【AI落地应用实战】基于 Amazon Redshift + dbt + MWAA 搭建现代数据栈
本文介绍了基于Amazon Redshift、dbt和MWAA的现代数据栈解决方案。通过ELT模式实现高效数据处理,先加载原始数据至Redshift,再利用dbt进行数据转换和建模。方案采用MWAA托管Airflow实现工作流自动化,结合Cosmos简化dbt任务编排。文章详细阐述了环境搭建步骤,包括Redshift Serverless配置、dbt项目初始化、MWAA环境创建及CI/CD管道构建
一、引言
在当今瞬息万变的商业环境中,数据已成为企业不可或缺的核心资产。面对海量数据,如何高效提取有价值的信息、支撑敏捷决策,成为企业必须应对的关键课题。
传统数据处理方式,如ETL(提取、转换、加载),在数据量激增和业务需求快速迭代的双重压力下,逐渐显露出响应迟缓、灵活性不足等局限。在这样的背景下,“现代数据栈”(Modern Data Stack)理念逐渐兴起。它倡导采用ELT(提取、加载、转换)模式,先将原始数据完整加载至数据仓库或数据湖,再根据具体需求在目标环境中进行转换。这种方式不仅有效控制了数据处理成本,还能灵活应对大规模数据的即时分析需求,特别适合为数据湖仓构建高效、可扩展的数据管道。
本文将聚焦结合Amazon Redshift、Amazon MWAA(Managed Workflows for Apache Airflow),以及当前备受青睐的开源工具dbt(data build tool)与Cosmos,从核心概念入手,解析各组件的协同工作机制,并通过一个完整实践案例,逐步演示如何从零搭建并部署这套现代数据栈解决方案。
二、核心技术概览与环境准备
构建现代数据栈离不开强大且灵活的技术组件支持。本方案选择了亚马逊云科技生态系统中一系列领先的数据服务,它们各自承担着关键角色,共同构成了方案的技术基石。
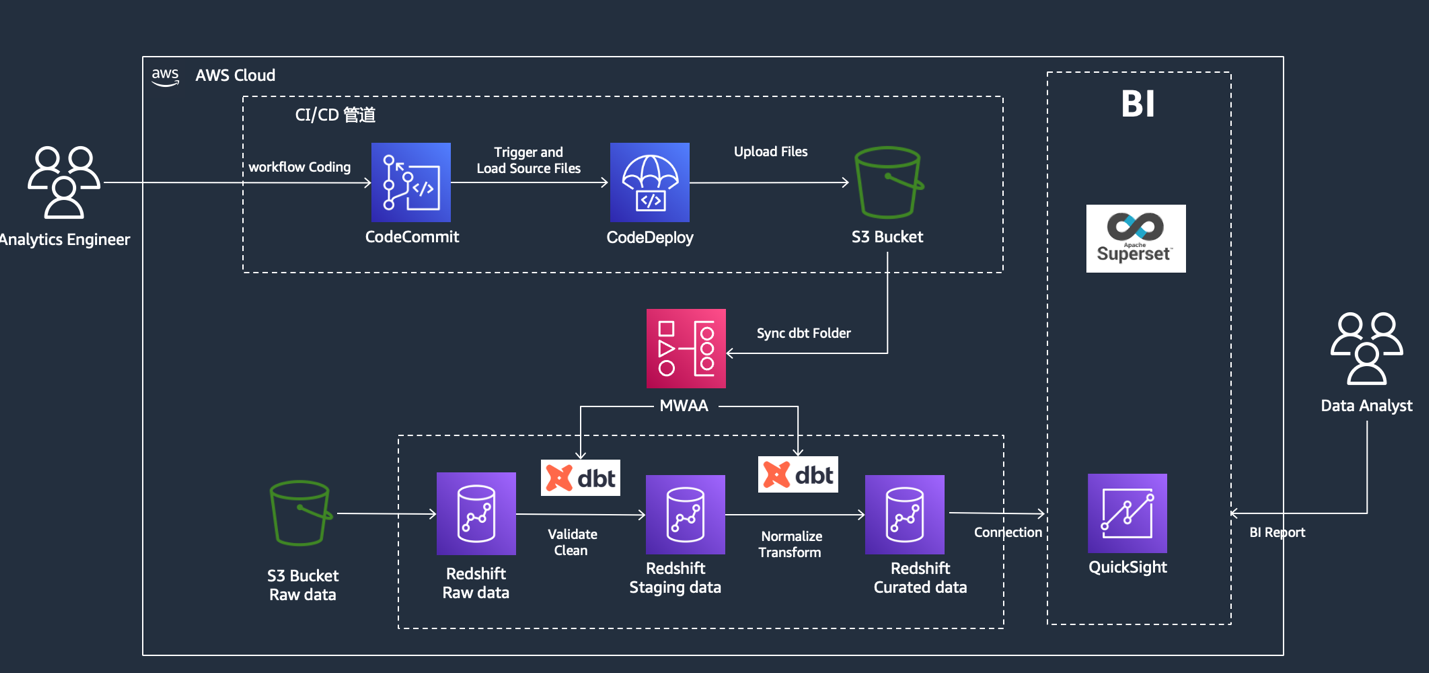
2.1 Amazon Redshift
Amazon Redshift是亚马逊云科技(https://aws.amazon.com/cn/free?trk=03ab2aa5-6002-4cf4-b49a-9310fb164960&sc_channel=sm)提供的完全托管的云数据仓库服务,专为处理大规模数据而设计。凭借其卓越的性能、灵活的可扩展性以及卓越的成本效益,Amazon Redshift已成为现代数据栈中数据存储和分析的核心组件。Redshift 采用列式存储架构和大规模并行处理(MPP)技术,能够大幅提升分析查询的效率。此外,其存算分离的特性使得存储和计算资源可以各自独立扩展,进一步优化了资源利用率。

2.2 dbt
dbt(data build tool)是一个开源工具,它将软件工程的最佳实践引入到数据转换和建模领域。dbt允许数据分析师和工程师使用纯SQL专注于数据转换和建模,而无需编写复杂的ETL代码。它通过引入版本控制、测试、文档生成和模块化等概念,解决了数据模型维护、版本管理和团队协作的痛点。dbt的核心在于使用SQL SELECT语句来构建数据模型,并将其**物化(Materialize)**为视图、表或增量表,从而简化了数据团队的协作,并提升了数据资产的质量和可维护性。

2.3 Amazon MWAA
Amazon MWAA是亚马逊云科技推出的完全托管服务,专为简化 Apache Airflow 的部署及运维而设计。Apache Airflow 是一款经典的开源工具,凭借其强大的数据管道编排和调度能力,已经成为数据工程领域的得力助手。在 MWAA 的助力下,用户可以轻松定义、调度和监控复杂的处理工作流,还能利用 DAG(有向无环图)编程范式,让数据流水线的逻辑结构更加直观清晰,便于理解和维护。
得益于 MWAA 的托管模式,用户无需操心底层基础设施的维护,大幅削减了运行 Airflow 的运维成本。这使得工程师们可以将宝贵的时间和精力从繁琐的基础设施管理中解放出来,专注于数据管道本身的开发与优化工作。同时,MWAA 提供了出色的可视化与监控功能,让整个数据工作流的运行状态一目了然,进一步提升了数据工作的透明度和可控性。

2.4 Cosmos
Cosmos是一个用于Airflow和dbt集成的框架,它极大地简化了在Airflow中编排dbt任务的复杂性。通过Cosmos,Airflow能够自动识别dbt模型的血缘信息,无需数据工程师再手工配置Airflow调度任务的依赖关系。这提高了数据工程师的工作效率,降低了管理复杂性,使得在Airflow中使用dbt变得更加简单和标准化。在本方案中,MWAA和dbt通过Cosmos协同工作,实现了数据处理流程的自动化编排和高效执行。

2.5 环境准备
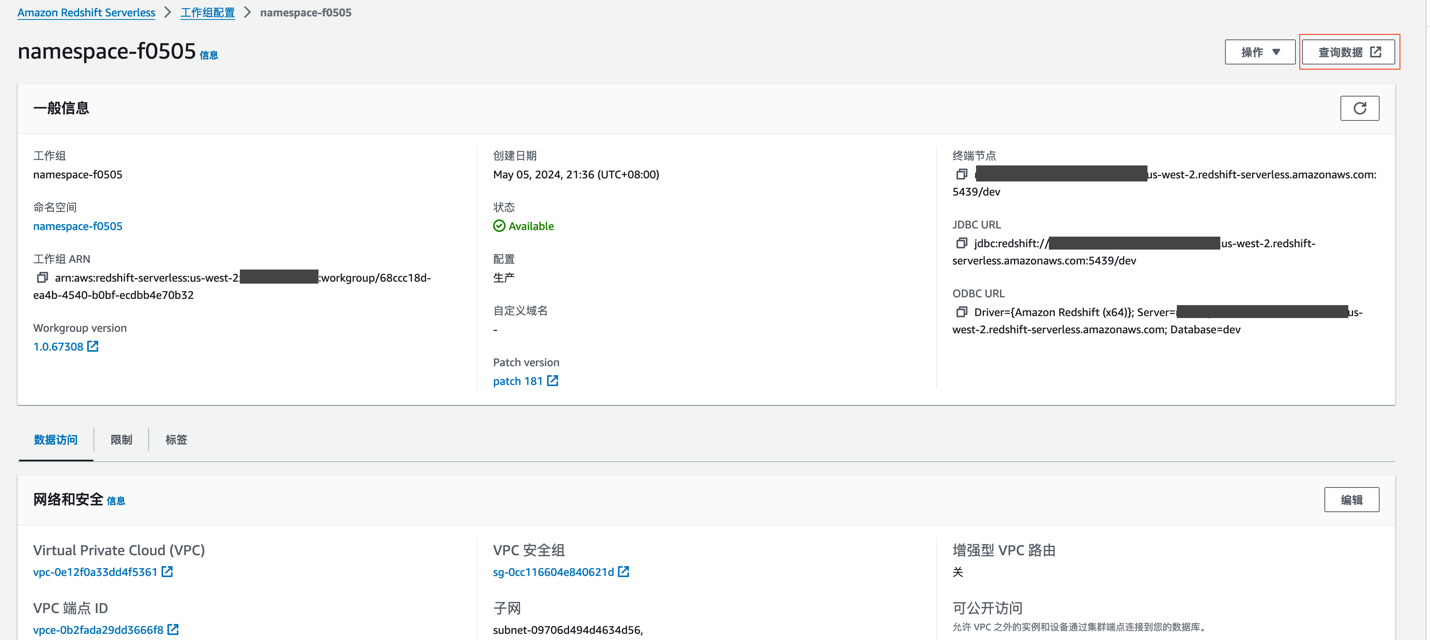
在搭建现代数据栈的基础环境过程中,我们首先需要创建Amazon Redshift Serverless,这是数据存储和分析的核心。您需要配置工作组和命名空间,以高效组织计算资源,同时设置数据库凭证和网络,确保安全连接。
接下来,我们需要安装 dbt(Data Build Tool),在 Cloud9 环境中,运行以下命令来安装 dbt Core 和 dbt Redshift 适配器:
暂时无法在飞书文档外展示此内容
安装完成后,您可以通过以下命令检查 dbt 的安装状态:
暂时无法在飞书文档外展示此内容

此命令会显示 dbt 的版本、安装路径等信息,确认安装无误后,即可开始下一步配置。
在安装 dbt 后,我们需要创建一个 dbt 项目来定义数据模型和相关的配置代码。dbt 项目是数据建模的起点,它允许您将数据转换逻辑组织为易于维护的模型。
运行以下命令初始化一个 dbt 项目:
暂时无法在飞书文档外展示此内容
完成 dbt 项目初始化后,我们需要确保 dbt 能够与 Redshift Serverless 建立连接,以便执行数据转换任务。<font style="background-color:rgb(187,191,196);">profiles.yml</font> 文件中存储了连接 Redshift 的参数,文件路径为 <font style="background-color:rgb(187,191,196);">~/.dbt/profiles.yml</font>。
您可以使用以下命令编辑 <font style="background-color:rgb(187,191,196);">profiles.yml</font> 文件:
暂时无法在飞书文档外展示此内容
编辑完成后,运行以下命令测试 dbt 是否能够成功连接到 Redshift:
暂时无法在飞书文档外展示此内容
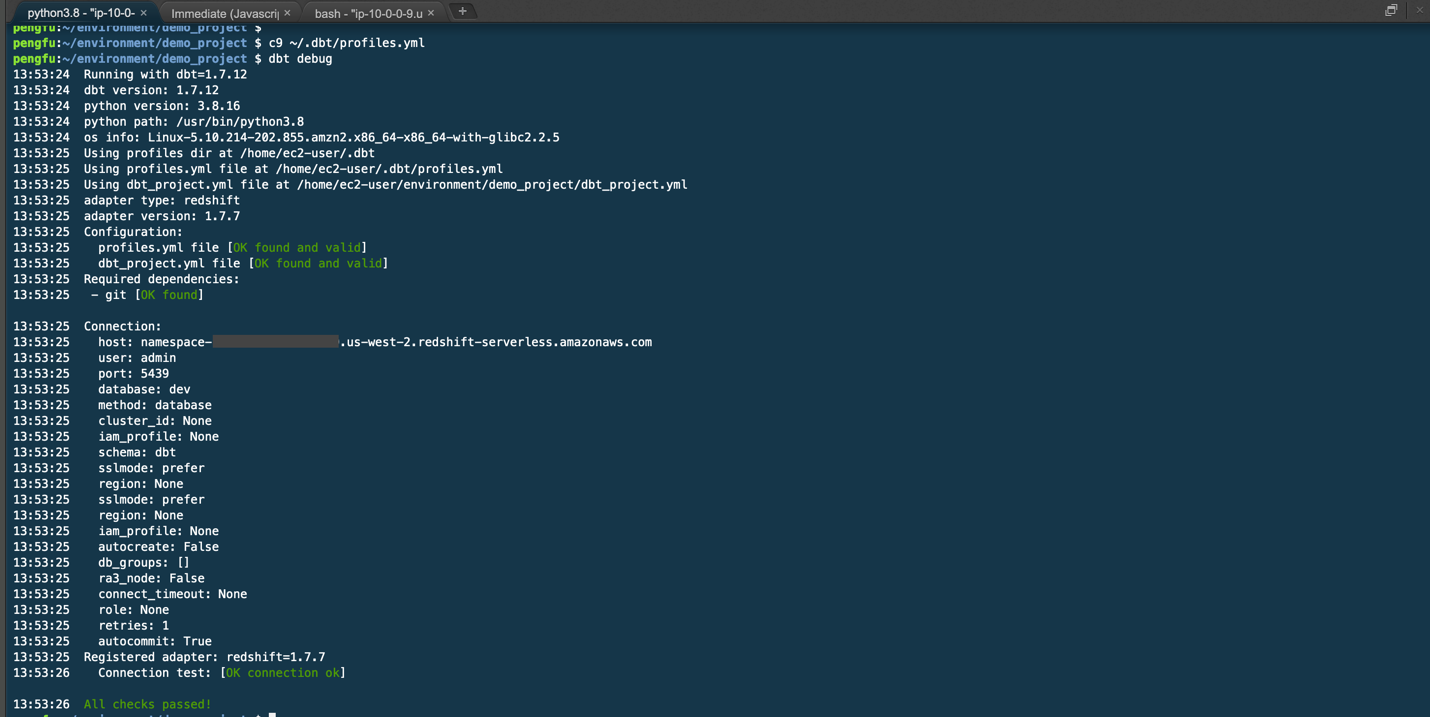
<font style="background-color:rgb(187,191,196);">dbt debug</font> 命令会检查您的配置是否正确,并尝试连接到 Redshift Serverless 端点。如果连接失败,请检查 <font style="background-color:rgb(187,191,196);">profiles.yml</font> 文件的内容是否完整,并确保网络设置(如安全组)允许访问 Redshift。
接下来,我们需要搭建 MWAA(Managed Workflows for Apache Airflow)环境,用于管理和调度数据处理任务。在开始之前,需要先创建 S3 桶和 dags 文件夹,并填入到 MWAA 环境信息中。
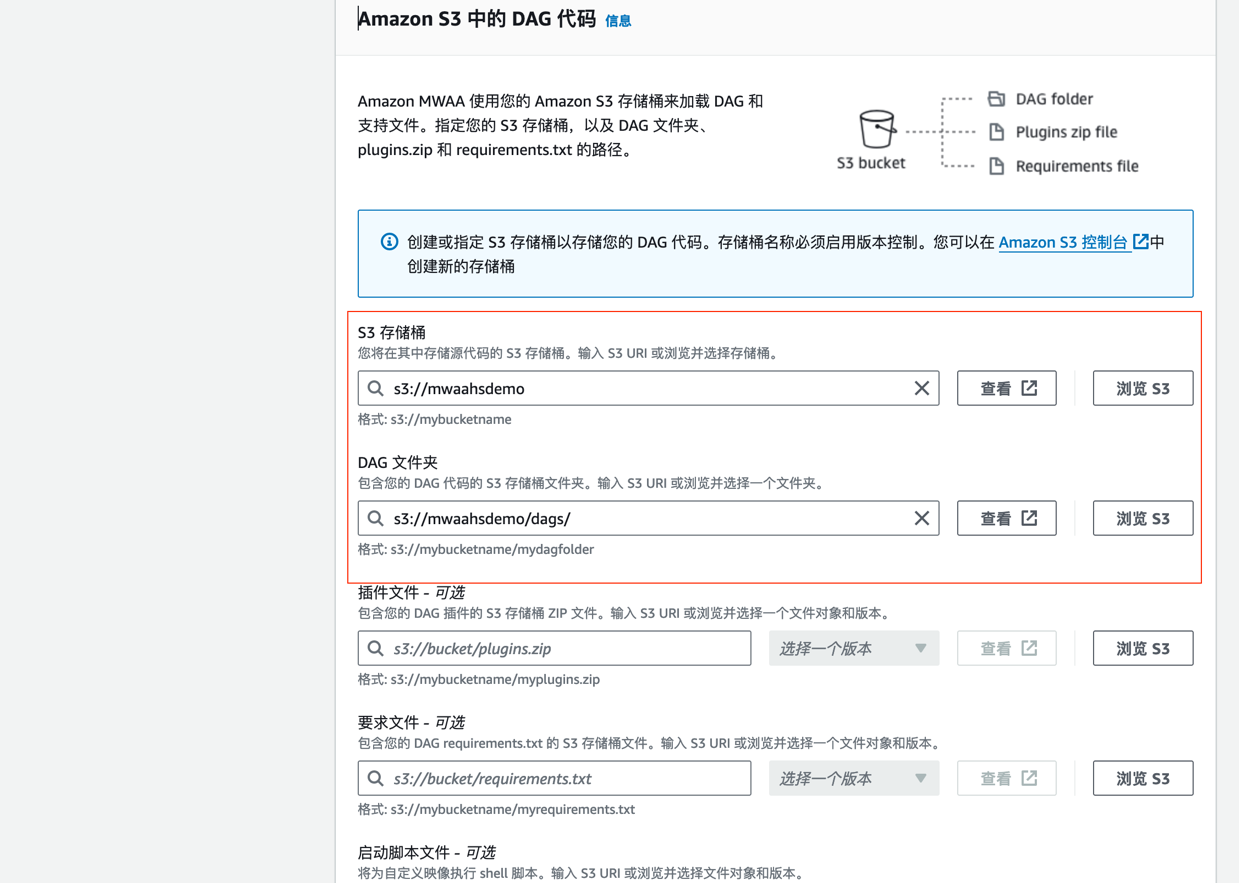
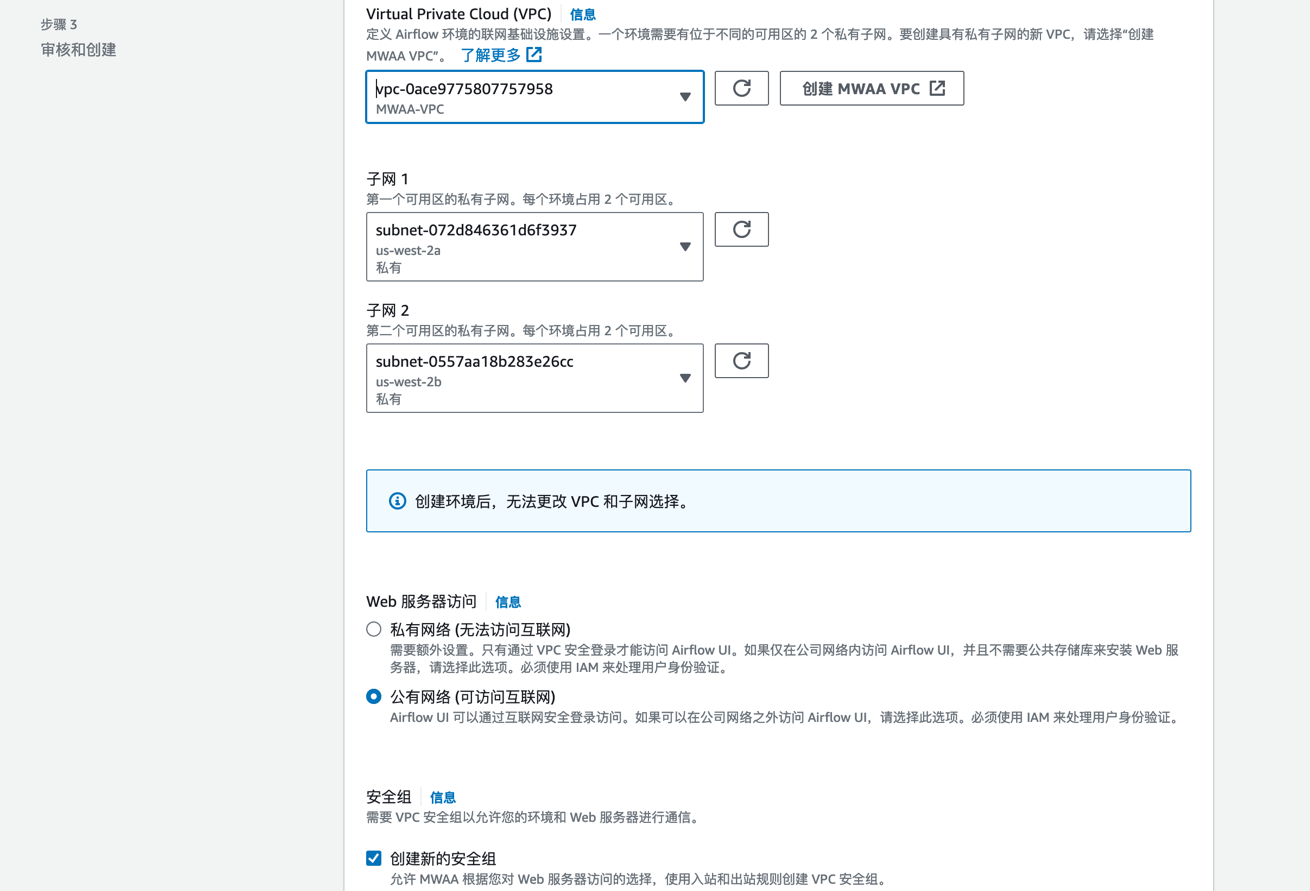
此过程需要 20-30 分钟,待创建完毕后,进入 airflow UI。此时因为 S3 桶中 dags 目录下为空,所以没有任何 DAG。

为了实现代码的自动化部署,我们需要构建一个 CI/CD 管道。创建 codecommit 存储仓库,以 mwaa-repo 为例。创建 codepipeline,构建管道,首先添加源。以 codecommit 为源,选择存储库与分支。
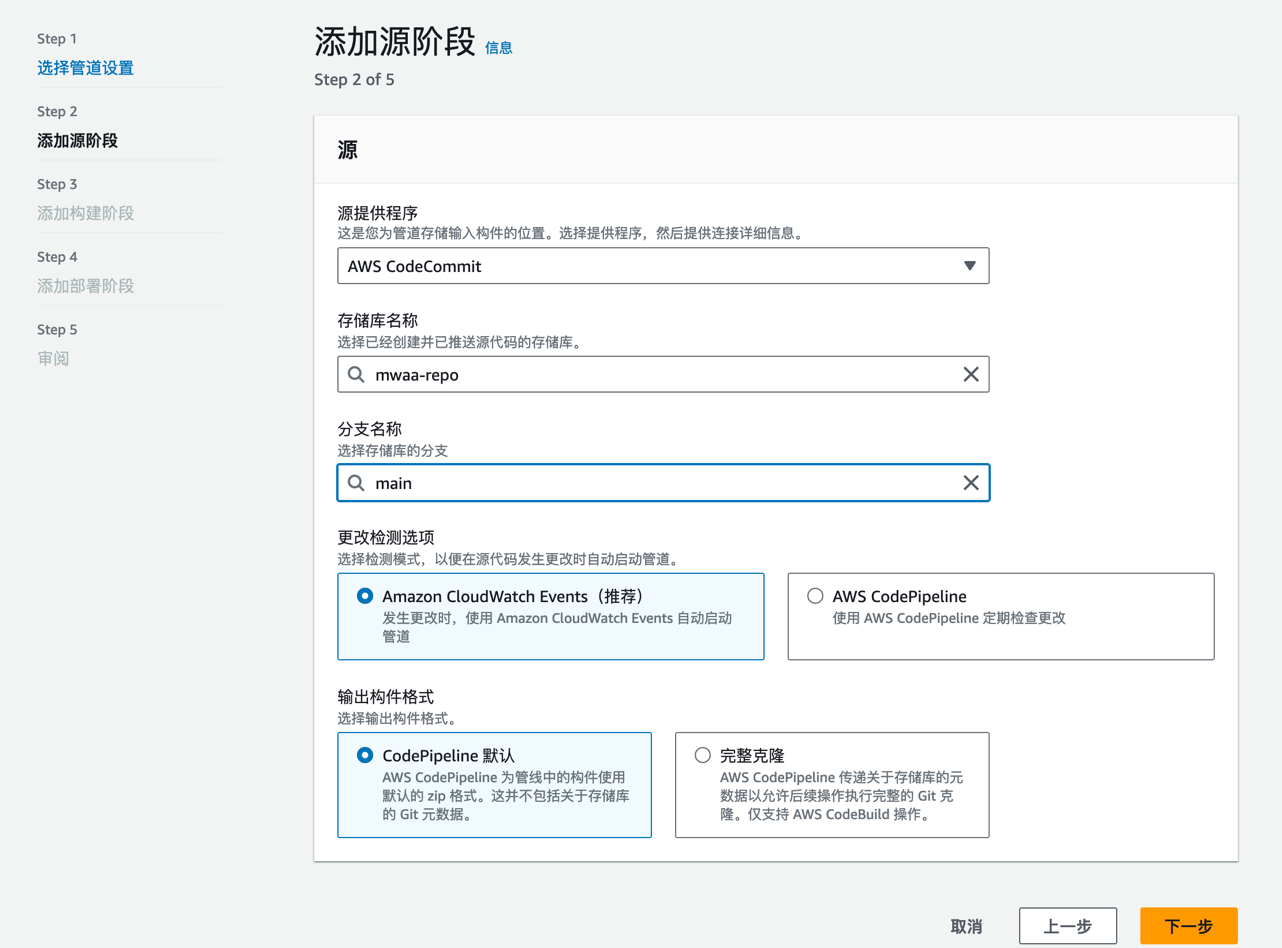
通过以上步骤,已完成现代数据栈的基础环境搭建,为后续的数据处理和自动化调度奠定了基础。
三、数据处理与工作流自动化
在完成了现代数据栈的环境准备之后,本章将探讨如何利用dbt在Amazon Redshift中进行数据处理和建模,并最终通过MWAA实现整个数据处理工作流的自动化运行。
3.1 数据处理
在ELT模式中,原始数据通常首先从各种源(如业务系统、日志文件等)抽取(Extract)并加载(Load)到数据湖或数据仓库中。在本方案中,Amazon S3作为数据湖,承载了原始数据。然后,数据在数据仓库(Amazon Redshift)中进行转换(Transform)。
为了演示数据处理过程,我们将使用示例数据。这些数据首先存储在Amazon S3中,然后通过Redshift的COPY命令高效地加载到Redshift数据仓库中。例如,通过执行COPY public.users FROM 's3://your-s3-bucket/path/to/users.csv' IAM_ROLE 'arn:aws:iam::your-account-id:role/your-redshift-iam-role' CSV;命令,即可将S3中的数据导入Redshift。数据加载完成后,可以通过简单的SQL查询验证数据是否已成功导入。
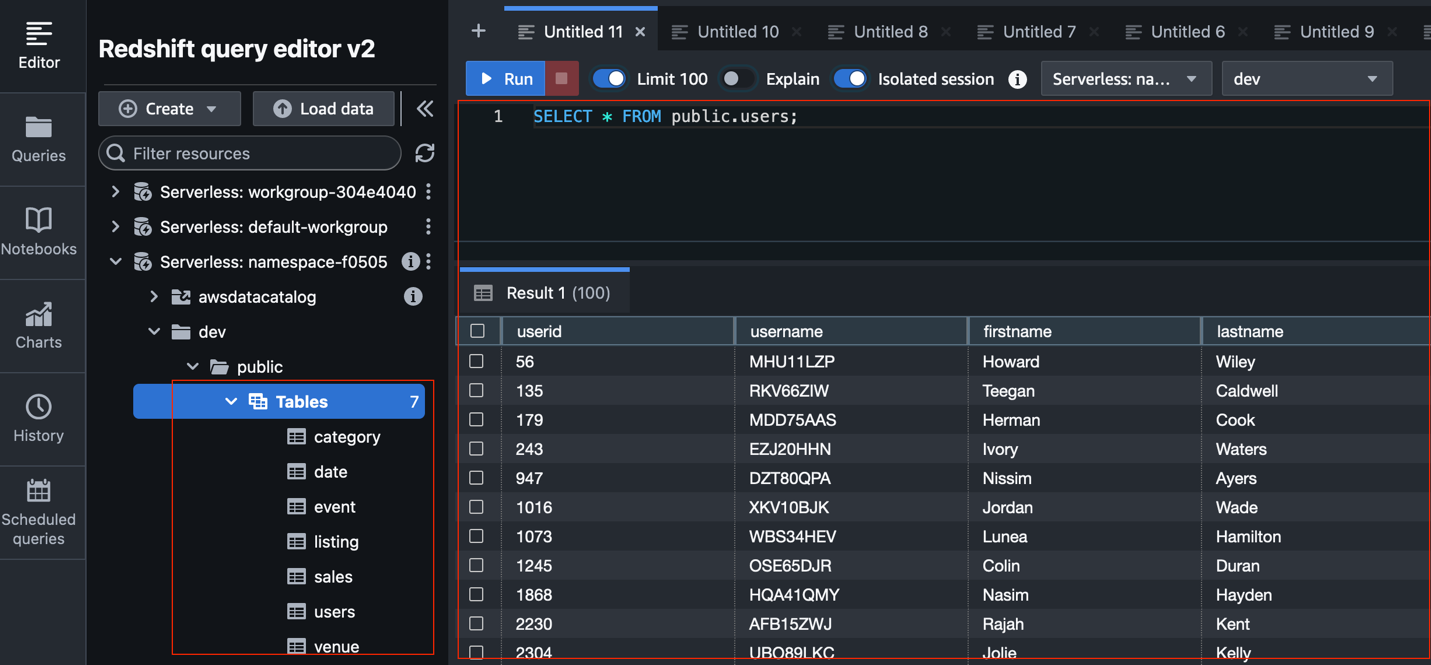
3.2 dbt数据建模
数据加载到Redshift后,dbt将发挥其核心作用,进行数据转换和建模。以下是dbt在数据建模中的关键步骤:
- 加载数据:数据从源头加载到Redshift后,dbt开始发挥作用。
- 初步处理(Staging层):首先对原始数据进行清理、去重和初步加工,为后续复杂业务逻辑的转换提供干净的数据基础。Staging层的模型通常是SQL的
<font style="background-color:rgb(187,191,196);">SELECT</font>语句,直接引用原始表并进行简单处理。 - 物化策略:dbt提供了多种物化选项(如
<font style="background-color:rgb(187,191,196);">view</font>、<font style="background-color:rgb(187,191,196);">table</font>、<font style="background-color:rgb(187,191,196);">incremental</font>、<font style="background-color:rgb(187,191,196);">ephemeral</font>等),可以选择适合的策略来决定数据如何存储和更新。在Staging层,通常将物化配置为<font style="background-color:rgb(187,191,196);">table</font>,以确保处理后的数据以物理表形式存在。 - 文件组织:通过创建staging模型文件夹,并在其中编写SQL文件(如
<font style="background-color:rgb(187,191,196);">staging_category.sql</font>)来实现数据转换。同时需要定义一个<font style="background-color:rgb(187,191,196);">schema.yml</font>文件来描述数据源。运行<font style="background-color:rgb(187,191,196);">dbt run --models staging</font>命令后,Redshift中会新增一个<font style="background-color:rgb(187,191,196);">dbt_staging</font>模式,包含物化后的表。 - 构建复杂模型:在Staging层的基础上,可以构建更复杂的业务模型,如计算季度财务数据等。使用
<font style="background-color:rgb(187,191,196);">ref</font>机制引用Staging层的表,避免重复编写SQL逻辑。例如,<font style="background-color:rgb(187,191,196);">yw_total_sales_by_event.sql</font>可以引用Staging层的数据,进一步实现业务逻辑。
3.3 文档生成与数据血缘
dbt不仅能够进行数据转换,还提供了强大的文档生成功能,包括数据血缘图,通过执行dbt docs generate命令生成文档,并使用dbt docs serve启动本地Web服务,即可查看详细的模型信息。
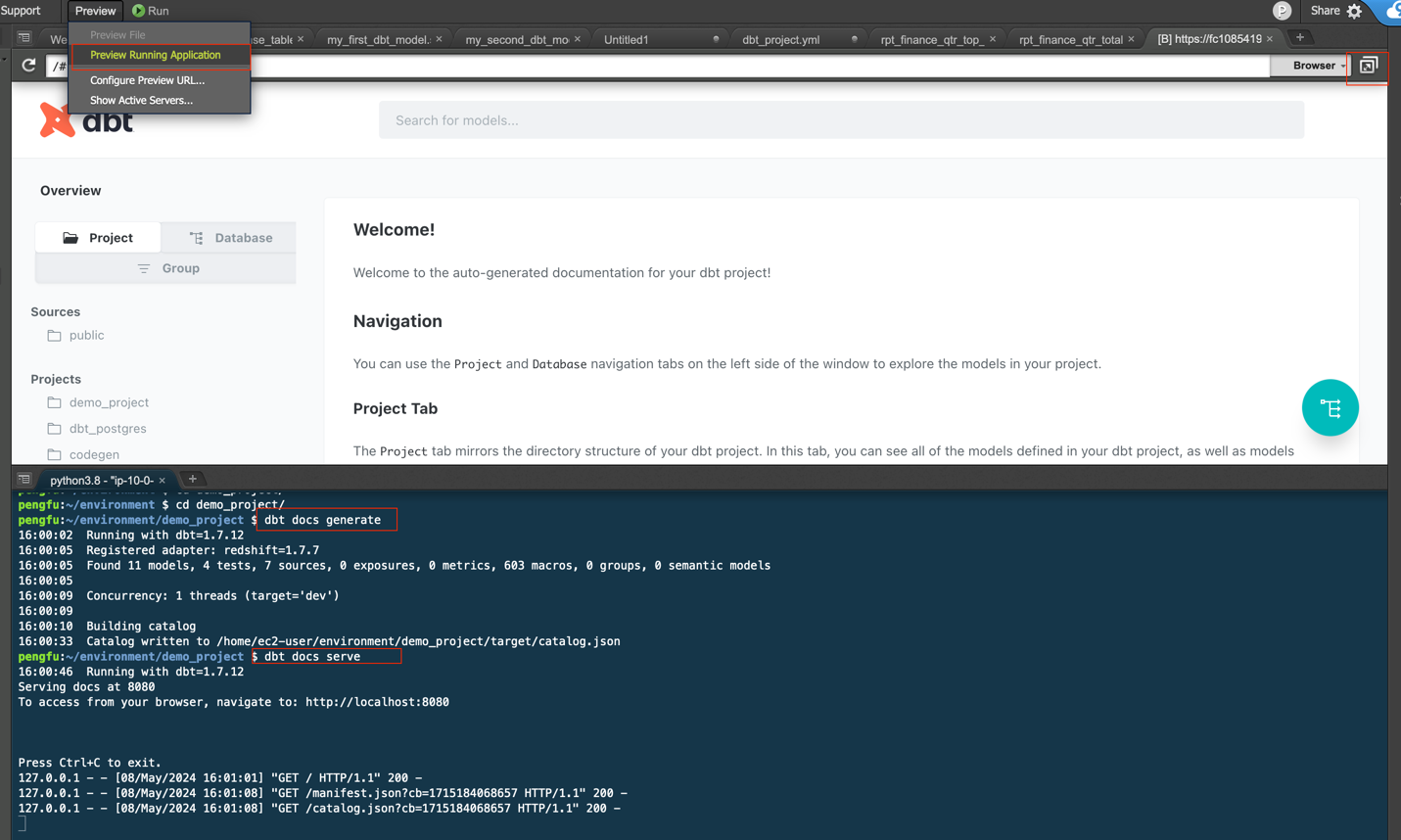
打开右上角 pop out 一个新的窗口,查看文档细节。借助 dbt document,我们可以看到文档(含字段)和血缘了。包括 project 下建立的模型,数据库详情,SQL 代码以及编译后的代码。具有非常好的可读性,助力团队内外不同人员去了解数据开发的情况。
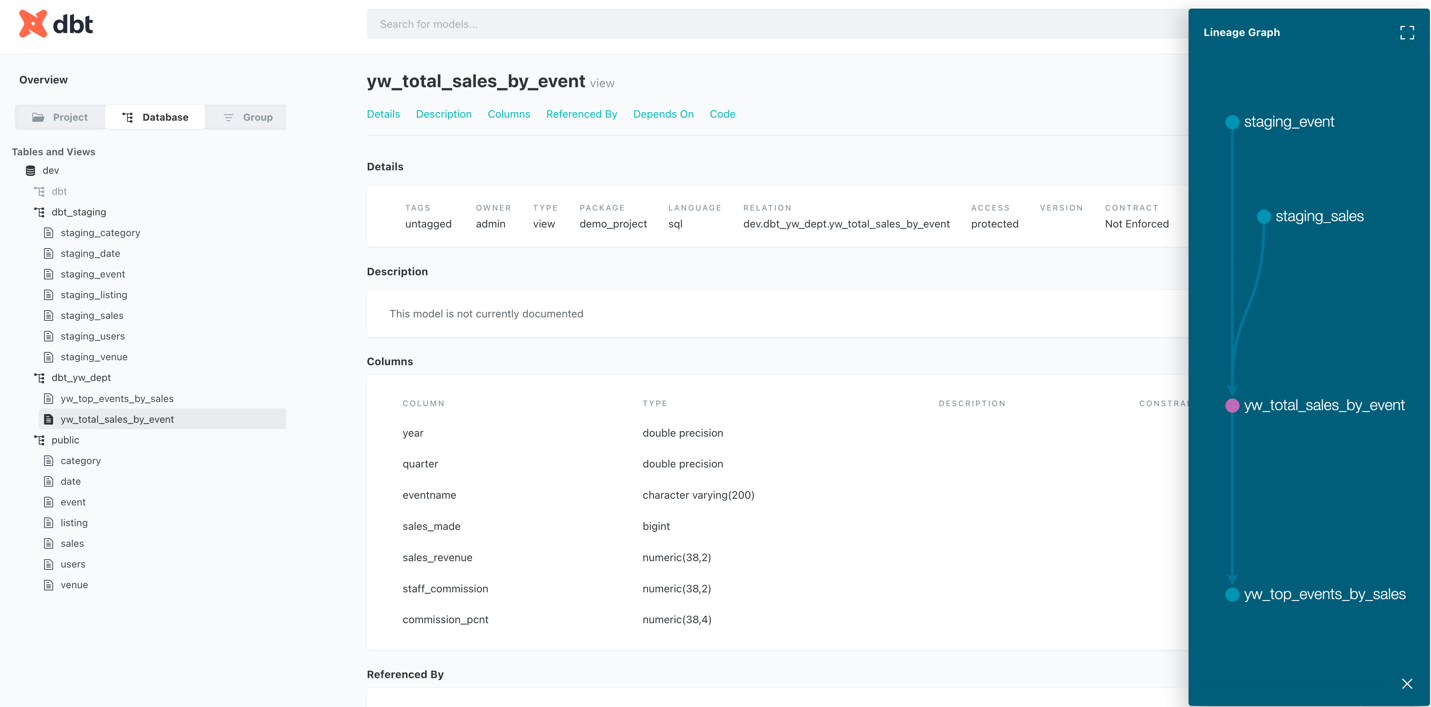
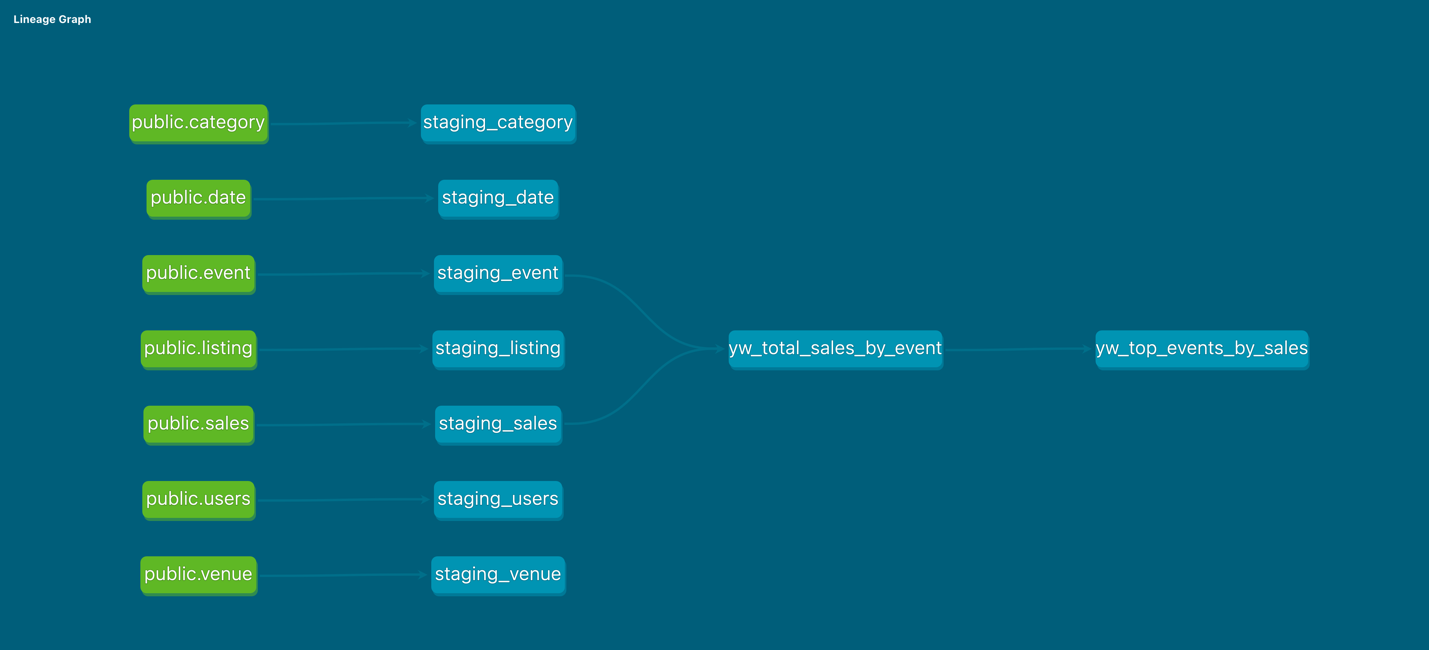
通过 dbt 文档,可以看到表级别血缘图,满足客户对数据分析中血缘关系的需求。
3.4 工作流编排与自动化运行
MWAA作为托管式Apache Airflow环境,负责将dbt数据处理任务集成到自动化工作流中,实现定时调度和监控。
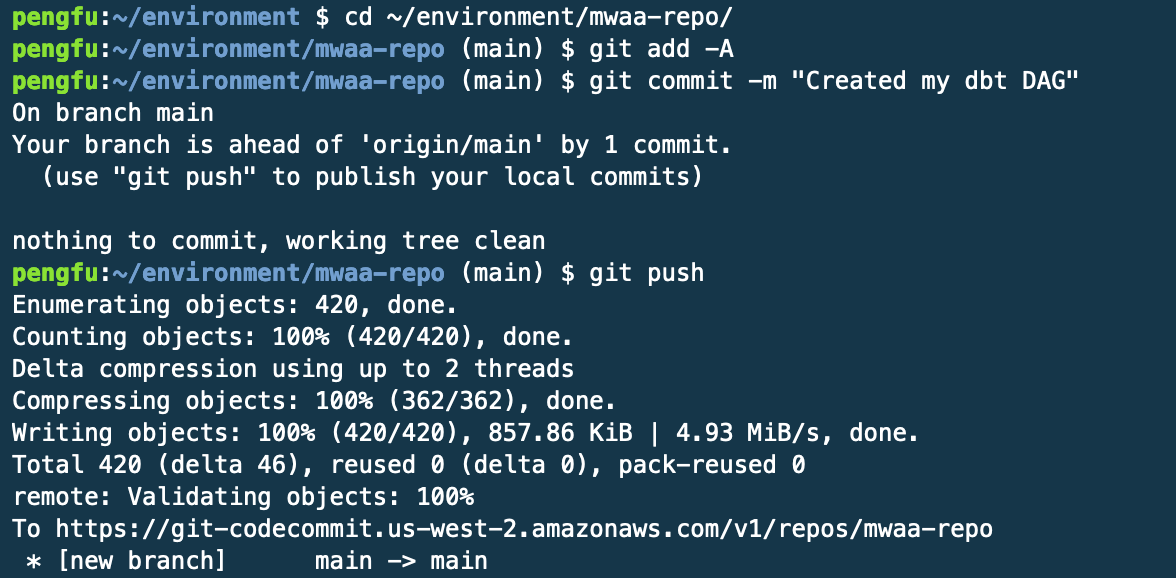
首先,需要将整个dbt项目和Airflow DAG文件(如dbt_dags.py)复制到MWAA环境关联的S3桶中的dags文件夹下。然后,将这些文件推送到Amazon CodeCommit存储库,之前配置的CodePipeline将自动触发,并将更新后的文件同步到MWAA的S3桶。
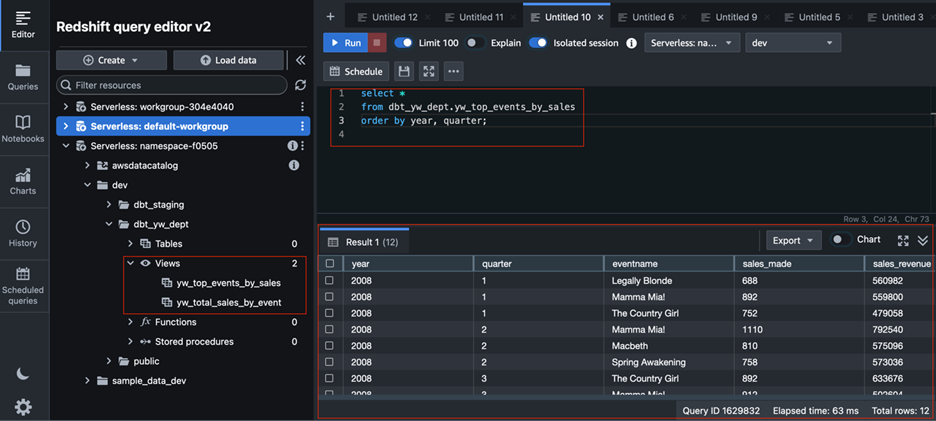
一旦文件同步完成,MWAA将自动发现新的DAG文件。登录MWAA的Airflow UI,即可看到名为dbt_dag的DAG。用户可以在Airflow UI中手动触发dbt_dag的运行,或等待其按计划自动执行。工作流运行成功后,dbt任务将在Amazon Redshift中执行数据转换和物化操作。通过登录Redshift Query Editor v2,检查之前定义的视图和表是否已更新,并且数据是否已成功生成,即可验证整个数据处理工作流已成功自动化运行。
亚马逊云科技现提供免费套餐服务,登录亚马逊官网,即可获得Amazon Deadline Cloud 等众多亚马逊云科技产品和服务的免费实践体验,注册即可获得 100 美元的服务抵扣金。
为避免产生不必要的费用,在实验结束后,请务必清理在亚马逊云科技账户中创建的所有资源。
四、未来展望
现代数据栈的演进永无止境,基于Amazon Redshift、dbt和MWAA的方案为企业构建了一个坚实的数据基础。未来,我们可以预见以下几个主要发展方向:更深度的自动化与智能化、实时数据处理能力的增强、多云与混合云集成、数据治理与安全合规的强化以及自助式数据分析的普及。
亚马逊云科技作为领先的云服务提供商,将持续创新其数据和分析服务,为现代数据栈的演进提供强大的技术支撑。我们期待这些技术能够帮助企业更好地驾驭数据,在数字化转型的浪潮中取得更大的成功。
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)