Edge Feature Enhancement for Fine-Grained Segmentation of Remote Sensing Images
现有的遥感分割数据集主要集中在土地利用、城市建筑等领域,专门针对矿区的细粒度标注数据集非常匮乏。:现有矿区数据集(如 RSMI)的边缘标注通常比较粗糙,无法满足细粒度(Fine-grained)像素级分类的任务需求。:矿区地形复杂且具有动态变化,准确标注需要大量的地质专业知识和实地考察验证。
一、研究背景
1. 数据集层面的缺陷(Data Level)
-
高质数据稀缺与标注粗糙:现有的遥感分割数据集主要集中在土地利用、城市建筑等领域,专门针对矿区的细粒度标注数据集非常匮乏 。
-
标注精度不足:现有矿区数据集(如 RSMI)的边缘标注通常比较粗糙,无法满足细粒度(Fine-grained)像素级分类的任务需求 。
-
标注成本极高:矿区地形复杂且具有动态变化,准确标注需要大量的地质专业知识和实地考察验证 。
2. 矿区图像本身的复杂特性(Object Level)
-
边缘特征模糊且不规则:矿区边界往往呈现“渐进式过渡”的状态,受到复杂自然环境的干扰(如噪声、动态变化等),导致目标边界线难以精确界定 。
-
多尺度与几何复杂性:矿区在遥感图像中跨越的尺度范围极大(2% 到 100% 占比不等),且形状极其不规则,甚至存在内部空洞(Internal voids),这极大地增加了模型捕捉边界特征的难度 。
-
背景干扰严重:露天矿区常位于山地或平原,极易与周围的植被、道路、建筑、废石堆等混淆
3. 分类任务的严峻挑战(Task Level)
-
“类间相似性”与“类内差异性”:
-
类内差异大:同一种矿石(如砂岩 Sandstone)受光照、颜色和形状影响,其子类表现迥异 。
-
类间相似度高:不同类型的矿石在遥感光谱特征上可能非常接近 。
-
-
边缘像素极易误判:由于上述的类间模糊性和类内不一致性,矿区边缘附近的像素非常容易发生错分类 。
二、主要贡献
1. 构建了细粒度矿区遥感数据集 (Fine-RSMI)
-
填补领域空白:针对现有遥感数据集边缘标注粗糙、矿区专用数据稀缺的问题,建立了专门用于细粒度分割的 Fine-RSMI 基准数据集 。
-
规模与质量:该数据集包含 10,225 张 精细标注的卫星图像 。
-
挑战性特征:数据集涵盖了 3 大类、22 个子类 的矿物 ,具有显著的多尺度变化(目标占比从 2% 到 100%)、边缘极度不规则以及存在内部空洞等复杂特性 。
2. 提出了边缘特征增强框架 (EDFEM & ESM)
为了解决不规则边缘的分割难题,论文提出了一个层次化融合的增强框架 :
-
边缘细节特征增强模块 (EDFEM):通过垂直级联多个特征融合单元,融合相邻层级的特征图,提取高阶互补信息,从而精准捕捉和细化边缘特征 。
-
边缘监督模块 (ESM):利用从 Ground Truth 生成的二值边缘图作为引导,通过强化学习的方式监督网络对边缘像素的学习,增强模型对边界的辨别能力 。
3. 实现“即插即用”的高效集成 (Plug-and-Play)
-
灵活性:这两个模块均采用即插即用的设计模式,可以无缝集成到现有的各种语义分割框架中(无论是基于 CNN 还是 Transformer 的架构) 。
-
低成本高性能:该方法在提升分割精度的同时,不增加推理阶段的计算成本(ESM 模块在推理阶段会被丢弃) ,且引入的额外参数量仅占原模型的约 3% 。
4. 取得 SOTA 性能表现
-
实验验证:在多个数据集上刷新了表现。在 Fine-RSMI 数据集上达到了 74.12% mIoU,在公共数据集 WHDLD 上达到了 78.64% mAcc 。
-
广泛适用性:实验证明,该方法在 ISPRS (Vaihingen 和 Potsdam) 等通用遥感数据集上同样能显著提升各基准模型的性能
三、方法模型
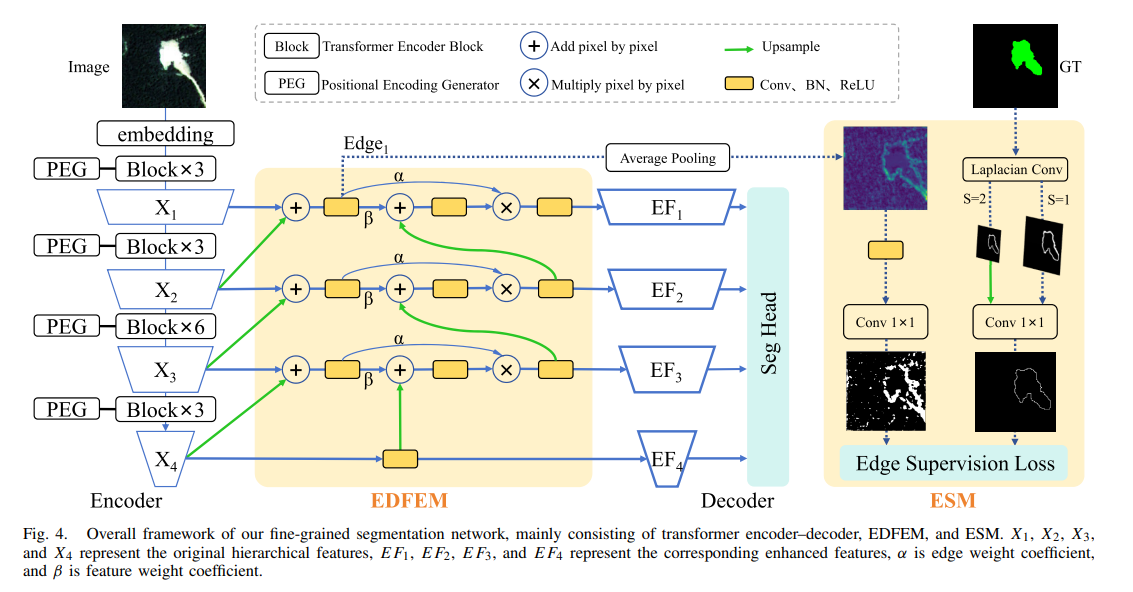
1. 模型的三大核心组成部分及作用
1. 主干网络:Twins-PCPVT 特征提取
在进入增强模块之前,模型首先需要生成基础的特征金字塔。
-
分级结构:模型采用 Twins-PCPVT 作为 Backbone 1。它包含四个下采样阶段,每个阶段输出不同分辨率的特征图(从 H/4 \times W/4 到 H/32 \times W/32),我们记为 X_1, X_2, X_3, X_4 。
-
位置编码生成器 (PEG):在每一阶段的第一个 Transformer 块之后,PEG 会动态生成条件位置编码 3。它通过对重塑后的特征图进行 2D 深度卷积(带零填充)来实现,确保了模型能够处理变长的序列输入 。
-
注意力机制:每个阶段由不同数量的 Transformer 块组成(配置为 3, 3, 6, 3) 。它结合了局部组合自注意力 (LSA) 和全局下采样注意力 (GSA),在提取全局语义的同时保留细粒度纹理
2. EDFEM:边缘细节特征增强模块
这是论文的核心创新点。它不是简单地叠加特征,而是通过垂直级联来逐层“提纯”边缘。
第一步:边缘信息提取
对于相邻的特征层 X_i 和 X_{i+1},首先统一通道数为 C。通过对两层进行逐像素相加并经过卷积处理,提取出该层的边缘细节特征 Edge_i:
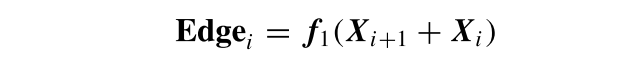
其中 f_1 代表 1 × 1 卷积、批归一化 (BN) 和 ReLU 激活的组合 。
第二步:层次化级联增强
这是 EDFEM 最精妙的地方。它利用深层特征作为底座,让边缘特征像“放大器”一样作用于其上:
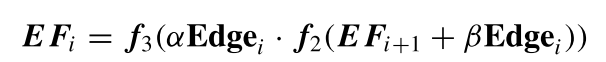
-
(特征权重):调整补充的细节信息量 。
-
(边缘权重):调整边缘特征图的强度。
-
物理意义:通过逐像素乘法,边缘特征图在目标边界区域具有更高的权重 。这增加了矿区内部平滑区域与边缘区域的差异(对比度),从而使网络更关注不规则的边界 。
3. ESM:边缘监督模块
如果说 EDFEM 是在提取特征,那么 ESM 就是在“校准”特征。
-
双路输入:
-
预测路:取 EDFEM 生成的最底层边缘特征 Edge_1,经过平均池化处理 。
-
标签路 (GT):利用真实标签 (Ground Truth),通过 Laplacian 卷积(步长为 1 和 2)生成二值边缘图 。
-
-
损失函数协同:针对边缘像素与非边缘像素的严重类别失衡,ESM 采用了联合损失函数 :
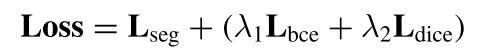
-
L_{bce} (二值交叉熵):负责基础的像素分类 。
-
L_{dice}:由于其只计算重叠度,对前景像素数量不敏感,能有效缓解类别失衡问题
-
2. 整体运行流程与协同工作机制
该模型的整体运行逻辑遵循从“粗略语义”到“精细边缘”的加工过程 :
-
特征提取阶段:原始图像输入 Backbone,经过四次下采样产生不同分辨率的特征图 X_1, X_2, X_3, X_4,其中浅层特征(如 X_1)包含丰富的纹理细节,深层特征(如 X_4)包含强语义信息 。
-
特征增强阶段(协同核心):
-
这些特征图被送入 EDFEM。在该模块内,深层语义信息被用作主要引导,而浅层细节信息被用作辅助 。
-
通过垂直级联和逐像素加权计算,边缘信息被逐层加强。这些被增强后的特征(EF_i)就像被“放大”了边界对比度的信号,能更清晰地界定矿区与背景 。
-
-
预测与监督阶段:
-
Decoder/Seg Head:将增强后的各级特征进行融合,输出最终的像素级分割预测图 。
-
ESM 辅助(仅限训练):同时,EDFEM 的输出会进入 ESM,利用二值交叉熵和 Dice 损失函数来优化边缘像素的学习。
-
-
推理阶段(效率优化):在实际使用(测试/部署)时,ESM 模块会被丢弃 。这意味着模型能够在不增加任何推理计算负担的情况下,利用训练时学到的边缘辨别能力来提升精度

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)