在 DataWorks 中一键部署大模型,即刻用于数据集成和数据开发
阿里云 DataWorks 发布大模型服务能力,基于 Serverless 资源组,支持用户 一键部署主流大模型,并可在 数据集成和数据开发任务中直接调用模型 API,实现“部署—集成—使用”全流程闭环,真正让数据工程师也能轻松玩转大模型!
在 AI 应用快速落地的今天,越来越多企业希望将大模型能力融入数据处理流程——无论是文本分析、智能摘要,还是 RAG 知识库构建。但传统模式下,模型部署依赖专业 MLOps 团队,需自行搭建推理环境、配置 GPU 资源、维护服务稳定性,门槛高、周期长、成本重。
现在,阿里云 DataWorks 发布大模型服务能力,基于 Serverless 资源组,支持用户 一键部署主流大模型,并可在 数据集成和数据开发任务中直接调用模型 API,实现“部署—集成—使用”全流程闭环,真正让数据工程师也能轻松玩转大模型!

三步完成模型部署,零代码上手
通过 DataWorks 大模型服务管理功能,您只需三个步骤即可完成模型上线:
-
选择模型 支持通义千问 Qwen3 系列、DeepSeek 系列等多种主流模型,涵盖生成、推理、向量化等场景。
-
一键部署 在控制台点击“部署”,选择目标 Serverless 资源组 和 GPU 规格(如 vGPU-1/4、vGPU-1),系统自动完成镜像拉取、服务启动与健康检查。
-
获取调用地址 部署成功后,自动生成标准 OpenAPI 接口地址和鉴权 Token,可用于后续任务调用。
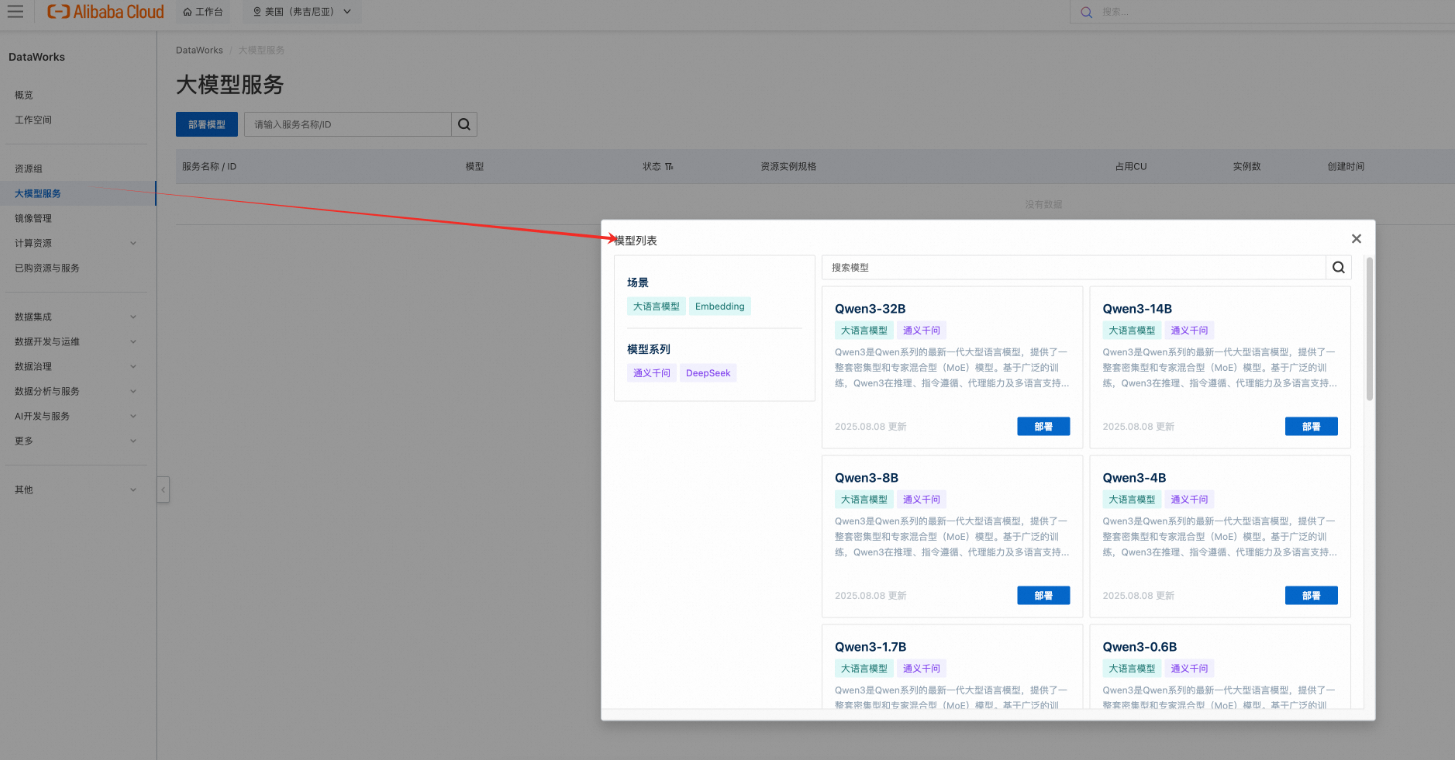
大模型部署页面
整个过程 无需关注底层资源调度、容器编排或网络配置,真正做到“点一下,就可用”,大幅降低大模型落地门槛。
核心优势

得益于底层资源优化与轻量化推理引擎,对于参数规模较小的模型(如 Qwen-Turbo、Embedding 模型),在 Serverless 资源组上的 平均推理延迟显著降低,性能提升近 10 倍,特别适合高频、低延迟的在线推理场景。
一键开启数据集成与开发的大模型应用
目前支持在数据集成、数据开发中调用大模型,实现对数据的智能处理。
数据集成中调用
在单表离线同步任务中,可使用大模型服务对同步中的数据进行AI辅助处理。
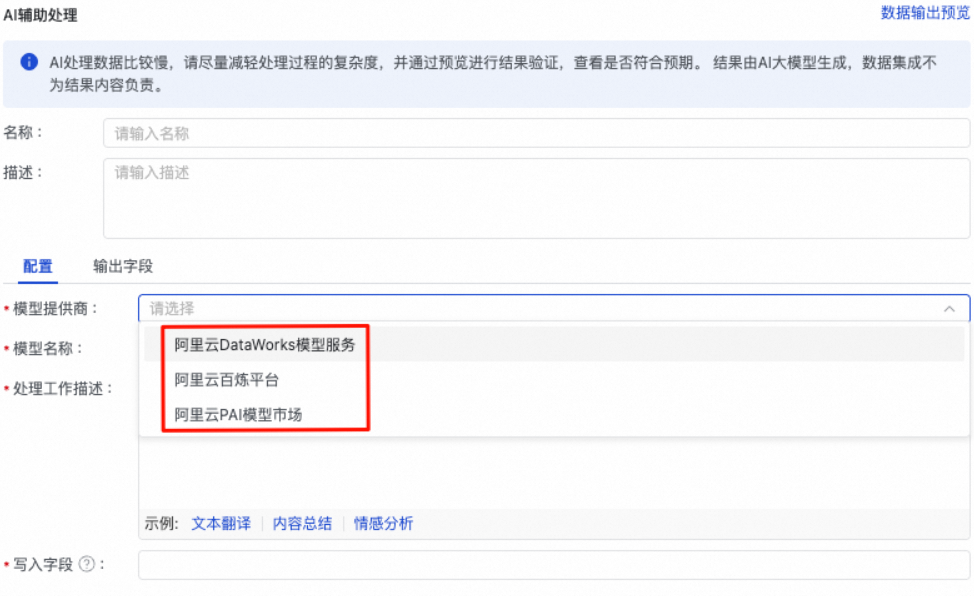
数据开发中调用
方式1、大模型节点调用大语言模型
DataWorks 新版数据开发 Data Studio 提供专属的大模型节点,支持通过可视化配置方式直接调用已部署的生成类或向量类大模型。用户无需编写代码,只需选择目标模型、输入提示词(Prompt)并设置参数,即可完成文本生成、摘要提取或文本向量化等任务,适用于快速验证模型效果和构建轻量级 AI 流程。
方式2、Shell 节点调用大语言模型
用户可在 Shell 节点中通过 curl 命令调用大模型服务 API,实现对生成模型或向量模型的灵活调用。例如,发送自然语言请求获取模型回复,或将文本传入 Embedding 模型生成向量。该方式适合熟悉命令行操作的开发者,结合调度配置可实现自动化任务执行。
方式3、Python节点调用大语言模型
通过 Python 节点,用户可使用 requests 等库编写脚本,以编程方式调用大模型服务。支持流式输出处理、自定义解析逻辑和复杂业务封装,适用于写诗、报告生成、结构化输出等需要精细控制的场景。需基于自定义镜像安装必要依赖后运行,并可集成至完整数据链路中。
接下来举个🌰展示如何在Python节点通过调用大语言模型完成写诗指令。
-
当前示例依赖Python的
requests库,请参考以下主要参数,基于DataWorks官方镜像创建自定义镜像安装该依赖环境。
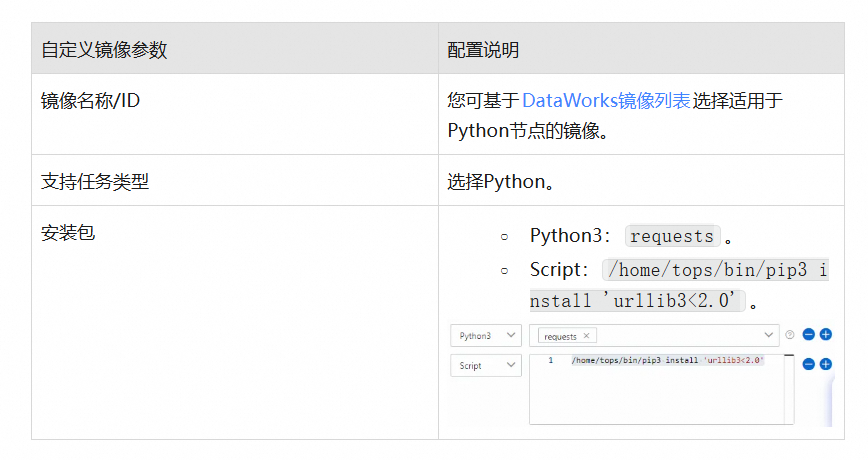
2. 创建Python节点,在Python节点添加如下示例代码:
import requests
import json
import time
import sys
def stream_print_response():
httpUrl = "http://ms-xxxx.cn-beijing.dataworks-model.aliyuncs.com"
apikey = "DW-ms-xxxx"
url = httpUrl + "/v1/completions"
headers = {
"Authorization": apikey,
"Content-Type": "application/json"
}
data = {
"prompt": "请写一篇关于春天的诗",
"stream": True,
"max_tokens": 512
}
try:
response = requests.post(url, headers=headers, json=data, stream=True)
response.raise_for_status()
full_text = "" # 累积完整回复,防止丢失
buffer = "" # 用于处理不完整的 JSON 行(可选)
for line in response.iter_lines():
if not line:
continue # 跳过空行
line_str = line.decode('utf-8').strip()
# print(f"[DEBUG] 收到行: {line_str}") # 调试用
if line_str.startswith("data:"):
data_str = line_str[5:].strip() # 去掉 "data: "
if data_str == "[DONE]":
print("\n[流式响应结束]")
break
# 尝试解析 JSON
try:
parsed = json.loads(data_str)
choices = parsed.get("choices", [])
if choices:
delta_text = choices[0].get("text", "")
if delta_text:
# 累积到完整文本
full_text += delta_text
# 逐字打印新增的字符
for char in delta_text:
print(char, end='', flush=True)
sys.stdout.flush()
time.sleep(0.03) # 打字机效果
except json.JSONDecodeError as e:
# print(f"[警告] JSON 解析失败: {e}, 原文: {data_str}")
continue
print(f"\n\n[完整回复长度: {len(full_text)} 字]")
print(f"[ 完整内容]:\n{full_text}")
except requests.exceptions.RequestException as e:
print(f" 请求失败: {e}")
except Exception as e:
print(f" 其他错误: {e}")
if __name__ == "__main__":
stream_print_response()
说明:请将代码中以http开头的大模型服务调用地址和以DW开头的Token信息替换为您的实际值。
3. 编辑节点内容后,在节点编辑页面右侧的调试配置中,选择已完成网络连通配置的资源组和步骤1中安装了requests库的自定义镜像。
4. 单击运行节点,即可调用已部署的服务模型执行相关命令。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)