基于视频理解的AI智能视频剪辑指南
摘要:随着视频成为核心传播载体,企业和创作者面临海量视频资源二次剪辑的挑战。传统人工剪辑效率低、成本高且标准化难,智能视频剪辑应运而生。该方案基于AWS云服务,通过"视频理解-内容抽取-重新组合"的自动化流程,实现80%以上的效率提升。核心技术包括分段理解、镜头/语音分割融合策略,以及向量化搜索与大模型推理双引擎架构。方案采用Serverless设计,支持多语言字幕、智能切片、
一、前言
在媒体娱乐、广告营销、零售电商等行业,视频已成为核心传播载体。企业和创作者往往手握海量视频资源 —— 从数小时的赛事录像、访谈节目,到碎片化的直播片段、创意素材,为了适配不同平台(如抖音、B 站、YouTube)和受众需求,需要进行二次剪辑、高光提取、多语言适配等大量工作。传统剪辑流程依赖专业人员逐帧观看、手动打点、反复调整,不仅人力成本高、周期长,还存在精度不足、标准化难等问题。
随着生成式 AI 多模态模型与云计算技术的深度融合,智能视频剪辑应运而生。本文基于 AWS 云服务的实践经验,详细拆解智能视频剪辑的技术架构、核心功能、应用场景及落地路径,为企业和创作者提供全面的智能化剪辑解决方案。
二、行业痛点与智能剪辑的核心价值
1. 传统视频剪辑的四大痛点
- 人力成本高:需专业剪辑师逐帧观看视频,手动标记精彩片段、添加字幕、调整转场,处理 1 小时视频往往需要数小时甚至数天;
- 效率低下:批量处理多视频时,重复劳动多,难以满足短视频平台 “日更”“小时级分发” 的运营节奏;
- 精度与标准化不足:人工判断存在主观性,关键信息易遗漏,不同剪辑师的作品风格不一致,难以形成统一品牌调性;
- 技术门槛高:多语言字幕翻译、超长视频分段、高光时刻精准提取等需求,需结合多种工具,协作流程繁琐。
2. 智能剪辑的核心价值
智能剪辑通过 “视频理解 - 内容抽取 - 重新组合” 的自动化流程,实现三大核心价值:
- 降本增效:将剪辑效率提升 80% 以上,批量处理时可实现 “上传即产出”,减少 90% 的重复劳动;
- 精准可控:基于 AI 模型的多维度解析,实现毫秒级时间精度,关键信息无遗漏,输出内容标准化;
- 灵活适配:支持自定义提示词、多模型切换、多格式输出,适配影视二创、体育赛事、电商直播等多场景需求;
- 安全可扩展:基于云原生 Serverless 架构,无需关注服务器部署与扩容,数据存储在客户私有账号,保障内容安全。
三、智能剪辑的核心场景与适用人群
1. 五大典型应用场景
|
业务场景 |
核心需求 |
适用客户 |
案例效果 |
|
影视 / 短剧二创 |
自动分段、高光提取、前情提要生成 |
流媒体公司、短剧运营企业 |
1 小时短剧→3 个 5 分钟高光片段,处理效率提升 10 倍 |
|
体育赛事传播 |
进球、逆转、绝杀等精彩瞬间提取 |
体育媒体、赛事运营方 |
90 分钟球赛→10 分钟精华集锦,无关键镜头遗漏 |
|
直播内容二次利用 |
电商直播卖点提取、娱乐直播名场面剪辑 |
电商商家、MCN 机构 |
6 小时直播→5 个 1 分钟产品卖点短视频 |
|
知识视频加工 |
纪录片分段、科教片总结、多语言翻译 |
传统媒体、教育机构 |
2 小时纪录片→8 个 15 分钟主题片段 + 3 种语言字幕 |
|
会议 / 发布会剪辑 |
核心观点提取、产品发布亮点集锦 |
企业市场部、科技公司 |
3 小时发布会→4 个 3 分钟核心内容视频,适配多平台分发 |
2. 适用人群
-
开发者:需要快速搭建视频剪辑工具、集成视频处理能力到现有系统;
-
内容运营者:批量处理视频、快速产出多平台适配内容;
-
企业 IT / 技术负责人:构建安全可控、可扩展的自动化视频处理工作流。
四、智能剪辑方案的设计原理与技术选型
1.核心工作流设计
智能剪辑方案的核心思路是模拟专业剪辑团队的工作流程,通过 AI 技术实现自动化处理,主要分为三大关键环节:

- 视频理解:从时间维度综合解析视频的画面、音频、字幕等多维度信息,构建对视频内容的全面认知;
- 视频内容抽取:基于理解结果,完成视频分段、高光时刻提取、特定场景 / 情节筛选等任务;
- 视频重新组合:利用专业媒体处理工具,对抽取的内容进行合成,并添加配音、字幕、转场特效等元素,生成最终视频。
2.关键技术选型
1.视频理解方式:分段理解优先
视频理解主要有两种方式,各有优劣,结合业务场景选型如下:
| 理解方式 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 整段理解 | 直接将完整视频输入多模态模型,获取时间维度理解结果 | 操作简单、适配性强,无需额外分段配置 | 视频长度增加后,时间准确度下降,存在信息遗漏风险,不支持超长视频(如超过 2 小时)输入 | 短视频、片段化素材的快速剪辑 |
| 分段理解 | 先按规则将视频分割为子单元(如镜头、段落),分别理解后整合全局认知 | 时间准确度高,分段越细致精度越高,可处理超长视频 | 需多模块协同,工程化复杂度较高 | 长视频(赛事、纪录片、发布会)、高精度剪辑需求场景 |
选型建议:优先采用分段理解方式,结合视频类型动态调整分段粒度,平衡精度与工程成本。
2.视频分段策略:镜头分割与语音分割结合
分段方式的合理性直接影响理解精度,三种主流分段方式对比如下:
| 分段方式 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 平均分割 | 按固定时长(如 5 分钟 / 段)拆分视频 | 操作简单、无技术门槛 | 易截断镜头和对话,破坏内容完整性,实用性差 | 无明确场景需求的临时拆分,不推荐核心业务使用 |
| 镜头分割 | 基于画面帧变化识别镜头切换,拆分视频 | 可完整覆盖视频视觉内容,不破坏画面逻辑 | 可能截断对话,影响语言类内容连贯性 | 体育比赛、纪录片、影视片段等以画面信息为主的视频 |
| 音频对话分割 | 基于语音识别、对话停顿拆分视频 | 不截断对话,保障语言类内容完整性 | 可能遗漏纯画面无语音的有价值片段 | 短剧、访谈、直播、会议等对话驱动型视频 |
选型建议:采用 “镜头分割 + 音频对话分割” 融合策略,通过 AI 识别视频类型(画面驱动 / 对话驱动),自动切换主导分段方式,兼顾内容完整性与逻辑连贯性。
3.视频内容抽取方式:大模型推理适配情节类剪辑
视频抽取的两种主流方式各有适用场景:
| 抽取方式 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 向量化搜索 | 将视频画面特征、转录文字向量化,通过搜索引擎匹配目标片段 | 检索速度快,在精确动作、关键词片段查找中表现稳定 | 对情节类、语义关联类片段识别能力弱 | 标签化媒体资源系统、精准动作片段提取(如体育赛事特定动作) |
| 大模型推理 | 通过多模态大模型全局理解剧情、语义关联,对结构化数据推理筛选 | 情节类、语义类片段识别准确率高,可理解复杂内容逻辑 | 检索速度略低于向量化搜索,对模型算力有一定要求 | 影视剧、短剧、知识视频等需按情节、语义筛选片段的场景 |
选型建议:构建 “向量化搜索 + 大模型推理” 双引擎抽取架构,用户可根据需求切换,兼顾精准检索与情节理解能力。
五、方案技术架构与核心功能
1.技术架构设计
方案基于 Amazon 平台构建,采用 Serverless 架构,无需关注系统并发和容量问题,核心架构分为四层:
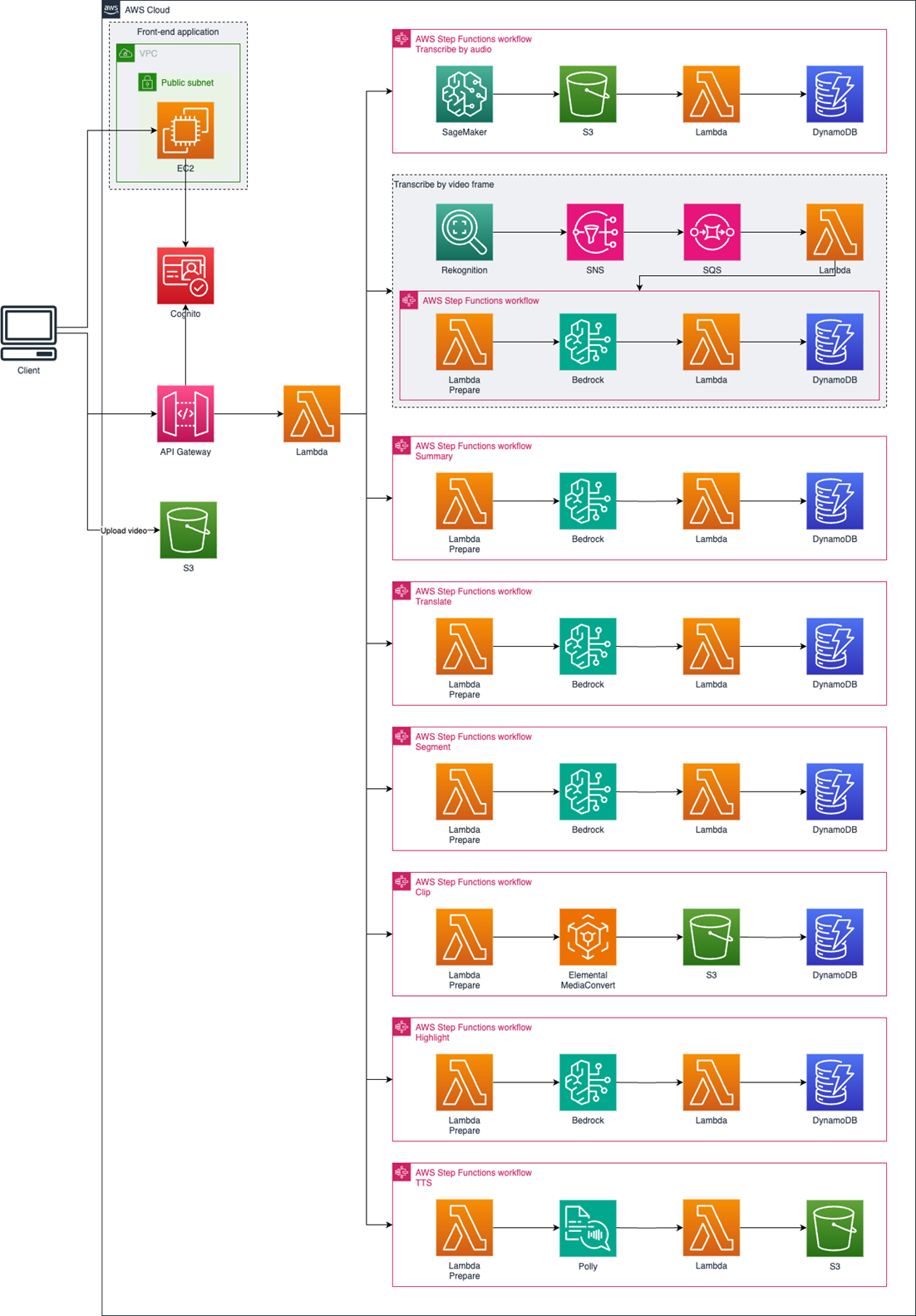
- 前端层:提供直观的操作界面,支持视频上传、参数配置(分段规则、提取关键词、字幕语言等)、实时预览、结果导出等功能,适配 PC 端、移动端操作;
- 存储层:通过 S3 存储原始视频、中间处理结果和最终产出视频,支持多格式兼容与海量数据存储;DynamoDB 存储结构化数据(如视频索引、剪辑参数、用户配置等),保障数据高效查询与管理;
- 计算与服务层:整合 AWS 核心服务,实现全流程能力支撑:
- 音频转录:通过 Transcribe 将视频音频转为文字,支持多语言识别与标点优化;
- 视频理解:依托 Rekognition 实现画面识别(镜头、物体、场景),结合 Bedrock 多模态大模型完成语义分析与情节理解;
- 摘要生成:通过 SageMaker 部署大语言模型,生成视频剧情梗概、核心观点摘要;
- 剪辑合成:利用 MediaConvert 实现视频拼接、转场特效添加,结合 Polly 生成多语言配音与字幕;
- workflow 协调层:通过 Step Functions 协调各模块工作流,实现 “上传 - 理解 - 抽取 - 合成 - 输出” 全流程自动化推进,支持异常重试、流程监控与日志追溯;
- 安全与接入层:通过 Cognito 实现用户身份认证与权限管理,API Gateway 提供标准化接口,支持与现有系统集成,三种鉴权模式(API 密钥、OAuth2.0、IAM)满足生产、测试、第三方集成等不同场景需求。
2.核心功能亮点
- 视频理解:支持音频转文字(ASR),基于视频抽帧或片段生成镜头描述,为后续剪辑提供数据基础;
- 视频摘要:通过大语言模型对音频转录文字或镜头描述进行总结,生成结构化剧情梗概;
- 字幕翻译:支持多语言字幕转换,适配全球分发需求;
- 智能切片:根据用户需求或大模型自动判断,将长视频精准切分为主题鲜明的短视频片段,用户可调整分段数量、起止时间;
- 高光时刻提取:智能识别视频中最具价值的片段,支持自定义旁白配音和字幕烧录,可通过多次迭代优化片段时长;
- 灵活配置:不绑定特定模型,用户可根据需求选择适配模型;支持自定义提示词和调用顺序,实现多样化产出效果。
3.方案核心优势
- 高效自动化:大幅减少人工操作,将原本需要数小时的剪辑工作缩短至分钟级;
- 安全可控:所有操作在客户账号下完成,视频数据不会用于公共基础模型训练,保障媒体资源安全;
- 灵活适配:支持多种视频格式(MP4、MOV、AVI 等)和分辨率(480P-4K),适配长视频、无声视频等多样化素材;
- 易集成扩展:提供完整的 API 和工具链对接方式,支持与现有工作流融合,三种鉴权模式满足生产、测试、第三方集成等不同场景需求。
六、总结与展望
基于视频理解的智能视频剪辑方案,通过多模态 AI 模型与专业媒体服务的深度融合,彻底革新了传统视频剪辑的工作模式。其核心价值在于将 AI 的高效性与专业剪辑的逻辑性相结合,既解决了传统流程中人力成本高、效率低、标准化难等痛点,又通过灵活的配置和扩展能力,适配不同行业、不同场景的多样化需求。
随着生成式 AI 技术的持续演进,未来智能剪辑将在更复杂的情节理解、更精准的风格适配、更个性化的创作支持等方面实现突破。对于企业而言,引入智能视频剪辑方案不仅是提升创作效率的选择,更是在内容爆炸时代抢占分发先机、提升用户体验的核心竞争力。无论是影视二创、体育赛事传播,还是电商直播剪辑、知识视频分发,智能视频剪辑都将成为驱动内容产业创新发展的重要引擎。
参考文章:https://aws.amazon.com/cn/blogs/china/intelligent-video-editing-guide-based-on-video-understanding/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)