【干货收藏】大模型Agent开发完全指南:12个核心原则详解
文章介绍了Agent开发的12个核心原则,强调Agent不同于传统软件,通过目标和规则实现实时决策。重点在于提示词和上下文工程,开发者需掌控提示词和上下文窗口,避免过度封装的AI框架。应构建小型专注的Agent,将其设计为无状态函数,通过简单API实现启动/暂停/恢复,利用工具调用与人类交互,并将错误信息注入上下文实现自我修复。灵活控制流和统一状态管理是构建高效Agent的关键。
文章介绍了Agent开发的12个核心原则,强调Agent不同于传统软件,通过目标和规则实现实时决策。重点在于提示词和上下文工程,开发者需掌控提示词和上下文窗口,避免过度封装的AI框架。应构建小型专注的Agent,将其设计为无状态函数,通过简单API实现启动/暂停/恢复,利用工具调用与人类交互,并将错误信息注入上下文实现自我修复。灵活控制流和统一状态管理是构建高效Agent的关键。
前言
本文来自于对 Agent 12 原则的总结。
总结后,感受如下:
- Agent 是软件,但不同于传统软件(需要工程师编写每个步骤和边缘情况),Agent 只需要给出目标和一组规则,通过 Agent 实时决策以确定执行路径,从而达成最后目标。
- Agent 给软件开发带来的改变:Agent 允许工程师编写更少的控制型代码,只需要将“图的边(Edge)”提供给 LLM,让他自行决策下一步执行节点。
- Agent 开发中,最重要的是提示词和上下文工程,这是工程师与 LLM 交互的核心方式。
- 过度封装的 AI 框架不一定带来好的性能,只有具备足够的灵活性,你才可以针对特定用例尝试出最好的结果。
- 顶尖 1% 的 AI 应用与其余 99% 的 AI 应用的构建方式都不相同。
- 达到 80% 的质量标准很容易,但对大多数用户来说,80% 是不够的,要想提升到 80% 以上就需要对框架、提示词、流程等进行逆向工程,从头开始。
01-自然语言到工具调用(Natural Language to Tool Calls)
**原则:**Agent 的核心模式之一是将自然语言转换为结构化的工具调用。
Agent 内部的 LLM 负责对自然语言进行解析,生成结构化的数据以描述要调用的工具,之后由确定性代码进行工具调用。
02-掌控你的提示词(Own your prompts)
**原则:**不要将你的提示词外包给框架,否则难以通过逆向工程对提示词调优,将更合适的 token 喂给模型。
**重要性:**提示词是应用与 LLM 交互的关键接口。
像对待核心代码一样,对提示词进行版本化、测试和维护。
优势:
- 完全控制:精确编写 Agent 所需指令,无需黑盒抽象。
- 测试和评估:像对待其他代码一样,为你的提示词构建测试和评估。
- 迭代:根据实际反馈快速修改提示词。
- 透明:确切知道你的 Agent 正在执行的具体指令。
- 灵活性:可以尝试奇怪的非标准提示词玩法,以模型达到最佳性能为目的。
03-掌控你的上下文窗口(Own your context window)
**原则:**在任何时候,你向 Agent 里的 LLM 输入的内容都是“到目前为止发生了…,下一步是…”。
**重要性:**LLM 是无状态函数,要想获取最佳输出,就需要提供最佳输入。
掌控你的上下文窗口,不一定要使用基于标准消息的格式向 LLM 传递上下文,只要具备足够的灵活性,你就可以尝试一切,直到获取最佳输出。
出色的上下文要具备:
- 提供给模型的提示词和指令。
- 检索到的任何文档和外部数据(例如 RAG)。
- 任何过去的状态、工具调用、结果或其他历史记录。
- 来自相关但彼此独立的历史对话中的消息或事件(记忆)。
- 指定需要输出的结构化数据类型。
灵活性
Agent 与 LLM 通常使用标准的消息交互格式,分为 SystemMessage、UserMessage、AssistantMessage、ToolMessage:
[ { "role": "system", "content": "You are a helpful assistant..." }, { "role": "user", "content": "Can you deploy the backend?" }, { "role": "assistant", "content": null, "tool_calls": [ { "id": "1", "name": "list_git_tags", "arguments": "{}" } ] }, { "role": "tool", "name": "list_git_tags", "content": "{\"tags\": [{\"name\": \"v1.2.3\", \"commit\": \"abc123\", \"date\": \"2024-03-15T10:00:00Z\"}, {\"name\": \"v1.2.2\", \"commit\": \"def456\", \"date\": \"2024-03-14T15:30:00Z\"}, {\"name\": \"v1.2.1\", \"commit\": \"abe033d\", \"date\": \"2024-03-13T09:15:00Z\"}]}", "tool_call_id": "1" }]
标准的消息交互格式可以满足绝大多数场景,但是如果你想要真正充分利用 LLM,就需要以最节省 token 和注意力的方式将上下文输入 LLM。
相比于标准的交互格式,可以尝试针对你的用例进行优化,构建自定义的上下文格式。
下边是将整个上下文窗口都放入 UserMessage 内部的示例:
[ { "role": "system", "content": "You are a helpful assistant..." }, { "role": "user", "content": | Here's everything that happened so far: <slack_message> From: @alex Channel: #deployments Text: Can you deploy the backend? </slack_message> <list_git_tags> intent: "list_git_tags" </list_git_tags> <list_git_tags_result> tags: - name: "v1.2.3" commit: "abc123" date: "2024-03-15T10:00:00Z" - name: "v1.2.2" commit: "def456" date: "2024-03-14T15:30:00Z" - name: "v1.2.1" commit: "ghi789" date: "2024-03-13T09:15:00Z" </list_git_tags_result> what's the next step? }]
优势:
- 信息密度:以最大化 LLM 理解的方式构建信息。
- 错误处理:以有助于 LLM 从错误中恢复的方式去包含错误信息。(考虑在错误解决后,将其上下文窗口隐藏,减少无用信息)
- 安全性:控制传递给 LLM 的信息,过滤掉敏感数据。
- 灵活性:根据你用例的最佳实践调整上下文的格式。
- Token 效率:优化上下文格式,以提高 Token 使用效率和 LLM 理解。
如下图,以 XML 格式自定义消息,可以实现更高的信息密度(相同的信息,左侧占用 87 token、右侧占用 57 token):

img
04-工具只是结构化输出(Tools are just structured outputs)
**原则:**工具不需要很复杂,工具的本质是来自于 LLM 的结构化输出。
❝
工具的本质是通过 LLM 选择工具,触发确定性代码,最终得到结构化输出。
举例:假设你有两个工具 CreateIssue 和 SearchIssue,要求 LLM 选择一个工具调用。
本质其实就是先让 LLM 输出结构化数据,用于表示选择的工具,之后再通过确定性代码去调用 LLM 选择的工具。
05-统一执行状态和业务状态(Unify execution state and business state)
**原则:**统一执行状态和业务状态。
对于 AI 应用,如果要对执行状态和业务状态进行分离,来跟踪当前步骤、下一步、等待状态、重试计数等,这可能涉及到复杂的抽象,虽然可能是值得的,但对你的用例来说可能有些“重”了。
分离会带来复杂性,如果可能,尽可能简化并统一这些内容:
- 执行状态:当前步骤、下一步、等待状态、重试次数等。
- 业务状态:Agent 工作流到目前为止发生的事情(例如消息列表、工具调用和结果等)。
实际上,可以通过设计应用,仅凭上下文窗口就能推断出全部的执行状态。
大多数情况下,执行状态(当前步骤、等待状态等)只是目前为止发生的事情的元数据。
小部分情况下,有一些内容无法放入上下文窗口(如会话 ID、密码上下文等),但你的目标应该是尽量减少这类内容。
优势:
- 简洁性:为所有状态提供单一事实来源。
- 序列化:线程可以轻松地进行序列化/反序列化。
- 调试:完整的历史记录在同一处可见。
- 灵活性:仅通过添加新的时间类型即可轻松新增状态。
- 恢复:仅需加载线程即可从任意点恢复。
- 分叉:通过将线程的子集复制到新的上下文,可在任意时刻分叉线程。
- 人机界面与可观测性:可轻松将线程转换为人类可读的 Markdown 或 Web 应用界面。
06-通过简单的API实现启动/暂停/恢复(Launch/Pause/Resume with simple APIs)
**原则:**Agent 就是程序,要像普通服务一样,能够通过简单的 API 实现启动、暂停、恢复和停止。
暂停:当需要执行长耗时任务,智能体应该能够暂停。
恢复:外部触发器(例如 webhook)应当能够让 Agent 从中断处恢复,而无需与 Agent 编排器深度耦合。
07-通过工具调用与人类联系(Contact humans with tool calls)
**原则:**让 LLM 通过工具调用与人类进行交互,从而始终输出结构化数据。
该原则建议 Agent 与人类交互时,不要只是简单地向控制台输出“我已完成任务”等纯文本内容,而是使用工具调用始终输出结构化数据。
该原则可能不会带来任何性能提升,但你应该尝试一些奇怪的方法,以获取最佳结果。(灵活性)
优势:
-
清晰的指令:不同类型的人类交互“工具”,能让 LLM 更准确地表达意图(输出内容结构化)。
-
内循环和外循环:支持不同于 ChatGPT 风格的代理工作流程。
-
❝
外循环 Agent:Agent 启动后执行一系列任务,任务耗时较长,当他们需要帮助时会主动联系人类(例如高风险任务中会寻求人工审批)。
外循环文章:https://theouterloop.substack.com/p/openais-realtime-api-is-a-step-towards
-
多人访问:可以通过结构化时间轻松跟踪并协调来自不同人类的输入。
-
多代理:简单的抽象可轻松扩展以支持
Agent -> Agent的请求和响应。 -
持久耐用:与 Factor-06 结合,可构建持久、可靠且可内省的多人工作流。
08-掌控你的控制流(Own your control flow)
**原则:**构建符合你特定用例的控制结构。
掌控并自定义控制结构,以下是几种控制流模式的示例:
- 请求澄清:模型请求更多的信息,跳出循环并等待人类的回复。
- 拉取 Git 标签:模型请求 Git 标签列表,并将其放入上下文窗口,然后返回给模型。
- 部署后端服务:模型被请求部署后端服务,这是高风险任务,因此需要中断循环并等待人工批准。
例如 - 对于所有的 AI 框架,我最重要的功能诉求是,我们需要能够中断一个正在工作的 Agent,并在之后恢复,尤其是在选择工具和调用工具的时候。
如果没有这种级别的可恢复性控制,就无法在工具调用前进行审查或批准。
09-将错误信息压缩到上下文窗口(Compact Errors into Context Window)
**原则:**将错误信息注入上下文供 LLM 理解学习,并在后续任务中进行修复。
Agent 的优势之一是自我恢复,当工具调用出现错误时,把错误信息注入上下文供 LLM 理解并修复,这种方式需要为特定工具实现错误计数,当达到尝试次数上限时(例如 3 次),考虑将错误上报人工处理。
不一定要将原始错误放回去,你完全可以重构它的表示方式。
优势:
- 自我修复:LLM 可以读取错误信息,并在后续工具调用中修复。
- 持久性:即使一次工具调用失败,Agent 也能继续运行。
10-小型、专注的 Agent(Small, Focused Agents)
**原则:**与其构建试图包揽一切的庞然大物,不如构建小型、专注的 Agent。
随着上下文的扩展, LLM 更容易迷失方向。
❝
注意力稀缺性源于 LLM 的架构限制,LLM 基于 transformer 架构,该架构允许每个 token 关注上下文中的所有其他 token,如果有 n 个 token,就会存在 n^2 个成对关系。
随着上下文长度增加,模型捕捉成对关系的能力逐渐下降,从而在上下文长度和注意力集中度之间产生矛盾。
优势:
- 可管理的上下文:更小的上下文窗口意味着更好的 LLM 性能。
- 职责明确:每个 Agent 都有明确的职责范围和目标。
- 更高的可靠性:更不容易在复杂的工作流中迷失方向。
- 更易于测试:更容易测试和验证特定功能。
- 调试改进:问题发生时更容易识别并修复。
11-随时随地触发,满足用户需求(Trigger from anywhere, meet users where they are)
**原则:**允许用户通过任何渠道触发 Agent,同时,Agent 以相同的渠道进行回复。
优势:
- 在用户所在的场景触达用户:这有助于你构建更像真人、或至少像数字同事的 AI 应用。
- 外循环代理:允许代理由非人类因素触发(如事件、定时任务、故障等)。它们可以工作5、20、90 分钟,但在到达关键节点时,可以联系人工寻求帮助、反馈或审批。
- 高风险工具:如果你能快速将各种人员纳入闭环,就可以赋予 Agent 更高风险的操作权限(例如发送外部电子邮件、更新生产环境数据等)。通过明确的规范确保全程可审计,并增强
12-把你的 Agent 设计为无状态函数(Make your agent a stateless reducer)
**原则:**把你的 Agent 设计为无状态函数。
Agent 其实只包含两个部分:
- 通过 LLM 决定下一步。
- 将结果放入上下文窗口。
- 循环…
Agent 仅此而已,过度抽象封装的 AI 框架,会带来更多的复杂度、更高的学习成本,并且会降低开发者的灵活性。
2025年伊始,AI技术浪潮汹涌,正在深刻重塑程序员的职业轨迹:
阿里云宣布核心业务全线接入Agent架构;
字节跳动后端岗位中,30%明确要求具备大模型开发能力;
腾讯、京东、百度等技术岗位开放招聘,约80%与AI紧密相关;
……
大模型正推动技术开发模式全面升级,传统的CRUD开发方式,逐渐被AI原生应用所替代!
眼下,已有超60%的企业加速推进AI应用落地,然而市场上能真正交付项目的大模型应用开发工程师,却极为短缺!实现AI应用落地,远不止写几个提示词、调用几个接口那么简单。企业真正需要的,是能将业务需求转化为实际AI应用的工程师!这些核心能力不可或缺:
✅RAG(检索增强生成):为模型注入外部知识库,从根本上提升答案的准确性与可靠性,打造可靠、可信的“AI大脑”。
✅Agent(智能体): 赋能AI自主规划与执行,通过工具调用与环境交互,完成多步推理,胜任智能客服等复杂任务。
✅微调:如同对通用模型进行“专业岗前培训”,让它成为你特定业务领域的专家。
大模型未来如何发展?普通人如何抓住AI大模型的风口?
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
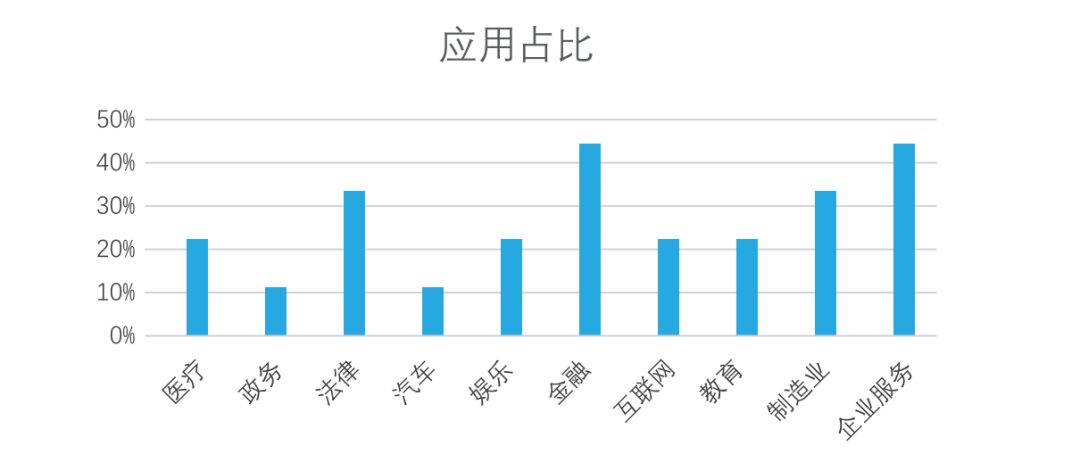
未来大模型行业竞争格局以及市场规模分析预测: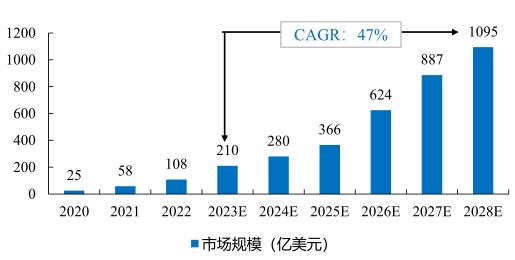
掌握AI能力的程序员,其薪资水位已与传统开发拉开显著差距。当大厂开始优化传统岗位时,却为AI大模型人才开出百万年薪——而这,在当下仍是一将难求。
技术的稀缺性,才是你「值钱」的关键!
AI浪潮,正在重构程序员的核心竞争力!不要等“有AI项目开发经验”,成为面试门槛的时候再入场,错过最佳时机!
那么,我们如何学习AI大模型呢?
在一线互联网企业工作十余年里,我指导过不少同行后辈,经常会收到一些问题,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题,也不是三言两语啊就能讲明白的。
所以呢,我专为各位开发者设计了一套全网最全最细的大模型零基础教程,从基础到应用开发实战训练,旨在将你打造成一名兼具深度技术与商业视野的AI大佬,而非仅仅是“调参侠”。
同时,这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
Part 1 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
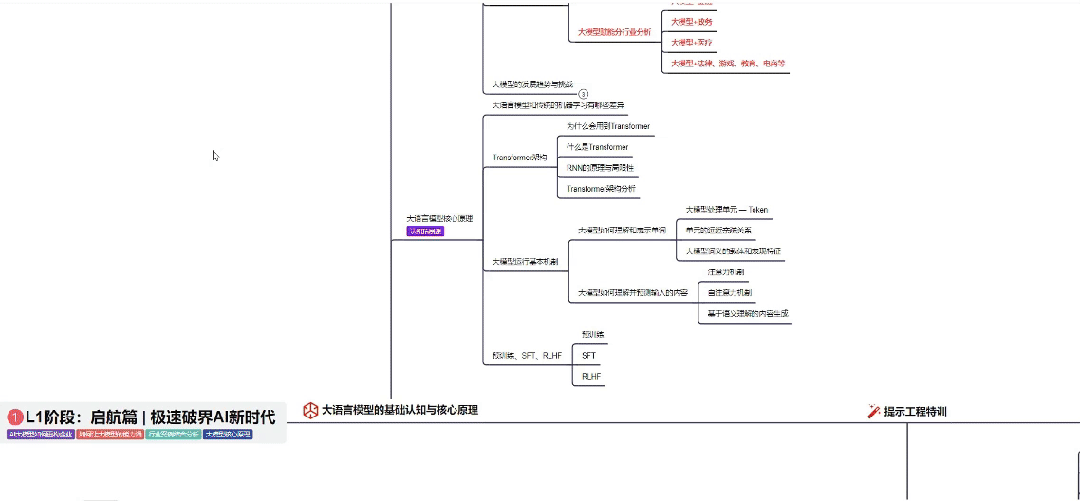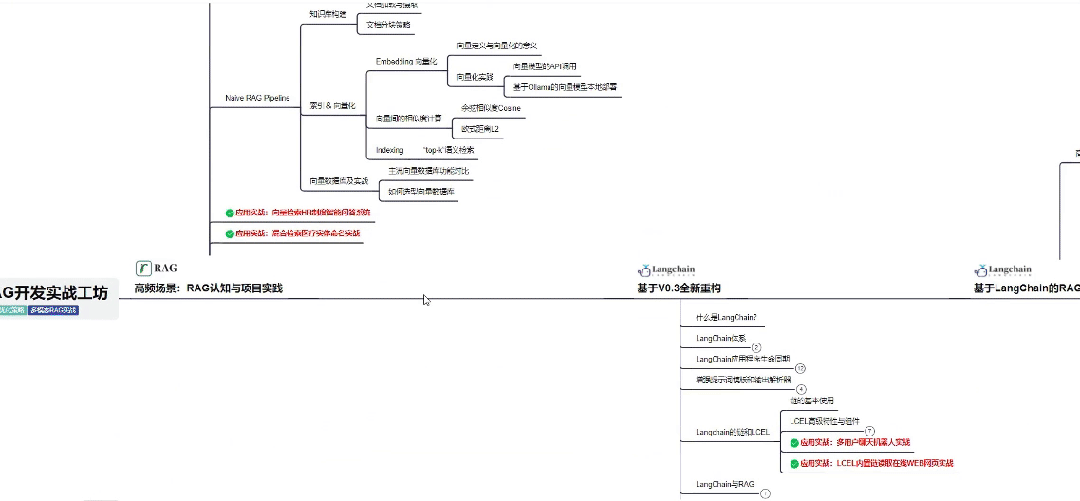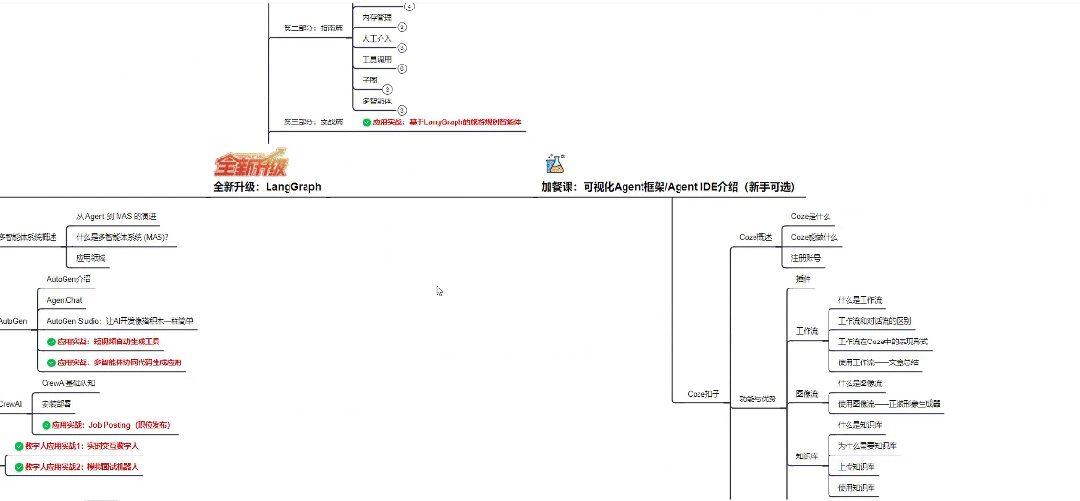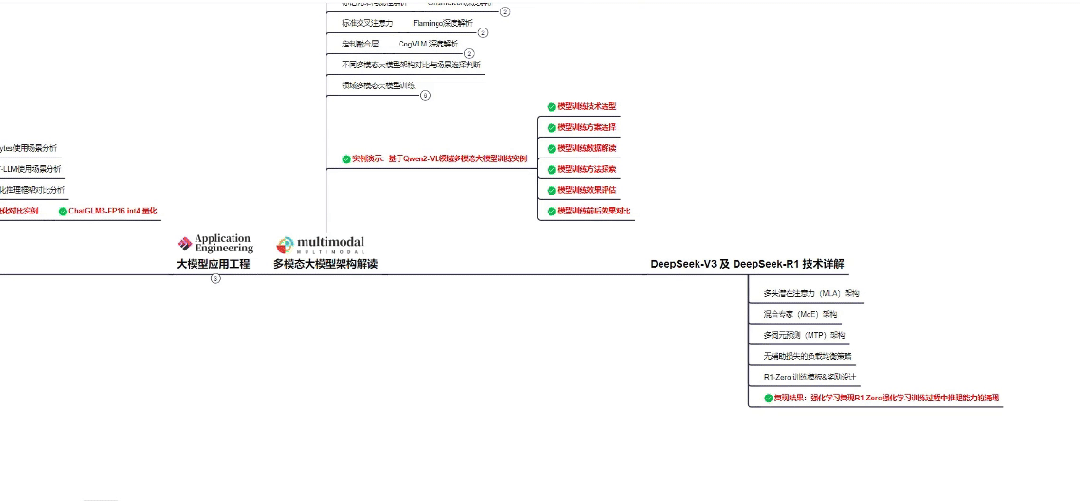
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
Part2 全套AI大模型应用开发视频教程
包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点。剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
01 大模型微调
- 掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
- 学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
02 RAG应用开发
-
深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
-
应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
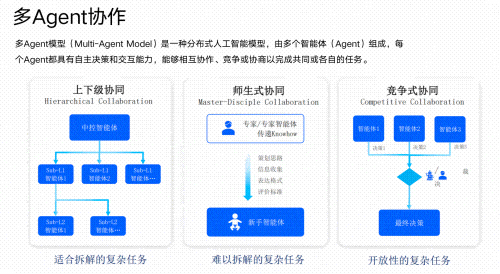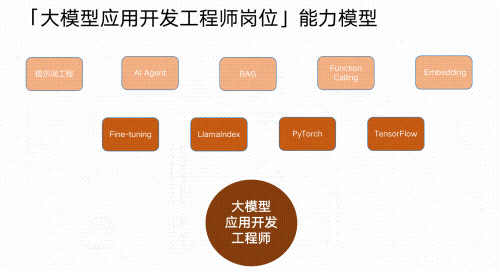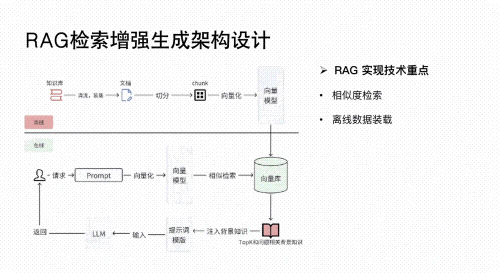
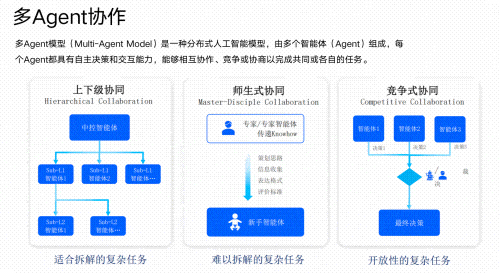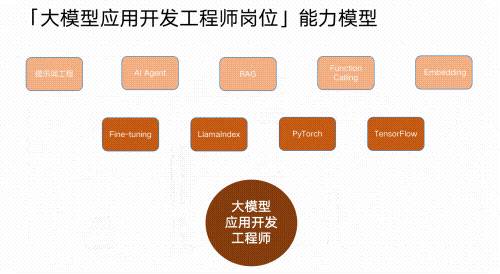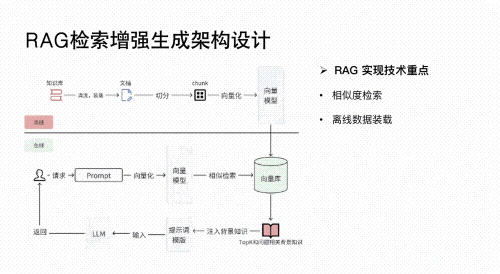
03 AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。
Part3 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

Part4 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
Part5 大模型项目实战&配套源码
学以致用,热门项目拆解,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
学完项目经验直接写进简历里,面试不怕被问!👇
Part6 AI产品经理+大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

最后,如果你正面临以下挑战与期待:
- 渴望转行进入AI领域,顺利拿下高薪offer;
- 即将参与核心项目,急需补充AI知识补齐短板;
- 拒绝“35岁危机”,远离降薪裁员风险;
- 持续迭代技术栈,拥抱AI时代变革,创建职业壁垒;
- ……
那么这份全套学习资料是一次为你量身定制的职业破局方案!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!与其焦虑……
不如成为「掌握AI大模型的技术人」!
毕竟AI时代,谁先尝试,谁就能占得先机!
最后,祝大家学习顺利,抓住机遇,共创美好未来!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献302条内容
已为社区贡献302条内容

所有评论(0)