上下文工程
上下文工程是优化大语言模型(LLM)动态上下文管理的系统性方法,旨在解决智能体在长时运行中的上下文爆炸和性能衰减问题。核心策略包括卸载、缩减、检索、隔离和缓存上下文,通过外部存储、智能摘要、语义搜索等技术降低Token消耗,提升响应效率。典型应用涵盖研究助手、多模态系统和企业自动化场景。多智能体架构通过任务分解和上下文隔离显著提升性能,但面临注意力分散、工具调用复杂等挑战。未来将聚焦自动化管理、多
·
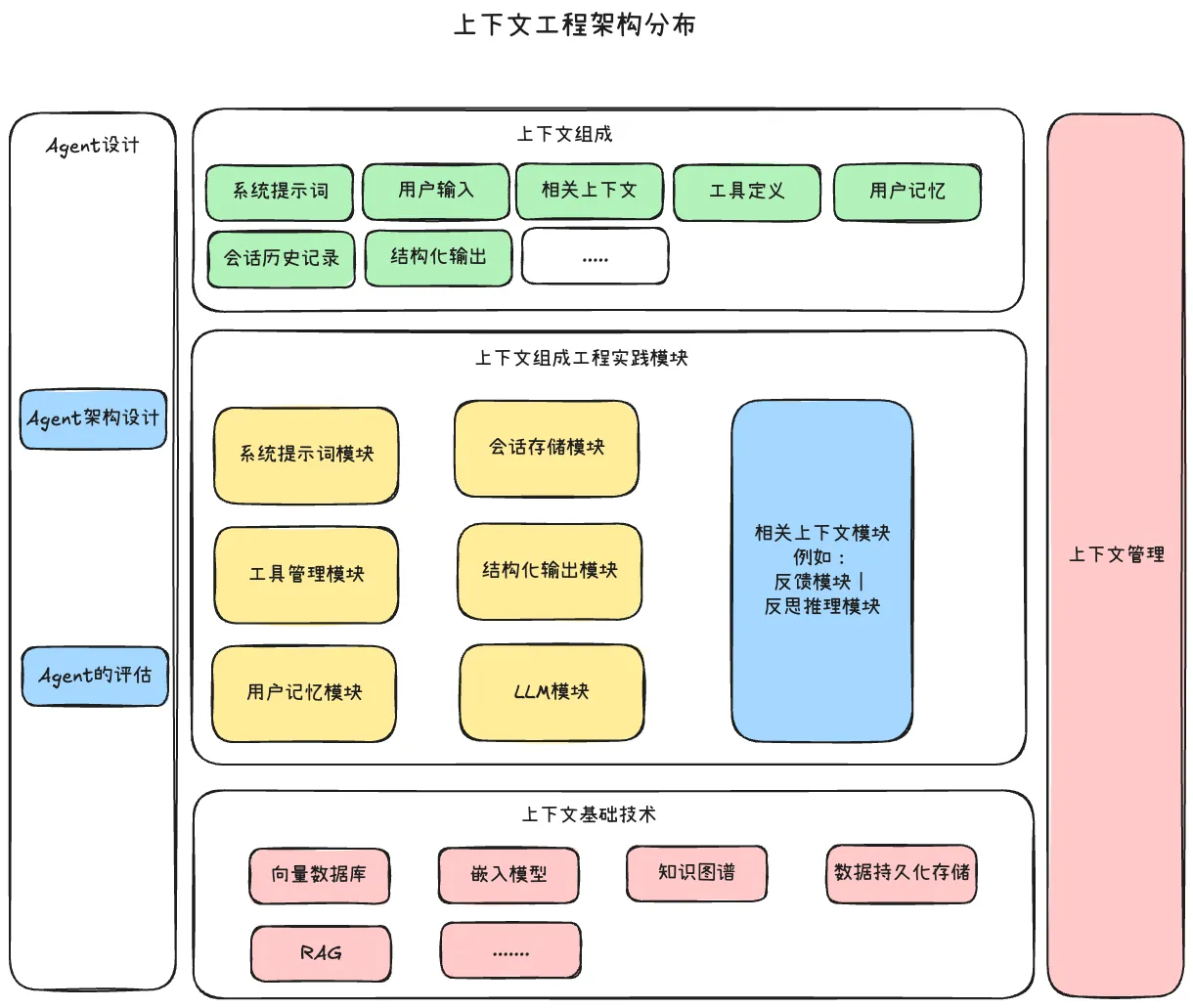
一、核心定义与兴起背景
上下文工程的本质与核心价值
上下文工程是一门聚焦 “动态构建 LLM 上下文” 的系统学科,通过筛选、组织、优化输入信息,确保 AI 智能体在每一步决策时获得 “恰好所需” 的上下文。其核心是解决传统提示工程的单一交互局限,应对智能体因工具调用和长时运行导致的上下文爆炸与性能衰减问题(如 Anthropic 提出的 “上下文腐烂” 现象),实现从 “单次提示优化” 到 “全流程信息生态管理” 的跨越。
技术演进与行业背景
- 兴起时间线:2022 年 ChatGPT 推动提示工程流行,2023 年随智能体(Agent)爆发,Andrej Karpathy 于 2024 年正式提出 “上下文工程” 概念,聚焦解决智能体运行中工具调用累积的海量上下文管理难题。
- 核心驱动:智能体需处理 50 - 数百次工具调用(如 Manus 典型任务需 50 次调用),传统固定上下文窗口(如 GPT-4 的 128K Token)难以承载,催生对动态上下文管理的需求。
二、五大核心策略
1. 上下文卸载(Context Offloading)
- 核心逻辑:将非即时必需的信息从上下文窗口移除,存储于外部系统(如文件系统、数据库),仅保留引用指针(如文件名、ID)。
- 实现方式:
-
- 文件系统存储:Manus、Open Deep Research 等项目将工具调用的完整输出(如网页搜索结果)存为文件,仅向智能体返回文件路径,避免 Token 超限(如减少 50% 以上的上下文占用)。
- 状态对象管理:LangChain 的 LangGraph 通过状态对象(State)持久化关键信息(如用户偏好、任务目标),运行时动态加载,减少历史消息堆积。
2. 上下文缩减(Context Reducing)
- 核心逻辑:通过摘要、精简等手段压缩上下文,保留关键信息,降低 Token 消耗。
- 主流方法:
-
- 智能摘要:Open Deep Research 对工具输出进行递归摘要(如将 1000 字网页内容浓缩为 100 字核心结论),Claude 3.5 Sonnet 内置自动压缩功能,触发阈值达 70% 时自动摘要历史对话。
- 冗余修剪:按时间 / 相关性排序,移除旧对话或低价值工具调用(如重复的错误重试记录),Cognition 通过子智能体交接时的摘要机制,减少 30% 以上的无效上下文。
3. 上下文检索(Context Retrieving)
- 核心逻辑:通过索引与搜索技术,动态获取当前任务最相关的上下文片段,避免全量加载。
- 技术路线:
-
- 语义检索:Cursor 使用向量索引 + 语义搜索(如 BM25、Dense Passage Retrieval),从历史对话和外部知识库中召回 Top 5 相关片段,提升工具调用准确率 40%。
- 轻量搜索:Claude Code 采用文件系统 + glob/grep 等简单工具,快速定位代码片段或配置文件,平衡效率与精度(响应时间较全量检索降低 60%)。
4. 上下文隔离(Context Isolating)
- 核心逻辑:通过多智能体架构(Multi-Agent)将上下文按功能 / 子任务拆分,每个子智能体独立管理专属上下文,避免相互干扰。
- 典型实践:
-
- 子智能体分工:Anthropic 的多智能体研究员将 “信息检索” 与 “报告生成” 分离,前者处理实时数据(如网页搜索),后者聚焦结构化输出,降低跨任务上下文污染风险。
- 状态隔离:Open Deep Research 的三阶段架构中,研究子智能体仅接收与子主题相关的上下文(如 “对比 OpenAI 与 Anthropic 的安全理念” 子任务,仅包含对应检索结果),专注度提升 30%。
5. 上下文缓存(Context Caching)
- 核心逻辑:缓存高频工具调用结果、用户偏好等信息,减少重复计算,提升响应速度。
- 应用场景:
-
- 任务规划缓存:Manus 通过持久化存储待办事项列表(To-Do List),避免长对话中目标遗忘,任务完成率提升 25%。
- 工具响应缓存:ChromaDB 等向量数据库缓存工具返回的结构化数据(如产品参数、用户历史行为),下次调用时直接复用,降低 API 调用频次 40%。
三、典型应用场景
1. 长时运行智能体(如研究助手、代码生成工具)
- 挑战:数百次工具调用导致上下文冗余(如代码生成需频繁检索 API 文档、用户需求变更记录)。
- 解决方案:
-
- 采用 “卸载 + 检索” 组合:Open Deep Research 将研究计划存为独立文件,通过 LangGraph 状态动态加载,同时用子智能体隔离不同技术领域的上下文(如 “算法设计” 与 “工程实现” 分属不同子智能体)。
2. 多模态交互系统(如图文生成、语音助手)
- 挑战:多模态数据(如图像描述、语音转写文本)占用大量 Token,传统单模态处理效率低下。
- 解决方案:
-
- 引入 “缩减 + 隔离” 策略:先将图像特征向量(如 CLIP 模型输出)缓存至外部存储,仅向 LLM 传递特征 ID,生成阶段通过索引快速召回,Token 消耗减少 50% 以上。
3. 企业级流程自动化(如客服工单处理、财务审计)
- 挑战:需整合企业知识库、历史工单、合规政策等多源信息,上下文复杂度高。
- 解决方案:
-
- 构建 “检索 + 缓存” 闭环:通过 RAG 检索最新政策文档,缓存常用合规条款,客服智能体调用时自动关联历史工单中的相似案例,响应合规性提升 60%。
四、实战案例解析
1. 单体架构:从 “全能处理” 到瓶颈显现
- 问题:单一 LLM 处理所有任务,上下文快速膨胀(如复杂研究任务 Token 消耗超 50 万 / 次),出现 “信息过载” 与 “目标偏离”。
- 局限:串行处理效率低,长对话中早期关键信息(如用户核心需求)被后期工具输出覆盖,生成质量波动大。
2. 流水线架构:职责分离与流程优化
- 改进:拆解为 “需求分析→信息收集→数据分析→报告生成” 四阶段,每个阶段独立管理上下文(如分析阶段仅包含筛选后的关键数据)。
- 效果:上下文长度减少 40%,但仍受限于串行处理瓶颈,复杂推理场景(如跨领域数据整合)表现不足。
3. 多智能体架构:上下文隔离与并行协同
- 突破:
-
- 监督者代理:动态分配子任务(如 “技术实现” 与 “市场分析” 子主题),生成独立上下文。
- 子智能体分工:每个子智能体仅处理专属上下文(如 “技术子智能体” 聚焦代码库检索结果,“市场子智能体” 处理行业报告),最终由监督者整合输出。
- 成果:Token 消耗降低 60%,任务完成时间缩短 50%,复杂研究任务的信息完整性提升 35%。
五、挑战与未来方向
核心挑战
- 上下文衰减(Context Decay):过长的上下文导致模型注意力分散,推理准确率随 Token 增加呈指数级下降(如超过 32K Token 时,错误率上升 20%)。
- 工具调用复杂性:多工具并行调用时,上下文需动态适配不同格式(如 API 返回的 JSON、网页文本、数据库记录),解析成本高。
- 跨智能体协同:多智能体上下文同步不及时(如子智能体 A 的更新未同步至子智能体 B),导致决策冲突(如重复检索或信息矛盾)。
未来方向
- 自动化上下文管理:开发智能摘要模型(如基于 LLM 的动态压缩器),实现上下文缩减策略的自适应调整(如根据任务复杂度自动选择摘要粒度)。
- 多模态上下文融合:整合文本、图像、语音等多模态数据的统一表示(如向量嵌入),支持跨模态检索与协同(如语音指令自动关联历史图文对话)。
- 标准化框架建设:推动上下文工程工具链标准化(如 LangChain 的 Context Manager 组件),降低企业级智能体开发门槛,实现策略复用(如预定义 “电商客服上下文模板”)。
结语
上下文工程是智能体从 “演示级玩具” 进化为 “生产级工具” 的核心引擎。它不仅是技术策略的集合,更是一种 “信息架构思维”—— 通过合理设计上下文的 “输入 - 处理 - 输出” 闭环,让智能体在复杂任务中保持 “专注” 与 “高效”。随着 LangChain、Claude 等框架的工具化支持,以及 Open Deep Research 等实战案例的经验沉淀,上下文工程正从 “专家经验” 转化为 “可复制的工程化方案”,推动 AI 智能体在代码生成、科学研究、企业流程自动化等领域的规模化落地,开启 “动态记忆管理” 的智能体开发新时代。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)