【AI】免费的代价?Google AI Studio 使用指南与 Cherry Studio + MCP 实战教程
Google AI Studio 与Cherry Studio 食用指南
🟢 定义速览:
- Google AI Studio 是使用谷歌相关模型的网页;
- Cherry Studio 是可以使用多种模型API Key的桌面软件。
文章目录
一、Google AI Studio
本小节内容基本可以在Gemini API文档中找到更详细的描述。
🔗URL:https://aistudio.google.com/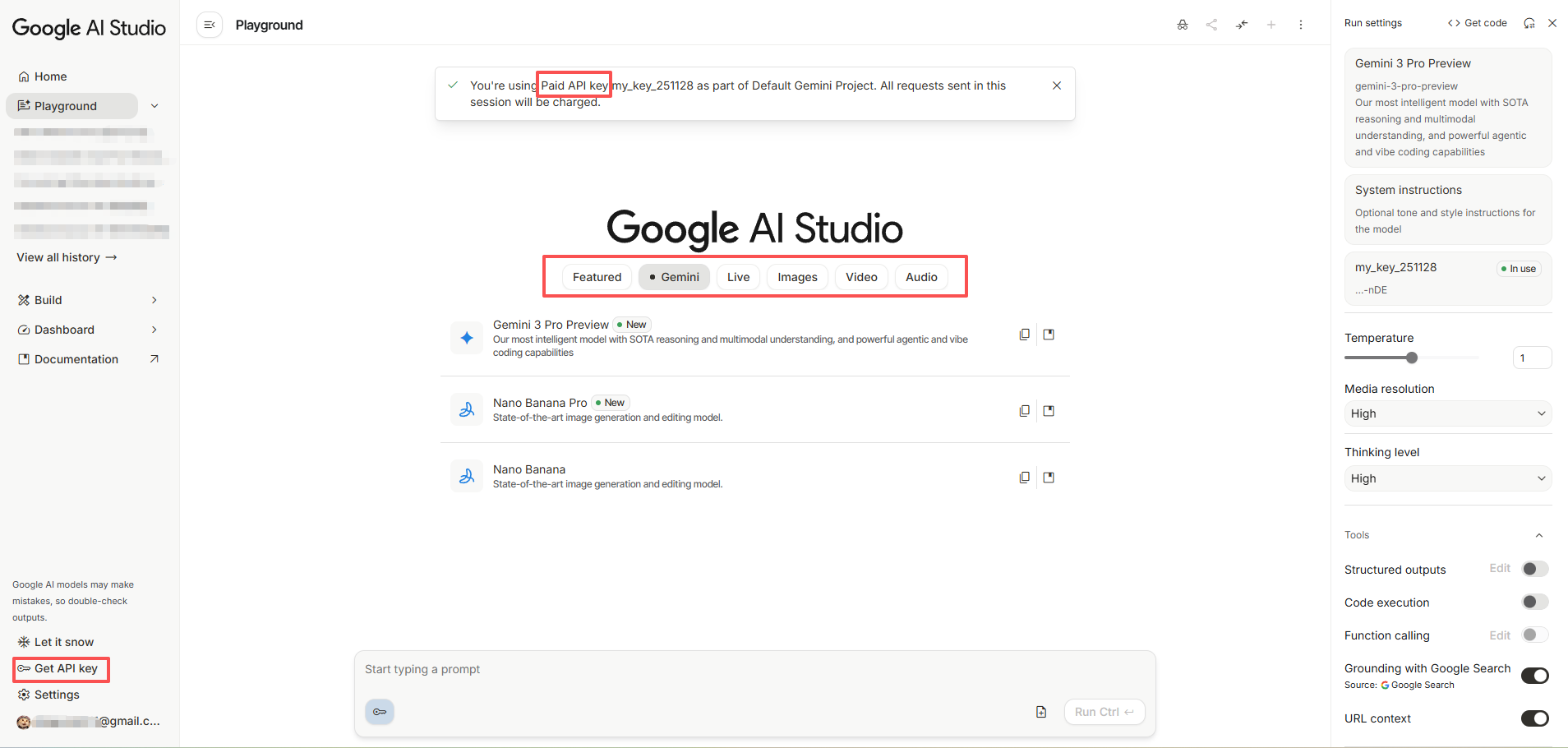
1.1 和Gemini网页版的区别
简单来说就是:Google AI Studio 可自定义的设置更多。
- 模型选择:Gemini 网页版 只能指定是最新模型的Flash(快速)或者Pro(思考)模式。而Studio 可以指定多种模型。
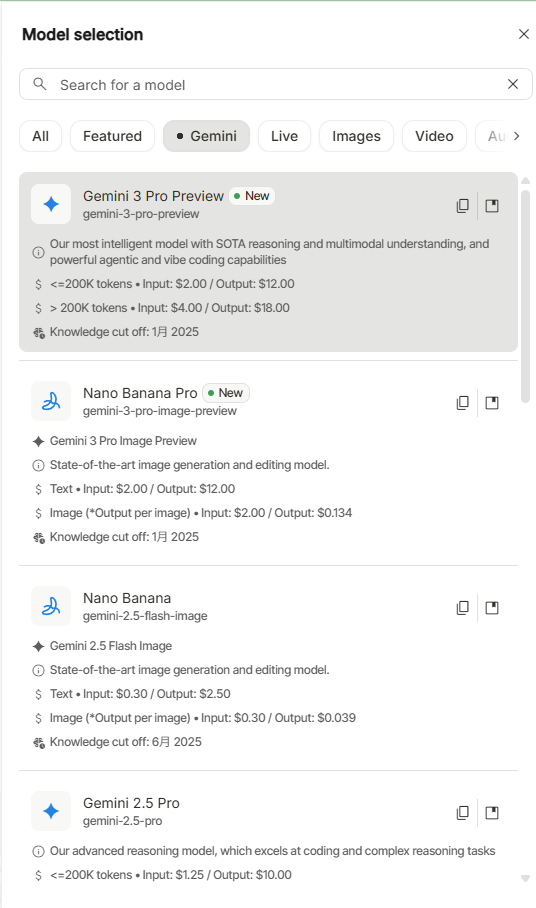
- 参数调整:AI Studio以调整 Temperature(创造性 vs 严谨性)、Top-K/Top-P、Output Length(输出长度限制)、图片数量、图片分辨率等等
- Gemini 网页版的Deep Research、Canvas等功能在AI Studio是没有的。
- 对上传的文件格式支持不同:这方面Gemini 网页版支持更丰富一些,如:AI Studio 里面不能上传
xlsx表格。
其它的则是相似的,如AI Studio可以预设多个提示词(AI Studio里面叫做:System instructions),而Gemini 网页版可以在设置-个人使用场景中设置全局的指令,也可以创建Gem(即给特定场景设置专属指令/提示词,知识库),以应对不同的需求。
1.2 免费层级的用量限制
Google AI Studio 里面可以免费使用最新的模型(以及旧模型),但有限制和代价。
速率限制通常从以下三个维度进行衡量:
- 每分钟请求数 (
RPM)- 每分钟 token 数(输入)(
TPM)- 每日请求数 (
RPD)- 我们会根据每项限制评估您的用量,如果超出任何一项限制,系统都会触发速率限制错误。例如,如果您的 RPM 限制为 20,那么在一分钟内发出 21 个请求会导致错误,即使您未超出 TPM 或其他限制也是如此。
- 速率限制按项目应用,而不是按 API 密钥应用。每天的请求数 (RPD) 配额会在太平洋时间午夜重置。
- 限额因所用模型而异,并且部分限额仅适用于特定模型。例如,每分钟生成的图片数 (IPM) 仅针对能够生成图片的模型(Imagen3)计算,但在概念上与 TPM 类似。其他模型可能设有每日 token 数量上限 (TPD)。
- 实验性模型和预览版模型的速率限制更为严格。
来源:Gemini API文档-速率限制
🟢速率限制与项目的用量层级(Tier)相关联: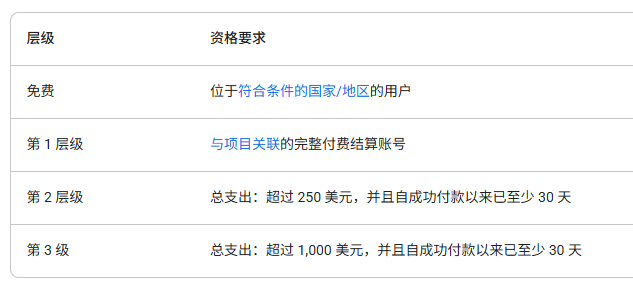
🟢这里就把Tier1的速率限制列出来:这是变化的,只作为参考,仅仅是发文时的数据,这里是非批量API的速率限制
主要看最后一列:每日请求次数限制(RPD)即可。
免费层级的我没找到准确数据(也懒得找😆),但据我以前的使用经验:对话一般每天足够使用的(除非你1+1这种问题也要问),图片生成数量很少,好像就几张。- 只要绑定有效的卡,就可以升级
Tier1,使用这个key是付费的。- 免费层级,也可以创建API Key,这个key你可以在你的代码中使用,或者其它软件中使用,速率一样有限制。
- 网页对话的Gemini3.0 Pro不适用以上内容,也不是本文的主题。
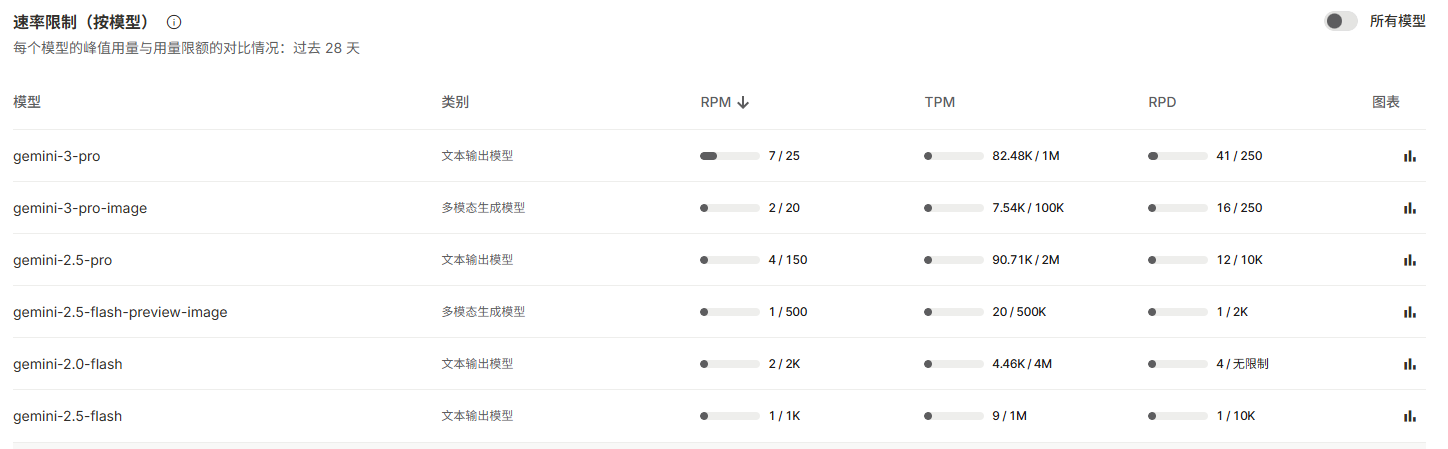
1.3 Google AI Studio 隐私问题(重要)
1.31 案例分享
🟠三星源码泄露事件(2023):
- 这是所有大模型(包括 Google Gemini)“免费层级”隐私警告的源头案例。虽然主角是 ChatGPT,但它直接导致了 Google 随后更新了极其严格的内部政策,并警告用户:“免费层级的对话就是训练数据”。
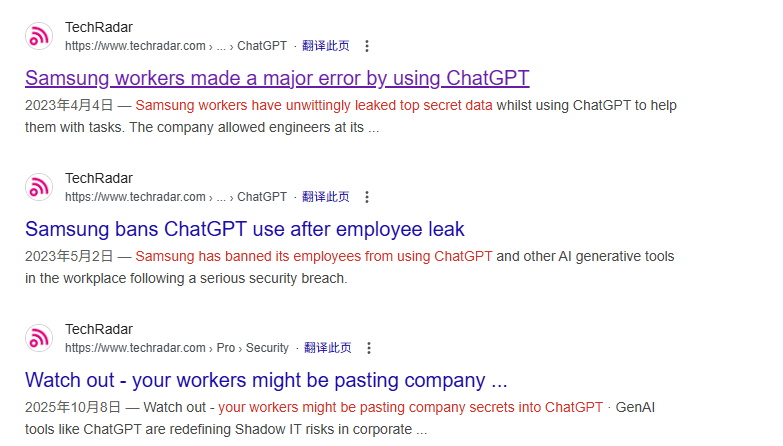
🟠针对 Google Gemini 的“秘密监控”集体诉讼 (2025年11月):
1.32 Gemini API 附加服务条款
直接看官方文档吧: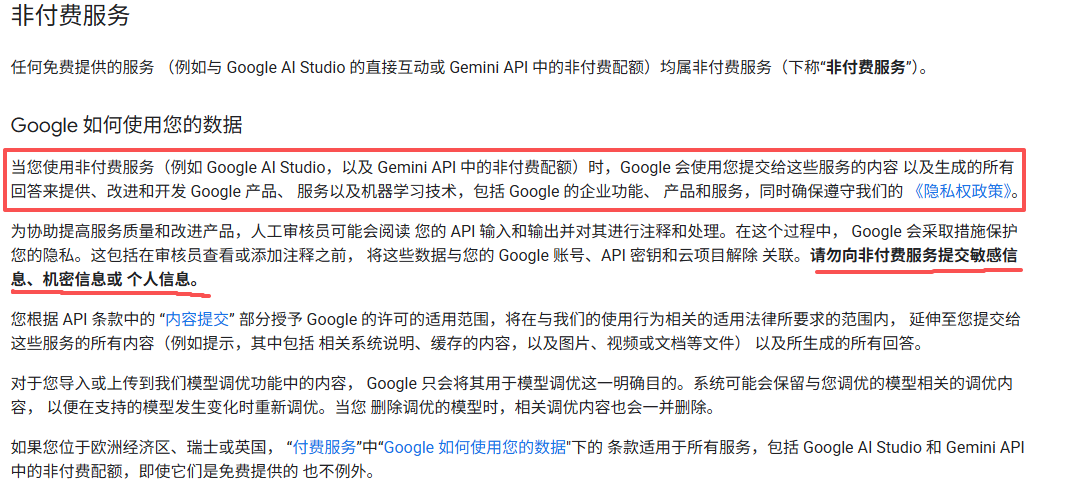
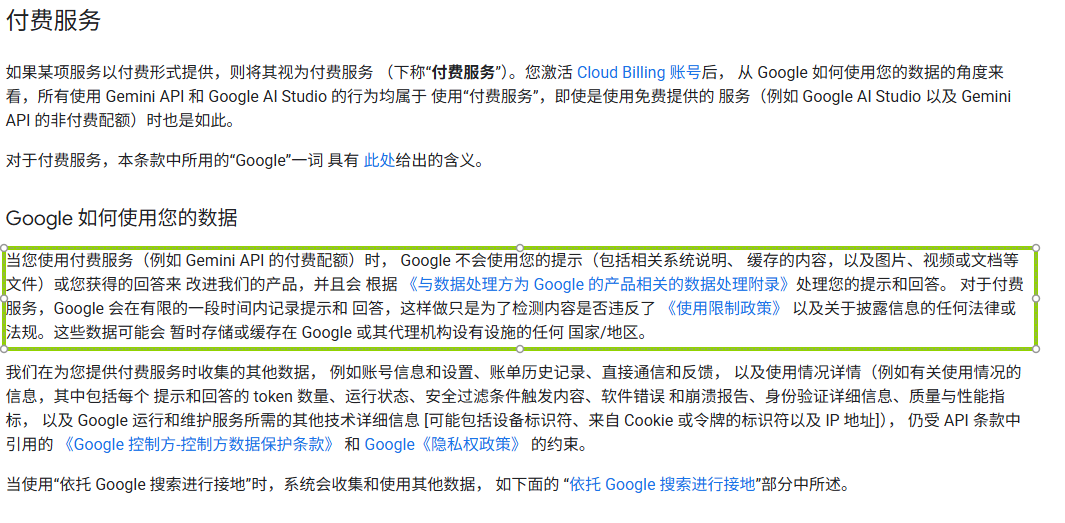
即使你使用的是后者,也最好不要上传敏感、机密、个人信息,开源尚且有风险,闭源就更不必说了。(其它领域也是类似,如不要向网盘上传我列举的那些内容)
1.4 API Key的价格
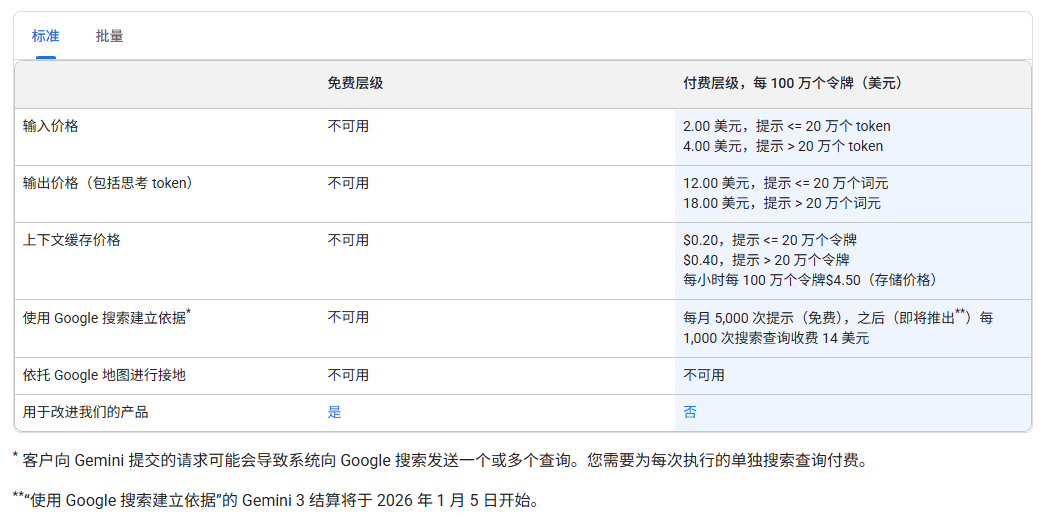
列出3.0的对话和画图的价格,其它模型以去官网文档查看:
下图中的:官网的谷歌翻译有问题,这里说明一下
token、词元、令牌 都代表:tokens- 提示:prompts,即你的输入(一段文字,一个pdf,一个代码等等)
🟢token与单词、汉字之间的数量关系:
| 语言/类型 | 换算关系 (预估) | 备注 |
|---|---|---|
| 英文 (English) | 100 Tokens ≈ 60 ~ 80 个单词 | 官方数据。通常按 1 Token ≈ 0.75 个单词 估算最准。 |
| 中文 (Chinese) | 100 Tokens ≈ 60 ~ 100 个汉字 | 中文比较复杂。现代模型(如 Gemini)通常 1 个汉字 ≈ 1 ~ 1.5 个 Token。 |
| 字符 (Characters) | 1 Token ≈ 4 个字符 | 这里的“字符”主要指英文字母。 |
20万个token相当于:
- 大约 150,000 个英文单词。
- 大约 130,000 ~ 200,000 个汉字。
🟢Gemini 3 Pro 预览版:
简要解释:这个是按照一次会话(可以有多轮,直到你发起新的对话)计算的,在这一次会话中,如果你的输入内容总长度不大于20万个tokens,那么:输入价格就是2美元/100万tokens,输出价格就是12美元/100万tokens。
场景:输入 100 tokens,输出 1000 tokens,没超过 20万档位。
-
输入费:
100 tokens × $ 2.00 1 , 000 , 000 = $ 0.0002 100 \text{ tokens} \times \frac{\$2.00}{1,000,000} = \$0.0002 100 tokens×1,000,000$2.00=$0.0002 -
输出费:
1000 tokens × $ 12.00 1 , 000 , 000 = $ 0.012 1000 \text{ tokens} \times \frac{\$12.00}{1,000,000} = \$0.012 1000 tokens×1,000,000$12.00=$0.012 -
总费用:
$ 0.0002 + $ 0.012 = $ 0.0122 \$0.0002 + \$0.012 = \mathbf{\$0.0122} $0.0002+$0.012=$0.0122
上下文缓存: AI模型是无状态的,它不会自动记住上次对话。每次请求都是一个独立事件,必须把需要它知道的“记忆”(即上下文,即前面所有输入输出)全部塞给它。因此,处理长文档的多轮对话会非常昂贵,因为每次都要为不断变长文档付费。
如果,我一开始就丢给他一本书的PDF,那我问了几个问题后,费用不是爆炸?💥
不会:模型有上下文缓存功能,2.5及以后的模型的隐式缓存默认处于启用状态,当上下文的tokens大于4096时即可开启,这会降低你的费用。(显式缓存开启时你自己使用Gemini的SDK、API写代码调用时的选项,网页版和Studio中没有相关选项)
所以:每次聊天的上下文不要太长了,一方面是价格问题,另一方面是上下文太长会降智,比如一直回复相同的内容。
🟢Gemini 3 Pro Image 预览版: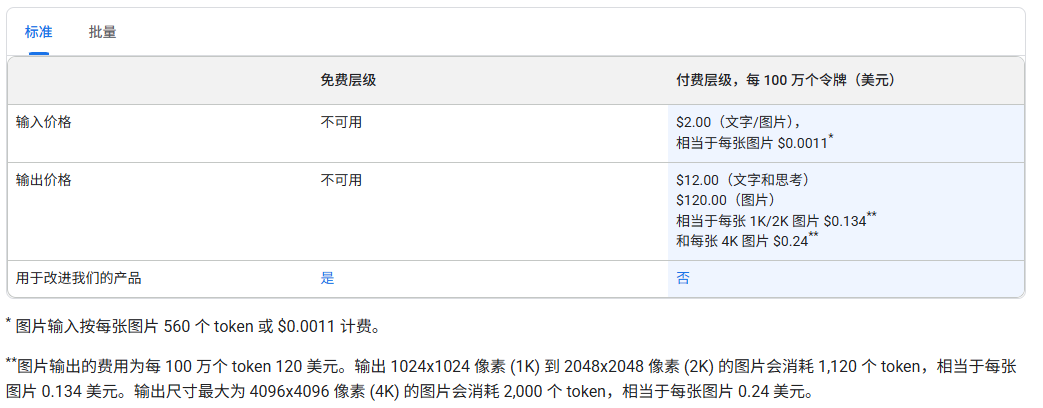
1.5 Google AI Studio 使用说明
目前页面不支持中文的(聊天支持),页面的英文选项你应该都认识。
先用图片标注说明这个页面的各部分是什么含义吧:
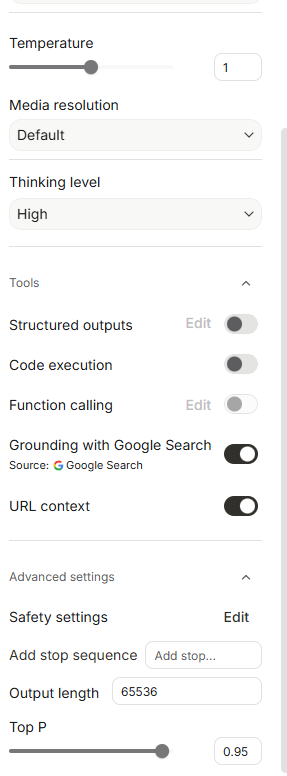
🟢模型参数解释:
💬(1)对话:功能是否开启,根据你的需求来,比如你发给它一个网址,让它读,就开启URL context
| 参数名称 (Parameter) | 中文名 | 功能详解 | 设置与建议 |
|---|---|---|---|
| Temperature | 温度 | 控制随机性。0最严谨(适合代码),2最奔放(适合创意)。1是平衡点。 | 1 (平衡,通用性好) |
| Media resolution | 媒体分辨率 | 识别图片/视频时的清晰度。Default是速度与细节的折中。 | Default (默认,够用) |
| Thinking level | 思考等级 | 推理模型专用。决定模型在回答复杂问题前“思考”的时间长度。 | High (深度思考,适合难任务) |
| Structured outputs | 结构化输出 | 强制模型只吐出标准 JSON 格式,开发程序接口时用。 | 关闭 (一般对话不用开) |
| Code execution | 代码执行 | 给模型一个Python环境,能写代码并真跑(算数、画图)。 | 关闭 (建议做数据分析时开启) |
| Function calling | 函数调用 | 让模型连接你的外部工具(API),是做智能体(Agent)用的。 | 关闭 |
| Grounding with Google Search | 谷歌搜索 | 联网能力。开启后可查实时信息(新闻、天气、股价)。 | 开启 (回答会带引用来源) |
| URL context | 网址上下文 | 允许直接读取提示词里贴的链接网页内容。 | 关闭 |
| Safety settings | 安全设置 | 敏感内容(如仇恨言论)的过滤阈值。 | 默认 |
| Add stop sequence | 停止序列 | 设定一个“暗号”,模型一旦说到这个词就立马闭嘴(停止生成)。 | 无 |
| Output length | 输出长度 | 单次回答的最大容量(Token数)。65k大约能写几万字。 | 65536 (拉满即可) |
| Top P | 核采样 | 辅助控制随机性,只选概率前95%的词,防止模型胡言乱语。 | 0.95 (标准值,不用动) |
🖼️(2)画图:
| 参数名称 | 中文含义 | 功能解释 | 推荐用法 |
|---|---|---|---|
| Aspect ratio | 宽高比 | 决定生成图片的形状比例。 | 根据你的需求选 |
| Resolution | 生成分辨率 | 决定生成图片的清晰度/像素大小。 | 根据需求选择 |
音视频的就不说了,选项很少。
不同模型的参数有差异,如Imagen 4 ,可以一次最多生成4张不同的图片。
画图最好的是
Nano Banna Pro,中文支持也好。
二、Cherry Studio
2.1 速通
Cherry Studio 是一款开源、跨平台的 AI 桌面客户端,专门为专业用户和开发者设计。
它就像一个 “万能聚合器” :你不需要去打开一个个独立的网页(比如 ChatGPT、Claude、DeepSeek 官网),而是把这些模型全部装进这一个软件里,通过你自己的 API Key 来使用,同时加上了极其强大的本地功能(如知识库、自动化助手)。
直接去github即可下载:https://github.com/CherryHQ/cherry-studio
或者去官网:https://www.cherry-ai.com/
如使用gemini-3-pro-preview和gemini-3-pro-image-preview(这两个叫做模型id):

画图示例:

各种功能自己探索即可,都是中文。
2.2 MCP
知识库什么的,就不展开说了,比如你有一项新技术,你可以把相关论文、教程创建一个知识库,让AI基于这个知识库回答。
AI的知识库是落后的,让它搜索也可能效果不好,较新、冷门的内容可以创建知识库。
这里说一下Cherry Studio的MCP功能。
MCP 全称是 Model Context Protocol(模型上下文协议):它的核心目的是:打破 AI 的孤岛状态,让 AI 能以一种标准化的方式,去读取你本地的数据、操作你的工具。
使用
VScode、Cursor、Google Antigravity的时候,AI可以读取你整个项目的内容,再使用Agent的话,还能完全操控你的文件(增加、删除、修改等),而Cherry Studio 默认没有这些功能。
先添加文件系统MCP:
填写配置:
示例:主要设置args那里的项目目录(可以填写多个目录,告诉AI你要操作哪个即可),以及isActive设置为true
{
"mcpServers": {
"U-B_DuXl3EbzIGGOMeFNF": {
"isActive": true,
"name": "@cherry/filesystem",
"type": "inMemory",
"args": [
"E:/AI/BrowserExtension"
],
"provider": "CherryAI",
"shouldConfig": true,
"installSource": "builtin",
"isTrusted": true
},
"wU439NroVcqpl5K26dpRQ": {
"isActive": false,
"name": "wU439NroVcqpl5K26dpRQ",
"type": "stdio",
"installSource": "unknown"
}
}
}
在对话里面选择这个MCP,AI就能读取电脑上的文件了: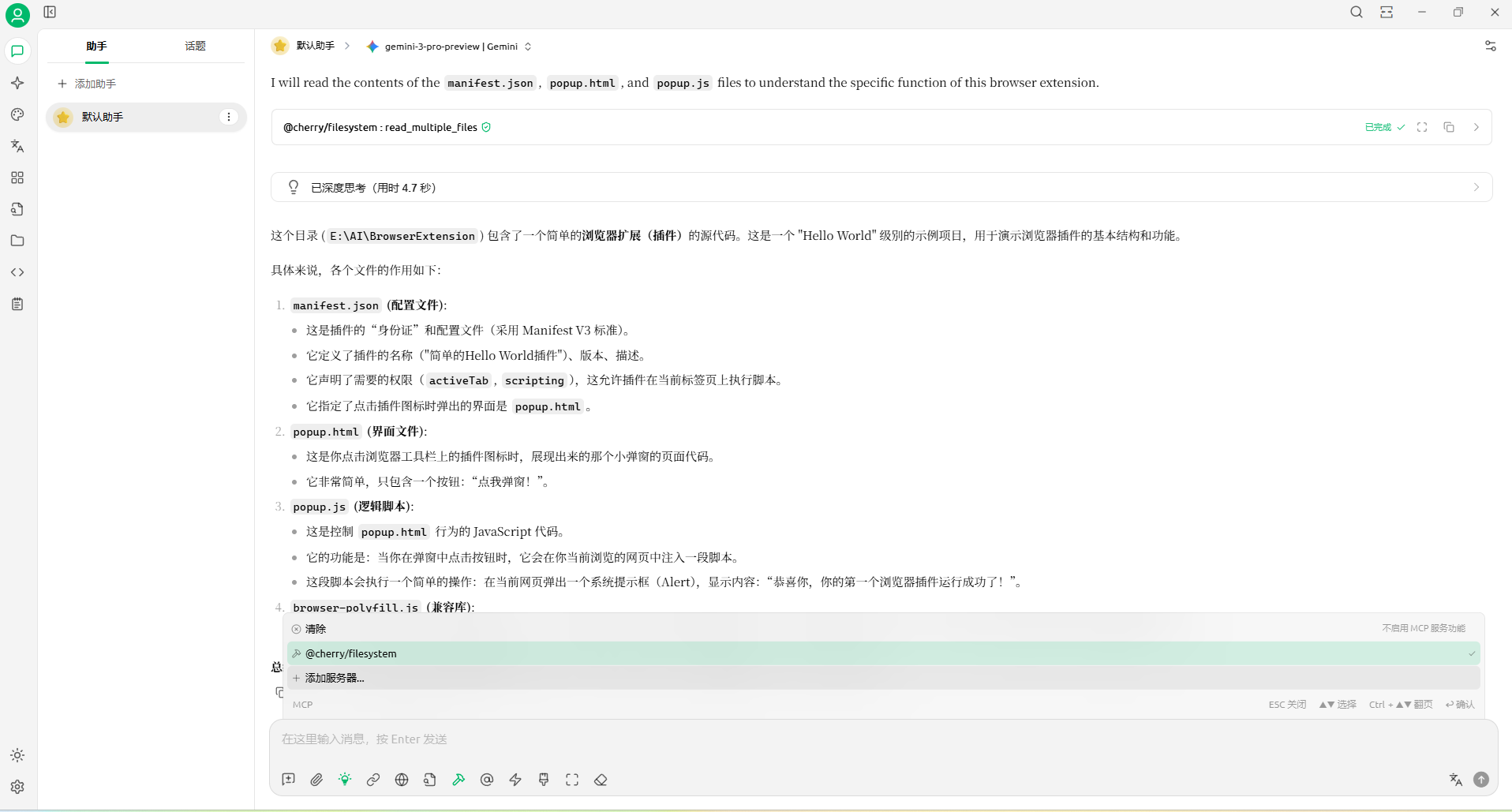
让它生成一个readme文件:
检查无误:
不过目前使用下来还是没有前面我提到的那3个编辑器舒服😆
你可以添加其它AI的key,如deepseek的,去deepseek开放平台弄就行了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)