[实战复盘] 性能提升 400 倍:我们为何放弃 Milvus 选择 PostgreSQL 做向量检索?
本文记录了一次从MySQL+Milvus到PostgreSQL(pgvector)的架构升级实践。针对AIoT业务中"结构化过滤+向量检索"的混合场景,原方案存在跨系统I/O瓶颈,导致查询耗时高达27秒。通过迁移1300万+数据至PostgreSQL并采用HNSW索引,实现了96%+召回率下0.03秒的查询响应,性能提升超400倍。测试表明,在1亿数据量级内,单机Postgre
在“强结构化筛选 + 向量相似度搜索”的混合场景下,传统的“MySQL(元数据)+ Milvus(向量)”割裂架构面临巨大的 I/O 瓶颈。
本文记录了一次真实的架构升级:我们将 1300万+ 数据迁移至 PostgreSQL (pgvector)。在保持 96%+ 召回率的前提下,小图场景查询耗时从 27秒 骤降至 0.03秒,性能提升超 400 倍,同时通过HNSW 索引大幅降低了内存消耗。
一、 背景:当“专业”遇上“割裂”
在我们的 AIoT 业务(自动驾驶/视频分析)中,图片和文本检索是一个核心场景。业务逻辑非常典型,属于混合搜索(Hybrid Search):
-
输入:图片或文本(转为 Embedding 向量)。
-
过滤:必须满足特定的元数据条件(如:传感器=FrontWide,距离<100米,CaseId=XXX)。
-
搜索:在过滤后的范围内,寻找最相似的 Top-K 结果。
1.1 原有架构:MySQL + Milvus
为了利用向量数据库的“专业能力”,我们最初采用了业界通用的分库架构:
-
MySQL:存储结构化元数据。
-
Milvus:存储向量数据(Vector)和 ID。
1.2 现实的痛点
这种架构在“先过滤,后搜索”的场景下十分尴尬。
-
ID 搬运工:我们需要先在 MySQL 查出符合条件的数万甚至数百万个 meta_id,拉回应用层,再作为过滤条件传给 Milvus。
-
网络瓶颈:大量 ID 的传输造成了巨大的网络开销。
-
资源浪费:Milvus 机器规格高达 384核 / 1.5T 内存,索引常驻内存(占 750GB+),维护成本极高。
实测结果:在小图场景下,单次查询平均耗时 23s - 27s,基本不可用。
二、 核心原理:为什么 pgvector 能赢?
我们需要一个能将“关系型过滤”和“向量检索”在存储引擎层融合的方案。PostgreSQL + pgvector 插件成为了最佳选择。
但在展示惊人的测试数据前,我们需要先理解支撑这一切的核心算法 —— HNSW。
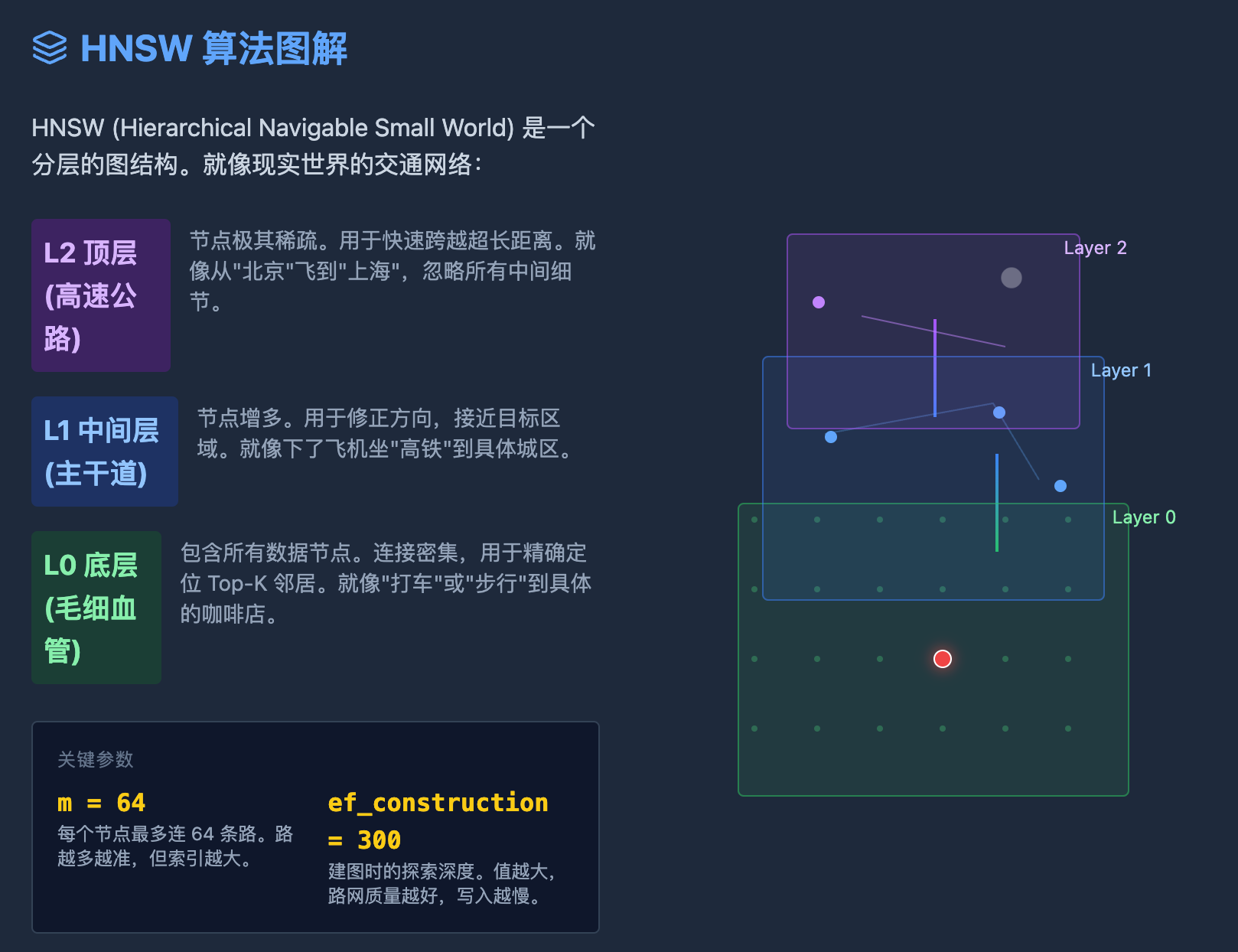
2.1 硬核科普:什么是 HNSW 算法?
HNSW (Hierarchical Navigable Small World,分层可导航小世界) 是目前业界最顶尖的向量索引算法(Milvus, ES, PG 都在用)。
如果把向量搜索比作“在全国地图上找一家具体的咖啡店”,朴素的搜索是挨家挨户敲门(暴力计算),而 HNSW 的做法是“坐飞机 -> 转高铁 -> 打车 -> 步行”。
它结合了两个核心思想:
-
小世界网络 (Small World):
想象一下“六度分隔理论”,每个人都认识几个“远方”的朋友。在数据图中,绝大多数节点互不相连,但任何两个节点都可以通过少数几步跳跃到达。-
搜索逻辑:贪婪搜索(Greedy Search)。看哪个邻居离目标最近,就跳过去,直到找不到更近的。
-
-
跳表分层 (Hierarchical / Skip List):
为了解决“在亿级数据中平铺搜索还是很慢”的问题,HNSW 引入了分层结构:-
L2 顶层(高速公路):节点稀少,连接跨度极大。主要用于快速定位大概区域(比如从北京一下子跳到上海)。
-
L1 中间层(主干道):节点稍多,用于修正方向。
-
L0 底层(毛细血管):包含所有数据,连接密集,用于精确定位目标。
-
HNSW 的搜索过程:
从顶层入口出发,利用长连接快速逼近目标区域,找到局部最优后“降落”到下一层,继续逼近,直到在底层找到真正的 Top-K。
2.2 pgvector 的“杀手锏”:索引参数调优
在 PG 中,我们这样创建索引:
CREATE INDEX ON image_vectors USING hnsw (vector vector_cosine_ops)
WITH (m = 64, ef_construction = 300);这里有两个关键参数决定了性能与精度的平衡:
-
m = 64:每个节点最多存 64 个邻居(边)。这就好比修路,路修得越多(M越大),越容易找到捷径,不容易走进死胡同,召回率越高,但索引体积也越大。
-
ef_construction = 300:在修路(建索引)的时候,我们向外探索 300 个节点来寻找最佳邻居。这个值越大,路网质量越高,查询越准,但写入越慢。
正是基于 HNSW 的高效导航,配合 PostgreSQL 强大的 Cost-based Optimizer (查询优化器),数据库可以智能地决定是“先用 B-Tree 索引过滤数据,再计算向量”,还是“直接在 HNSW 图上搜索并实时过滤”,彻底消除了跨系统 I/O。

三、 性能大比拼:实测数据说话
我们抽取了 1300万+ 记录进行对比测试。
3.1 惊人的性能飞跃
| 场景用例 | 原方案 (MySQL+Milvus) | 新方案 (PG, 有索引未分片) | 性能提升 | 准确率 (重叠率) |
| Construction Sign | 27.11s | 0.11s | 246倍 | 99.00% |
| Forklift | 23.84s | 0.03s | 794倍 | 100.00% |
| Minicar | 25.82s | 0.06s | 430倍 | 100.00% |
| Trailer | 24.66s | 0.11s | 224倍 | 86.87% |
| 全图搜索 (Bike) | 7.06s | 2.14s | 3.3倍 | 97.00% |
数据解读:
在带有具体过滤条件的小图场景下,PG 展现了统治级的优势,平均提升 400 倍以上。
在全图搜索(几乎无过滤)场景下,PG 依然快了 3 倍左右,且准确率保持在 97% 的高位。
3.2 意料之外的发现:分片竟然变慢了?
为了测试扩展性,我们使用了 Citus 插件进行了分片测试,结果出乎意料:
-
单表未分片:0.03s - 0.11s
-
Citus 分片后:0.19s - 0.21s
深度分析:
HNSW 算法本身极快。在 1300万 这个数据量级下,单机计算是毫秒级的。引入分片后,查询需要分发到 Worker 节点再聚合,网络通信的 RTT(往返时延)反而超过了计算时间。
结论:不要盲目迷信分布式。在 PG 上,单机支撑 5000万-1亿 向量数据通常是性价比最高的选择,过早分片反而引入不必要的开销。
3.3 索引与内存对比
-
Milvus:索引强制加载进内存,占用约 750GB(In-memory index)。
-
PostgreSQL:HNSW 索引大小约 26GB。PG 依赖操作系统的 Page Cache,不需要将所有索引常驻内存,对硬件要求大幅降低。
四、 为什么不选 Elasticsearch?
既然要换,为什么不选大名鼎鼎的 ES?
-
架构复杂度:我们的元数据本就在关系型数据库中。使用 PG 是“原地升级”,引入 ES 则是“数据异构”,需要解决同步延迟和一致性问题。
-
资源消耗:ES 是 Java 进程,JVM 的堆内存(Heap)和垃圾回收(GC)在高并发下是潜在的抖动源。而 PG 基于 C 语言,更加轻量稳定。
-
算法同源:ES 的向量检索底层(Lucene)同样使用的是 HNSW 算法。在算法层面两者没有代差,但在结构化数据的混合查询优化上,关系型数据库出身的 PG 更胜一筹。
五、 总结与建议
这次从 Milvus 到 PostgreSQL 的迁移,不仅是一次性能优化,更是一次架构的回归与简化。
主要收益:
-
极速响应:查询延迟从“秒级”跨入“毫秒级”。
-
架构极简:下线了昂贵的专用向量集群,一套 PG 集群搞定所有。
-
成本降低:大幅节省了内存和服务器成本。
给开发者的建议:
-
如果你的场景是“复杂的元数据过滤 + 向量检索”,PostgreSQL + pgvector 目前是地表最强选择之一。
-
理解 HNSW:根据业务对准确率的要求,合理调整 m 和 ef_construction。如果不需要 99% 的准确率,适当降低参数可以获得更小的索引和更快的写入速度。
-
克制分片:数据量未破亿时,单机 PG + SSD 往往比分布式方案更快。
本文基于真实业务性能测试数据整理,转载请注明出处。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)