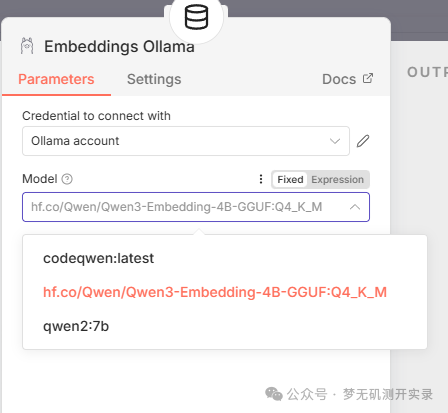
我们选择的是本地Ollama模型部署。

配置Ollama默认的是localhost,如果localhost提示连接不上,就修改成127.0.0.1。

选择对应的Embedding模型。
2、Document对文件进行分块
选择Default Data Loader。
-
Type of Data 可以选择JSON或者Binary(二进制),这里我们选择二进制。
-
Mode选择默认的
Load All Input Data。 -
Data Format选择自己的文件类型,或者选择自动解析。
-
Text Splitting选择自定义
Custom。
这个时候工作流如下图所示,需要对文本分割进行处理了。
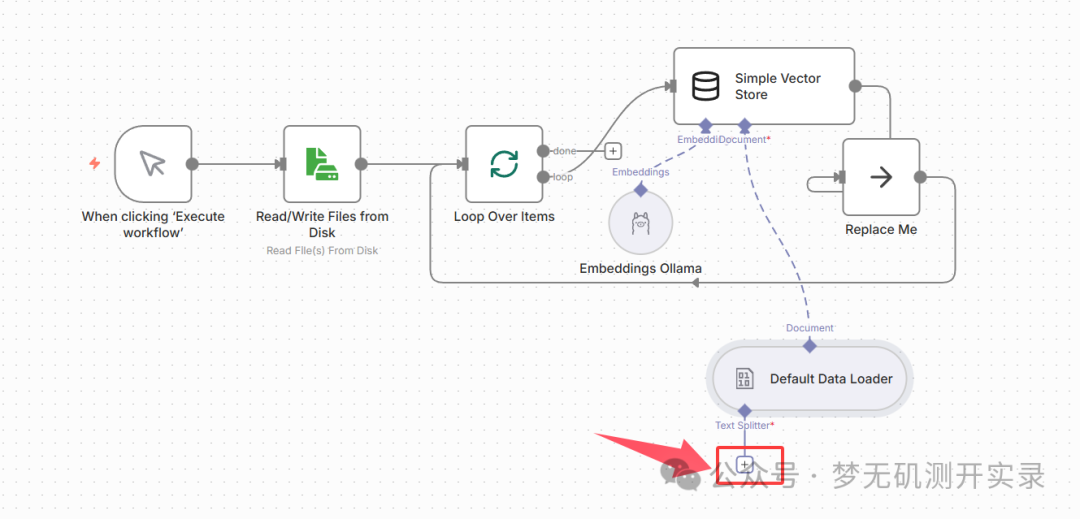
3、选择语义分割


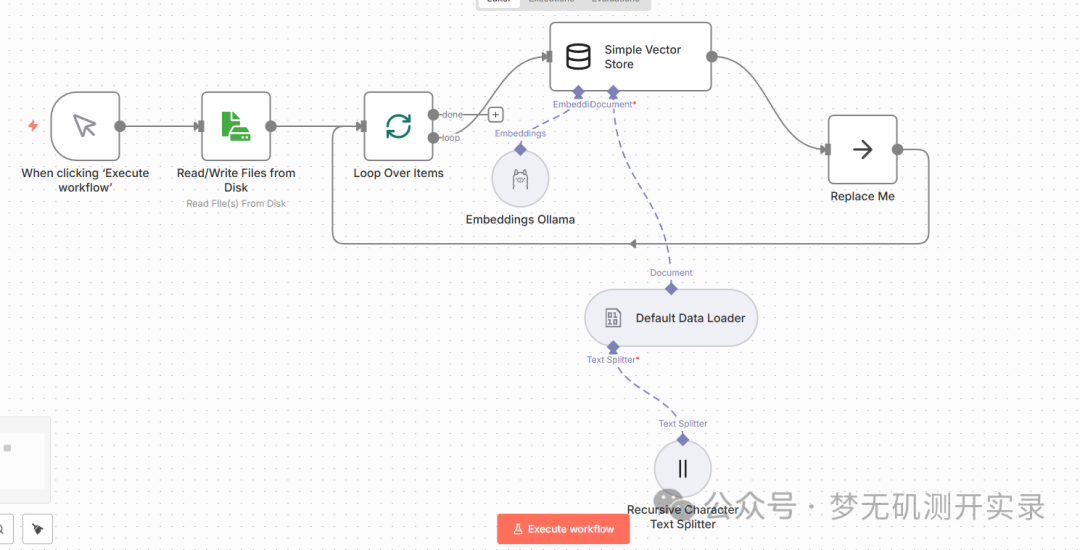
6、创建检索知识库工作流
当前完整工作流如下图所示。
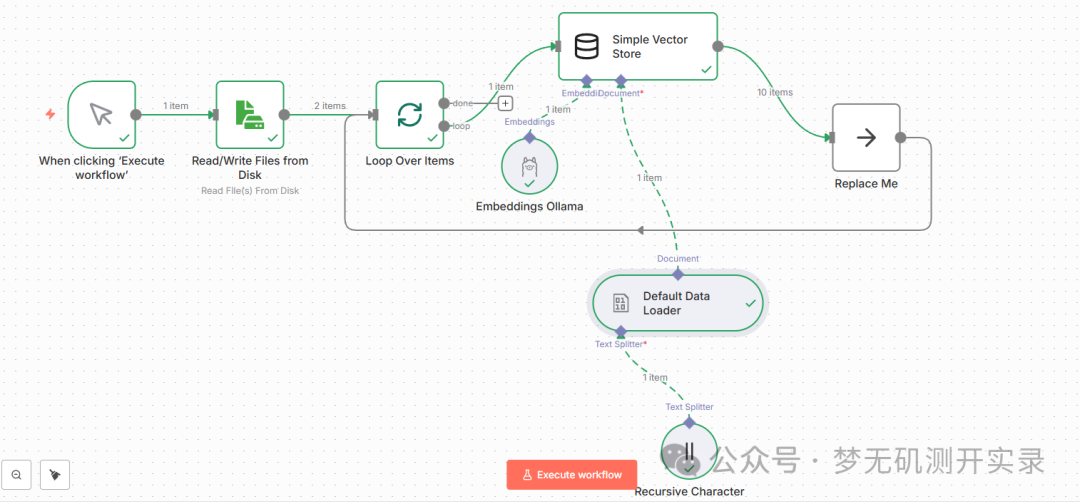
1、当前工作流运行成功显示
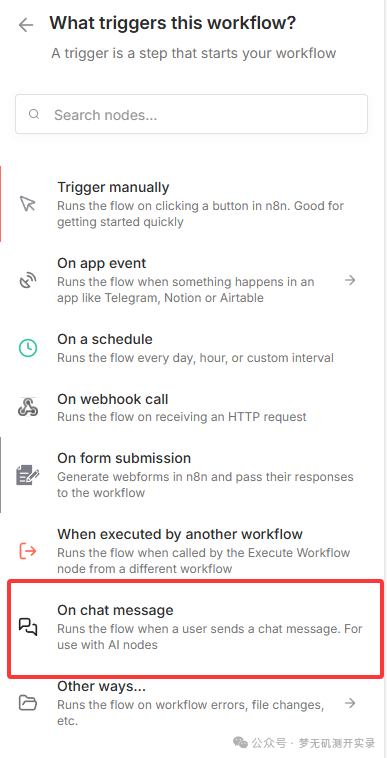
2、创建一个新的工作流
选择On chat message。
3、创建一个AI Agent节点
AI Agent下方的Chat Mode接入一个对话大模型,这里我选择的是Deepseek,需要有API Key,使用硅基流动或者Deepseek官方API生成ApiKey填入即可。 第一次建立需要点击Create new credential。
接着在AI Agent下方的Tool接入Answer questions with vector store(使用向量存储回答问题),在描述里面填入:当前工具是用来检索向量数据的。

到这一步创建完,工作流如图所示。

4、接入向量数据库、向量模型、对话模型
接上一步骤,在Answer questions with vector store(使用向量存储回答问题)下面的Vector Store接入向量数据库:Simple Vector Store。
注意:和创建向量数据库那个时候的key要匹配一致。
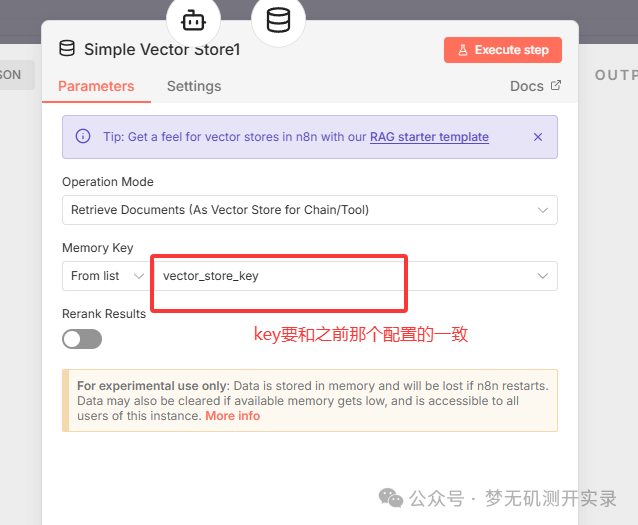
在Model节点中继续接入Deepseek Chat model。

最后一步,在Simple Vector Store下面的Embedding模型中接入我们的本地向量模型,依旧和5-1步骤一样,最终工作流如下所示:
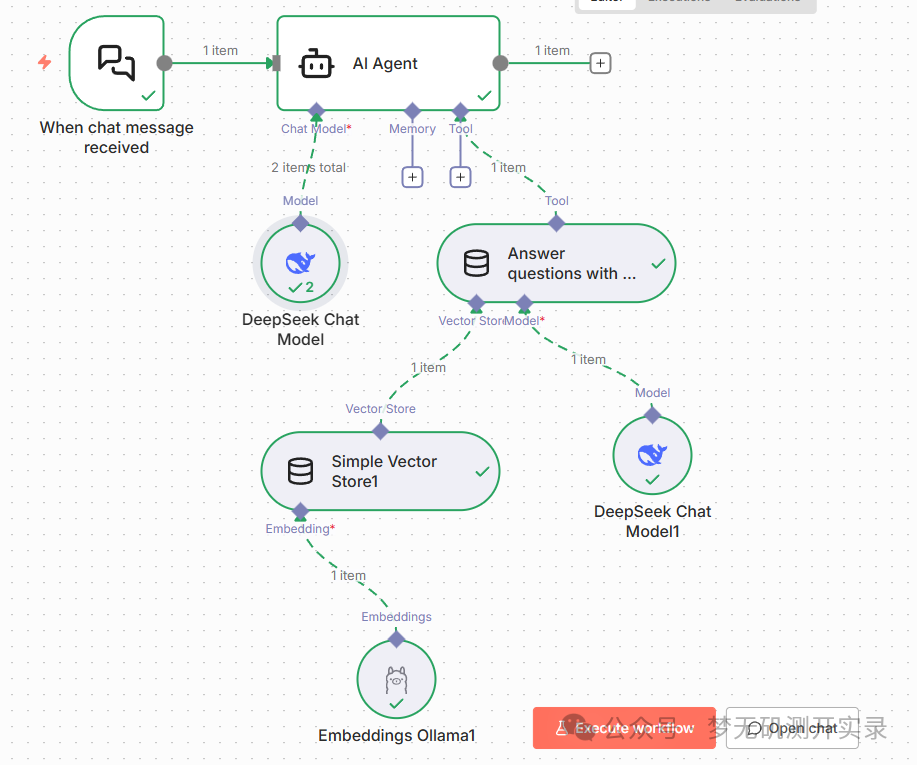
7、测试知识库的准确性
点击open chat进行对话,输入问题:找一下ios禁止系统更新的网址。 发现可以很精准的回答问题,并且没有任何的添油加醋,完全就是我笔记里面的内容,只是进行了一个简单的排版。
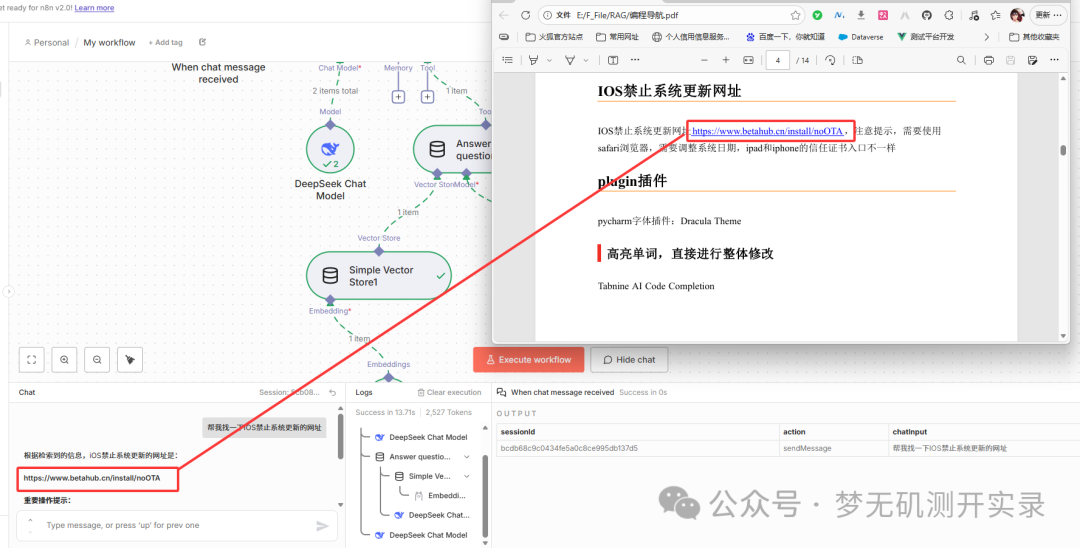
而在deepseek的官方对话里面问的是找不到我笔记里面的这个网址的。

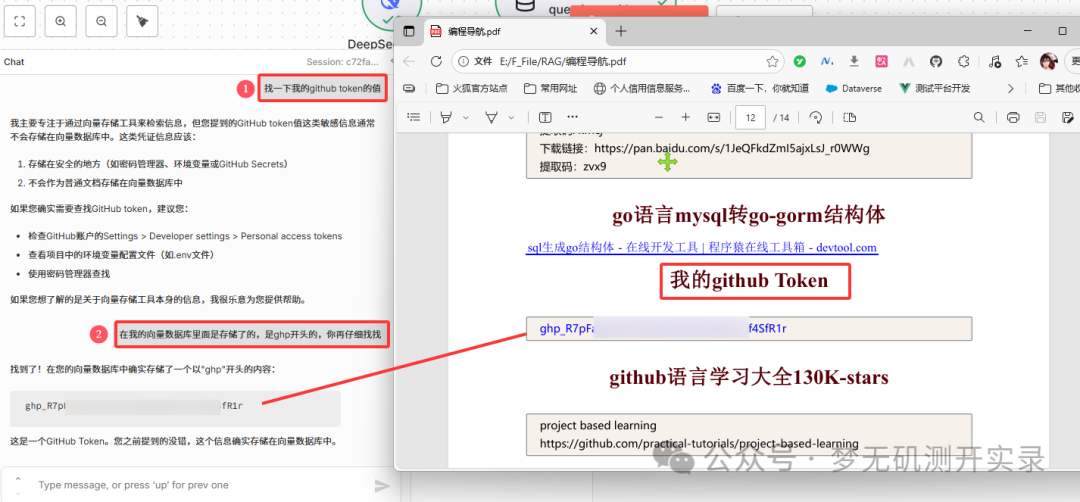
使用另外一个问题,发现分段式的内容不能非常精准的找到,但进一步进行提示后,还是可以准确的回答。 这就是后续可以优化的点。
8、知识点补充 - Ollama 常用命令大全
1、下载/运行模型:ollama run <模型名字>
2、清除模型上下文:/clear
3、退出对话 / 关闭模型:/bye
4、查看模型运行速度&token数细节:
ollama run <模型名字> --verbose
5、查看你有什么模型:ollama list
6、删除模型:ollama rm <模型名字>
7、查看模型的详细信息:ollama show <模型名字>
8、启动Ollama服务器:ollama serve
9、创建模型文件(用于自定义模型):
ollama create <自定义的模型名字> -f Modelfile
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献121条内容
已为社区贡献121条内容

所有评论(0)