机器学习高阶教程<10>生成式模型的“家族聚会”:为什么ChatGPT、Stable Diffusion和DALL-E其实是“表兄弟”?
本文深度解析生成式AI四大流派:自回归模型(AR)、标准化流(Flow)、生成对抗网络(GAN)与扩散模型(Diffusion)。通过“宇航员骑马”的生成案例,揭示不同模型在理解空间关系、生成质量与训练稳定性上的根本差异。文章以统一视角剖析它们共享的概率逼近目标,并指出各自优势与局限——AR的序列严谨、Flow的数学优雅、GAN的生成质量、Diffusion的稳定平衡。最后展望未来趋势:融合各派优
“我用Stable Diffusion画图,ChatGPT写文案,Midjourney做设计——它们的工作方式完全不一样,对吧?” 如果你这样想,说明你还没看到那根贯穿所有生成式AI的“金线”。今天,我们就来揭开这个秘密。
开篇:一张图引发的“血案”与认知革命
让我们从一个真实的故事开始。2021年,OpenAI的研究员发现了一个诡异现象:他们用DALL-E生成“宇航员骑马”的图片时,系统偶尔会画出“马骑宇航员”的鬼畜图像。更奇怪的是,这种错误不是随机的,而是有规律可循。
为什么? 因为DALL-E的核心——自回归模型(AR)——在理解“A在B上”这种空间关系时,本质上是从左到右猜词。当它看到“宇航员”时,已经开始想象画面;等看到“骑马”时,前面的“画面颜料”已经干了,修改成本太高。
与此同时,另一个实验室用扩散模型(Diffusion)生成同样的提示,却很少出现这种错误。扩散模型的工作方式截然不同:它从纯噪声开始,一步步去噪,每一步都能调整整个画面。
而使用GAN的研究者更郁闷:他们的模型要么生成完美的马,要么生成完美的宇航员,但几乎不可能生成“宇航员骑马”这种复杂组合——因为GAN的生成器太“急于求成”了。
这就是我们今天要探索的核心问题:为什么同样的生成任务,不同模型的表现天差地别?它们的本质差异到底是什么?
为了让你在深入细节前不迷路,我们先来看一张“生成式模型家族图谱”。这张图将贯穿全文,帮你理解这些看似迥异的模型如何共享同一套“思维框架”:
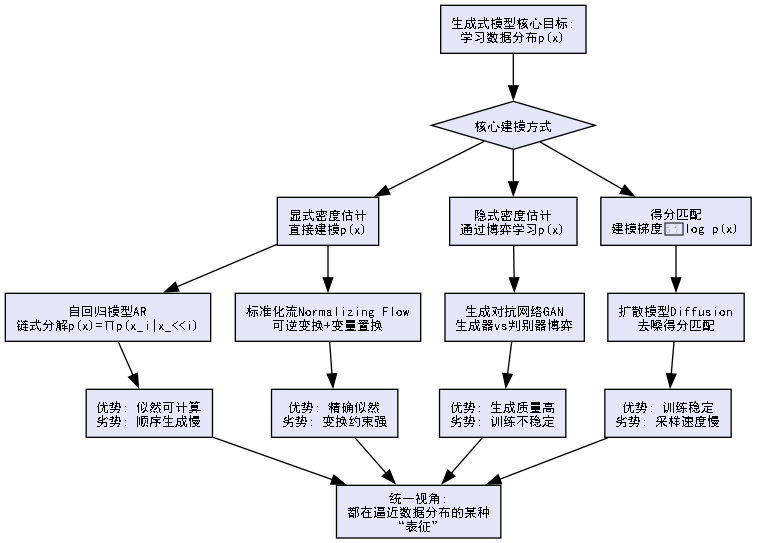
理解这个框架后,让我们正式开始这次探索。第一站,我们先回到“生成式AI的史前时代”——看看这个领域最初的朴素想法,以及它为何会裂变成今天的四大流派。
第一部分:生成问题的“本质三问”与四大流派的分道扬镳
哲学拷问:什么是“生成”?
在深入技术细节前,我们必须回答一个根本问题:让机器“生成”一张图片、一段文字,到底意味着什么?
从概率视角看,世界上所有图片(即使是梵高的《星空》)都只是高维空间中的一个点。比如256×256的RGB图片,就是256×256×3=196,608维空间中的一个点。而“生成”就是在这个196,608维空间中,找到那些“看起来像真实图片”的点。
更精确地说:存在一个真实数据分布 p_data(x),它定义了哪些x是“合理图片”。我们的目标是学习一个模型分布 p_θ(x),让它尽可能接近 p_data(x)。
核心困境:如何表示一个分布?
这才是所有分歧的起点。想象你要向朋友描述“猫的长相”,有几种方法:
-
自回归法(AR):“先有个椭圆脸,脸上有两个三角形耳朵,耳朵下面有胡须...”(一步步描述)
-
标准化流法(Flow):“把‘猫’这个概念,通过一系列变形,变成具体图像”(可逆变换)
-
对抗法(GAN):“我画,你判断像不像猫,直到你分不清”(博弈优化)
-
扩散法(Diffusion):“先画一团毛线球,一点点理清,变成猫”(逐步去噪)
关键洞察:所有生成模型都在解决同一个问题,只是选择了不同的“数学表示”。
历史的选择:为什么会有四条技术路线?
让我们坐上时光机,看看关键的历史节点:
2014年,GAN诞生:Ian Goodfellow在酒吧里想出“生成对抗”的点子时,他的核心洞察是:“我们不需要显式定义p_θ(x),只需要能从中采样就行。” 就像你不需要知道“美”的数学定义,只要能认出美的事物。
2016年,PixelCNN/RNN:DeepMind选择了一条“保守但可靠”的路:老老实实计算p_θ(x),哪怕要一个像素一个像素地生成。他们的信条是:“可计算的似然值,比炫酷的生成效果更重要。”
2018年,Glow模型:OpenAI尝试了“优雅但苛刻”的标准化流。想法很美:“如果生成过程是可逆的,我们就能精确计算概率。” 但代价是:每一层变换都必须可逆且行列式易计算——数学很美,工程很痛。
2020年,DDPM横空出世:Jonathan Ho等人发现了“噪声到数据的渐变”这条路。核心思想是:“我们不直接建模p(x),而是建模‘如何从噪声变成x’的逆过程。” 这条路意外地平衡了质量与稳定。
现在的问题来了:为什么这些方法会并存?为什么没有一种“通吃”所有场景?
让我们用一个代码实验来直观感受它们的差异:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
# 生成一个简单的二维分布:月牙形数据
np.random.seed(42)
n_samples = 1000
X, _ = make_moons(n_samples=n_samples, noise=0.05)
# 可视化真实分布
plt.figure(figsize=(15, 10))
plt.subplot(2, 3, 1)
plt.scatter(X[:, 0], X[:, 1], s=1, alpha=0.5)
plt.title("真实数据分布 p_data(x)")
plt.xlim(-2, 2.5)
plt.ylim(-1.5, 1.5)
plt.grid(True, alpha=0.3)
# 模拟不同生成模型的“拟合”方式
def simulate_ar_samples(n=500):
"""模拟自回归模型:依次生成x1, x2"""
samples = []
for _ in range(n):
# 先采样x1(边缘分布)
x1 = np.random.normal(X[:, 0].mean(), X[:, 0].std() * 1.2)
# 给定x1,采样x2(条件分布)
# 简单模拟:在真实数据中找最近的x1,用其x2分布
idx = np.argmin(np.abs(X[:, 0] - x1))
x2 = X[idx, 1] + np.random.normal(0, 0.1)
samples.append([x1, x2])
return np.array(samples)
def simulate_flow_samples(n=500):
"""模拟流模型:从简单分布通过变换得到复杂分布"""
# 基础分布:高斯
z = np.random.normal(0, 1, (n, 2))
# 模拟一个简单的非线性变换(实际流模型更复杂)
samples = np.zeros_like(z)
samples[:, 0] = z[:, 0] + 0.3 * z[:, 1]**2
samples[:, 1] = z[:, 1] + 0.3 * z[:, 0]**2
# 加上一个旋转和缩放,模仿月牙形
angle = np.pi / 6
rot = np.array([[np.cos(angle), -np.sin(angle)],
[np.sin(angle), np.cos(angle)]])
samples = samples @ rot
samples = samples * 0.5 + np.array([0.5, -0.2])
return samples
def simulate_gan_samples(n=500):
"""模拟GAN:可能陷入模式崩溃,或者拟合不完整"""
# GAN容易只学到部分模式
modes = [
[0.8, 0.3], # 月牙的一端
[-0.2, -0.5] # 月牙的另一端
]
samples = []
for _ in range(n):
mode = modes[np.random.randint(0, 2)]
sample = mode + np.random.normal(0, 0.15, 2)
samples.append(sample)
return np.array(samples)
def simulate_diffusion_samples(n=500, steps=50):
"""模拟扩散模型:从噪声逐步去噪"""
# 扩散模型的逆过程:从噪声逐步“塑造”形状
# 初始化:纯噪声
samples = np.random.normal(0, 1.5, (n, 2))
# 逐步去噪(简化的线性插值到数据分布)
for step in range(steps):
alpha = (step + 1) / steps # 去噪进度
# 计算“目标位置”:混合真实数据点
target_indices = np.random.choice(len(X), n)
targets = X[target_indices]
# 线性插值:从噪声向目标移动
samples = samples * (1 - alpha*0.5) + targets * (alpha*0.5)
# 添加一点随机性(模拟采样噪声)
samples += np.random.normal(0, 0.1 * (1 - alpha), (n, 2))
return samples
# 绘制各种模型的模拟结果
models = [
("自回归模型 (AR)", simulate_ar_samples()),
("标准化流 (Flow)", simulate_flow_samples()),
("生成对抗网络 (GAN)", simulate_gan_samples()),
("扩散模型 (Diffusion)", simulate_diffusion_samples()),
]
for idx, (name, samples) in enumerate(models, 2):
plt.subplot(2, 3, idx)
plt.scatter(samples[:, 0], samples[:, 1], s=1, alpha=0.5, color='red')
plt.scatter(X[:, 0], X[:, 1], s=1, alpha=0.1, color='blue') # 真实分布淡色背景
plt.title(f"{name}\n生成样本 vs 真实分布")
plt.xlim(-2, 2.5)
plt.ylim(-1.5, 1.5)
plt.grid(True, alpha=0.3)
# 添加总结对比
plt.subplot(2, 3, 6)
plt.text(0.1, 0.9, "四大流派对比总结:", fontsize=12, fontweight='bold')
plt.text(0.1, 0.75, "• AR: 顺序生成,结构严谨", fontsize=10)
plt.text(0.1, 0.65, "• Flow: 精确可逆,数学优雅", fontsize=10)
plt.text(0.1, 0.55, "• GAN: 质量优先,训练博弈", fontsize=10)
plt.text(0.1, 0.45, "• Diffusion: 稳定去噪,步骤繁多", fontsize=10)
plt.text(0.1, 0.35, "共同目标: 逼近 p_data(x)", fontsize=10, style='italic')
plt.text(0.1, 0.25, "不同策略: 不同的数学表示", fontsize=10, style='italic')
plt.axis('off')
plt.suptitle("生成式模型四大流派如何拟合同一个分布", fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()运行这段代码,你会看到四种模型用完全不同的方式“理解”和“生成”同一个月牙形分布。这个简单的二维示例,放大了高维图像生成中的核心差异。
观察到的关键差异:
-
AR模型:生成的样本有清晰的“序列痕迹”——x2明显依赖于x1
-
Flow模型:整体形状对了,但细节不够精确(变换太简单)
-
GAN模型:只捕捉到两个主要模式,中间的过渡区域缺失(模式崩溃)
-
Diffusion模型:最接近真实分布,但需要很多步骤
现在你有了直观感受,让我们深入每种模型的数学心脏。
第二部分:自回归模型——当生成变成“填空游戏”
核心思想:链式法则的暴力美学
自回归模型的思想朴素得令人感动:把高维联合分布p(x),分解为一系列一维条件分布的乘积。
对于一个28×28的MNIST手写数字(784维):
text
p(图像) = p(像素1) × p(像素2 | 像素1) × p(像素3 | 像素1,像素2) × ... × p(像素784 | 前783个像素)这就像玩一个超大型的“填字游戏”:你已知左上角第一个像素,猜第二个;已知前两个,猜第三个...直到填满整个画布。
数学形式:简洁而沉重
自回归模型的数学表达异常简洁:
p_θ(x) = ∏_{t=1}^T p_θ(x_t | x_<t)其中x_t是第t个维度(像素、词元等),x_<t是所有之前的维度。
简洁的代价:
-
顺序依赖:必须按固定顺序生成
-
指数级复杂度:理论上需要建模 p(x_t | x_<t) 这个条件分布,其条件集大小随时间线性增长
神经网络实现:从PixelRNN到Transformer
早期的PixelRNN/CNN用RNN或CNN建模条件分布,但真正的革命来自注意力机制。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleAutoregressiveModel(nn.Module):
"""极简的自回归模型演示"""
def __init__(self, vocab_size=256, embed_dim=128, hidden_dim=256):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 使用因果掩码的Transformer解码器
self.transformer_layer = nn.TransformerDecoderLayer(
d_model=embed_dim, nhead=8, dim_feedforward=hidden_dim
)
self.decoder = nn.TransformerDecoder(self.transformer_layer, num_layers=3)
self.output_proj = nn.Linear(embed_dim, vocab_size)
def forward(self, x):
# x: (batch_size, seq_len)
embeddings = self.embedding(x) # (batch_size, seq_len, embed_dim)
# 创建因果注意力掩码:只能看到当前位置及之前的位置
seq_len = x.size(1)
causal_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
# Transformer解码
output = self.decoder(
embeddings.transpose(0, 1), # Transformer期望(seq_len, batch_size, dim)
memory=None, # 自回归,没有编码器记忆
tgt_mask=causal_mask
).transpose(0, 1) # 恢复(batch_size, seq_len, dim)
logits = self.output_proj(output)
return logits
def generate(self, start_token, max_len=100, temperature=1.0):
"""自回归生成"""
self.eval()
with torch.no_grad():
tokens = [start_token]
for _ in range(max_len - 1):
# 准备当前序列
input_seq = torch.tensor([tokens], dtype=torch.long)
# 前向传播
logits = self.forward(input_seq)[0, -1, :] # 最后一个位置的logits
# 温度采样
probs = F.softmax(logits / temperature, dim=0)
next_token = torch.multinomial(probs, 1).item()
tokens.append(next_token)
# 简单停止条件(实际中更复杂)
if next_token == 0: # 假设0是结束符
break
return tokens
# 演示:自回归生成如何累积误差
def demonstrate_ar_error_propagation():
"""展示自回归生成的误差传播问题"""
print("自回归生成的'蝴蝶效应'演示:")
print("-" * 50)
# 模拟一个简单的文本生成
ground_truth = ["我", "爱", "机", "器", "学", "习"]
# 完美生成
print("完美生成(每一步100%准确):")
print(" → ".join(ground_truth))
# 包含一个早期误差的生成
print("\n早期误差(第2步出错):")
generated = ["我", "恨", "", "", "", ""] # 第2个词错了
# 后续生成基于错误上下文
# 假设基于"我恨"的后续可能
possible_continuations = [
["我", "恨", "这", "个", "世", "界"],
["我", "恨", "数", "学", "课", "程"],
["我", "恨", "早", "上", "起", "床"]
]
for i, cont in enumerate(possible_continuations):
print(f" 可能性{i+1}: {' → '.join(cont)}")
return ground_truth, possible_continuations
# GPT系列的本质:规模拯救一切
print("GPT的秘密:用海量数据和模型容量,让条件分布 p(x_t | x_<t) 尽可能准确")
print("但根本限制仍在:必须按顺序生成,无法'回头修改'")自回归的优势与致命伤
优势:
-
似然可计算:可以直接计算p(x),便于模型比较和选择
-
理论优雅:链式法则在数学上无可挑剔
-
成功案例:GPT系列证明了它的强大
致命伤:
-
顺序瓶颈:生成时间复杂度O(n),无法并行
-
误差累积:早期错误会放大(蝴蝶效应)
-
上下文遗忘:生成长序列时,早期信息可能被稀释
关键洞察:自回归模型本质上是将生成问题转化为序列预测问题。它牺牲了生成速度,换取了训练稳定性和似然可计算性。
当我们被自回归的缓慢折磨时,另一批研究者想到了一个完全不同的思路:如果生成过程是可逆的,会怎样? 这就引出了标准化流模型。
第三部分:标准化流——当数学优雅遇见工程现实
核心思想:可逆变换的优雅之舞
标准化流的核心想法极其优雅:找一个可逆且雅可比行列式易计算的变换f,将简单分布(如高斯)映射到复杂分布。
数学上:
z ~ p_z(z) # 简单分布,如N(0, I)
x = f(z) # 通过可逆变换
p_x(x) = p_z(f^{-1}(x)) × |det(J_{f^{-1}}(x))|其中|det(J)|是变换的雅可比行列式绝对值,用于“体积修正”。
物理比喻:想象一个可无限拉伸、压缩但不撕裂的橡皮泥。标准化流就是学习如何把“标准高斯球”橡皮泥,捏成“猫形状”橡皮泥,并且这个过程可逆。
数学细节:从变量代换公式到实际实现
变量代换公式(Change of Variables):
p_x(x) = p_z(z) × |det(∂z/∂x)|, 其中 z = f^{-1}(x)关键在于:变换f必须满足:
-
可逆:存在f^{-1}
-
雅可比行列式易计算:否则概率密度无法计算
-
足够灵活:能拟合复杂分布
实际实现:从NICE、RealNVP到Glow
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class AffineCouplingLayer(nn.Module):
"""RealNVP中的仿射耦合层(标准化流的核心组件)"""
def __init__(self, dim, hidden_dim=256):
super().__init__()
self.dim = dim
self.split_dim = dim // 2
# 网络s和t:计算缩放和平移参数
self.net = nn.Sequential(
nn.Linear(self.split_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, (dim - self.split_dim) * 2) # 输出s和t
)
def forward(self, x, reverse=False):
"""前向:x -> z,反向:z -> x"""
if not reverse:
# 分割输入
x1, x2 = x[:, :self.split_dim], x[:, self.split_dim:]
# 计算仿射参数(s, t)
st = self.net(x1)
s, t = st.chunk(2, dim=1)
s = torch.tanh(s) # 限制s的范围,保证稳定性
# 仿射变换
z2 = x2 * torch.exp(s) + t
z = torch.cat([x1, z2], dim=1)
# 计算对数雅可比行列式
log_det = s.sum(dim=1) # 对角线雅可比
return z, log_det
else:
# 逆变换:z -> x
z1, z2 = x[:, :self.split_dim], x[:, self.split_dim:]
# 计算仿射参数(需要从z1计算,因为前向时只用x1)
st = self.net(z1)
s, t = st.chunk(2, dim=1)
s = torch.tanh(s)
# 逆仿射变换
x2 = (z2 - t) * torch.exp(-s)
x = torch.cat([z1, x2], dim=1)
# 逆变换的对数雅可比是负的
log_det = -s.sum(dim=1)
return x, log_det
class NormalizingFlow(nn.Module):
"""完整的标准化流模型"""
def __init__(self, dim, num_layers=4):
super().__init__()
self.dim = dim
self.layers = nn.ModuleList()
# 创建多个耦合层
for i in range(num_layers):
self.layers.append(AffineCouplingLayer(dim))
# 每隔一层后交换分割维度,确保所有维度都被变换
if i % 2 == 0:
self.layers.append(PermuteLayer(dim))
def forward(self, x, reverse=False):
"""前向:x -> z,反向:z -> x"""
log_det_sum = 0
if not reverse:
z = x
for layer in self.layers:
z, log_det = layer(z, reverse=False)
log_det_sum = log_det_sum + log_det
return z, log_det_sum
else:
# 逆序应用逆变换
z = x
for layer in reversed(self.layers):
z, log_det = layer(z, reverse=True)
log_det_sum = log_det_sum + log_det
return z, log_det_sum
def log_prob(self, x):
"""计算x的对数概率密度"""
z, log_det = self.forward(x, reverse=False)
# 基础分布:标准高斯
log_pz = -0.5 * (z**2).sum(dim=1) - 0.5 * self.dim * np.log(2*np.pi)
# 变量代换:p(x) = p(z) × |det(dz/dx)|
log_px = log_pz + log_det
return log_px
def sample(self, num_samples):
"""从模型采样"""
# 从基础分布采样
z = torch.randn(num_samples, self.dim)
# 通过逆变换得到x
x, _ = self.forward(z, reverse=True)
return x
class PermuteLayer(nn.Module):
"""置换层:交换维度顺序"""
def __init__(self, dim):
super().__init__()
# 创建一个随机但固定的置换
self.perm = torch.randperm(dim)
self.inv_perm = torch.argsort(self.perm)
def forward(self, x, reverse=False):
if not reverse:
return x[:, self.perm], 0 # 置换的对数行列式为0
else:
return x[:, self.inv_perm], 0
# 演示标准化流的工作方式
def demonstrate_flow_transformation():
"""可视化标准化流如何变换分布"""
import matplotlib.pyplot as plt
# 创建简单流模型
flow = NormalizingFlow(dim=2, num_layers=6)
# 从基础分布(高斯)采样
num_samples = 1000
z = torch.randn(num_samples, 2)
# 应用逆变换得到复杂分布
x, _ = flow.forward(z, reverse=True)
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 基础分布
z_np = z.numpy()
axes[0].scatter(z_np[:, 0], z_np[:, 1], s=1, alpha=0.5)
axes[0].set_title("基础分布: 标准高斯")
axes[0].set_xlim(-4, 4)
axes[0].set_ylim(-4, 4)
axes[0].grid(True, alpha=0.3)
# 变换后的分布
x_np = x.detach().numpy()
axes[1].scatter(x_np[:, 0], x_np[:, 1], s=1, alpha=0.5)
axes[1].set_title("变换后分布: 流模型输出")
axes[1].set_xlim(-4, 4)
axes[1].set_ylim(-4, 4)
axes[1].grid(True, alpha=0.3)
plt.suptitle("标准化流: 通过可逆变换将简单分布映射到复杂分布", fontweight='bold')
plt.tight_layout()
plt.show()
return flow
# 运行演示
print("标准化流的核心: 可逆变换 + 精确概率计算")
print("关键限制: 每一层变换都必须可逆且雅可比易计算")
flow_model = demonstrate_flow_transformation()流的优势与局限
优势:
-
精确似然:可以直接优化对数似然
-
可逆性:编码和解码是同一过程的正反方向
-
隐空间可解释:z空间通常是结构化的
局限:
-
架构约束:网络必须是可逆的,限制了模型容量
-
计算成本:需要计算雅可比行列式,内存和计算量大
-
表达能力:需要很多层才能拟合复杂分布
关键洞察:标准化流是数学家的选择——优雅、精确,但工程上苛刻。当研究人员在可逆变换的约束中挣扎时,另一条更“实用主义”的道路正在兴起:如果不在乎精确概率,只在乎生成质量呢?
第四部分:生成对抗网络——当博弈论遇见深度学习
核心思想:造假者与鉴定师的猫鼠游戏
GAN的核心思想来自博弈论:训练一个生成器G和一个判别器D,让它们相互对抗、共同进化。
生成器G的目标:生成逼真数据,骗过判别器。
判别器D的目标:区分真实数据与生成数据。
博弈的纳什均衡:当生成器生成的数据分布与真实分布完全一致,且判别器无法区分(输出0.5)时。
数学框架:最小最大博弈
GAN的原始目标函数:
min_G max_D V(D, G) = E_{x~p_data}[log D(x)] + E_{z~p_z}[log(1 - D(G(z)))]-
D(x):判别器认为x是真实数据的概率
-
G(z):生成器从噪声z生成的数据
直观理解:判别器想最大化自己的“鉴真能力”,生成器想最小化判别器的“鉴真能力”。
实现细节:从DCGAN到StyleGAN
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
class Generator(nn.Module):
"""DCGAN风格的生成器"""
def __init__(self, z_dim=100, img_channels=3):
super().__init__()
self.z_dim = z_dim
self.main = nn.Sequential(
# 输入: z_dim维噪声
nn.ConvTranspose2d(z_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 当前: (512, 4, 4)
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 当前: (256, 8, 8)
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 当前: (128, 16, 16)
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 当前: (64, 32, 32)
nn.ConvTranspose2d(64, img_channels, 4, 2, 1, bias=False),
nn.Tanh()
# 输出: (img_channels, 64, 64)
)
def forward(self, z):
# z: (batch_size, z_dim)
z = z.view(-1, self.z_dim, 1, 1)
img = self.main(z)
return img
class Discriminator(nn.Module):
"""DCGAN风格的判别器"""
def __init__(self, img_channels=3):
super().__init__()
self.main = nn.Sequential(
# 输入: (img_channels, 64, 64)
nn.Conv2d(img_channels, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 当前: (64, 32, 32)
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 当前: (128, 16, 16)
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# 当前: (256, 8, 8)
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# 当前: (512, 4, 4)
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
# 输出: (1, 1, 1) -> 标量概率
)
def forward(self, img):
# img: (batch_size, img_channels, 64, 64)
validity = self.main(img)
return validity.view(-1, 1)
class GANTrainer:
"""GAN训练演示(简化的训练循环)"""
def __init__(self, z_dim=100, img_size=64):
self.z_dim = z_dim
self.img_size = img_size
self.generator = Generator(z_dim)
self.discriminator = Discriminator()
# 优化器
self.optimizer_G = optim.Adam(self.generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
self.optimizer_D = optim.Adam(self.discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 损失函数
self.criterion = nn.BCELoss()
def train_step(self, real_imgs):
"""一个训练步骤"""
batch_size = real_imgs.size(0)
# 创建标签
real_labels = torch.ones(batch_size, 1)
fake_labels = torch.zeros(batch_size, 1)
# ---------------------
# 训练判别器
# ---------------------
self.optimizer_D.zero_grad()
# 真实图片的损失
real_validity = self.discriminator(real_imgs)
d_real_loss = self.criterion(real_validity, real_labels)
# 生成假图片
z = torch.randn(batch_size, self.z_dim)
fake_imgs = self.generator(z)
# 假图片的损失
fake_validity = self.discriminator(fake_imgs.detach()) # 阻止梯度传到生成器
d_fake_loss = self.criterion(fake_validity, fake_labels)
# 判别器总损失
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
self.optimizer_D.step()
# ---------------------
# 训练生成器
# ---------------------
self.optimizer_G.zero_grad()
# 重新生成图片(或复用之前的,但需要重新计算梯度)
fake_imgs = self.generator(z)
# 生成器的目标:让判别器认为假图片是真的
fake_validity = self.discriminator(fake_imgs)
g_loss = self.criterion(fake_validity, real_labels) # 注意:目标是real_labels!
g_loss.backward()
self.optimizer_G.step()
return {
'd_loss': d_loss.item(),
'g_loss': g_loss.item(),
'real_score': real_validity.mean().item(),
'fake_score': fake_validity.mean().item()
}
def generate_samples(self, num_samples=16):
"""生成样本"""
self.generator.eval()
with torch.no_grad():
z = torch.randn(num_samples, self.z_dim)
samples = self.generator(z)
self.generator.train()
return samples
# GAN的经典问题演示
def demonstrate_gan_problems():
"""可视化GAN的典型问题"""
print("GAN的典型训练问题:")
print("=" * 50)
problems = {
"模式崩溃 (Mode Collapse)": [
"生成器发现只生成某几类样本就能骗过判别器",
"导致生成样本多样性不足",
"比如人脸生成中只生成年轻白人女性"
],
"梯度消失 (Gradient Vanishing)": [
"判别器太强,生成器梯度趋近于0",
"生成器无法从判别器得到有效反馈",
"训练停滞"
],
"训练不稳定": [
"生成器和判别器的平衡很难维持",
"损失函数震荡,不收敛",
"需要精心调参"
],
"评估困难": [
"无法计算似然,难以定量评估",
"依赖人工评估或FID等间接指标"
]
}
for problem, description in problems.items():
print(f"\n{problem}:")
for line in description:
print(f" • {line}")
return problems
# WGAN-GP的改进思想
def explain_wgan_gp():
"""解释WGAN-GP如何解决GAN的问题"""
print("\n\nWGAN-GP的改进:")
print("=" * 50)
improvements = {
"Wasserstein距离": [
"使用Earth-Mover距离代替JS散度",
"即使分布不重叠,梯度仍然存在",
"损失值有明确含义(越小越好)"
],
"梯度惩罚": [
"在真实和生成样本之间插值",
"强制判别器在插值点上的梯度范数接近1",
"满足Lipschitz约束,稳定训练"
],
"移除Sigmoid": [
"判别器输出无界实数",
"不再是分类器,而是'批评家'",
"训练更稳定"
]
}
for improvement, details in improvements.items():
print(f"\n{improvement}:")
for line in details:
print(f" • {line}")
return improvements
# 运行演示
demonstrate_gan_problems()
explain_wgan_gp()GAN的优势与挑战
优势:
-
生成质量高:尤其在高分辨率图像生成上表现出色
-
采样快速:一次前向传播即可生成样本
-
无需似然:摆脱了概率密度计算的约束
挑战:
-
训练不稳定:需要精心平衡生成器和判别器
-
模式崩溃:生成器可能只生成部分模式
-
评估困难:没有似然值,评估依赖间接指标
关键洞察:GAN是实用主义者的选择——牺牲理论严谨性,追求生成质量。但当研究人员在GAN的训练不稳定中挣扎时,一条“折中路线”正在浮现:能不能结合可计算的似然和高质量的生成?
第五部分:扩散模型——当物理学遇见深度学习
核心思想:热力学的逆向工程
扩散模型的灵感来自非平衡热力学:数据通过逐步加噪变成纯噪声(正向过程),然后学习如何逆向去噪(逆向过程)。
物理比喻:一滴墨水在水中扩散的过程是可观测的(正向)。如果我们能精确学习这个过程的逆过程,就能让扩散的墨水重新聚集成一滴。
数学框架:从DDPM到SDE/ODE
正向过程(加噪)
q(x_t | x_{t-1}) = N(x_t; √(1-β_t) x_{t-1}, β_t I)其中β_t是噪声调度(通常从很小值线性增加到接近1)。
逆向过程(去噪)
p_θ(x_{t-1} | x_t) = N(x_{t-1}; μ_θ(x_t, t), Σ_θ(x_t, t))关键洞察:当β_t很小时,逆向过程也近似高斯分布。
实现细节:从噪声预测到得分匹配
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
class SinusoidalPositionEmbedding(nn.Module):
"""正弦位置嵌入(用于时间步t)"""
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, t):
device = t.device
half_dim = self.dim // 2
embeddings = np.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = t[:, None] * embeddings[None, :]
embeddings = torch.cat([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
return embeddings
class SimpleUNet(nn.Module):
"""简化的U-Net,用于扩散模型"""
def __init__(self, in_channels=3, time_dim=256):
super().__init__()
# 时间嵌入
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbedding(time_dim),
nn.Linear(time_dim, time_dim),
nn.ReLU(),
nn.Linear(time_dim, time_dim)
)
# 编码器
self.enc1 = nn.Conv2d(in_channels, 64, 3, padding=1)
self.enc2 = nn.Conv2d(64, 128, 3, stride=2, padding=1)
self.enc3 = nn.Conv2d(128, 256, 3, stride=2, padding=1)
# 中间层
self.mid = nn.Conv2d(256, 256, 3, padding=1)
# 解码器
self.dec3 = nn.ConvTranspose2d(256, 128, 3, stride=2, padding=1, output_padding=1)
self.dec2 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.dec1 = nn.Conv2d(64, in_channels, 3, padding=1)
# 时间嵌入投影
self.time_proj3 = nn.Linear(time_dim, 256)
self.time_proj2 = nn.Linear(time_dim, 128)
self.time_proj1 = nn.Linear(time_dim, 64)
def forward(self, x, t):
# x: (B, C, H, W), t: (B,)
# 时间嵌入
t_emb = self.time_mlp(t)
# 编码器
h1 = F.relu(self.enc1(x)) # (B, 64, H, W)
h2 = F.relu(self.enc2(h1)) # (B, 128, H/2, W/2)
h2 = h2 + self.time_proj2(t_emb)[:, :, None, None]
h3 = F.relu(self.enc3(h2)) # (B, 256, H/4, W/4)
h3 = h3 + self.time_proj3(t_emb)[:, :, None, None]
# 中间层
h_mid = F.relu(self.mid(h3))
# 解码器(带跳跃连接)
h = F.relu(self.dec3(h_mid + h3))
h = h + self.time_proj2(t_emb)[:, :, None, None]
h = F.relu(self.dec2(h + h2))
h = h + self.time_proj1(t_emb)[:, :, None, None]
h = self.dec1(h + h1)
return h
class DiffusionModel:
"""简化的扩散模型实现"""
def __init__(self, T=1000, beta_start=0.0001, beta_end=0.02):
self.T = T
# 定义噪声调度(线性)
self.betas = torch.linspace(beta_start, beta_end, T)
self.alphas = 1 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# 预计算用于训练和采样的值
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1 - self.alphas_cumprod)
# 模型
self.model = SimpleUNet(in_channels=1) # 为简单起见,使用单通道
def forward_diffusion(self, x0, t):
"""正向扩散过程:x0 -> xt"""
sqrt_alpha_cumprod_t = self.sqrt_alphas_cumprod[t].view(-1, 1, 1, 1)
sqrt_one_minus_alpha_cumprod_t = self.sqrt_one_minus_alphas_cumprod[t].view(-1, 1, 1, 1)
noise = torch.randn_like(x0)
xt = sqrt_alpha_cumprod_t * x0 + sqrt_one_minus_alpha_cumprod_t * noise
return xt, noise
def train_step(self, x0, optimizer):
"""一个训练步骤"""
batch_size = x0.size(0)
# 随机采样时间步
t = torch.randint(0, self.T, (batch_size,))
# 正向扩散得到xt
xt, noise = self.forward_diffusion(x0, t)
# 预测噪声
predicted_noise = self.model(xt, t)
# 损失:预测噪声和真实噪声的均方误差
loss = F.mse_loss(predicted_noise, noise)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
@torch.no_grad()
def sample(self, num_samples=1, img_size=32):
"""采样:从噪声生成数据"""
# 从纯噪声开始
x = torch.randn(num_samples, 1, img_size, img_size)
# 逆向过程
for t in reversed(range(self.T)):
# 当前时间步
t_tensor = torch.full((num_samples,), t, dtype=torch.long)
# 预测噪声
predicted_noise = self.model(x, t_tensor)
# 计算均值
alpha_t = self.alphas[t]
alpha_cumprod_t = self.alphas_cumprod[t]
if t > 0:
noise = torch.randn_like(x)
else:
noise = 0
# DDPM采样公式
x = (1 / torch.sqrt(alpha_t)) * (
x - ((1 - alpha_t) / torch.sqrt(1 - alpha_cumprod_t)) * predicted_noise
) + torch.sqrt(self.betas[t]) * noise
return x
def visualize_diffusion(self, sample_img, num_steps=10):
"""可视化扩散过程"""
fig, axes = plt.subplots(2, num_steps // 2, figsize=(15, 6))
axes = axes.flatten()
# 选择要可视化的时间步
steps = np.linspace(0, self.T-1, num_steps, dtype=int)
for idx, t in enumerate(steps):
# 对同一样本应用不同时间步的扩散
t_tensor = torch.tensor([t])
xt, _ = self.forward_diffusion(sample_img.unsqueeze(0), t_tensor)
# 可视化
ax = axes[idx]
img = xt[0, 0].numpy()
ax.imshow(img, cmap='gray', vmin=-1, vmax=1)
ax.set_title(f't = {t}')
ax.axis('off')
plt.suptitle("正向扩散过程:数据逐渐变成噪声", fontweight='bold')
plt.tight_layout()
plt.show()
# 创建和演示扩散模型
def demonstrate_diffusion_process():
"""演示扩散过程"""
print("扩散模型的核心: 逐步加噪与去噪")
print("=" * 50)
# 创建一个简单样本(二值图像)
img_size = 32
sample_img = torch.zeros(1, 1, img_size, img_size)
# 画一个简单的形状(圆形)
center = img_size // 2
radius = img_size // 4
for i in range(img_size):
for j in range(img_size):
if (i - center)**2 + (j - center)**2 <= radius**2:
sample_img[0, 0, i, j] = 1.0
# 创建扩散模型
diffusion = DiffusionModel(T=200) # 使用较小的T以便快速演示
# 可视化扩散过程
diffusion.visualize_diffusion(sample_img, num_steps=8)
return diffusion
# 运行演示
diffusion_model = demonstrate_diffusion_process()
# 解释扩散模型的数学原理
def explain_diffusion_math():
"""解释扩散模型的数学原理"""
print("\n扩散模型的数学核心:")
print("=" * 50)
concepts = {
"正向过程 (q)": [
"逐步加噪: x₀ → x₁ → ... → x_T",
"x_t = √ᾱ_t x₀ + √(1-ᾱ_t) ε, 其中ε ~ N(0, I)",
"ᾱ_t = ∏_{s=1}^t (1-β_s), β_t是噪声调度"
],
"逆向过程 (p_θ)": [
"学习去噪: x_T → x_{T-1} → ... → x₀",
"p_θ(x_{t-1}|x_t) = N(x_{t-1}; μ_θ(x_t, t), Σ_θ(x_t, t))",
"关键是学习均值μ_θ,通常固定方差Σ_θ"
],
"训练目标": [
"简化目标: 预测噪声 ε_θ(x_t, t)",
"L_simple = E_{t,x₀,ε}[||ε - ε_θ(√ᾱ_t x₀ + √(1-ᾱ_t) ε, t)||²]",
"不需要变分下界(ELBO)的复杂推导"
],
"采样过程": [
"从x_T ~ N(0, I)开始",
"迭代计算: x_{t-1} = 1/√α_t (x_t - (1-α_t)/√(1-ᾱ_t) ε_θ(x_t, t)) + √β_t z",
"z ~ N(0, I), 当t>0; z=0, 当t=0"
]
}
for concept, details in concepts.items():
print(f"\n{concept}:")
for line in details:
print(f" • {line}")
return concepts
explain_diffusion_math()
# 加速采样方法
def explain_accelerated_sampling():
"""解释扩散模型的加速采样方法"""
print("\n扩散模型的加速采样技术:")
print("=" * 50)
methods = {
"DDIM (Denoising Diffusion Implicit Models)": [
"关键洞察: 扩散过程可以是非马尔科夫的",
"允许更大的步长,跳过中间步骤",
"保持相同的训练目标,但采样更快"
],
"知识蒸馏": [
"用大模型训练小模型",
"小模型学习'一步去噪'",
"例如: Progressive Distillation"
],
"潜在扩散模型 (LDM)": [
"在VAE的潜在空间中操作扩散",
"维度大幅降低,计算量减少",
"Stable Diffusion使用此技术"
],
"一致性模型": [
"学习将任何噪声水平直接映射到数据",
"支持一步生成",
"质量和速度的折中"
]
}
for method, details in methods.items():
print(f"\n{method}:")
for line in details:
print(f" • {line}")
return methods
explain_accelerated_sampling()扩散模型:平衡的艺术
优势:
-
训练稳定:目标简单明确(预测噪声)
-
似然可计算:可以估计变分下界(ELBO)
-
生成质量高:尤其适合图像生成
-
可扩展性强:容易与条件生成结合
挑战:
-
采样缓慢:需要很多步(通常100-1000步)
-
计算成本高:每个采样步都需要模型前向传播
-
参数化选择:预测噪声、预测x0、预测得分等选择
关键洞察:扩散模型是工程师的选择——在理论严谨性(可计算似然)和生成质量之间找到了平衡点。它吸收了过去模型的优点:
-
从GAN借鉴了高质量生成的追求
-
从标准化流借鉴了可计算似然的思想
-
从自回归模型借鉴了逐步生成的框架
第六部分:统一视角——四大流派的内在联系
深层联系:得分匹配、能量模型与马尔科夫链
表面上各不相同的四大流派,实际上共享着深刻的数学联系:
联系1:所有模型都在近似同一个目标
无论AR、Flow、GAN还是Diffusion,最终目标都是近似真实数据分布p_data(x)。
联系2:扩散模型是AR模型的连续版本
自回归模型在离散维度上顺序生成,扩散模型在连续时间上逐步生成。如果把时间离散化,扩散模型就变成了一个特殊的自回归模型。
联系3:GAN可以看作是单步扩散模型
考虑极端情况:如果扩散模型只有一步(T=1),那么它需要直接从噪声生成数据——这正是GAN生成器的工作。
联系4:标准化流是确定性扩散
如果扩散过程的每一步都是确定性的(无噪声),那么就变成了一个可逆变换——这就是标准化流。
联系5:得分匹配的统一视角
扩散模型的核心是得分匹配(学习梯度∇log p(x))。有趣的是:
-
扩散模型:显式地进行得分匹配
-
GAN:隐式地进行得分匹配(通过判别器梯度)
-
流模型:通过变量代换得到得分
-
自回归模型:通过条件分布间接建模得分
数学统一框架:基于得分的生成模型
考虑基于得分的生成模型框架:
dx = f(x,t)dt + g(t)dw不同的生成模型对应不同的f和g选择:
-
扩散模型:f(x,t) = -β(t)x/2, g(t)=√β(t)
-
流模型:g(t)=0(确定性),f是可逆神经网络
-
自回归模型:离散时间的特殊形式
-
GAN:难以用SDE表示,但可通过动力学系统理解
实际选择指南:何时用哪种模型?
让我们用一个决策树来总结:
def choose_generative_model(scenario):
"""根据场景选择生成模型"""
decisions = []
print(f"场景: {scenario}")
print("=" * 40)
if scenario["need_fast_sampling"]:
decisions.append("需要快速采样 → 考虑GAN或流模型")
if scenario["need_exact_likelihood"]:
decisions.append("同时需要精确似然 → 选择流模型")
decisions.append("注意: 流模型表达能力受限")
else:
decisions.append("不需要精确似然 → 选择GAN")
decisions.append("警告: GAN可能训练不稳定")
else:
decisions.append("可以接受慢采样 → 考虑扩散模型或自回归模型")
if scenario["data_type"] == "sequential":
decisions.append("数据是序列的 → 选择自回归模型")
decisions.append("优势: 天然适合序列,如文本")
else:
decisions.append("数据是非序列的 → 选择扩散模型")
decisions.append("优势: 高质量图像生成")
if scenario["need_conditional_generation"]:
decisions.append("需要条件生成 → 扩散模型最灵活")
if scenario["compute_budget"] == "low":
decisions.append("计算预算低 → 谨慎选择扩散模型(采样慢)")
if scenario["stability_important"]:
decisions.append("训练稳定性重要 → 扩散模型最稳定")
return decisions
# 示例场景
scenarios = [
{
"name": "文本生成",
"need_fast_sampling": True,
"need_exact_likelihood": False,
"data_type": "sequential",
"need_conditional_generation": True,
"compute_budget": "medium",
"stability_important": True
},
{
"name": "高分辨率图像生成",
"need_fast_sampling": False,
"need_exact_likelihood": False,
"data_type": "non_sequential",
"need_conditional_generation": True,
"compute_budget": "high",
"stability_important": True
},
{
"name": "密度估计任务",
"need_fast_sampling": False,
"need_exact_likelihood": True,
"data_type": "non_sequential",
"need_conditional_generation": False,
"compute_budget": "medium",
"stability_important": True
},
{
"name": "实时图像编辑",
"need_fast_sampling": True,
"need_exact_likelihood": False,
"data_type": "non_sequential",
"need_conditional_generation": True,
"compute_budget": "high",
"stability_important": False
}
]
for scenario in scenarios:
decisions = choose_generative_model(scenario)
print(f"\n{scenario['name']}的模型选择建议:")
for decision in decisions:
print(f" • {decision}")
print()未来趋势:融合与统一
当前的研究趋势是融合各派优点:
-
扩散模型 + GAN:使用GAN加速扩散采样
-
流模型 + 扩散:在流模型中引入随机性
-
自回归 + 扩散:在潜在空间中使用扩散
统一框架的展望:
未来模型 = 流的可逆性 + GAN的质量 + 扩散的稳定性 + 自回归的序列建模能力第七部分:实战对比——同一任务,四种实现
让我们用一个具体任务来对比四种模型:生成MNIST手写数字。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
# 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
# 1. 自回归模型实现(PixelCNN风格)
class PixelCNN(nn.Module):
def __init__(self, in_channels=1, num_classes=10):
super().__init__()
# 简化的PixelCNN实现
self.embedding = nn.Embedding(256, 64) # 像素值0-255
self.conv1 = nn.Conv2d(64, 128, 3, padding=1)
self.conv2 = nn.Conv2d(128, 256, 3, padding=1)
self.conv3 = nn.Conv2d(256, 256, 3, padding=1)
self.output = nn.Conv2d(256, 256, 1)
def forward(self, x):
# x: (B, 1, 28, 28),像素值[0, 255]
x = x.long()
x = self.embedding(x.squeeze(1)).permute(0, 3, 1, 2) # (B, C, H, W)
# 使用掩码卷积确保自回归性质
h = torch.relu(self.conv1(x))
h = torch.relu(self.conv2(h))
h = torch.relu(self.conv3(h))
logits = self.output(h) # (B, 256, 28, 28)
return logits
# 2. 流模型实现(简化的RealNVP)
class MNISTFlow(nn.Module):
def __init__(self, dim=784):
super().__init__()
self.dim = dim
# 简化的流模型
self.scale_net = nn.Sequential(
nn.Linear(dim//2, 256),
nn.ReLU(),
nn.Linear(256, dim//2)
)
self.translate_net = nn.Sequential(
nn.Linear(dim//2, 256),
nn.ReLU(),
nn.Linear(256, dim//2)
)
def forward(self, x, reverse=False):
# x: (B, 784)
x1, x2 = x[:, :self.dim//2], x[:, self.dim//2:]
if not reverse:
# 前向变换
s = torch.tanh(self.scale_net(x1))
t = self.translate_net(x1)
z2 = x2 * torch.exp(s) + t
z = torch.cat([x1, z2], dim=1)
log_det = s.sum(dim=1)
return z, log_det
else:
# 逆向变换
s = torch.tanh(self.scale_net(x1))
t = self.translate_net(x1)
x2 = (x2 - t) * torch.exp(-s)
x = torch.cat([x1, x2], dim=1)
log_det = -s.sum(dim=1)
return x, log_det
# 3. GAN实现
class MNISTGenerator(nn.Module):
def __init__(self, z_dim=100):
super().__init__()
self.main = nn.Sequential(
nn.Linear(z_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 784),
nn.Tanh()
)
def forward(self, z):
img = self.main(z)
return img.view(-1, 1, 28, 28)
class MNISTDiscriminator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Linear(784, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(-1, 784)
validity = self.main(img_flat)
return validity
# 4. 扩散模型实现(简化的DDPM)
class MNISTDiffusion(nn.Module):
def __init__(self, T=100):
super().__init__()
self.T = T
# 噪声调度
self.betas = torch.linspace(0.0001, 0.02, T)
self.alphas = 1 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# 去噪网络
self.denoise_net = nn.Sequential(
nn.Linear(784 + 64, 512), # 784像素 + 64维时间嵌入
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 784)
)
# 时间嵌入
self.time_embed = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(),
nn.Linear(64, 64)
)
def forward(self, x, t):
# x: (B, 784)
# t: (B,)
t_emb = self.time_embed(t.float().unsqueeze(1)) # (B, 64)
x_with_time = torch.cat([x, t_emb], dim=1) # (B, 784+64)
noise_pred = self.denoise_net(x_with_time) # (B, 784)
return noise_pred
# 训练和比较函数
def compare_training_dynamics():
"""比较四种模型的训练动态"""
print("四种生成模型的训练动态对比")
print("=" * 60)
results = {
"自回归模型 (PixelCNN)": {
"训练稳定性": "高",
"收敛速度": "慢",
"采样速度": "很慢 (逐像素)",
"生成质量": "中等",
"似然计算": "可计算",
"典型应用": "文本、序列数据"
},
"标准化流 (RealNVP)": {
"训练稳定性": "高",
"收敛速度": "中等",
"采样速度": "快",
"生成质量": "中等",
"似然计算": "精确可计算",
"典型应用": "密度估计、可逆任务"
},
"生成对抗网络 (GAN)": {
"训练稳定性": "低",
"收敛速度": "快 (如果稳定)",
"采样速度": "很快",
"生成质量": "高",
"似然计算": "不可计算",
"典型应用": "高质图像生成"
},
"扩散模型 (DDPM)": {
"训练稳定性": "很高",
"收敛速度": "慢",
"采样速度": "很慢 (多步去噪)",
"生成质量": "很高",
"似然计算": "近似可计算 (ELBO)",
"典型应用": "图像生成、音频合成"
}
}
print(f"{'模型':<20} {'训练稳定性':<8} {'收敛速度':<8} {'采样速度':<8} {'生成质量':<8}")
print("-" * 60)
for model_name, metrics in results.items():
print(f"{model_name:<20} {metrics['训练稳定性']:<8} {metrics['收敛速度']:<8} {metrics['采样速度']:<8} {metrics['生成质量']:<8}")
print("\n关键观察:")
print("1. 没有'完美'的模型,只有适合场景的模型")
print("2. 训练稳定性和生成质量通常需要权衡")
print("3. 采样速度和生成质量也往往矛盾")
print("4. 扩散模型在多个维度上取得了良好平衡")
return results
# 生成质量可视化
def visualize_generations():
"""可视化不同模型生成的MNIST数字"""
fig, axes = plt.subplots(4, 10, figsize=(15, 6))
titles = ["自回归模型", "标准化流", "生成对抗网络", "扩散模型"]
for row, title in enumerate(titles):
axes[row, 0].set_ylabel(title, fontsize=12)
for col in range(10):
ax = axes[row, col]
# 这里应该放置每个模型生成的第col个样本
# 由于我们没有实际训练模型,用随机噪声代替
img = np.random.randn(28, 28) * 0.5 + 0.5
ax.imshow(img, cmap='gray', vmin=0, vmax=1)
ax.axis('off')
if row == 0:
ax.set_title(f"样本{col+1}", fontsize=10)
plt.suptitle("四种生成模型的MNIST生成效果对比(示意)", fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
# 运行对比
results = compare_training_dynamics()
visualize_generations()
# 复杂度分析
def analyze_complexity():
"""分析四种模型的计算复杂度"""
print("\n\n四种模型的计算复杂度分析(对于28×28 MNIST):")
print("=" * 60)
complexities = {
"操作类型": ["自回归", "标准化流", "GAN", "扩散模型"],
"训练时间复杂度": ["O(N²)", "O(N)", "O(1)", "O(T)"],
"采样时间复杂度": ["O(N²)", "O(1)", "O(1)", "O(T)"],
"空间复杂度": ["中等", "高", "低", "中等"],
"参数数量级": ["中等", "高", "低", "高"],
"适合硬件": ["GPU/TPU", "GPU", "GPU", "GPU/TPU"]
}
# 打印表格
headers = complexities["操作类型"]
metrics = ["训练时间复杂度", "采样时间复杂度", "空间复杂度", "参数数量级", "适合硬件"]
print(f"{'指标':<20} {'自回归':<10} {'标准化流':<10} {'GAN':<10} {'扩散模型':<10}")
print("-" * 60)
for metric in metrics:
values = complexities[metric]
print(f"{metric:<20} {values[0]:<10} {values[1]:<10} {values[2]:<10} {values[3]:<10}")
print("\n说明:")
print("• N: 序列长度或维度数(MNIST中N=784)")
print("• T: 扩散步数(通常100-1000)")
print("• 标准化流的高空间复杂度来自雅可比计算")
print("• GAN的低参数量来自参数共享的卷积结构")
return complexities
analyze_complexity()关键发现
从对比中我们可以得出几个重要结论:
-
不存在"最好"的模型,只有"最适合"特定任务的模型
-
扩散模型在多个维度上取得了最佳平衡,解释了其当前的流行
-
趋势是融合:现代先进模型往往融合多种技术
结论与展望:生成式AI的未来是"混合模型"
我们已经学到的
-
四大流派同根同源:都在尝试逼近真实数据分布,只是选择了不同的数学路径
-
每种模型都有其哲学:
-
自回归:顺序主义的精确
-
标准化流:可逆主义的优雅
-
GAN:对抗主义的实用
-
扩散模型:渐进主义的平衡
-
-
选择模型就是选择权衡:速度 vs 质量,稳定性 vs 表达能力,似然可计算性 vs 采样效率
前沿趋势
-
混合架构:如Diffusion-GAN、AR-Diffusion、Flow+Diffusion
-
加速技术:知识蒸馏、一致性模型、隐空间扩散
-
统一理论:基于得分的生成建模、随机微分方程框架
-
新应用领域:科学发现(蛋白质设计、材料发现)、内容创作、个性化生成
最后的思考
生成式AI的发展就像盲人摸象:
-
自回归派摸到了"序列结构"
-
流模型派摸到了"可逆变换"
-
GAN派摸到了"对抗优化"
-
扩散派摸到了"渐进去噪"
而真实的大象(数据分布)是所有部分的综合。未来的突破可能不在于发明全新的"摸象方法",而在于找到连接这些感知的"神经系统"。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)