【即插即用模块】AAAI2025 | 高频 + 空间感知!新 HS-FPN 让“极小目标”不再消失!SCI保二区争一区!彻底疯狂!!!
针对 FPN 在小目标检测中存在的 “特征有限、缺乏关注、空间感知不足” 三大问题,提出 HS-FPN 网络,通过高频感知模块(HFP)和空间依赖感知模块(SDP)增强小目标特征表达与空间关联性;在 AI-TOD、DOTA_minil0 等数据集上验证,相比基线模型 AP 提升 1.2-3.4 个百分点,且易嵌入现有检测框架。高频特征增强:HFP 模块(High Frequency Percept
0 论文信息
- 论文标题: HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection
- 中文标题:高频与空间感知特征金字塔网络(HS-FPN)用于小目标检测
- 论文链接
- 论文代码
- 论文出处:AAAI2025
1 论文概述
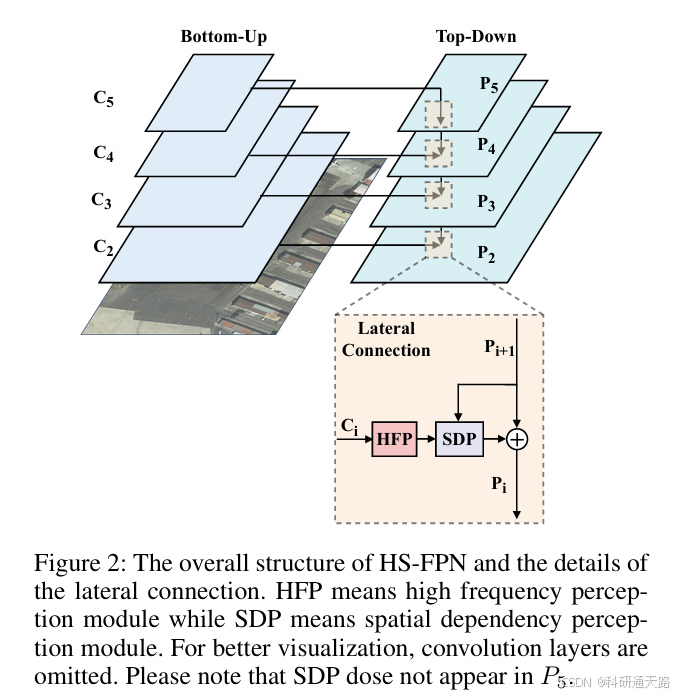
针对 FPN 在小目标检测中存在的 “特征有限、缺乏关注、空间感知不足” 三大问题,提出 HS-FPN 网络,通过高频感知模块(HFP)和空间依赖感知模块(SDP)增强小目标特征表达与空间关联性;在 AI-TOD、DOTA_minil0 等数据集上验证,相比基线模型 AP 提升 1.2-3.4 个百分点,且易嵌入现有检测框架。
2 实验动机
现有基于 FPN 的小目标检测模型存在三大核心痛点,且传统方法与前沿技术提供了优化启发,共同构成实验动机:
FPN 的固有缺陷:
- 小目标可用特征有限:骨干网络下采样压缩小目标特征,最终特征图中仅残留少量像素,难以支撑精准检测;
- 缺乏网络关注:FPN 对所有尺度特征采用统一处理流程(1×1 卷积降维、像素级相加融合),未针对小目标弱特征进行特殊增强;
- 空间感知不足:上下层特征通过像素级相加融合,上采样导致的像素偏移引发特征错位,无法捕捉小目标周围空间关联。
- 传统频域方法的启发:小目标在图像中表现为细节和边缘,对应频域中的高频成分,而低频成分主要是背景轮廓。传统方法(如小波变换、DCT)通过过滤低频可增强小目标显著性(用信号杂波比 SCR 量化),启发设计 HFP 模块。
- 注意力机制的借鉴:Vision Transformer(ViT)的注意力机制擅长捕捉长距离依赖,但直接应用于小目标检测易受噪声干扰;因此设计 SDP 模块,通过特征块划分与交叉注意力,精准捕捉上下层特征的像素级空间依赖。
3 创新之处
-
提出 HS-FPN 网络架构:首次将 “频域特征增强” 与 “空间依赖捕捉” 结合到 FPN 中,针对性解决小目标检测的三大痛点,结构简洁且兼容现有检测模型。
-
高频感知模块(HFP):
采用可调节参数 α 的高通滤波器,动态过滤低频背景成分,提取小目标高频响应;
双分支注意力机制:通道路径(CP)通过 GAP+GMP 聚合高频特征,为含小目标信息的通道分配高权重;空间路径(SP)生成空间掩码,聚焦小目标所在区域;
双分支特征融合后通过 3×3 卷积优化,增强特征表达的同时抑制噪声。 -
空间依赖感知模块(SDP):
不同于 FPN 的像素级相加,SDP 对上下层特征( C i C_i Ci与上采样后的 P i + 1 P_{i+1} Pi+1)构建 Query-Keys-Value 矩阵,通过特征块划分避免维度不匹配;
计算特征块内像素级交叉注意力,捕捉空间关联,解决上采样导致的特征错位;
与 ViT 的块间注意力不同,SDP 聚焦块内像素交互,更适配小目标的局部特征增强。 -
低侵入性与实用性:HS-FPN 与 FPN 结构高度相似,无需重构检测框架,可直接替换现有模型中的 FPN 模块,适配 ResNet、MobileNet 等多种骨干网络。
4 模块介绍
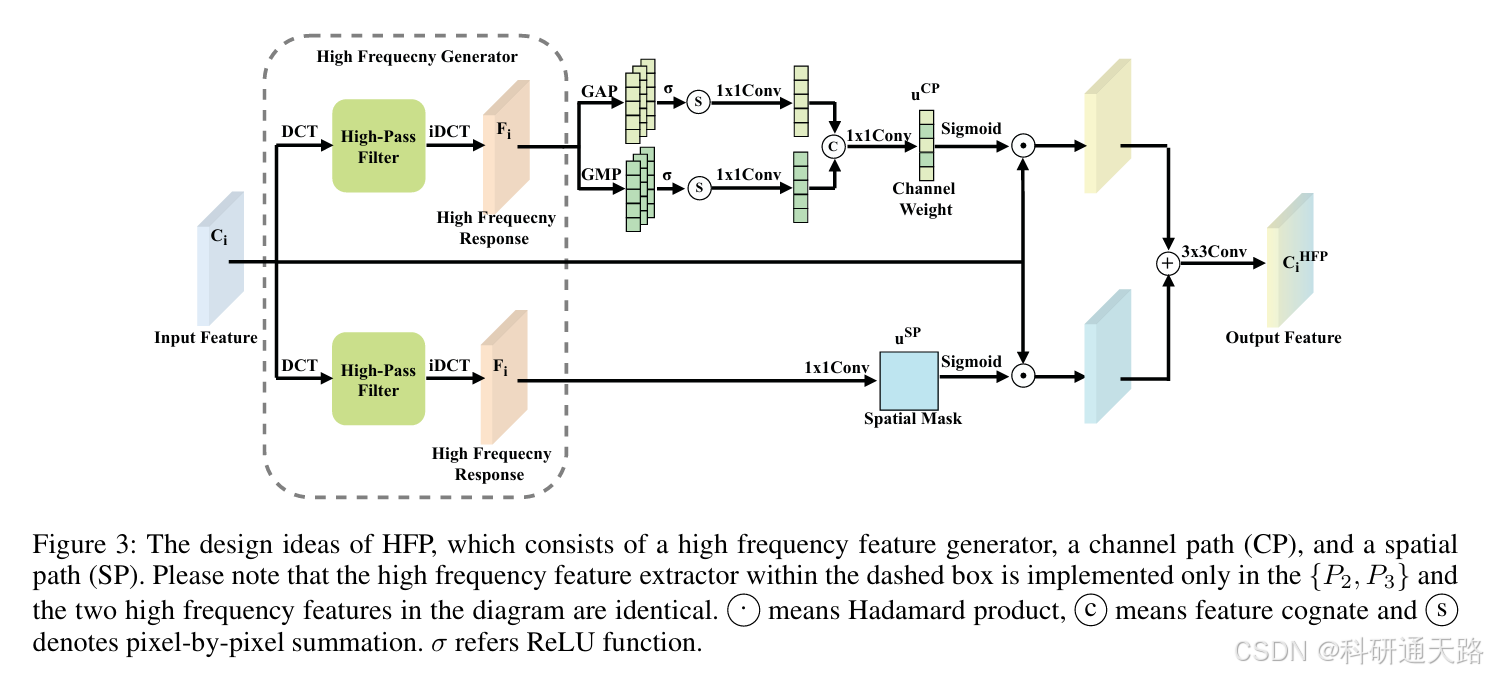
高频感知模块HFP(High Frequency Perception)
高频特征增强:HFP 模块(High Frequency Perception)通过 DCT + 高通滤波器 提取高频响应,专门增强微小目标的“边缘/细节”特征。高频响应分别作为 channel 权重(CP)+ spatial 权重(SP),突出包含 tiny objects 的通道与空间区域。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch_dct as DCT
# 定义DCT空间交互模块
class DctSpatialInteraction(nn.Module):
def __init__(self,
in_channels, # 输入特征图的通道数
ratio, # 用于计算高频保留比例的参数
isdct=True): # 标记是否使用DCT变换,True时在p1&p2中使用,False时在p3&p4中使用
# 调用父类nn.Module的初始化方法
super(DctSpatialInteraction, self).__init__()
self.ratio = ratio
self.isdct = isdct
# 如果不使用DCT,创建1x1卷积用于空间注意力
if not self.isdct:
self.spatial1x1 = nn.Sequential(
# 1x1卷积将输入通道数转为1,用于生成空间注意力图
*[nn.Conv2d(in_channels, 1, kernel_size=1, bias=False)]
)
# 计算权重矩阵的方法
def _compute_weight(self, h, w, ratio):
# 根据比例计算低频区域的高度和宽度
h0 = int(h * ratio[0]) # 高度方向的低频区域比例
w0 = int(w * ratio[1]) # 宽度方向的低频区域比例
# 创建全为1的权重矩阵,大小与输入特征图的空间维度相同
weight = torch.ones((h, w), requires_grad=False) # 不需要计算梯度
# 将低频区域(左上角)的权重设为0,实现过滤低频特征的效果
weight[:h0, :w0] = 0
return weight
def forward(self, x): # x是输入特征图
# 获取输入特征图的形状:batch_size, channels, height, width
_, _, h0, w0 = x.size()
# 如果不使用DCT,直接通过1x1卷积生成空间注意力并与输入相乘
if not self.isdct:
# 用sigmoid将卷积结果归一化到0-1,作为注意力权重
return x * torch.sigmoid(self.spatial1x1(x))
# 对输入特征图进行二维DCT变换
idct = DCT.dct_2d(x, norm='ortho') # 使用正交归一化 二维离散余弦变换
# 计算权重矩阵并移动到与输入相同的设备(CPU/GPU)
weight = self._compute_weight(h0, w0, self.ratio).to(x.device)
# 调整权重形状并扩展到与DCT结果相同的形状
weight = weight.view(1, h0, w0).expand_as(idct)
# 用权重过滤低频特征(保留高频特征)
dct = idct * weight # 过滤掉低频特征
# 对处理后的DCT结果进行逆DCT变换,生成空间掩码
dct_ = DCT.idct_2d(dct, norm='ortho')
# 将输入特征图与生成的空间掩码相乘
return x * dct_
# 定义DCT通道交互模块
class DctChannelInteraction(nn.Module):
def __init__(self,
in_channels, # 输入特征图的通道数
patch, # 用于池化的补丁大小
ratio, # 用于计算高频保留比例的参数
isdct=True # 标记是否使用DCT变换
):
super(DctChannelInteraction, self).__init__()
self.in_channels = in_channels
self.h = patch[0] # 补丁的高度
self.w = patch[1] # 补丁的宽度
self.ratio = ratio
self.isdct = isdct
# 1x1卷积,用于通道注意力计算,使用分组卷积(32组)
self.channel1x1 = nn.Sequential(
*[nn.Conv2d(in_channels, in_channels, 1, groups=32)],
)
self.channel2x1 = nn.Sequential(
*[nn.Conv2d(in_channels, in_channels, 1, groups=32)],
)
self.relu = nn.ReLU() # ReLU激活函数
# 计算权重矩阵的方法(与空间交互模块中的实现相同)
def _compute_weight(self, h, w, ratio):
h0 = int(h * ratio[0])
w0 = int(w * ratio[1])
weight = torch.ones((h, w), requires_grad=False)
weight[:h0, :w0] = 0# 将低频区域权重设为0
return weight
# 前向传播方法
def forward(self, x): # x是输入特征图
# 获取输入特征图的形状:batch_size, channels, height, width
n, c, h, w = x.size()
# 如果不使用DCT,使用普通的通道注意力机制
if not self.isdct:# true时在p1&p2中使用,false时在p3&p4中使用
# 对输入进行自适应最大池化,得到1x1的特征图
amaxp = F.adaptive_max_pool2d(x, output_size=(1, 1))
# 对输入进行自适应平均池化,得到1x1的特征图
aavgp = F.adaptive_avg_pool2d(x, output_size=(1, 1))
# 将最大池化和平均池化的结果通过ReLU激活后,再通过1x1卷积,最后相加
channel = self.channel1x1(self.relu(amaxp)) + self.channel1x1(self.relu(aavgp))
# 生成通道注意力权重并与输入相乘
return x * torch.sigmoid(self.channel2x1(channel))
# 如果使用DCT,先对输入进行二维DCT变换
idct = DCT.dct_2d(x, norm='ortho')
# 计算权重矩阵并移动到与输入相同的设备
weight = self._compute_weight(h, w, self.ratio).to(x.device)
# 调整权重形状并扩展到与DCT结果相同的形状
weight = weight.view(1, h, w).expand_as(idct)
# 过滤低频特征,保留高频特征
dct = idct * weight # 过滤掉低频特征
# 对处理后的DCT结果进行逆DCT变换
dct_ = DCT.idct_2d(dct, norm='ortho')
# 对逆DCT结果进行自适应最大池化和平均池化,输出大小为patch大小
amaxp = F.adaptive_max_pool2d(dct_, output_size=(self.h, self.w))
aavgp = F.adaptive_avg_pool2d(dct_, output_size=(self.h, self.w))
# 对池化结果应用ReLU激活,然后在空间维度上求和,调整形状为(batch_size, channels, 1, 1)
amaxp = torch.sum(self.relu(amaxp), dim=[2, 3]).view(n, c, 1, 1)
aavgp = torch.sum(self.relu(aavgp), dim=[2, 3]).view(n, c, 1, 1)
# 计算通道注意力
channel = self.channel1x1(amaxp) + self.channel1x1(aavgp)
# 生成通道注意力权重并与输入相乘
return x * torch.sigmoid(self.channel2x1(channel))
# 定义高频感知模块
class High_Frequency_Perception_Module(nn.Module):
def __init__(self,
in_channels, # 输入特征图的通道数
ratio=(0.25, 0.25), # 高频保留比例,默认保留75%的高频区域
patch=(8, 8), # 池化补丁大小
isdct=True): # 是否使用DCT变换
super(High_Frequency_Perception_Module, self).__init__()
# 创建空间交互子模块
self.spatial = DctSpatialInteraction(in_channels, ratio=ratio, isdct=isdct)
# 创建通道交互子模块
self.channel = DctChannelInteraction(in_channels, patch=patch, ratio=ratio, isdct=isdct)
# 输出处理模块:3x3卷积(保持空间大小)+ 分组归一化
self.out = nn.Sequential(
*[nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False),
nn.GroupNorm(32, in_channels)] # 使用32组的分组归一化
)
def forward(self, x): # x是输入特征图
# 通过空间交互模块得到空间注意力加权后的特征
spatial = self.spatial(x)
# 通过通道交互模块得到通道注意力加权后的特征
channel = self.channel(x)
# 将空间和通道注意力的结果相加,再通过输出处理模块
return self.out(spatial + channel)
if __name__ == '__main__':
input = torch.randn(1, 32, 50, 50)
# 实例化高频感知模块,输入通道数为32
model = High_Frequency_Perception_Module(in_channels=32)
output = model(input)
print(f"输入张量形状: {input.shape}")
print(f"输出张量形状: {output.shape}")

空间依赖感知模块(Spatial Dependency Perception Module SDFM)
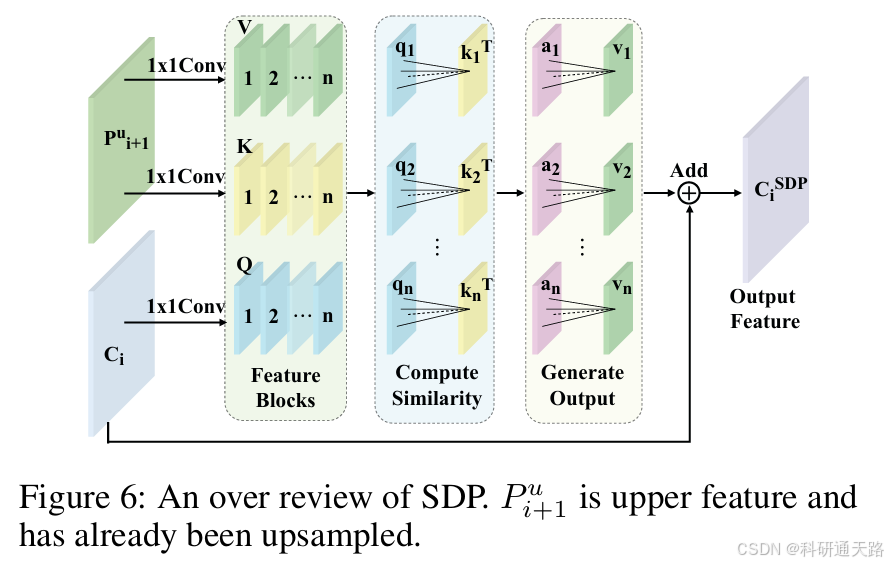
实际意义:①空间融合缺陷:FPN递归上采样导致上下层特征图中小目标位置错位,仅通过像素级加法融合特征,未建模像素间的空间依赖关系。②小目标空间信息缺失:小目标特征易被背景噪声掩盖,传统方法无法聚焦局部区域,上层高语义特征与下层细节特征缺乏有效关联,特征表达不完整。
实现方式:①输入上层特征图A与下层特征图B。②特征映射生成:通过1×1卷积分别从特征图A生成查询(Q),从特征图B生成键(K)和值(V)。③特征块划分:将 Q、K、V划分为多个特征块,对每个特征块计算Q与K的像素级相似度矩阵。④加权融合:用相似度矩阵对 V 进行加权聚合,生成空间依赖信息特征。⑥输出整合:将特征块按空间位置拼接,与原始输入相加,得到增强后的特征图。
待补充
5 写作思路
空间依赖感知模块(Spatial Dependency Perception Module,SDFM):
思想延伸(跨领域写作、包括不仅限于,请务必举一反三):
1、语义分割任务/小目标边界分割:①实际问题:传统分割网络(如U-Net)融合高低层特征时,小目标(如行人、交通标志)边界易因空间错位导致分割不连续。解决方案:①SDP迁移方案:在解码器与编码器之间插入SDFM,细节特征为Q,语义特征为K/V,通过像素级相似度建立边界与语义的空间关联。
思想延伸(跨领域写作、包括不仅限于,请务必举一反三):
2、图像超分辨率任务/纹理细节增强:①实际问题:在放大低分辨率图像时,高频纹理(如布料纹理、文字边缘)与低频语义(如物体形状)的空间对应关系丢失,导致“伪纹理”模糊出现。解决方案:①将低分辨率特征作为Q,高分辨率语义特征作为K/V,学习纹理细节在于语义空间分布规律。【研究对象可任意替换】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)