AI大模型:Python汽车数据分析与推荐系统 机器学习 线性回归预测算法 requests爬虫 Flask框架 汽车之家 大数据毕业设计✅
AI大模型:Python汽车数据分析与推荐系统 机器学习 线性回归预测算法 requests爬虫 Flask框架 汽车之家 大数据毕业设计✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、汽车之家数据、推荐模块、机器学习、线性回归预测算法、requests爬虫、Echarts可视化、HTML
汽车数据分析与预测系统功能模块介绍
本系统以Python语言为核心,基于Flask框架搭建,依托requests爬虫抓取汽车之家数据,融合机器学习、线性回归算法与Echarts可视化技术,构建覆盖数据采集、分析、预测、推荐的全流程汽车数据应用体系,核心功能模块如下:
数据采集与管理模块是系统基础:通过requests爬虫定向获取汽车之家的车型详情、销量、价格等全维度数据;后台数据管理模块支持数据增删改查、异常值清洗与校验,保障数据准确性与完整性,为后续分析预测提供可靠数据源。
数据展示与可视化模块实现多维度洞察:数据中心汇总全量汽车数据,支持多维度筛选查看;汽车详情页展示单一车型的参数、价格、口碑等核心信息;数据可视化分析模块通过折线图、柱状图等形式,直观呈现销量趋势、价格分布、车型特征等规律,汽车销量数据模块则聚焦销量明细与汇总展示。
智能分析与推荐模块体现系统核心价值:基于线性回归预测算法构建汽车销量预测模型,输出未来销量趋势,为经营决策提供量化依据;汽车推荐模块融合机器学习算法,结合车型特征与用户偏好实现精准推荐,满足个性化选车需求。
整体而言,系统打通“数据采集-可视化分析-智能预测-个性化推荐”闭环,既为用户提供直观的汽车数据参考与精准的车型推荐,也为行业从业者提供销量预测、市场分析的决策支撑。
2、项目界面
(1)数据中心
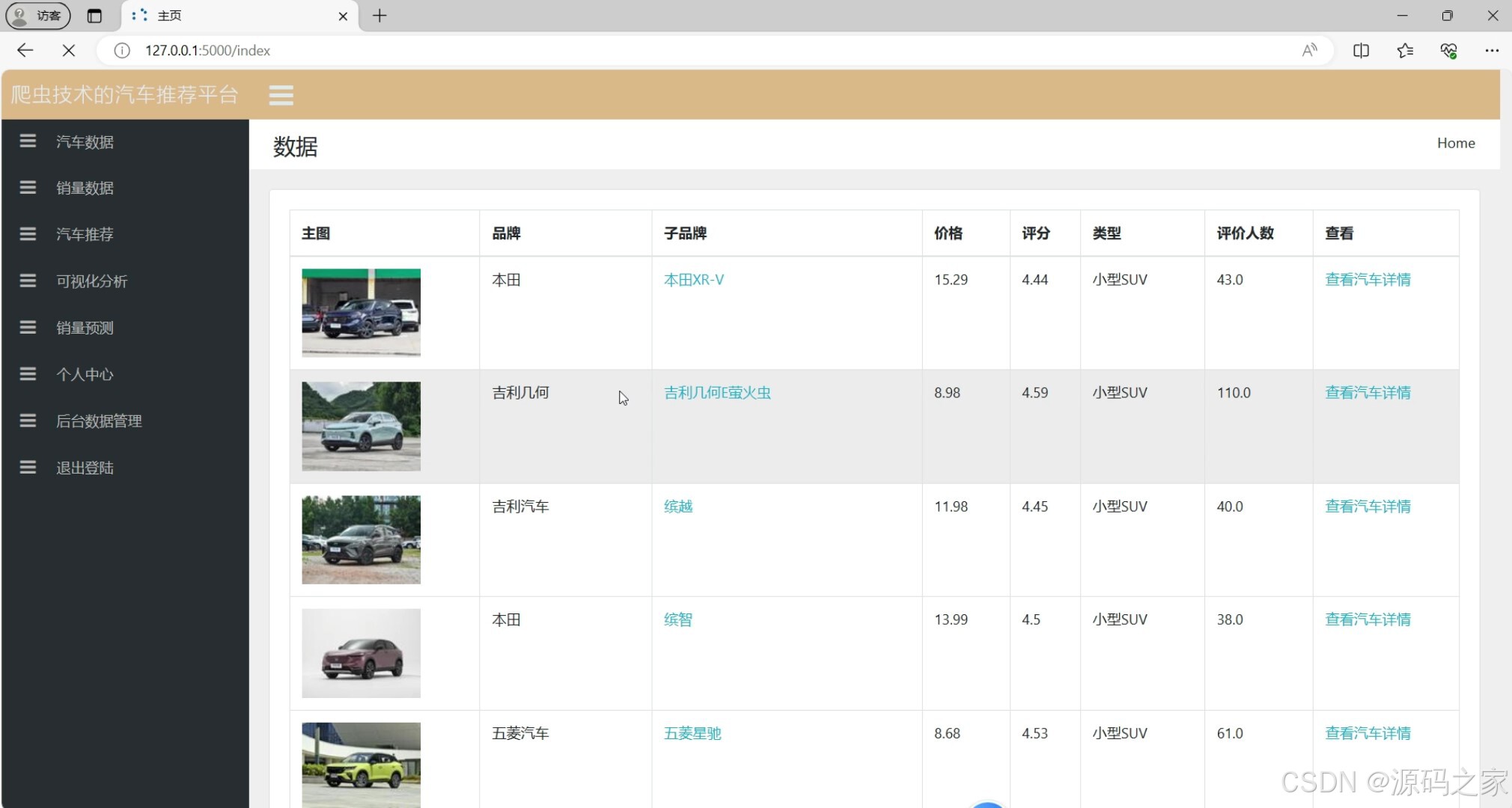
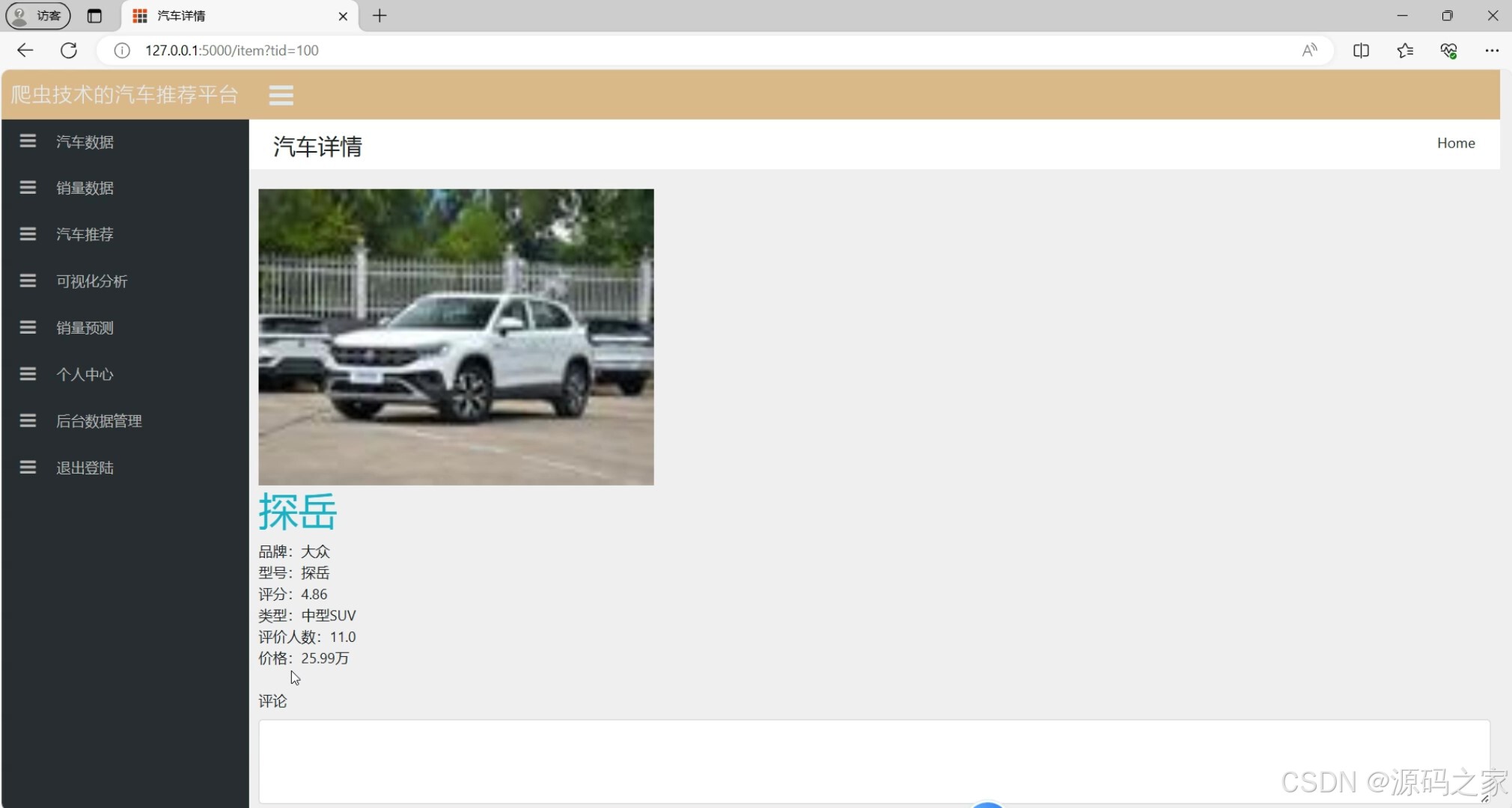
(2)汽车详情页
(3)数据可视化分析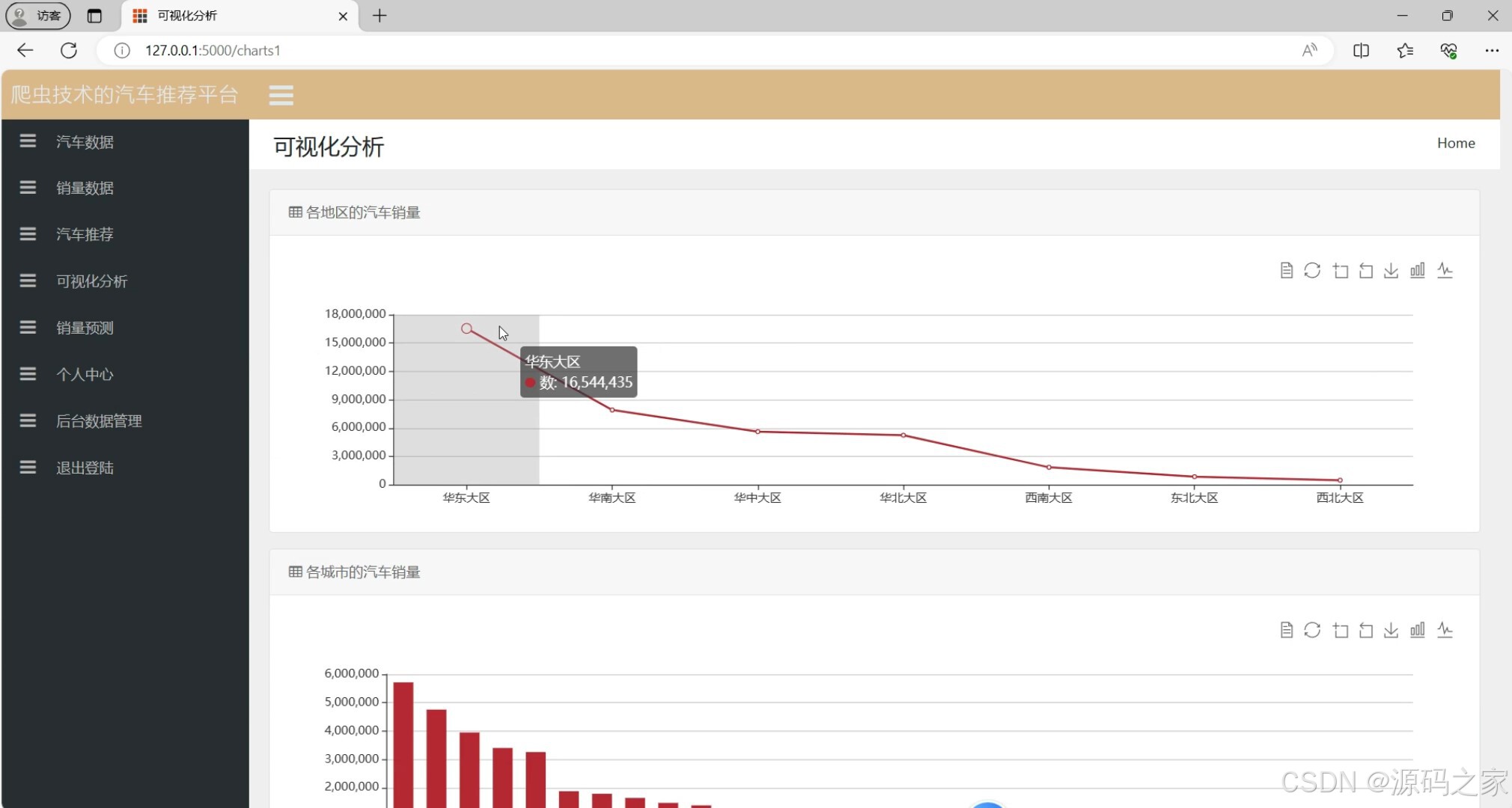
(4)数据可视化分析2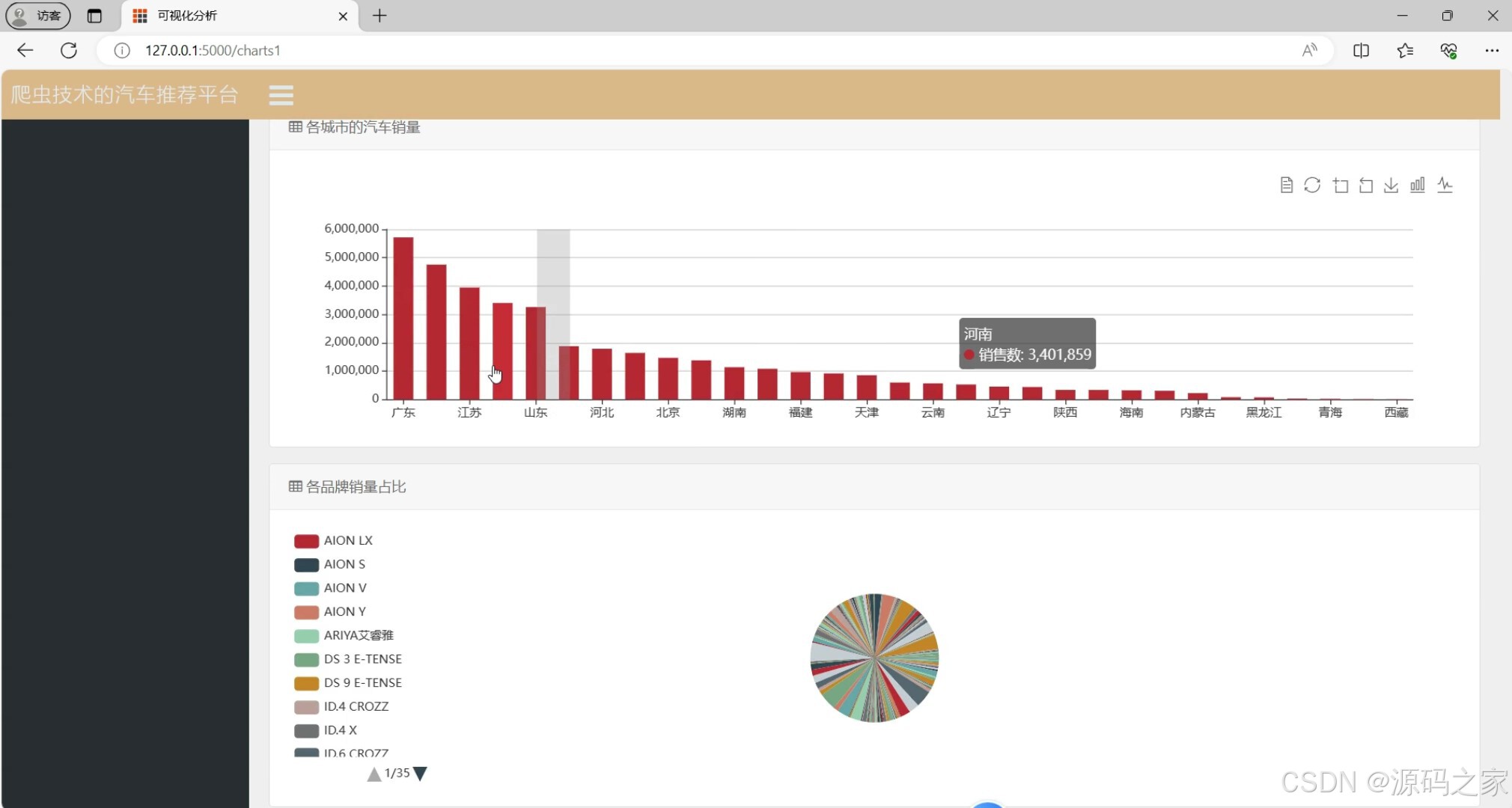
(5)汽车销量数据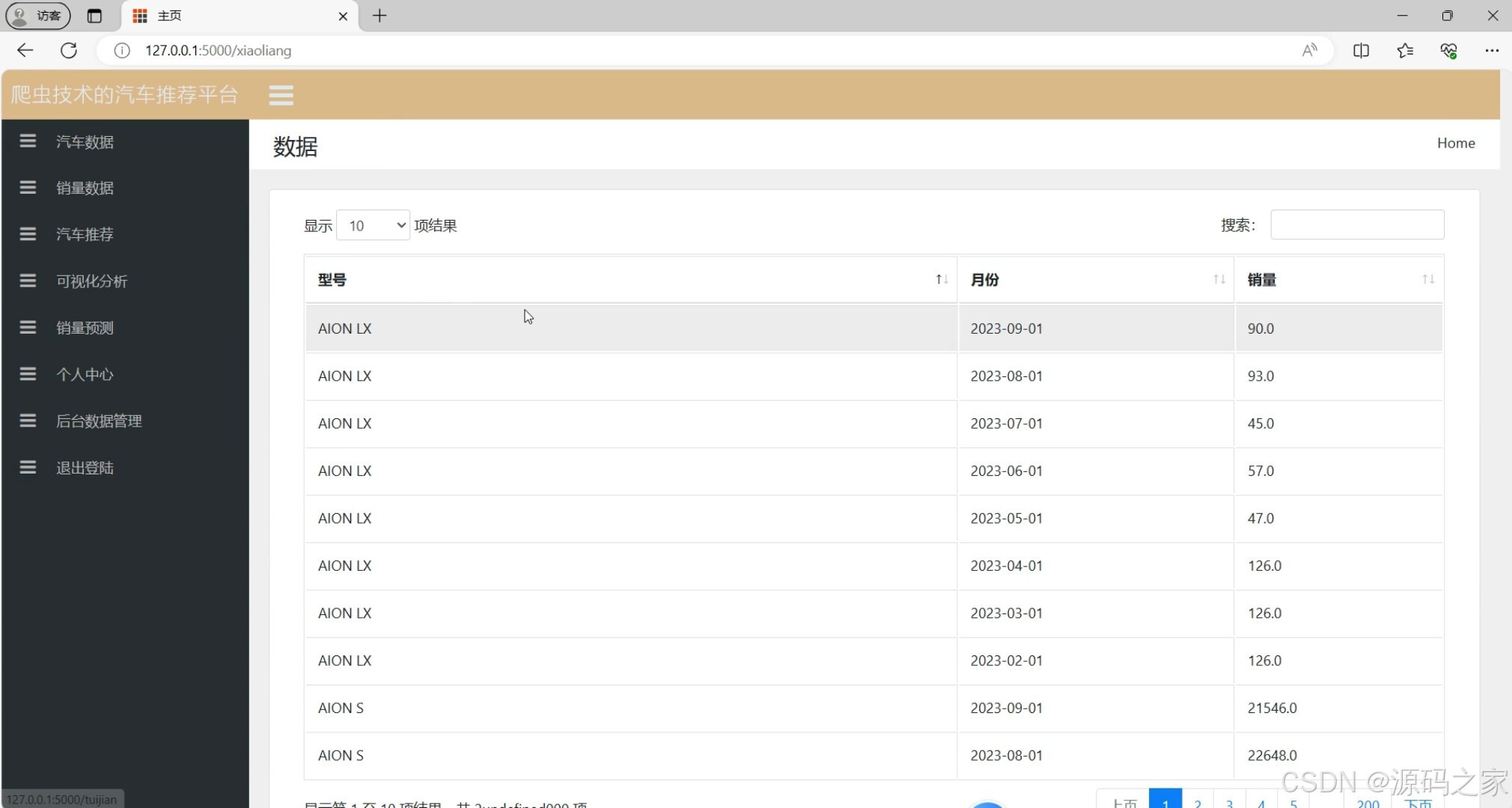
(6)汽车销量预测(机器学习)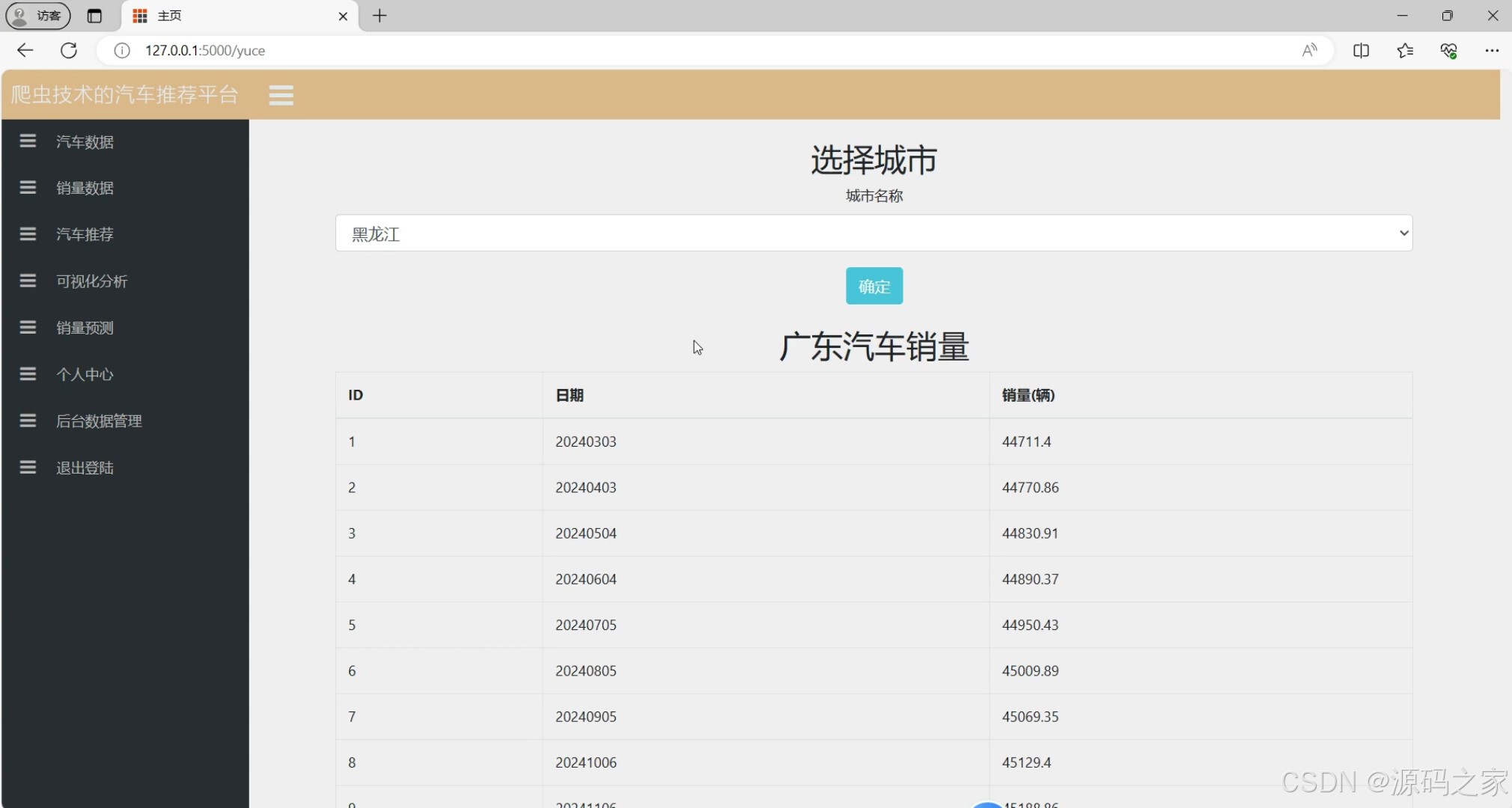
(7)汽车推荐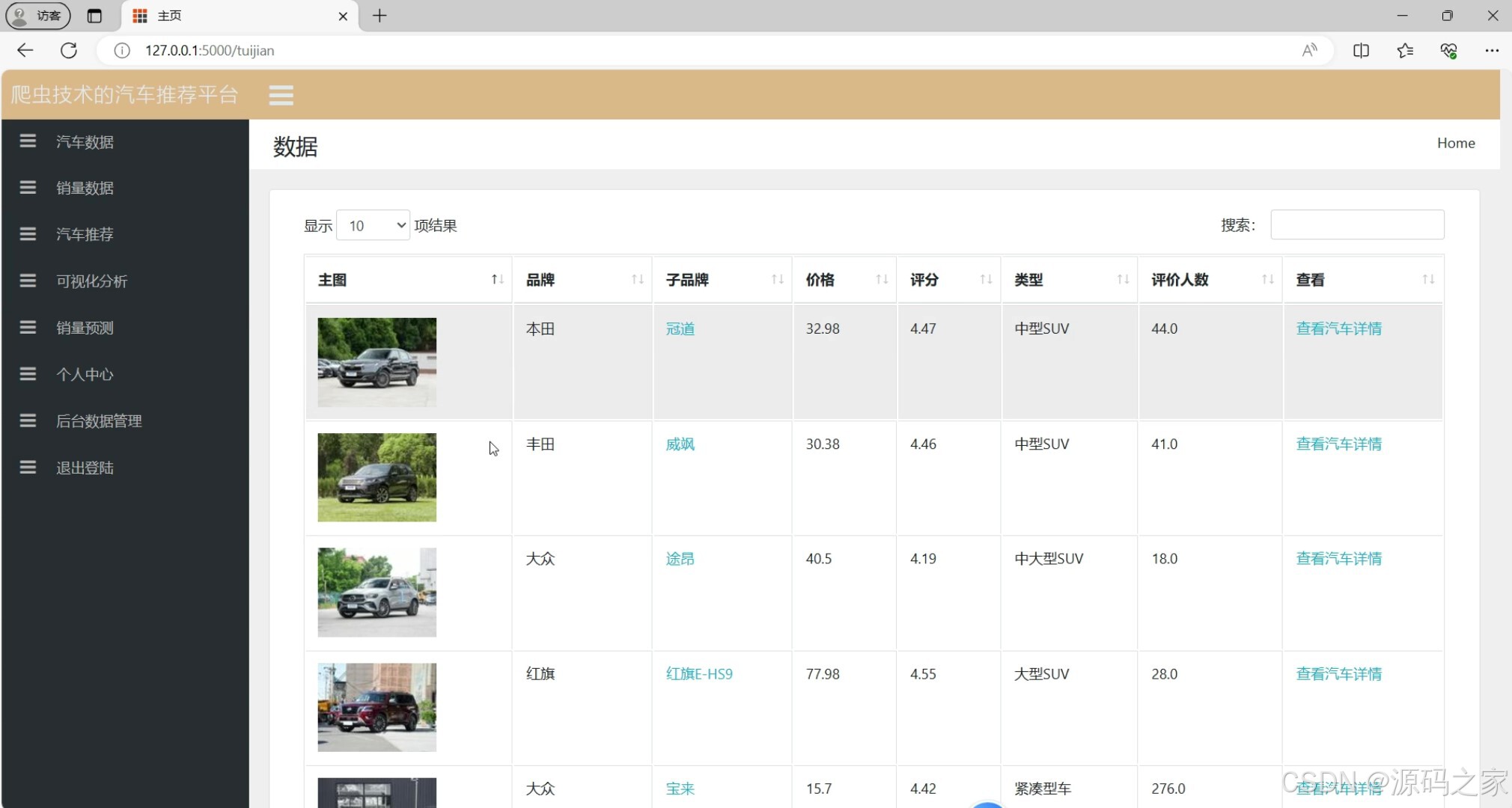
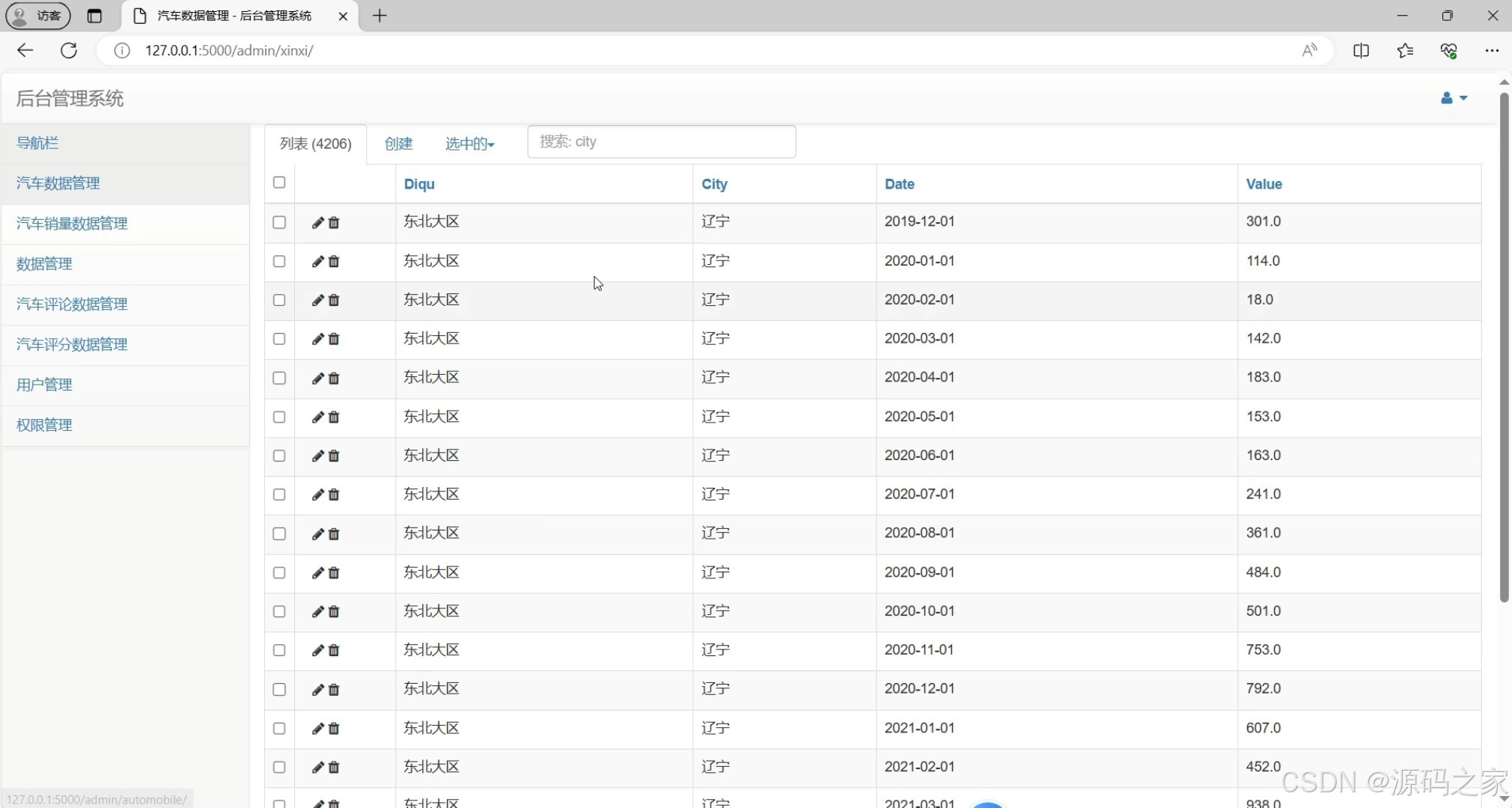
(8)后台数据管理
3、项目说明
汽车数据分析与预测系统功能模块介绍
本系统以Python语言为核心,基于Flask框架搭建,依托requests爬虫抓取汽车之家数据,融合机器学习、线性回归算法与Echarts可视化技术,构建覆盖数据采集、分析、预测、推荐的全流程汽车数据应用体系,核心功能模块如下:
数据采集与管理模块是系统基础:通过requests爬虫定向获取汽车之家的车型详情、销量、价格等全维度数据;后台数据管理模块支持数据增删改查、异常值清洗与校验,保障数据准确性与完整性,为后续分析预测提供可靠数据源。
数据展示与可视化模块实现多维度洞察:数据中心汇总全量汽车数据,支持多维度筛选查看;汽车详情页展示单一车型的参数、价格、口碑等核心信息;数据可视化分析模块通过折线图、柱状图等形式,直观呈现销量趋势、价格分布、车型特征等规律,汽车销量数据模块则聚焦销量明细与汇总展示。
智能分析与推荐模块体现系统核心价值:基于线性回归预测算法构建汽车销量预测模型,输出未来销量趋势,为经营决策提供量化依据;汽车推荐模块融合机器学习算法,结合车型特征与用户偏好实现精准推荐,满足个性化选车需求。
整体而言,系统打通“数据采集-可视化分析-智能预测-个性化推荐”闭环,既为用户提供直观的汽车数据参考与精准的车型推荐,也为行业从业者提供销量预测、市场分析的决策支撑。
项目功能模块介绍
1. 数据中心
- 功能:展示和管理汽车相关的数据,例如汽车的基本信息、销量数据、用户评价等。
- 实现方式:
- 使用 Flask 框架搭建后端服务,通过 Python 的
requests库从汽车之家等数据源爬取数据。 - 数据存储在本地数据库中(如 SQLite 或 MySQL)。
- 前端使用 HTML 和 Echarts 进行数据的可视化展示。
- 使用 Flask 框架搭建后端服务,通过 Python 的
2. 汽车详情页
- 功能:展示单个汽车的详细信息,包括图片、配置、用户评价等。
- 实现方式:
- 后端通过 Flask 提供 API 接口,前端通过 AJAX 请求获取数据并动态渲染页面。
- 使用 HTML 和 CSS 设计页面布局,展示丰富的汽车详情内容。
3. 数据可视化分析
- 功能:通过图表展示汽车数据的分析结果,例如销量趋势、用户评分分布等。
- 实现方式:
- 使用 Python 的数据分析库(如 Pandas)对数据进行处理。
- 前端使用 Echarts 库生成各种图表(如柱状图、折线图、饼图等)。
- 通过 Flask 后端将数据传递到前端,前端动态生成图表。
4. 数据可视化分析2
- 功能:进一步深入分析汽车数据,可能包括对比分析、市场趋势等。
- 实现方式:
- 后端使用 Python 进行复杂的数据分析和处理。
- 前端通过 Echarts 展示多维度的可视化结果。
5. 汽车销量数据
- 功能:展示汽车的销量数据,可能包括历史销量、月度销量等。
- 实现方式:
- 数据通过爬虫从汽车之家等平台获取。
- 使用 Flask 后端处理数据,前端通过 Echarts 展示销量趋势。
6. 汽车销量预测(机器学习)
- 功能:使用线性回归等机器学习算法预测汽车未来的销量。
- 实现方式:
- 后端使用 Python 的机器学习库(如 scikit-learn)构建线性回归模型。
- 用户输入相关特征(如车型、市场趋势等),后端模型进行预测并将结果返回给前端。
7. 汽车推荐
- 功能:根据用户的历史行为或偏好,推荐相关的汽车。
- 实现方式:
- 后端使用推荐算法(如协同过滤、基于内容的推荐等)。
- 用户在前端选择偏好或历史行为数据被记录,后端根据这些数据生成推荐结果。
8. 后台数据管理
- 功能:管理员可以管理数据,包括数据的导入、导出、更新等。
- 实现方式:
- 后端使用 Flask 提供管理接口,管理员可以通过网页操作数据库。
- 前端提供管理界面,方便管理员进行数据操作。
4、核心代码
@app.route('/charts1', methods=['GET', 'POST'])
def charts1():#获取session的数据,判断是否登录,如未登录跳转到登录页
uuid = current_user.is_anonymous
if uuid:
return redirect(url_for('logins'))
username = models.User.query.get(current_user.get_id()).username
if request.method == 'GET':
datas = models.Xinxi.query.all()
#各地区的新能源汽车销量
sps = [i.diqu for i in datas]
sps_set = set(list(sps))
list1 = []
for resu in sps_set:
rows = models.Xinxi.query.filter(models.Xinxi.diqu==resu).all()
num = 0
for row in rows:
num += row.value
list1.append((resu,num))
list1.sort(key=lambda xx: xx[1], reverse=True)#对数据进行排序
zhiwei_list = []
xinzhi_list = []
for resu in list1:
zhiwei_list.append(resu[0])
xinzhi_list.append(resu[1])
#各城市的新能源汽车销量
citys = [i.city for i in datas]
citys_set = set(list(citys))
list1 = []
for resu in citys_set:
rows = models.Xinxi.query.filter(models.Xinxi.city==resu).all()
num = 0
for row in rows:
num += row.value
list1.append((resu, num))
list1.sort(key=lambda xx: xx[1], reverse=True) # 对数据进行排序
xiaoliang_list = []
xiaoliang_count = []
for resu in list1:
xiaoliang_list.append(resu[0])
xiaoliang_count.append(resu[1])
# 各品牌销量占比
leixing_set = list(set([i.name for i in models.XiaoLiang.query.all()]))
leixing_set.sort()
leixing_list = []
for row in leixing_set:
rows = models.XiaoLiang.query.filter(models.XiaoLiang.name == row).all()
num = 0
for row1 in rows:
num += row1.value
leixing_list.append({"name":row,"value":num})
print(leixing_list)
return render_template('charts1.html',**locals())
import traceback
from collections import OrderedDict
import pandas as pd
import models
from sqlalchemy import or_,and_
import datetime
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import numpy
def yuce1(name):
try:
dates = models.Xinxi.query.filter(models.Xinxi.city == name).all()
li1 = []
for row in dates:
li1.append([int(str(row.date).replace('-','')),row.value])
li1.sort(key=lambda xx:xx[0])
date_day = []
liuliang = []
for row in li1:
date_day.append(row[0])
liuliang.append(row[1])
# 数据集
examDict = {
'日期': date_day,
'销量': liuliang
}
print(examDict)
examOrderedDict = OrderedDict(examDict)
examDf = pd.DataFrame(examOrderedDict)
examDf.head()
# exam_x 即为feature
exam_x = examDf.loc[:, '日期']
# exam_y 即为label
exam_y = examDf.loc[:, '销量']
x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.8)
x_train = x_train.values.reshape(-1, 1)
x_test = x_test.values.reshape(-1, 1)
model = LinearRegression()
model.fit(x_train, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
rDf = examDf.corr()
model.score(x_test, y_test)
data1 = datetime.datetime.strptime(str(date_day[-5]), '%Y%m%d')
li1 = []
for i in range(12):
data1 = data1 + datetime.timedelta(31)
li1.append([int(data1.strftime('%Y%m%d'))])
li2 = numpy.array(li1)
y_train_pred = model.predict(li2)
li2 = []
for i in range(len(li1)):
dicts = {}
dicts['riqi'] = li1[i][0]
dicts['xiaoliang'] = round(abs(y_train_pred[i]),2)
li2.append(dicts)
return li2[2:]
except:
print(traceback.format_exc())
return []
@app.route('/yuce', methods=['GET', 'POST'])
def yuce():
if request.method == 'GET':
result = list(set([i.city for i in models.Xinxi.query.all()]))
return render_template('yuce.html',**locals())
elif request.method == 'POST':
result = list(set([i.city for i in models.Xinxi.query.all()]))
name = request.form.get('name')
print(name)
datas = yuce1(name)
riqi = [i['riqi'] for i in datas]
xiaoliang = [i['xiaoliang'] for i in datas]
return render_template('yuce.html',**locals())
@app.route('/user', methods=['GET', 'POST'])
def user():
stu_id = current_user.is_anonymous
if stu_id:
return redirect(url_for('logins'))
if request.method == 'GET':
results = models.User.query.get(current_user.get_id())
return render_template('user.html',data=results)
elif request.method == 'POST':
data = request.form
username = data.get('name')
occupation = data.get('occupation')
results = models.User.query.get(current_user.get_id())
results.username = username
results.occupation = occupation
models.db.session.commit()
return redirect('/user')
from flask_security.utils import login_user, logout_user
@app.route('/logins', methods=['GET', 'POST'])
def logins():
uuid = current_user.is_anonymous
if not uuid:
return redirect(url_for('index'))
if request.method=='GET':
return render_template('account/index.html')
elif request.method=='POST':
user = request.form.get('user')
password = request.form.get('password')
data = models.User.query.filter(and_(models.User.username==user,models.User.password==password)).first()
if not data:
return render_template('account/index.html',error='账号密码错误')
else:
login_user(data, remember=True)
return redirect(url_for('index'))
@app.route('/loginsout', methods=['GET'])
def loginsout():
if request.method=='GET':
logout_user()
return redirect(url_for('logins'))
@app.route('/signups', methods=['GET', 'POST'])
def signup():
uuid = current_user.is_anonymous
if not uuid:
return redirect(url_for('index'))
if request.method == 'GET':
return render_template('account/register.html')
elif request.method == 'POST':
user = request.form.get('user')
email = request.form.get('email')
password = request.form.get('password')
if models.User.query.filter(models.User.username == user).all():
return render_template('account/register.html', error='账号名已被注册')
elif user == '' or password == '' or email == '':
return render_template('account/register.html', error='输入不能为空')
else:
new_user = user_datastore.create_user(username=user, email=email, password=password,occupation='')
normal_role = user_datastore.find_role('User')
models.db.session.add(new_user)
user_datastore.add_role_to_user(new_user, normal_role)
models.db.session.commit()
login_user(new_user, remember=True)
return redirect(url_for('index'))
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)