【小白笔记】“手撕” KNN(K-Nearest Neighbors)
方法用法示例作用说明np.array()将列表转换为 Numpy 数组,支持高性能的矢量化运算。np.sum()对数组元素求和。在距离计算中,用来把各个维度的差值平方加起来。np.sqrt()np.sqrt(4)开平方根。非常重要!返回数组值从小到大排序后的索引。例如[10, 5, 8]返回[1, 2, 0]。数组减法广播机制 (Broadcasting)。如果x是 ,x_train是 ,结果直接

2. 代码实现
假设我们使用欧氏距离,公式为: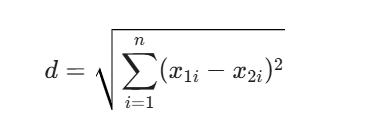
import numpy as np
from collections import Counter
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
# KNN 是“懒惰学习”,不需要训练过程
# 只需要把训练数据存起来即可
self.X_train = X
self.y_train = y
def predict(self, X):
# 对测试集里的每一个点进行预测
predictions = [self._predict(x) for x in X]
return np.array(predictions)
def _predict(self, x):
# 1. 计算测试点 x 与所有训练点之间的距离
distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]
# 2. 取得最近的 k 个点的索引
# argsort 返回的是排序后的下标
k_indices = np.argsort(distances)[:self.k]
# 3. 提取这 k 个点对应的标签
k_nearest_labels = [self.y_train[i] for i in k_indices]
# 4. 多数投票
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
# --- 测试一下 ---
if __name__ == "__main__":
# 模拟数据:[身高, 体重] -> 类别 (0: 瘦, 1: 胖)
X_train = np.array([[160, 45], [165, 50], [170, 80], [180, 90]])
y_train = np.array([0, 0, 1, 1])
clf = KNN(k=3)
clf.fit(X_train, y_train)
# 预测一个新身材 [175, 85]
X_new = np.array([[175, 85]])
prediction = clf.predict(X_new)
print(f"预测结果类别为: {prediction[0]} (1表示胖, 0表示瘦)")
初学者在接触“面向对象编程”和“机器学习流程”时最容易混淆的三个点。我们一个一个来拆解。
1. 啥时候用 self.xxx?(记忆胶囊)
在类(Class)中,self 就像是一个**“跨房间的储物柜”**。
- 局部变量(不用
self):如果你在一个函数里定义一个变量(比如distances),它就像一张便利贴。函数运行完,这张纸就被扔掉了,别的函数(比如fit)看不见它。 - 实例变量(必须用
self):如果你想把数据存起来供以后使用,就必须加self。
在你的 KNN 代码中:
self.k:在初始化时存入,为了让后面的_predict函数知道要找几个邻居。self.X_train:在fit阶段存入。因为 KNN 不会“学习”,它只是把训练集存进储物柜,等到predict的时候再拿出来对比。
规律:如果你发现这个数据在
函数A里产生,但在函数B里也要用到,那就把它赋给self。
2. 什么是“训练数据” vs “测试数据”?
你可以把机器学习想象成一场考试:
- 训练数据 (X_train, y_train):这就是课本和课后练习题。里面既有题目(X),也有标准答案(y)。电脑通过看这些数据来“记住”什么样的身材算胖,什么样的算瘦。
- 测试数据 (X_new / X_test):这就是考卷上的新题。只有题目(X),没有答案。电脑的任务是根据刚才“储物柜”里的练习题,猜出这些新题的答案。
3. “最近的标签”含义 & 为什么要返回元组?
“最近的标签”是什么意思?

为什么 Counter 返回的是元组?
这行代码:most_common = Counter(k_nearest_labels).most_common(1)
它的返回结果长这样:[(1, 2)]。
这是一个列表,里面装了一个元组 (元素, 次数)。
1:代表出现次数最多的标签(类别 1,即“胖”)。2:代表它出现了 2 次。
为什么要返回这种结构?
因为 Counter 很严谨,它怕你不仅想知道“谁最火”,还想知道“火到什么程度”(也就是得票数)。
代码逻辑拆解:
most_common[0]:取出列表里的第一个元组(1, 2)。most_common[0][0]:取出元组里的第一个值1。这就是我们要的最终预测类别!
总结一下你的 KNN 逻辑流:
fit: 把“课本”(训练集)锁进self储物柜。predict: 拿“考卷”(测试集)来考试。_predict:
- 算出考卷题目和储物柜里所有练习题的距离。
- 找出最像的 道题。
- 看这 道题的答案(标签)。
- 投票:哪个答案多,我就填哪个。
在编程中,clf是 Classifier(分类器) 的缩写。这不仅是一个变量名,也是机器学习界的一个“行业惯例”。
就像我们在数学里习惯用 表示未知数一样,在 Python 机器学习代码(尤其是使用著名的 scikit-learn 库时)中,大家习惯把实例化后的模型对象命名为 clf。
1. clf 具体指代什么?
在你的代码里:
clf = KNN(k=3)
KNN(k=3):这是你定义的那个“类(Class)”。它就像一张建筑图纸,规定了 KNN 应该怎么存数据、怎么算距离。clf:这是根据图纸盖出来的具体的房子,也叫实例(Instance)或对象(Object)。
一旦执行了这一行,clf 就成了一个具备了 fit 和 predict 能力的实体。
2. 为什么要用 clf 这个名字?
虽然你把它改名为 model、my_knn 甚至 aaa 都能运行,但用 clf 有两个好处:
- 可读性:别人一看就知道这是一个用来做**分类(Classification)**任务的模型。
- 专业感:它是监督学习中“分类器”的标准缩写。如果是一个**回归(Regression)**任务(预测具体数值,如房价),大家通常会用
reg。
3. clf 在代码中的生命周期
你可以把 clf 想象成一个**“入职的员工”**:
- 诞生 (
clf = KNN(k=3)):招聘了一个新员工,告诉他:“你的工作原则是只看最近的 3 个人。” - 培训 (
clf.fit(X_train, y_train)):给员工看练习题和答案。员工把这些信息存在自己的“脑子”(也就是self.X_train储物柜)里。 - 上岗考试 (
clf.predict(X_new)):给员工一张没答案的卷子。员工根据脑子里的练习题,给出预测结果。
4. 补充:为什么后面用了 prediction[0]?
这也是一个容易困惑的地方:
prediction = clf.predict(X_new) # 返回的是 [1]
print(prediction[0]) # 输出的是 1
- 因为你的
predict方法设计的初衷是处理一批数据(比如一次预测 100 个人)。 - 即使你只传进了一个人
X_new,predict也会返回一个数组(比如[1])。 - 为了打印出干净的数字
1而不是带中括号的[1],我们就用[0]取出数组里的第一个结果。
总结
clf 就是 Classifier。它承载了你所有的训练数据和预测逻辑。
3. 这里的关键点
np.argsort:这个函数非常关键,它不直接对距离排序,而是返回排序后的“位置索引”。这样我们才能去y_train里找到对应的标签。Counter:这是 Python 自带的计数器,most_common(1)会返回出现频率最高的一个元素及其次数,如[(label, count)]。- 特征缩放(重要):在真实场景中,如果身高的数值(180)远大于体重(80),距离计算会被身高主导。所以正式使用前通常需要做 Normalization(归一化)。
4. 它的缺点(为什么现在用得少了?)
- 计算量大:每次预测都要算一遍和全量数据的距离。如果训练集有 100 万条数据,预测一个点就要算 100 万次距离。
- 费内存:要把所有训练数据一直存在内存里。
- 维度灾难:当特征特别多(比如几千维)时,高维空间的距离变得不再可靠。

优化后的 KNN 实现
这里我使用了 Python 的 heapq 模块。因为 Python 默认是小顶堆,为了维护“最小的 K 个值”,我们需要将距离取负数放入堆中,形成逻辑上的大顶堆。
import numpy as np
import heapq
from collections import Counter
class KNN_Optimized:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def _predict(self, x):
# 1. 使用大顶堆维护前 K 个最近邻
# 堆中存储元素格式: (-距离, 标签)
max_heap = []
for i, x_train in enumerate(self.X_train):
dist = np.sqrt(np.sum((x - x_train)**2))
if len(max_heap) < self.k:
# 堆还没满,直接塞进去
heapq.heappush(max_heap, (-dist, self.y_train[i]))
else:
# 堆满了,如果当前距离比堆顶(最大距离)小,则替换
if -dist > max_heap[0][0]:
heapq.heapreplace(max_heap, (-dist, self.y_train[i]))
# 2. 提取堆中的所有标签
k_nearest_labels = [label for (_, label) in max_heap]
# 3. 处理 Tie(平局)情况
votes = Counter(k_nearest_labels)
top_votes = votes.most_common()
# 如果得票最高的存在多个(平局)
if len(top_votes) > 1 and top_votes[0][1] == top_votes[1][1]:
# 策略:在平局的类别中,选择距离最近的那个类别
# 或者简单点:递归调用 k-1(这里演示距离最近策略)
return self._resolve_tie(max_heap, top_votes[0][1])
return top_votes[0][0]
def _resolve_tie(self, max_heap, max_count):
# 寻找平局类别中,距离绝对值最小的那一个
# 堆里存的是 (-dist, label)
best_label = None
min_dist = float('inf')
for neg_dist, label in max_heap:
if abs(neg_dist) < min_dist:
min_dist = abs(neg_dist)
best_label = label
return best_label
def predict(self, X):
return np.array([self._predict(x) for x in X])


1. k=3 是什么意思?
在 __init__ 方法中,k 是一个超参数(Hyperparameter)。
- 含义:它代表“参考邻居的数量”。
- 默认值:
k=3意味着如果你在调用时不指定 ,算法默认会找距离最近的 3个点 来决定新点的类别。 - 为什么选 3? 这只是一个常用的初始默认值。在实际应用中,通常会选一个奇数(如 3, 5, 7),这样在处理二分类问题时可以有效避免 2:2 这种“平局”情况。
2. 代码中涉及的 Numpy 用法总结
Numpy 是机器学习的灵魂,代码里用到的几个方法非常经典,建议熟练掌握:
| 方法 | 用法示例 | 作用说明 |
|---|---|---|
np.array() |
np.array([1, 2]) |
将列表转换为 Numpy 数组,支持高性能的矢量化运算。 |
np.sum() |
np.sum(arr) |
对数组元素求和。在距离计算中,用来把各个维度的差值平方加起来。 |
np.sqrt() |
np.sqrt(4) |
开平方根。用于欧氏距离公式的最后一步: |
np.argsort() |
np.argsort(dist) |
非常重要! 返回数组值从小到大排序后的索引。例如 [10, 5, 8] 返回 [1, 2, 0]。 |
| 数组减法 | x - x_train |
广播机制 (Broadcasting)。如果 x 是 ,x_train 是 ,结果直接是 ,不需要写 for 循环遍历坐标。 |
**2 |
arr ** 2 |
对数组里的每个元素分别求平方。 |
3. Python 内置工具总结
除了 Numpy,代码里为了优化和统计还用了这两个利器:
A. heapq (堆队列算法)
这是你之前提到的优化核心。
heapq.heappush(heap, item): 把元素压入堆中,并保持堆结构(默认小顶堆)。heapq.heapreplace(heap, item): 弹出最小元素,并压入新元素。这比先pop再push效率更高。- 技巧:因为我们需要大顶堆(剔除最大的距离),而 Python 只有小顶堆,所以我们把距离取负数(
-dist)存储。
B. collections.Counter (计数器)
专门用来统计频率,手撕算法必背。
Counter(list): 统计列表中每个元素出现的次数。例如Counter(['A', 'A', 'B'])得到{'A': 2, 'B': 1}。.most_common(n): 返回出现次数最多的前 n 个元素及其计数的列表。例如[('A', 2)]。
4. 逻辑串联
如果你把这些工具组合起来,KNN 的逻辑就是:
- 用 Numpy 矢量化运算 快速算出距离。
- 用
heapq维护一个大小为 的“最邻近池子”。 - 用
Counter统计池子里哪个标签胜出。
这几行代码是 KNN 的核心。虽然看起来简洁,但每一行都利用了 Python 的推导式和 NumPy 的**矢量化(Vectorization)**特性。
我们逐行拆解:
第一步:计算距离(列表推导式 + 矢量运算)
distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]
for x_train in self.X_train: 这是一个列表推导式。它遍历训练集中每一个样本x_train。(x - x_train): 这里触发了 NumPy 的广播机制。假设x是[1, 2],x_train是[4, 6],它会直接对应位置相减,得到[-3, -4]。不需要写循环。**2: 对减法结果的每个元素求平方,得到[9, 16]。np.sum(...): 将平方后的数组求和,得到25。np.sqrt(...): 开方,得到5.0。这是典型的欧氏距离公式。- 结果:
distances最终是一个列表,记录了“当前测试点”到“所有训练点”的距离。
简单来说,广播机制 (Broadcasting) 是 NumPy 的一种“超能力”。它允许你对两个形状不同的数组进行算术运算,而 NumPy 会在后台自动“扩展”较小的数组,使其与较大的数组形状匹配,从而避免了手动写 for 循环的麻烦,极大地提升了计算速度。
1. 直观理解:自动填充
想象你有两个矩阵,如果它们形状一模一样,对应位置加减很自然。但如果形状不同呢?
- 场景 A:标量与数组运算
如果你执行[1, 2, 3] + 10:
NumPy 会把10自动想象成[10, 10, 10],然后进行加法。 - 场景 B:向量与矩阵运算(KNN 中的情况)
在 KNN 代码里,x是一个特征向量(如[身高, 体重]),而X_train是一个矩阵。
当执行x - x_train时,NumPy 会把x沿着行方向不断“复制”,直到它的行数和X_train一样多,然后再做减法。
2. 广播的规则(严谨定义)
NumPy 判断两个数组能否广播,遵循以下原则:
从两个数组形状(Shape)的末尾(即最右侧)开始比较:
- 维度大小相等。
- 其中一个维度的大小是 1。
如果满足其中之一,广播就能成功;否则会报错 ValueError。
例子解析:
假设 x_train 的形状是 (100, 2)(100个样本,每个样本2个特征),
你的测试点 x 的形状是 (2,)。
- NumPy 先看最右边的维度:都是
2。匹配! - 再看前一个维度:
x_train是100,x没有这个维度(缺位视为 1)。匹配! - 结果:
x被广播成(100, 2)的形状进行计算。
3. 为什么广播机制在机器学习中很重要?
- 代码简洁:
如果没有广播,计算欧氏距离你需要写两层嵌套循环:
# 错误/低效示范:
dists = []
for row in X_train:
diff_sum = 0
for i in range(len(row)):
diff_sum += (x[i] - row[i])**2
dists.append(np.sqrt(diff_sum))
有了广播,一行搞定:np.sqrt(np.sum((x - X_train)**2, axis=1))。
2. 性能飞跃:
Python 的 for 循环很慢,而 NumPy 的广播是在 C 语言底层实现的内存优化操作。处理万级以上的数据时,广播比循环快几百倍。
4. 避坑指南:形状陷阱
有时候你会遇到 (5,) 和 (5, 1)。虽然它们都有 5 个元素,但行为不同:
(5,)是 一维阵列(Rank 1 array)。(5, 1)是 二维矩阵(列向量)。
在做矩阵运算时,建议养成使用 reshape 的习惯,确保维度符合预期。
第二步:获取索引(排序技巧)
k_indices = np.argsort(distances)[:self.k]
np.argsort(distances): 这是 NumPy 非常天才的设计。它不返回排序后的数值,而是返回这些数值在原数组中的下标(索引)。
- 假设
distances = [10, 5, 8] - 排序后应该是
[5, 8, 10] argsort就会返回[1, 2, 0](因为 5 在原数组下标是 1,8 是 2,10 是 0)。
[:self.k]: 切片操作。取排名前 k 个最小距离对应的索引。
- 这样我们就拿到了“离我最近的 k 个邻居”在训练集里的位置。
第三步:提取标签(花式索引)
k_nearest_labels = [self.y_train[i] for i in k_indices]
self.y_train[i]: 我们已经有了邻居的下标i,现在去标签集y_train里查这些邻居到底是“猫”还是“狗”。- 结果:
k_nearest_labels变成了一个包含 个标签的列表,比如['猫', '猫', '狗']。
第四步:多数投票(统计学)
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
Counter(k_nearest_labels): 创建一个计数字典。如果是['猫', '猫', '狗'],它会生成{'猫': 2, '狗': 1}。.most_common(1): 找出出现次数最多的前 1 名。它返回的是一个列表嵌套元组:[('猫', 2)]。most_common[0][0]:
[0]取出第一个元组('猫', 2)。[0]再从元组中取出具体的标签'猫'。
- 返回: 最终预测结果就是“猫”。
总结:语法要点表格
| 语法点 | 类型 | 作用 |
|---|---|---|
[f(x) for x in list] |
列表推导式 | 快速生成列表,替代显式的 for 循环。 |
x - x_train |
NumPy 广播 | 允许不同形状(但在一定规则下)的数组直接进行算术运算。 |
np.argsort |
索引排序 | 机器学习中经常需要保留原始位置,所以 argsort 比 sort 常用得多。 |
[:k] |
切片 | 提取序列的前 个元素。 |
Counter |
集合计数器 | 快速统计频率,非常适合处理“多数投票”逻辑。 |
这是一个非常敏锐的观察!在 KNN 这种基于距离的算法中,单位不统一(量纲问题)是致命的。
为什么单位不统一会造成破坏?
假设我们有两个特征:身高(m)和收入(元):
- 样本 A:
[1.8, 10000] - 样本 B:
[1.7, 10100] - 样本 C:
[1.1, 10000](这是一个小孩)
计算欧氏距离时:
- A 和 B 的距离主要被收入差(100元)主导,身高差(0.1m)几乎被忽略了。
- 结果算法会认为“高大的 A”和“矮小的 C”更接近,因为他们的收入一样。
这就是量纲压制。解决方法是:数据标准化 / 归一化 (Feature Scaling)。
1. 两种主流解决方案

2. 手撕代码:如何给 KNN 加上标准化?
在实际操作中,你需要先对训练集计算均值和标准差,然后用同样的参数去处理测试集(这叫防止数据泄露)。
import numpy as np
def standardize(X_train, X_test):
# 1. 计算训练集的均值和标准差 (按列计算,axis=0)
mean = np.mean(X_train, axis=0)
std = np.std(X_train, axis=0)
# 2. 对训练集进行变换
X_train_scaled = (X_train - mean) / std
# 3. 重要:使用训练集的 mean 和 std 来变换测试集!
X_test_scaled = (X_test - mean) / std
return X_train_scaled, X_test_scaled
# 示例数据
X_train = np.array([[170, 50000], [180, 60000], [160, 40000]])
X_test = np.array([[175, 55000]])
X_train_s, X_test_s = standardize(X_train, X_test)
print(X_train_s)
3. 注意事项(面试常考)
- 为什么要用训练集的参数去缩放测试集?
因为在现实世界中,测试集是“未来的数据”,你是不知道它的均值的。如果你用了测试集自己的均值,就相当于提前知道了未来的信息,这会导致模型评估不准。 - 哪些算法不需要标准化?
决策树、随机森林。因为它们是通过“切一刀”来分类的,看的是相对大小,而不是距离。而 KNN、SVM、神经网络、线性回归 都非常依赖标准化。
4. 总结:涉及到的 NumPy 新方法
| 方法 | 用法 | 作用 |
|---|---|---|
np.mean(X, axis=0) |
axis=0 表示按列计算 |
算出每一列特征的平均值。 |
np.std(X, axis=0) |
axis=0 表示按列计算 |
算出每一列特征的标准差。 |
综合我们之前的讨论,一个工业级标准的“手撕 KNN”实现需要包含以下三个核心要素:
- 数据标准化:解决单位不统一(量纲)问题。
- 大顶堆优化:将时间复杂度从 优化到 。
- 平局处理:解决票数相同时的决策逻辑。
以下是完整的 Python 代码实现:
import numpy as np
import heapq
from collections import Counter
class KNNClassifier:
def __init__(self, k=3):
self.k = k
self.mean = None
self.std = None
def _standardize(self, X, train=True):
"""数据标准化 (Z-score Normalization)"""
if train:
self.mean = np.mean(X, axis=0)
self.std = np.std(X, axis=0)
# 防止标准差为0的情况
self.std[self.std == 0] = 1.0
return (X - self.mean) / self.std
def fit(self, X_train, y_train):
"""
KNN的训练过程:其实就是把标准化的数据存起来
"""
self.X_train = self._standardize(X_train, train=True)
self.y_train = np.array(y_train)
def predict(self, X_test):
"""预测测试集"""
X_test_scaled = self._standardize(X_test, train=False)
predictions = [self._predict_single(x) for x in X_test_scaled]
return np.array(predictions)
def _predict_single(self, x):
"""对单个样本进行预测,使用大顶堆优化"""
# 堆中存放 (-距离, 标签),因为 heapq 是小顶堆,取负号可模拟大顶堆
max_heap = []
for i, x_train in enumerate(self.X_train):
# 使用 NumPy 广播机制计算欧氏距离
dist = np.sqrt(np.sum((x - x_train)**2))
if len(max_heap) < self.k:
heapq.heappush(max_heap, (-dist, self.y_train[i]))
else:
# 如果当前距离比堆中最大的距离还小,则替换
if -dist > max_heap[0][0]:
heapq.heapreplace(max_heap, (-dist, self.y_train[i]))
# 提取 K 个邻居的标签
k_nearest_labels = [label for (_, label) in max_heap]
# 统计票数
votes = Counter(k_nearest_labels)
top_votes = votes.most_common() # 返回示例: [('A', 3), ('B', 3)]
# --- 处理 Tie (平局) 情况 ---
if len(top_votes) > 1 and top_votes[0][1] == top_votes[1][1]:
# 策略:如果票数相同,选择距离最近的那个标签
# 在 max_heap 中找绝对值最小的那个距离对应的标签
best_label = min(max_heap, key=lambda x: abs(x[0]))[1]
return best_label
return top_votes[0][0]
# --- 测试代码 ---
if __name__ == "__main__":
# 模拟数据:特征是 [身高(cm), 体重(kg)], 标签 0:瘦, 1:胖
X_train = np.array([[160, 45], [165, 50], [155, 40], [170, 80], [180, 90], [175, 85]])
y_train = np.array([0, 0, 0, 1, 1, 1])
# 初始化模型
knn = KNNClassifier(k=3)
knn.fit(X_train, y_train)
# 预测新样本 [172, 75]
X_new = np.array([[172, 75]])
res = knn.predict(X_new)
print(f"新样本 {X_new[0]} 的预测类别为: {res[0]} (1:胖, 0:瘦)")
代码关键点回顾:
axis=0: 在np.mean中,这个参数确保我们是按“列”计算。如果身高是一列,体重是一列,我们要分别得到它们的均值。heapq.heapreplace: 这是一个性能技巧。它比先heappop再heappush快,因为它只进行一次堆调整。max_heap[0][0]: 堆顶元素(下标0)永远是目前 个邻居里距离最大的那一个。- 防泄露标准化: 注意
predict里的train=False。我们使用的是fit阶段存下来的self.mean和self.std。
KNN 的局限性总结
虽然我们手动实现了它,但你要记住 KNN 的三个硬伤:
- 样本不平衡敏感:如果“瘦子”样本有 1000 个,“胖子”只有 10 个,即便新点离胖子近,由于邻居里瘦子多,也会被判为瘦子。
- 计算昂贵:每一个新点都要遍历整个训练集。
- 内存消耗:必须把整个训练集塞进内存。
在机器学习中,几乎所有的模型(无论是简单的 KNN 还是复杂的深度神经网络)都可以抽象为一套通用的框架。
通常一个标准的模型类会包含 3 到 5 个核心部分。我们可以用**“厨师做菜”**来类比这个框架,这样非常方便记忆。
机器学习类的“五大金刚”框架
以我们刚才写的 KNNClassifier 为例,按照这个框架来拆解:
| 框架组件 | 对应函数 | 厨师做菜类比 | 在 KNN 中的具体作用 |
|---|---|---|---|
| 1. 初始化配置 | __init__ |
准备厨具 | 设定超级参数 ,准备好存放数据的空仓库。 |
| 2. 数据记忆/训练 | fit |
购买食材 | 记录训练集的数据,计算并存下标准化的“尺子”(均值和标准差)。 |
| 3. 预测入口 | predict |
开门营业 | 接收新订单(测试集),对每个数据进行标准化处理并启动预测流程。 |
| 4. 核心逻辑(私有) | _predict_single |
后厨烹饪 | KNN 的核心:算距离、进堆排序、投票决策(不希望外部直接调用的内部细节)。 |
| 5. 辅助工具(私有) | _standardize |
洗菜切菜 | 一个通用的工具函数,负责把数据处理成统一的规格。 |
深入解释:为什么是这几部分?
第一部分:__init__ (构造函数)
- 作用:定义模型的“性格”。
- KNN 例子:你告诉模型,“你以后办事要参考 5 个邻居()”。这些参数在预测开始前就定死了。
第二部分:fit (拟合/训练)
- 作用:让模型看数据,学习规律。
- KNN 例子:对于 KNN 这种“懒惰学习者”,它其实没在学习,只是在“背书”——把训练数据存进内存。但它需要在这里计算全局特征(比如均值),这就像是厨师要先记住食材的特性。
第三部分:predict (预测)
- 作用:对外的统一接口。
- KNN 例子:它负责把一堆测试数据(批量数据)拆开,一个一个丢给后厨(
_predict_single)去处理,最后把结果打包还给用户。
第四部分:_predict_single (核心计算) —— 这是最体现算法灵魂的地方
- 作用:实现具体的数学公式。
- KNN 例子:也就是你写的“算距离 -> 堆排序 -> 找邻居 -> 投票”的那套逻辑。我们用下划线
_开头,意思是它是“内部操作”,外行(用户)不需要知道里面是怎么算的。
第五部分:辅助函数(如 _standardize)
- 作用:保持代码整洁(DRY原则:Don’t Repeat Yourself)。
- KNN 例子:训练集要缩放,测试集也要缩放。如果不用函数封装,你就要写两遍同样的公式,容易出错。
记忆口诀:“配、记、算、推、辅”
- 配 (
init):配置参数。 - 记 (
fit):记住规律(或数据)。 - 算 (
_predict_single):数学公式计算。 - 推 (
predict):推理结果。 - 辅 (
_standardize):辅助预处理。
为什么掌握这个框架很重要?
当你以后去学 Scikit-learn(工业级 Python 机器学习库)时,你会发现所有的算法(逻辑回归、随机森林、SVM)全都是按照这个 fit 和 predict 的结构写的。只要记住了这个类框架,你就能“一通百通”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)