CAIF-10图像分类模型训练(PyTorch Lightning手把手教程)
【第0步】代码运行环境介绍
1. 教程:使用PyTorch Lighting来实现图像分类模型
2. 环境:google colab,python 3.10;GPU和CPU都可以
3. 数据集:CIFAR10 dataset;(源代码提供自动下载功能)
4. 学习时长:10~30分钟
5. 难度:初学者
6. 源代码:见附录链接
7. 实践中,遇到任何问题,都可以在评论区留言,看到会马上回复
【第一步】安装PyTorch Lighting环境
进入colab,运行安装命
!pip install lightning
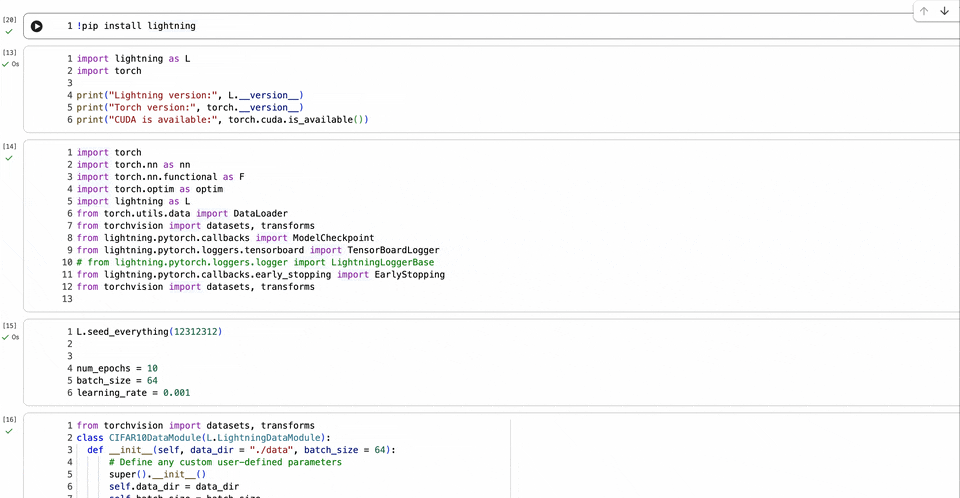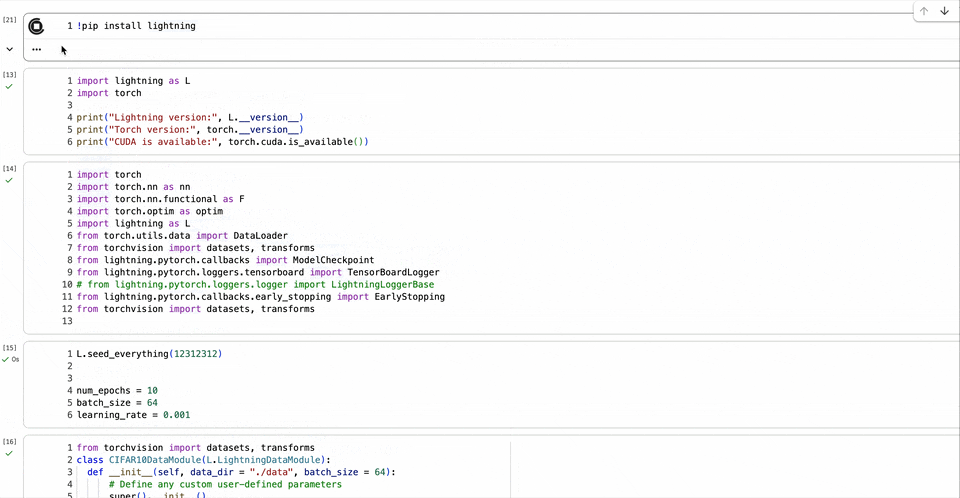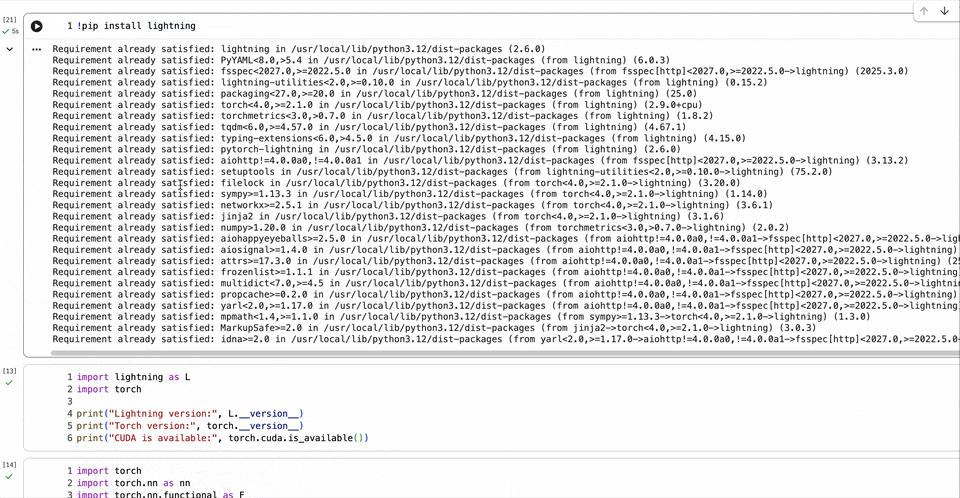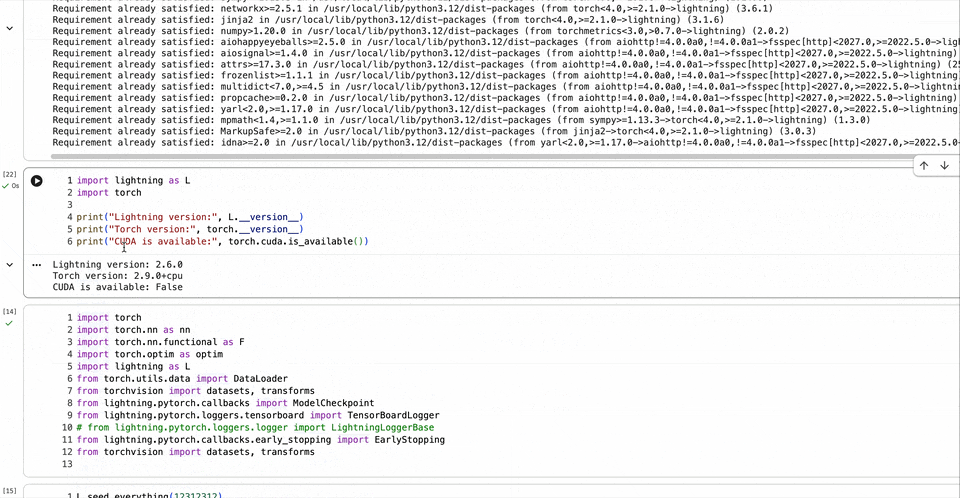
安装完成,打印组件对应版本,可以正常运行,说明安装成功。这里用的是CPU环境,如果是GPU环境,则会显示
CUDA is available:True
【第二步】加载CIFAR10图像分类数据库
LightningDataModule用来在整个训练过程中,管理维护训练数据库。主要函数功能:
1. prepare_data函数:下载数据;数据存储路径:”./data/”文件夹下
2. setup函数:用于加载数据并进行分割;
3. train_dataloader, val_dataloader, test_dataloader:返回相应的torch.utils.data.DataLoader实例
LightningDataModule优势:使用简单,方便地结合训练过程。
from torchvision import datasets, transforms
class CIFAR10DataModule(L.LightningDataModule):
def __init__(self, data_dir = "./data", batch_size = 64):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform_train = transforms.Compose(
[
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
],
)
self.transform_test = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
def prepare_data(self):
# Download the data 初始化数据
datasets.CIFAR10(self.data_dir, train=True, download=True)
datasets.CIFAR10(self.data_dir, train=False, download=True)
def setup(self, stage=None):
if stage == 'fit' or stage is None:
self.cifar_train = datasets.CIFAR10(self.data_dir, train=True, transform=self.transform_train)
self.cifar_val = datasets.CIFAR10(self.data_dir, train=False, transform=self.transform_train)
if stage == 'test' or stage is None:
self.cifar_test = datasets.CIFAR10(self.data_dir, train=False, transform=self.transform_test)
def train_dataloader(self):
return DataLoader(self.cifar_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.cifar_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.cifar_test, batch_size=self.batch_size)【第三步】设置神经网络模型
神经网络模型设置。
这里是一个10分类问题,所以最后一层Linear层(fc2)输出的是10。
class CIFAR10CNN(L.LightningModule):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 4 * 4, 512)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 64 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x【第四步】模型训练配置
模型训练配置也是在CIFAR10CNN类中的函数training_step进行配置。最后的返回结果是loss。
LightingModule模块会自动实施backward参数优化迭代更新的工作。
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
acc = (y_hat.argmax(1) == y).float().mean()
self.log("train_loss", loss)
self.log("train_acc", acc)
return loss【第五步】validation和test过程
validation_step和test_step,这里Lighting最大的优势,是无需手动进行对应数据集的配置。会自动根据data module模块的validation和test数据集和进行计算。
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
acc = (y_hat.argmax(1) == y).float().mean()
self.log('val_loss', loss)
self.log('val_acc', acc)
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
acc = (y_hat.argmax(1) == y).float().mean()
self.log('test_loss', loss)
self.log('test_acc', acc)【第六步】配置优化函数
configure_optimizers是默认方法,需要进行重载。
返回的对象包含:
1. optimizer:优化器
2. lr_scheduler:学习速率调度器
2.1 scheduler:调整learning rate的方案;如果连续5步,loss都没有减少,那么讲按照factor的比例,对learning rate进行调整(减少learning rate)
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=5
)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"monitor": "val_loss",
},
}【第七步】训练过程
在开始最终的训练之前,需要先设置Trainer训练器。参数:
1. 最大的训练epochs
2. callbacks:
2.1 checkpoint_callback:提供存储中间模型的功能。类似与游戏存档点。
2.2 early_stopping:通过早停功能。如果模型在50 epochs之前就已经收敛,训练会提前停止。
可以查看文档,选用lightning提供callback函数,进行使用。
model = CIFAR10CNN()
# Initialize the trainer
trainer = L.Trainer(
max_epochs=50,
callbacks=[checkpoint_callback, early_stopping],
accelerator="gpu" if torch.cuda.is_available() else "cpu",
devices="auto",
)
data_module = CIFAR10DataModule()
trainer.fit(model, data_module)训练过程
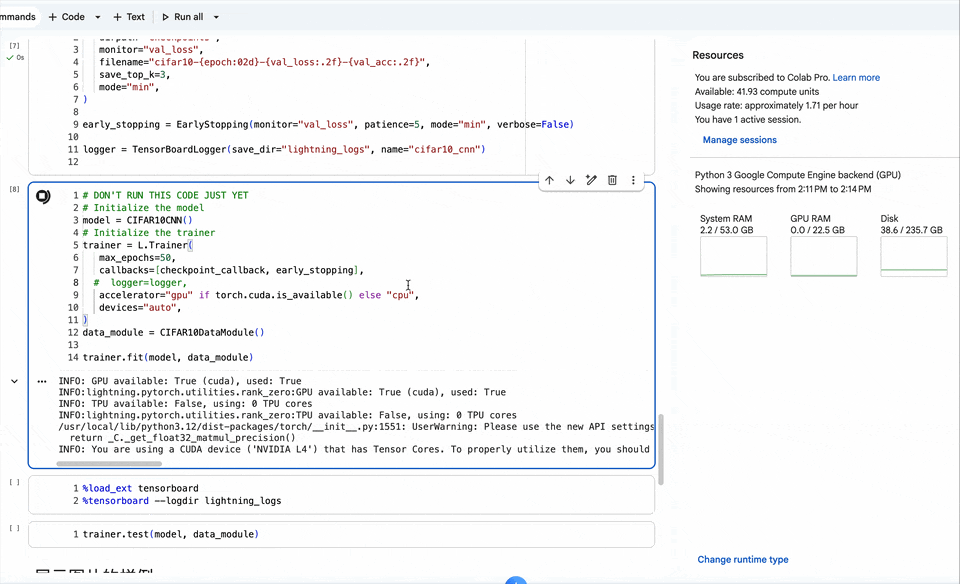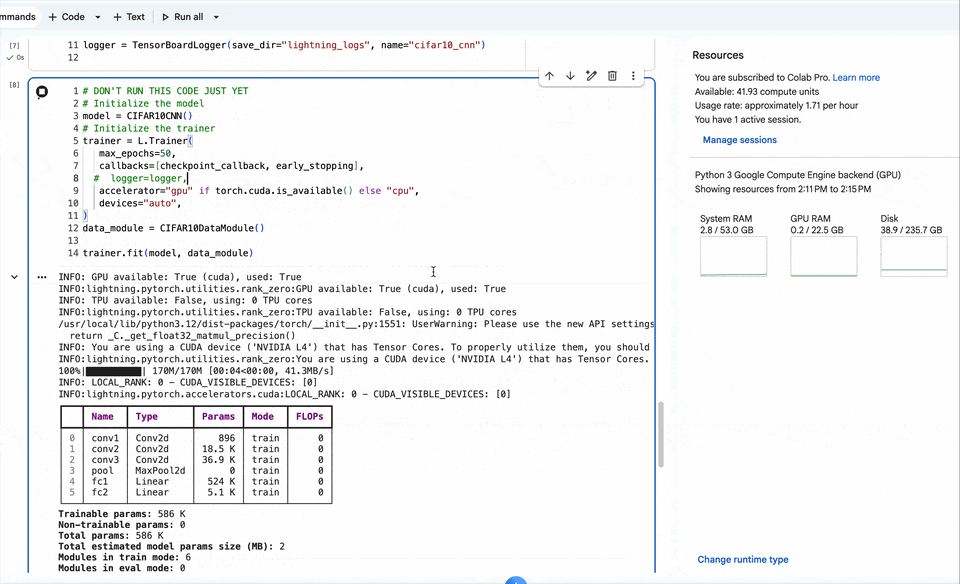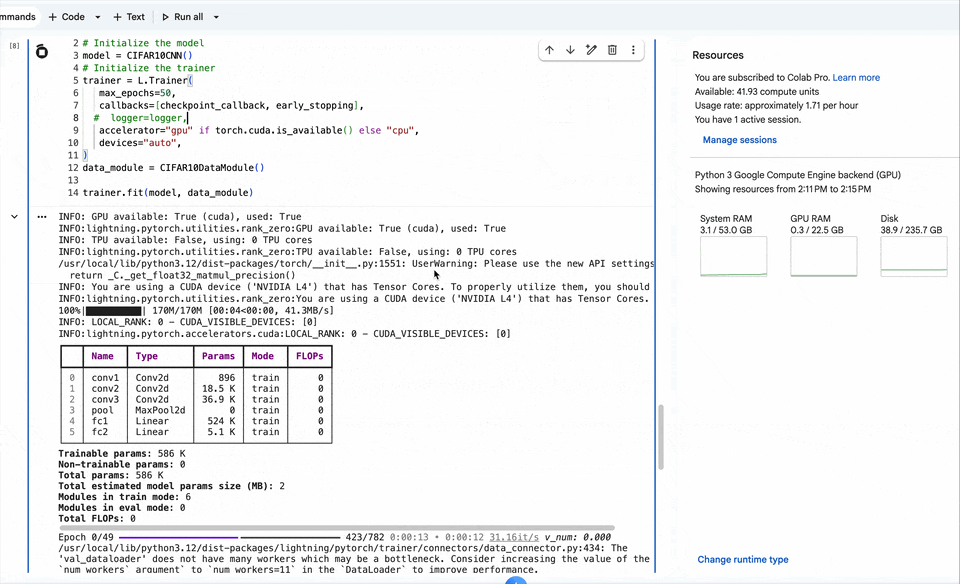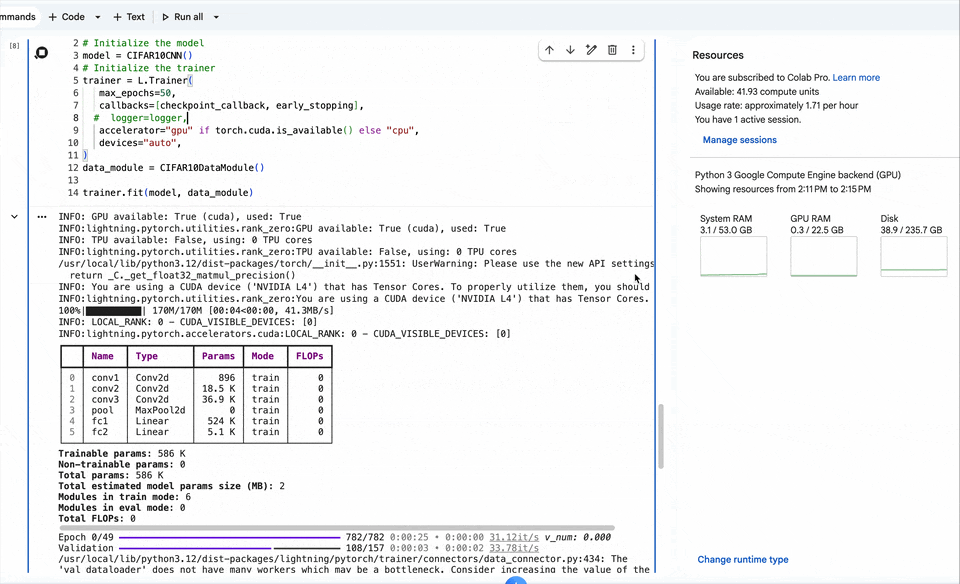
【第八步】测试集评估结果查看
测试集评估结果,以及抽样查看具体图片的分类结果。
CIFAR-10数据集:准确率在79.2%,模型性能属于及格~良好之间。
import matplotlib.pyplot as plt
import numpy as np
test_dl = data_module.test_dataloader()
def imshow(img):
# 如果之前做了 Normalize((0.5,), (0.5,)), 这里需要反归一化:img = img * std + mean
img = img / 2 + 0.5
npimg = img.numpy()
# 转换维度:PyTorch 是 [C, H, W],但 Matplotlib 需要 [H, W, C]
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 取出一组图片并展示
images, labels = next(iter(test_dl))
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 制作成网格图
grid = torchvision.utils.make_grid(images[:8]) # 只看前 8 张
imshow(grid)
print("Ture Labels:", labels[:8].tolist())
print("Predicted Labels:", predicted[:8].tolist())
## 评估测试集性能指标
trainer.test(model, data_module)
# [{'test_loss': 0.6113594770431519, 'test_acc': 0.7924000024795532}]运行结果

【附录】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)