Datawhale大模型RAG实战
本文介绍了检索增强生成(RAG)技术,通过引入外部知识解决通用大模型的知识局限、数据安全风险和模型幻觉问题。RAG流程包括离线计算(文档处理、向量化存储)和在线计算(查询处理、检索排序、生成回复)。文章基于Yuan2-2B-Mars模型搭建简化版RAG系统,详细说明环境准备、模型下载(使用bge-small-zh-v1.5向量模型)和操作步骤,帮助读者掌握RAG核心技术。完整教程可参考Datawh
1 引言1.1 什么是 RAG
通用大模型存在知识局限(无实时 / 非公开数据)、数据安全风险、模型幻觉问题,检索增强生成(RAG)通过引入外部知识解决这些问题,已成为主流应用方案,核心三步:
- 索引:文档分割为 Chunk 并构建向量索引
- 检索:计算 Query 与 Chunk 相似度,筛选相关片段
- 生成:结合检索结果生成准确回答
1.2 完整 RAG 链路RAG 链路分为离线与在线计算:
- 离线计算:解析 pdf/word/ppt 等文档→切割清洗去重→通过 Embedding 模型向量化→向量存入数据库(如 Milvus)
- 在线计算:用户 Query→向量化→召回(TF-IDF/BM25 快速匹配)→精排(余弦相似度计算)→重排(Reranker 优化排序)→选取 k 个相关 Chunk 与 Query 拼接为 prompt→输入大模型生成回复
1.3 开源 RAG 框架
主流开源框架包括 TinyRAG、LlamaIndex、LangChain、QAnything、RAGFlow 等,功能丰富但学习成本较高。本节课将基于 Yuan2-2B-Mars 模型,搭建简化版 RAG 系统,帮助掌握核心技术与完整链路。
温馨提示:
以下内容部分借鉴了Datawhale官方教程内容,内容介绍不太完整,完整版请借鉴DataWhale官方内容链接,教程链接如下:
https://m.datawhale.cn/activity/460
2.1 环境准备
进入你的魔塔社区,找到你昨天创建的实例,进入实例,点击终端。运行下面代码,下载文件,并将 Task 3:源大模型RAG实战 中内容拷贝到当前目录。
git lfs install
git clone https://www.modelscope.cn/datasets/Datawhale/AICamp_yuan_baseline.git
cp AICamp_yuan_baseline/Task\ 3:源大模型RAG实战/* .
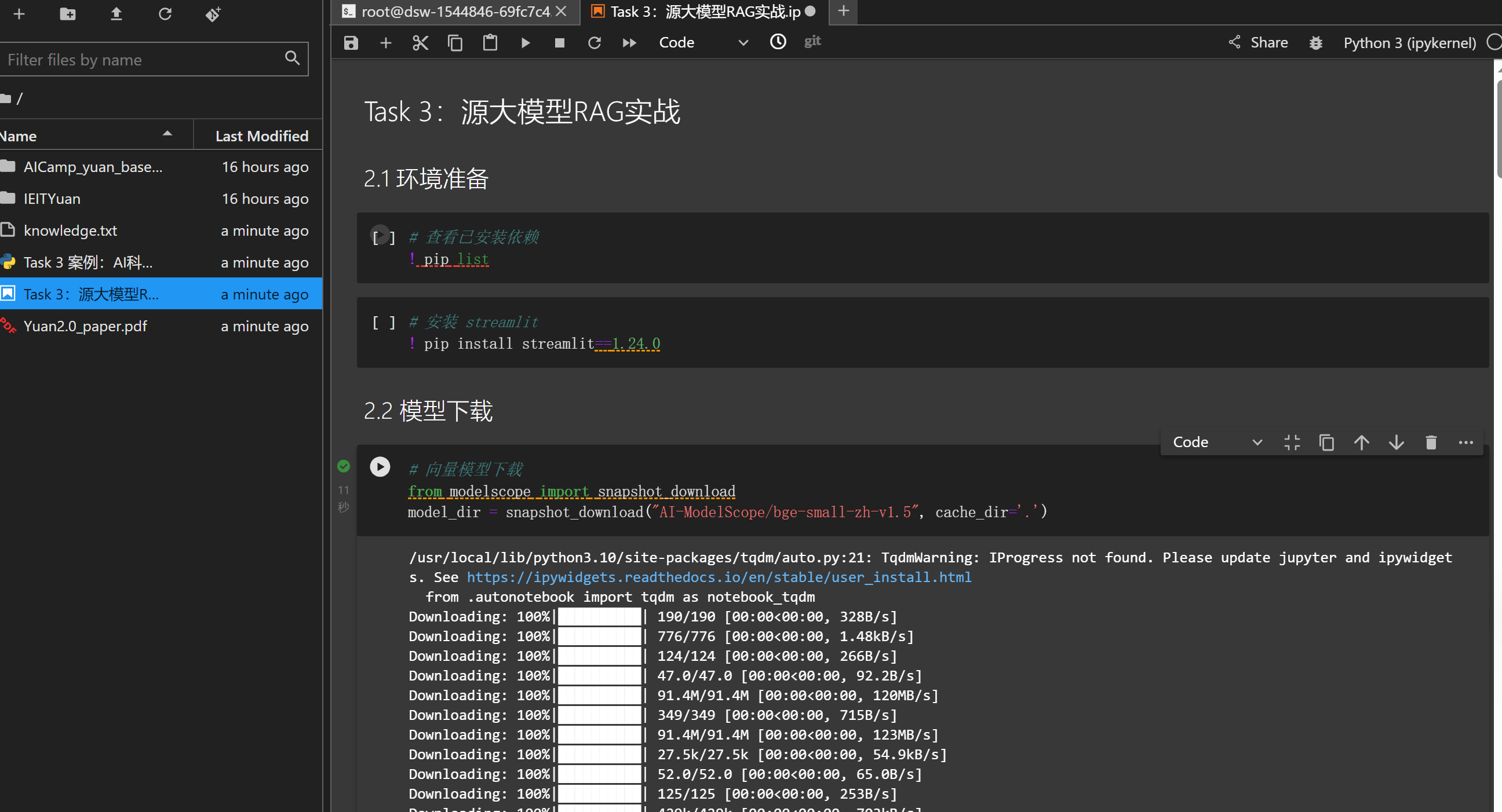
找到顶栏的Run,找到Run All Cells,点击一下。运行开始。
但是为了进行模型微调以及Demo搭建,还需要在环境中安装 streamlit。
# 安装 streamlit
pip install streamlit==1.24.0
2.2 模型下载
在本次学习中,我们选用基于BERT架构的向量模型 bge-small-zh-v1.5 ,它是一个4层的BERT模型,最大输入长度512,输出的向量维度也为512。
bge-small-zh-v1.5 支持通过多个平台进行下载,因为我们的机器就在魔搭,所以这里我们直接选择通过魔搭进行下载。
模型在魔搭平台的地址为http://AI-ModelScope/bge-small-zh-v1.5。
单元格 2.2 模型下载 会自动执行向量模型和源大模型下载。
向量模型命令:
# 向量模型下载
from modelscope import snapshot_download
model_dir = snapshot_download("AI-ModelScope/bge-small-zh-v1.5", cache_dir='.')
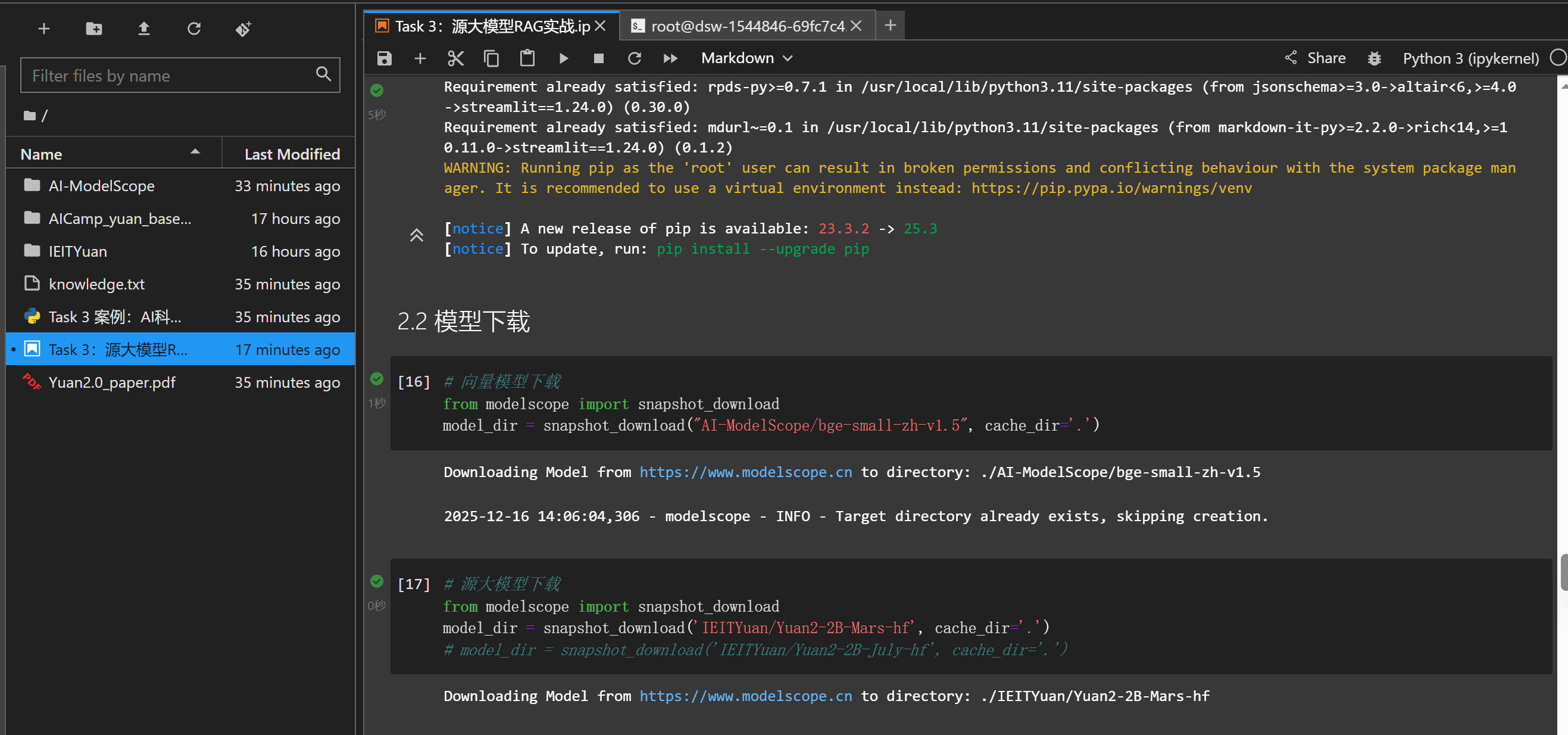
源大模型下载:
# 源大模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('IEITYuan/Yuan2-2B-Mars-hf', cache_dir='.')
2.3 体验新模型
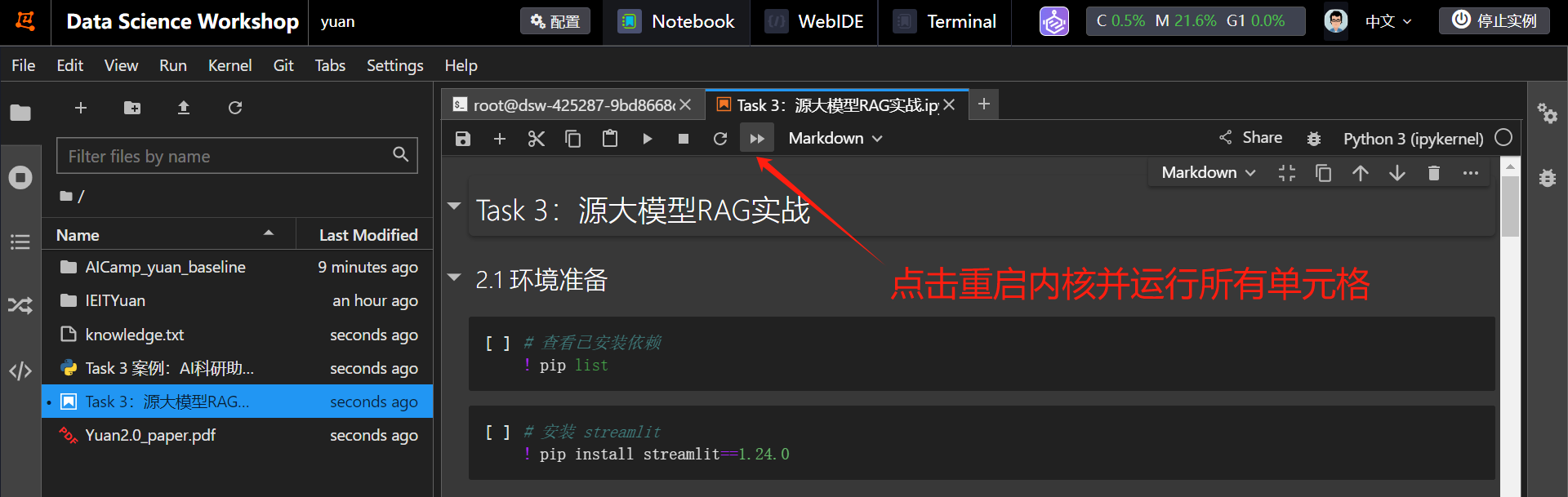
将Notebook中刚刚下载好的Task 3:源大模型RAG实战 # 源大模型下载 和 # 创建llm对象 下面的被注释的行把前面是注释删掉,点击 重启内核并运行所有单元格 即可体验!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)