论文简读:InternVL3| Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
介绍InternVL3(InternVL系列重大升级):实现原生多模态预训练(预训练阶段同步习得语言与多模态能力,规避传统后训练复杂优化难题)。核心技术:引入可变视觉位置编码(支持更长多模态上下文)、结合有监督微调与混合偏好优化等先进后训练策略、采用测试阶段缩放方案。性能表现:全品类多模态任务树立开源模型新标杆,保留强大语言能力;InternVL3-78B在MMMU基准测试中72.2,超越现有开源

Code: https://github.com/OpenGVLab/InternVL
Model: https://huggingface.co/OpenGVLab/InternVL3-78B
Data: https://huggingface.co/datasets/OpenGVLab/InternVL-Data
发布时间:2025年4月19日
InternVL3(InternVL系列重大升级版本),采用原生多模态预训练范式:无需先训练纯文本大语言模型再适配,单一预训练阶段同步输入多模态数据与纯文本语料,同步习得语言能力与多模态能力,解决传统后处理流程的复杂对齐难题。
为提升性能与可扩展性,引入可变视觉位置编码(V2PE) 以支持更长多模态上下文窗口,采用有监督微调、混合偏好优化等后训练策略,配合测试阶段缩放策略与优化训练基础设施。实验表明,InternVL3-78B在MMMU基准测试中取得72.2分,刷新开源多模态大模型标杆。
主要亮点:
- 介绍InternVL3(InternVL系列重大升级):实现原生多模态预训练(预训练阶段同步习得语言与多模态能力,规避传统后训练复杂优化难题)。
- 核心技术:引入可变视觉位置编码(支持更长多模态上下文)、结合有监督微调与混合偏好优化等先进后训练策略、采用测试阶段缩放方案。
- 性能表现:全品类多模态任务树立开源模型新标杆,保留强大语言能力;InternVL3-78B在MMMU基准测试中72.2,超越现有开源多模态大语言模型,显著缩小与闭源旗舰模型的性能差距。
1 引言
主流多模态大语言模型多通过纯文本大语言模型+复杂多阶段适配的后处理方案实现,依赖原始纯文本预训练,存在模态对齐难题,落地需专业辅助数据、精细参数冻结与多阶段微调,凸显高效多模态训练范式的研发必要性。
InternVL3核心亮点为原生多模态预训练策略:预训练阶段同步输入多模态数据与纯文本语料,一体化获取语言与多模态能力。
技术创新:引入可变视觉位置编码(V2PE) 适配超长多模态上下文;融合有监督微调、混合偏好优化等后训练策略,结合测试阶段缩放策略与优化训练基础设施,提升效率与表现。
实验证明,InternVL3全面超越前代模型,覆盖多学科推理等多模态任务;引入领域专属数据集后,在工具使用等方向进步显著。性能媲美顶尖闭源模型,MMMU基准测试达72.2分,树立开源模型新标杆;语言能力与同量级顶尖大语言模型相当。
2 InternVL3关键技术
2.1 模型架构
InternVL3沿用前代**“ViT-MLP-LLM”整体框架**,架构参数见表1。
采用预训练权重初始化ViT与大语言模型模块以节约训练成本:视觉编码器可选InternViT-300M、InternViT-6B;语言模型采用Qwen2.5系列、InternLM3-8B预训练基座权重(无指令微调);MLP为两层网络(随机初始化,与InternVL2.5一致)。新增像素重排操作,将视觉token数量压缩至1/4,448×448图像仅需256个视觉token,提升高分辨率图像处理扩展性。
核心技术
可变视觉位置编码(V2PE),为视觉token分配更小、更灵活的位置增量,支持更长多模态上下文且不过度扩展位置窗口。
技术细节
多模态样本表示为 x = ( x 1 , x 2 , … , x L ) \mathbf{x} = \left(x_1, x_2, \dots, x_L\right) x=(x1,x2,…,xL)( x i x_i xi可为文本/视觉/其他模态嵌入);位置索引 p i p_i pi递归计算: p 1 = 0 p_1=0 p1=0, p i = f pos ( p i − 1 , x i ) p_i=f_{\text{pos}}(p_{i-1}, x_i) pi=fpos(pi−1,xi)( i ≥ 2 i\geq2 i≥2)。区别于传统统一递增1的方式,V2PE采用模态专属规则:文本token步长1(维持位置辨识度),视觉token步长 δ \delta δ( δ < 1 \delta<1 δ<1,减缓索引增长)。
参数设置
训练阶段 δ \delta δ从预定义集合 Δ = { 1 , 1 2 , 1 4 , 1 8 , 1 16 , 1 32 , 1 64 , 1 128 , 1 256 } \Delta=\left\{1,\frac{1}{2},\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32},\frac{1}{64},\frac{1}{128},\frac{1}{256}\right\} Δ={1,21,41,81,161,321,641,1281,2561}随机选取,单张图像内 δ \delta δ固定以保留内部相对位置;推理阶段可灵活选 δ \delta δ平衡任务表现与位置窗口有效性, δ = 1 \delta=1 δ=1时等价于传统固定步长编码。
2.2 原生多模态预训练
提出原生多模态预训练方法:将语言预训练与多模态对齐训练整合于同一预训练阶段,混合输入多模态数据(图文、视频文本等)与大规模纯文本语料实现联合优化,同步学习语言与多模态能力,无需额外桥接模块或跨模型对齐流程即可高效处理跨模态任务。
核心技术1:多模态自回归建模。模型 M \mathcal{M} M(Transformer架构,参数 θ \boldsymbol{\theta} θ)针对长度为 L L L的样本 x = ( x 1 , . . . , x L ) \boldsymbol{x}=(x_1,...,x_L) x=(x1,...,xL)采用从左到右自回归目标,仅在文本token上计算损失(视觉token作为条件上下文),损失函数为: L text-only ( θ ) = − ∑ i = 2 x i ∈ Text L w i ⋅ log p θ ( x i ∣ x 1 , … , x i − 1 ) \mathcal{L}_\text{text-only}(\boldsymbol{\theta}) = -\sum_{\substack{i=2 \\ x_i \in \text{Text}}}^{L} w_i \cdot \log \ p_{\boldsymbol{\theta}}\left(x_i \mid x_1, \dots, x_{i-1}\right) Ltext-only(θ)=−∑i=2xi∈TextLwi⋅log pθ(xi∣x1,…,xi−1)。为缓解梯度偏向问题,采用平方平均策略设置损失权重 w i = 1 / l 0.5 w_i=1/l^{0.5} wi=1/l0.5( l l l为需计算损失的token总数)。
核心技术2:联合参数优化。预训练期间联合更新所有模型参数,优化目标为 θ ∗ = arg min θ E x ∈ D multi [ L text-only ( θ ) ] \boldsymbol{\theta}^* = \arg\min_{\boldsymbol{\theta}} \mathbb{E}_{\boldsymbol{x} \in \mathcal{D}_\text{multi}} \left[ \mathcal{L}_\text{text-only}(\boldsymbol{\theta}) \right] θ∗=argminθEx∈Dmulti[Ltext-only(θ)]( D multi \mathcal{D}_\text{multi} Dmulti为纯文本+多模态数据集);对所有层级联合训练,协同优化全部参数,保证语言与视觉特征同步演化,无需额外微调即可胜任纯语言与多模态任务。
技术细节:预训练数据含多模态数据(现有数据集+真实世界数据,覆盖OCR、文档理解等领域,新增GUI、工具使用等场景数据)与纯文本数据(弥补文本多样性不足,强化语言能力)。采用两阶段采样策略确定最优模态比例,最终语言数据:多模态数据=1:3,总训练token约2000亿(纯文本500亿、多模态1500亿)。
2.3 MPO后训练
通过两阶段后训练进一步提升模型的多模态对话和推理能力,包含有监督微调(SFT)和混合偏好优化(MPO)。在SFT阶段,模型学习模仿高质量回复来拟合正向监督信号。后续的MPO阶段则引入正负样本的额外监督,进一步提升模型的综合能力。
有监督微调 复用了随机JPEG压缩、平方损失重加权和多模态数据打包技术。相比前代,InternVL3的SFT阶段将训练样本拓展到工具使用、3D场景理解、GUI操作、长上下文任务、视频理解、科学图表理解、创意写作以及多模态推理等领域。
混合偏好优化。在预训练和SFT阶段,模型基于真实标签token进行预测,而在推理阶段模型需要基于自身的历史输出来生成后续token。真实标签和模型生成token之间的分布偏移会损害模型的思维链推理能力。为缓解这一问题,引入混合偏好优化(MPO),通过正负样本的额外监督来将模型的回复分布对齐到真实标签分布,最终提升推理性能。具体而言,MPO的训练目标由偏好损失 L p \mathcal{L}_p Lp、质量损失 L q \mathcal{L}_q Lq和生成损失 L g \mathcal{L}_g Lg组合得到:
L = w p L p + w q L q + w g L g , (9) \mathcal{L} = w_p \mathcal{L}_p + w_q \mathcal{L}_q + w_g \mathcal{L}_g, \tag{9} L=wpLp+wqLq+wgLg,(9)
其中 w ∗ w_* w∗对应各损失分支的权重。具体来说,DPO损失作为偏好损失,让模型学习选中回复和落选回复之间的相对优劣:
L p = − log σ ( β log π θ ( y c ∣ x ) π 0 ( y c ∣ x ) − β log π θ ( y r ∣ x ) π 0 ( y r ∣ x ) ) , (10) \mathcal{L}_p = -\log \sigma\left( \beta \log \frac{\pi_{\boldsymbol{\theta}}(y_c \mid x)}{\pi_0(y_c \mid x)} - \beta \log \frac{\pi_{\boldsymbol{\theta}}(y_r \mid x)}{\pi_0(y_r \mid x)} \right), \tag{10} Lp=−logσ(βlogπ0(yc∣x)πθ(yc∣x)−βlogπ0(yr∣x)πθ(yr∣x)),(10)
其中 β \beta β是KL惩罚系数, x x x为用户提问, y c y_c yc和 y r y_r yr分别是选中回复和落选回复。策略模型 π 0 \pi_0 π0基于初始模型初始化。随后我们使用BCO损失作为质量损失,让模型学会判断单一回复的绝对质量:
L q = L q + + L q − , (11) \mathcal{L}_q = \mathcal{L}_q^+ + \mathcal{L}_q^-, \tag{11} Lq=Lq++Lq−,(11)
其中 L q + \mathcal{L}_q^+ Lq+和 L q − \mathcal{L}_q^- Lq−分别是选中回复和落选回复对应的损失,二者独立计算,要求模型能够单独判别各回复的质量。损失分支计算如下:
L q + = − log σ ( β log π θ ( y c ∣ x ) π 0 ( y c ∣ x ) − δ ) , (11) \mathcal{L}_q^+ = -\log \sigma\left( \beta \log \frac{\pi_{\boldsymbol{\theta}}(y_c \mid x)}{\pi_0(y_c \mid x)} - \delta \right), \tag{11} Lq+=−logσ(βlogπ0(yc∣x)πθ(yc∣x)−δ),(11)
L q − = − log σ ( − ( β log π θ ( y r ∣ x ) π 0 ( y r ∣ x ) − δ ) ) , (12) \mathcal{L}_q^- = -\log \sigma\left( -\left( \beta \log \frac{\pi_{\boldsymbol{\theta}}(y_r \mid x)}{\pi_0(y_r \mid x)} - \delta \right) \right), \tag{12} Lq−=−logσ(−(βlogπ0(yr∣x)πθ(yr∣x)−δ)),(12)
其中 δ \delta δ为奖励偏移量,由历史奖励的滑动平均值计算得到,用于稳定训练。最终我们使用LM损失作为生成损失,辅助模型学习生成优质回复,损失函数定义与公式6一致。
数据。我们在现有训练语料基础上构建SFT训练语料,并新增了工具使用、3D场景理解、GUI操作、科学图表、多模态推理等样本,最终SFT训练样本规模得到大幅扩充。MPO的数据基于现有数据集和采样方案构建,覆盖了通用视觉问答、科学、图表、数学、OCR和文档等广泛领域。在MPO阶段,所有模型都在同一个数据集上训练,该数据集包含约30万样本。
2.4 测试阶段缩放策略
测试缩放已被证明是提升大语言模型和多模态大语言模型推理能力的有效方法。在本文中,我们使用Best-of-N评测策略并以VisualPRM-8B作为评判模型,为推理和数学任务筛选最佳回复。
视觉过程奖励模型。VisualPRM首先为给定解答的每个步骤打分,再通过平均得到该解答的整体得分。该流程被设计为多轮对话任务,充分利用了多模态大语言模型的生成能力。图像 I I I、问题 q q q以及问题的分步解答 s = { s 0 , s 1 , … , s n } ∈ S s = \{s_0, s_1, \dots, s_n\} \in \mathcal{S} s={s0,s1,…,sn}∈S的第一步会作为第一轮的输入,后续轮次则依次输入新的步骤。在训练阶段,模型需要预测每一轮中对应步骤的正确性:
c i ∼ M ( y i ∣ I , q , s ≤ i ) , (14) c_i \sim M(y_i \mid I, q, s_{\leq i}), \tag{14} ci∼M(yi∣I,q,s≤i),(14)
其中 c i ∈ { + , − } c_i \in \{+, -\} ci∈{+,−}代表第 i i i个步骤是否正确。在推理阶段,每一步的得分被定义为生成“+”的概率。
数据。VisualPRM400K被用于训练VisualPRM,该数据集基于MMPR v1.2收集的多模态问题构建。遵循现有数据流水线,我们通过InternVL3的采样输出进一步扩充数据集。
2.5 训练基础设施
- 扩展InternEVO框架(原优化大语言模型训练零冗余优化器(ZeRO))以支持InternVL模型训练,可在数千张GPU上高效训练数千亿参数模型。
- 引入ViT、MLP和大语言模型模块灵活解耦的分片策略(计算与通信重叠提升效率),支持数据并行、张量并行、序列并行、流水线并行及任意组合。
- 针对视觉-文本token比例波动导致的计算负载不均衡问题,引入动态平衡计算负载技术,保障资源高效公平利用。
- 针对不同参数量InternVL模型,框架可找到平衡内存占用与通信开销的最优配置;支持32K token序列时结合头并行和序列并行技术解决扩展性瓶颈;同等计算预算下,InternVL3使用该框架使同规格模型50%~200%。
3 效果对比
3.1 与其他先进多模态大语言模型的综合对比
InternVL3在全品类多模态任务上的性能领先一众竞品,不仅显著超越其他开源模型,同时在性能上也媲美顶尖闭源模型。值得一提的是,InternVL3-78B的表现甚至能和旗舰级闭源模型一较高下。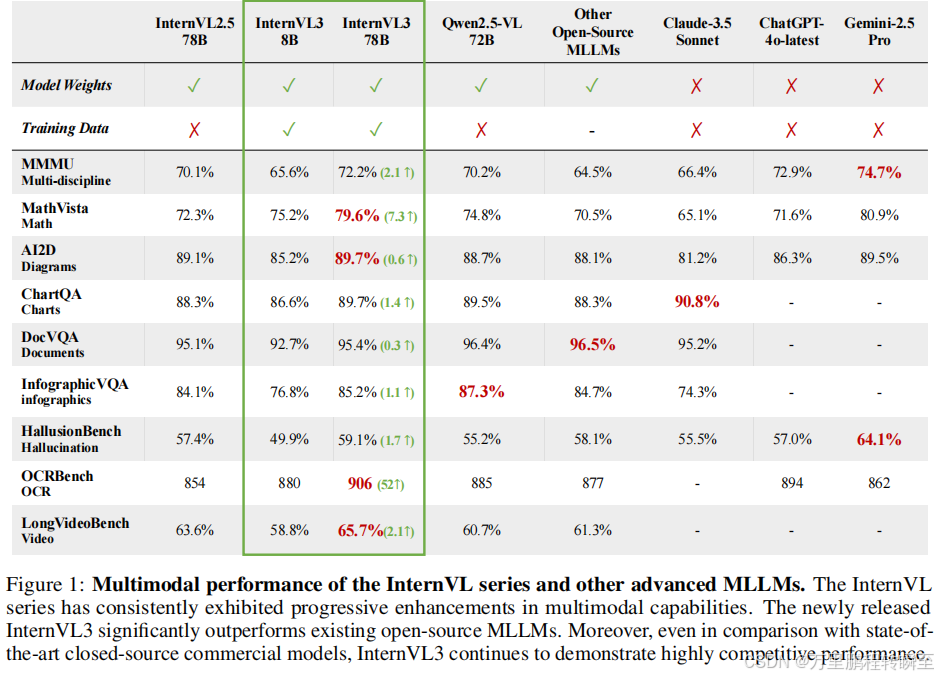
InternVL3在各类基准测试中全面超越前代InternVL模型,在对比闭源商业旗舰模型时,InternVL3同样保持了极强的竞争力。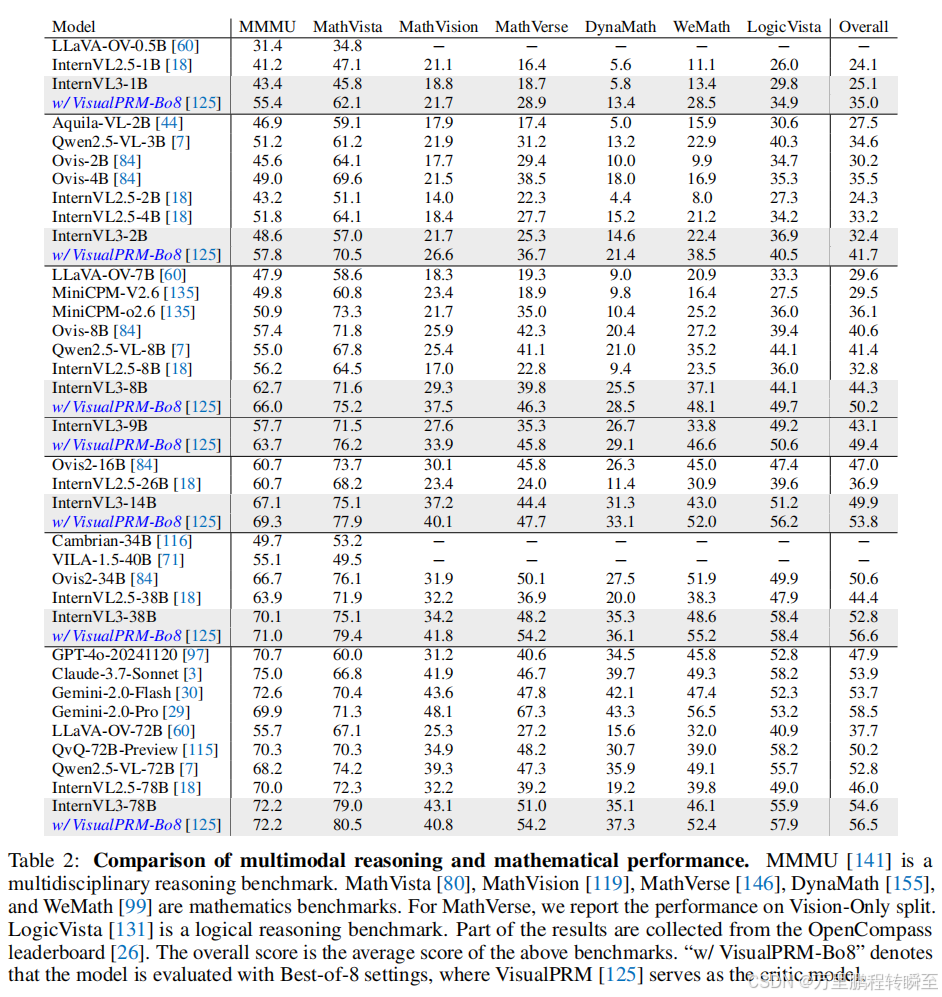
3.2 多模态推理与数学能力
该模型一大亮点是Best-of-N评测策略的高效性。使用该方法时,即便是小参数量的模型也能在推理性能上取得大幅提升,这一提升充分证明了测试阶段缩放策略的有效性。
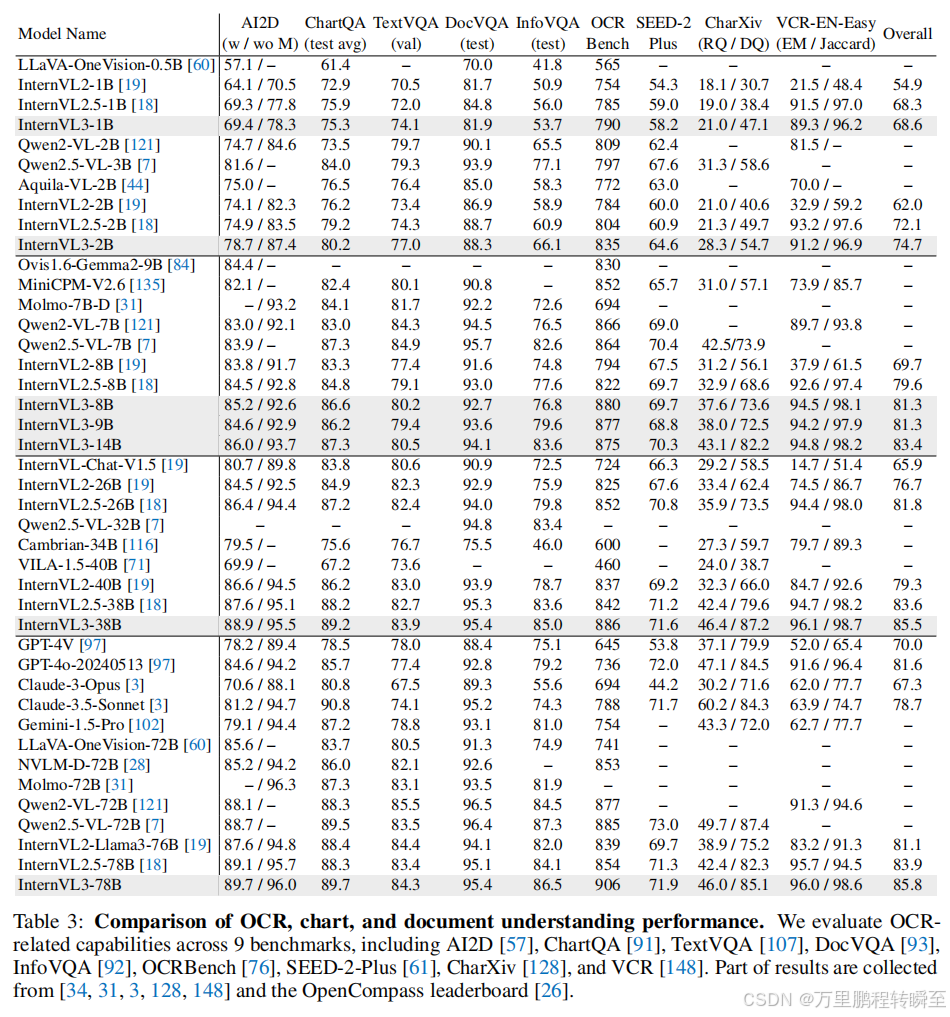
3.3 OCR、图表与文档理解
3.4 多图理解
使用BLINK、Mantis-Eval、MMIU、MuirBench、MMT-Bench和MIRB等权威基准测试InternVL3的多图关系感知和理解能力,这些基准全面考察了跨图推理和上下文整合能力,这些能力是实现高效多模态交互的关键。
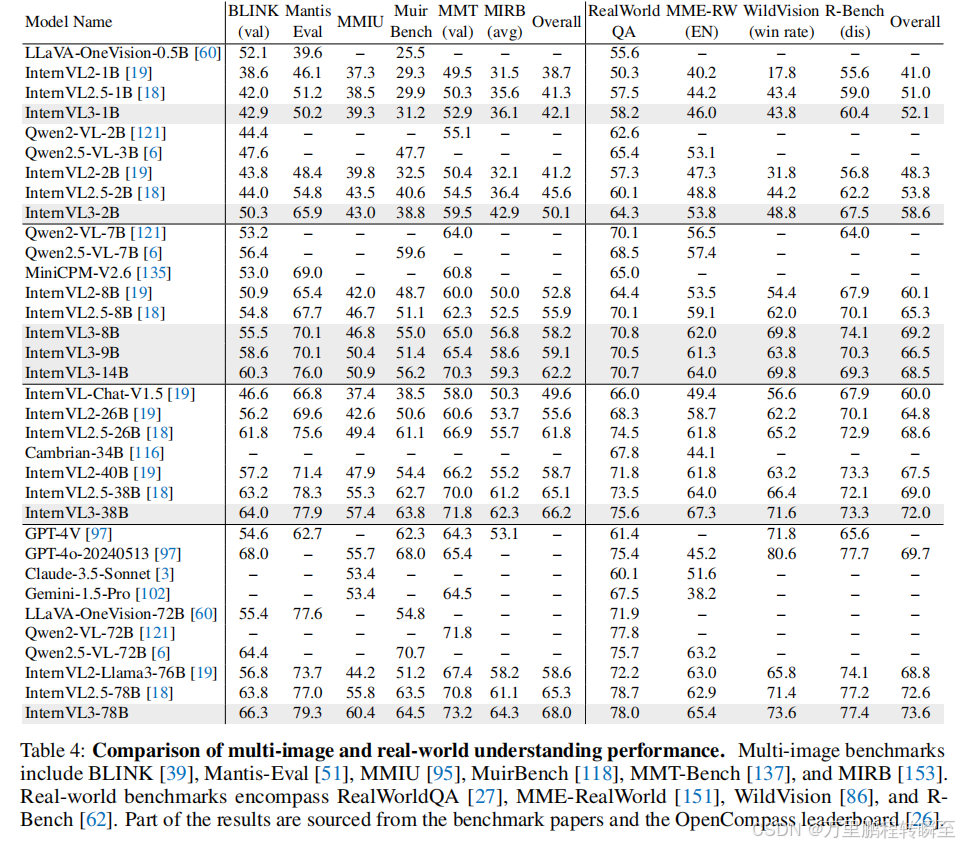
3.5 真实世界场景理解
使用RealWorldQA、MME-RealWorld、WildVision和R-Bench四项真实世界理解基准评测InternVL3,测试其处理复杂真实任务的能力。
3.6 多模态综合评测
综合多模态评测基于MME、MMBench、MMBench v1.1、MMVet、MMVet v2和MMStar等成熟基准开展。小参数量InternVL3已经实现了性能提升,模型参数量越大性能提升越显著。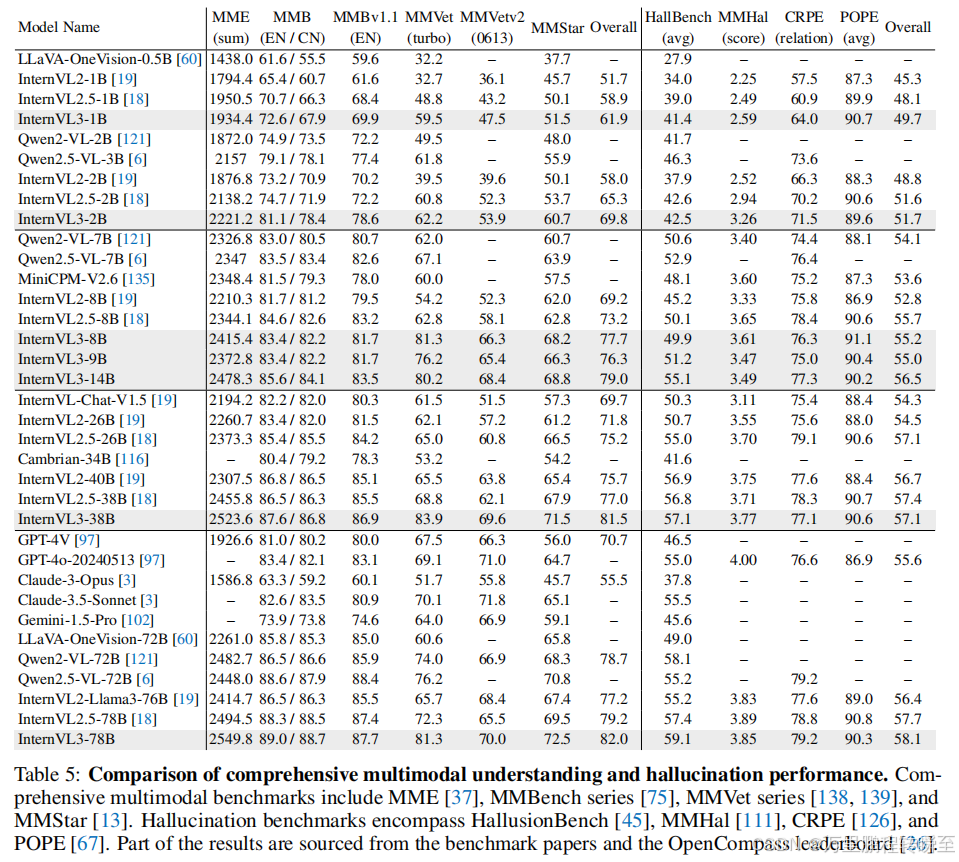
3.7 多模态幻觉检测
在HallusionBench、MMHal-Bench、CRPE和POPE四项成熟基准上评估InternVL3生成幻觉的倾向。相比前代模型,新一代InternVL3模型在所有参数量级别上都展现出了全面且具备竞争力的幻觉检测表现,同时在处理多模态幻觉任务时实现了持续改进。
3.8 视觉定位
基于RefCOCO、RefCOCO+和RefCOCOg数据集评测InternVL3的视觉定位能力,模型需要根据文本描述在图像中精准定位目标物体。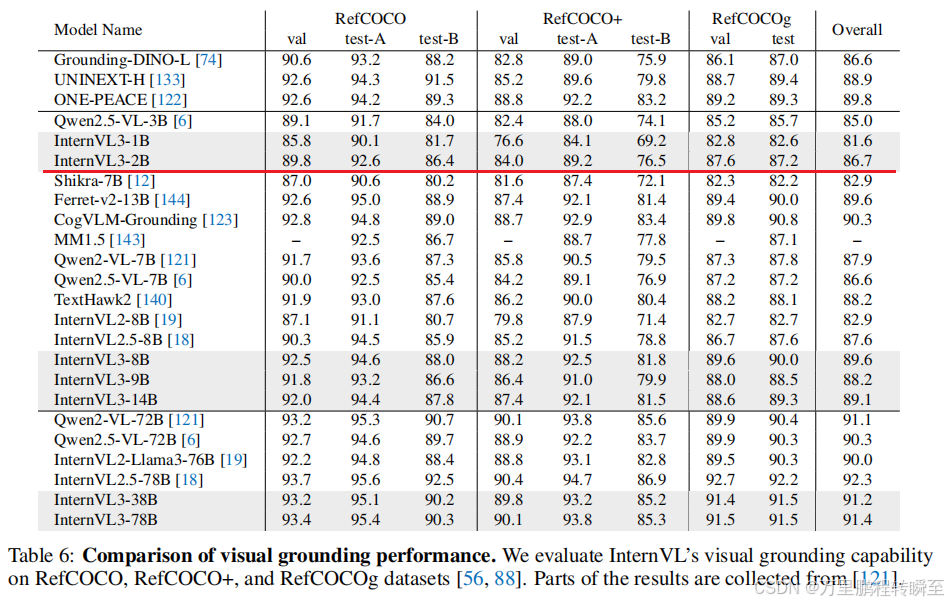
3.9 多模态多语言理解
使用MMMB、Multilingual MMBench和MTVQA三项基准评测InternVL3的多模态多语言理解能力。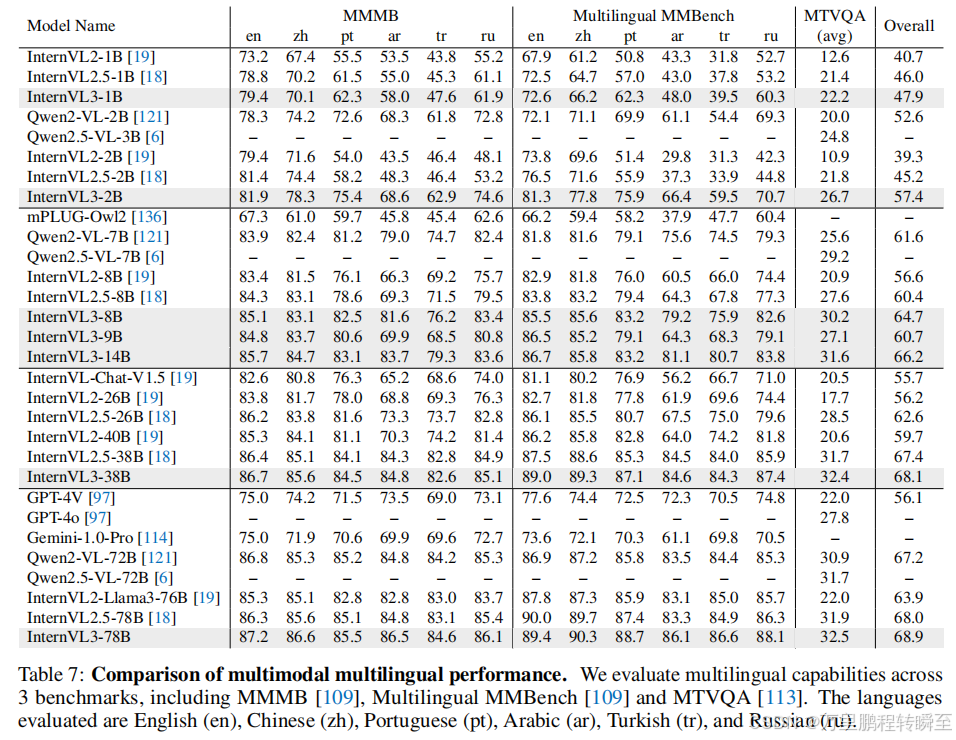
3.10 视频理解
视频理解能力是评估多模态大语言模型捕获时序和多模态线索的核心指标。在本文中,我们使用Video-MME、MVB、MMBench-Video、MLVU、LongVideoBench和CG-Bench六项成熟基准评测InternVL3系列。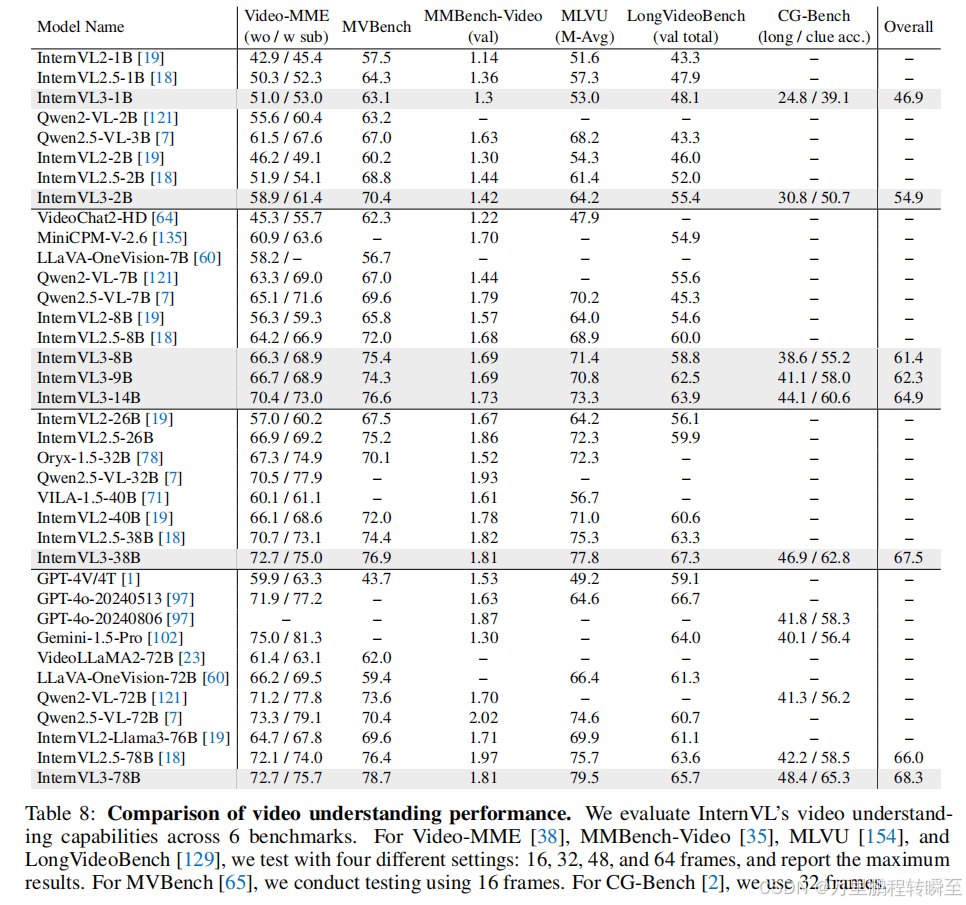
3.11 GUI定位

在ScreenSpot测试中,InternVL3-72B准确率小幅领先其他开源模型,大参数量的InternVL3-38B则以显著优势超越了多款闭源旗舰模型。
在难度更高的ScreenSpot-V2基准测试中,InternVL3展现出了出色的缩放能力,小参数量版本就已经超过其他竞品,大参数量版本进一步缩小了与超大参数量模型的差距。这些结果凸显了InternVL3在GUI理解任务上的稳健性,特别是在处理复杂屏幕布局和动态界面方面。性能提升随模型参数量增长愈发显著,说明更大的模型架构能够更好地捕捉精准GUI定位所需的细粒度视觉文本对齐关系。
3.12 空间推理
空间推理需要模型通过视觉输入构建三维环境的心智表征,对于自动驾驶这类应用而言至关重要。基于Visual-Spatial Intelligence Benchmark(VSI-Bench)测试InternVL3的性能,对比了当前顶尖的多模态大语言模型。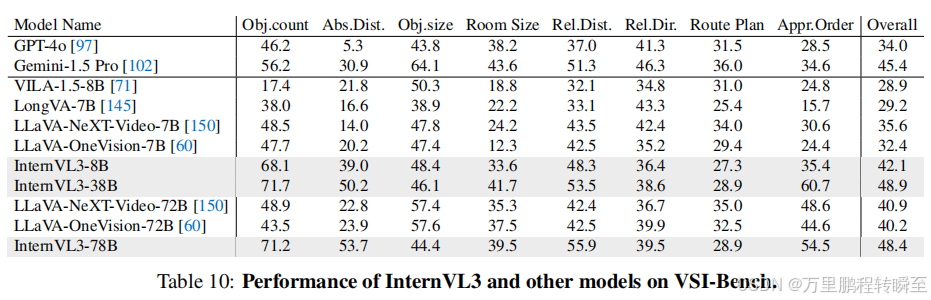
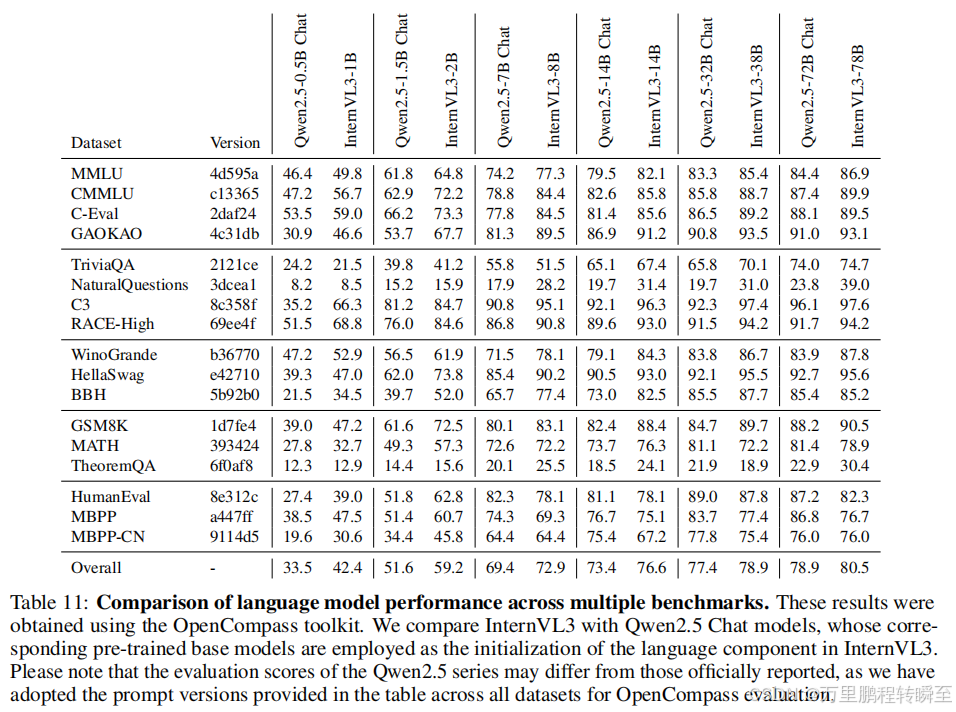
3.13 语言能力评测
通过MMLU、CMMLU、C-Eval、GAOKAO-Bench、TriviaQA、NaturalQuestions、RACE、WinoGrande、HellaSwag、BigBench Hard、GSM8K-Test、MATH、TheoremQA、HumanEval、MBPP以及MBPP-CN多品类基准全面评测InternVL3的语言能力,这些基准涵盖了通识知识、语言理解、推理、数学和编程等任务。
4 消融实验
原生多模态预训练效果验证
为评估原生多模态预训练的有效性,我们在保持模型架构、初始化参数和训练数据完全不变的前提下开展了对照实验。传统训练流程是先进行MLP预热实现多模态对齐,再进行指令微调阶段。我们的实验将传统MLP预热阶段替换为原生多模态预训练流程,以此单独剥离出原生多模态预训练对模型整体多模态能力的贡献。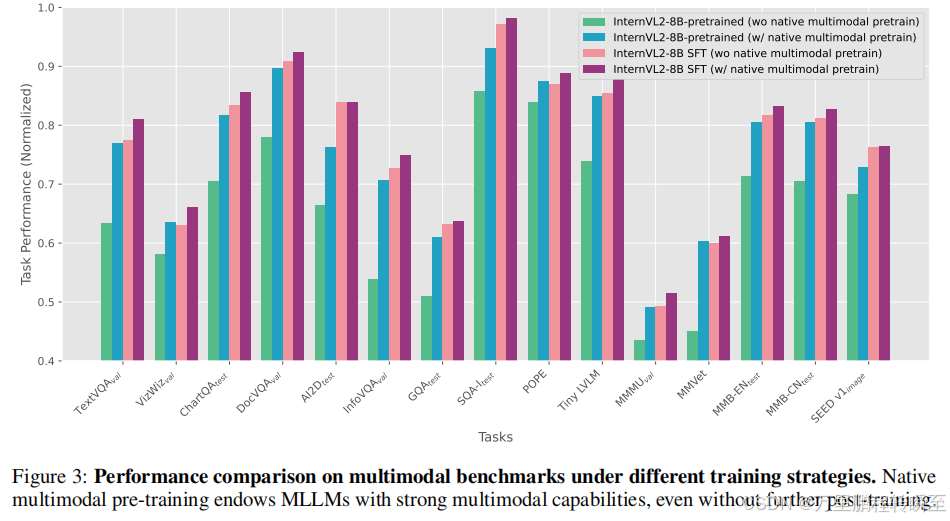
评测结果表明,搭载原生多模态预训练的模型,即便不进行额外的后训练,在大部分基准测试上的性能也可以与完整多阶段训练的基线持平。如果在高质量数据上进行指令微调,模型在所有评测任务上都能实现进一步的性能提升,这些结果凸显了原生多模态预训练赋予多模态大语言模型强大多模态能力的高效性。
可变视觉位置编码效果评估
为了拓展模型在长上下文多模态场景下的能力,InternVL3使用可变视觉位置编码(V2PE)进行视觉嵌入。为了在更广泛的场景探索V2PE的效用,我们在原生多模态预训练阶段引入了该机制,并使用标准多模态基准对预训练后的模型进行评测。
表12的结果表明,引入V2PE为大多数评测指标带来了显著的性能提升。消融实验通过调整位置增量 δ \delta δ发现,即便是针对短上下文任务,使用较小的 δ \delta δ值也能够实现最优性能。这些结果为优化多模态大语言模型的视觉token位置编码策略提供了极具价值的参考。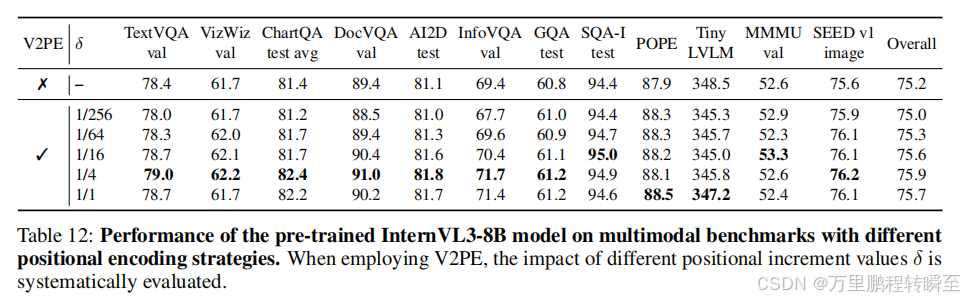
混合偏好优化效果验证
从表13可以看出,经过MPO微调的模型,在七项多模态推理基准上的表现都优于未使用MPO的模型。值得注意的是,MPO使用的训练数据是SFT数据集的一个子集,这说明模型性能提升主要来自优化算法而非训练数据本身。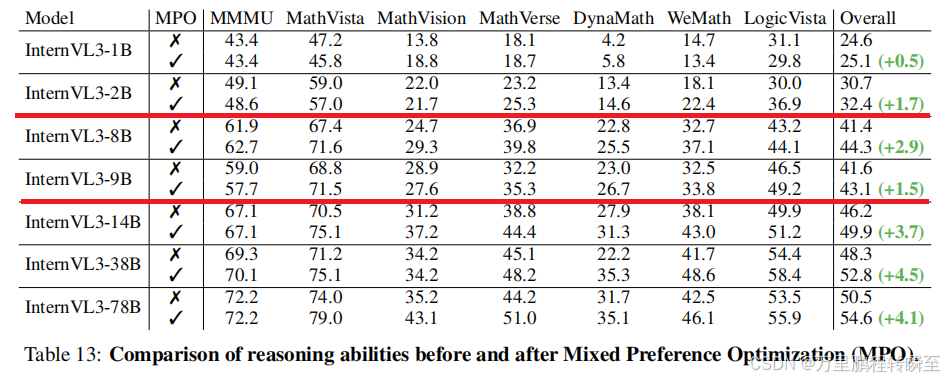
5 总结
- 介绍InternVL3(InternVL系列重大升级):实现原生多模态预训练(预训练阶段同步习得语言与多模态能力,规避传统后训练复杂优化难题)。
- 核心技术:引入可变视觉位置编码(支持更长多模态上下文)、结合有监督微调与混合偏好优化等先进后训练策略、采用测试阶段缩放方案。
- 性能表现:全品类多模态任务树立开源模型新标杆,保留强大语言能力;InternVL3-78B在MMMU基准测试中72.2,超越现有开源多模态大语言模型,显著缩小与闭源旗舰模型的性能差距。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)