深度分析:AI智能体记忆是如何管理的?
AI 智能体记忆管理已从简单的 "存储 - 检索" 发展为完整的记忆生态系统,核心技术包括:分层记忆架构模拟人类记忆机制;向量化存储实现语义理解和快速检索;生命周期管理确保记忆 "质" 与 "量" 的平衡;上下文整合让记忆与推理深度融合;以及各类专用框架提供一站式解决方案。
记忆(Memory)是AI智能体必备的能力之一。
随着对话轮数与深度的增加,如何让AI智能体“记住”过去的上下文,是实现精准理解与个性化AI系统的关键。由于LLM存在上下文长度限制,如果不对记忆进行优化,长对话很容易带来两个问题:
遗忘早期信息,导致理解偏差,过度消耗大量计算资源与成本。关于智能体的记忆管理我们之前有一些工具框架的介绍:
如何让AI 智能体拥有持久记忆:基于 LangGraph 的记忆管理实践指南
那么,今天咱们探讨一下AI智能体记忆管理的相关问题。
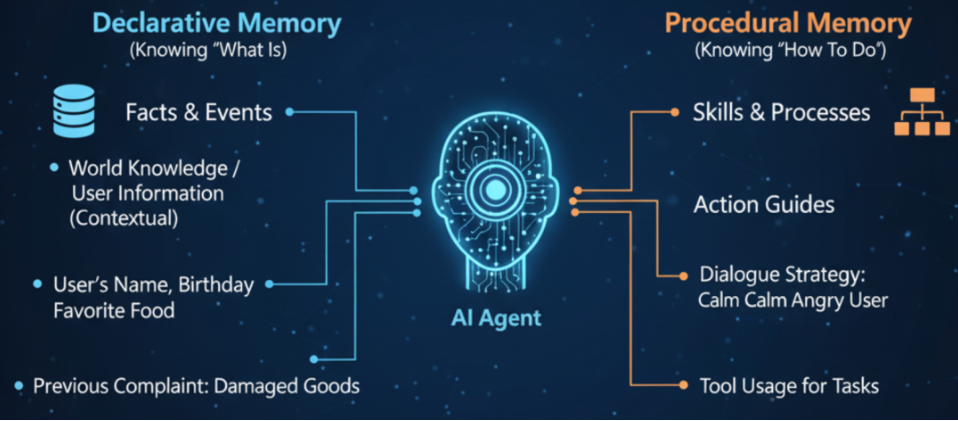
分层记忆架构:模拟人类记忆系统
AI 智能体采用多级记忆结构,实现从即时响应到长期知识积累的全链路管理:
1. 短期记忆 (STM / 工作记忆)
- 实现方式:
-
对话上下文窗口:保留最近 N 轮交互 (5-10 轮)
-
状态跟踪:存储当前任务进度、参数和临时数据
-
LangGraph 中通过 Checkpointer 实现线程级持久化,支持对话恢复
-
- 存储介质
:内存 / Redis,响应时间 <10ms,容量受 LLM 上下文窗口限制 (通常 8K-32K tokens)
2. 中期记忆 (情景记忆)
- 功能定位
-
跨会话但有限期的关键信息存储
-
任务流程和执行轨迹记录
-
- 技术特点
-
向量数据库存储 (FAISS/Milvus),支持语义检索
-
时效性控制 (TTL),自动清理过时信息
-
支持 "记忆快照",记录特定时间点的完整状态
-
3. 长期记忆 (LTM / 知识库)
- 核心特性
-
永久性存储,跨对话、跨应用、跨系统共享
-
结构化组织:命名空间 + 唯一键 + 值的三级架构
-
LangGraph 中通过 Store 实现,支持 JSON 文档存储和语义搜索langchain-ai.github.io
-
- 存储方案
:关系型数据库 (PostgreSQL)+ 向量索引,支持 TB 级数据和复杂查询
向量化存储与检索:记忆系统的 "神经网络"
1. 记忆编码技术

- 嵌入模型选择:
-
通用:Sentence-BERT、OpenAI Embeddings (ada-2)
-
专用:BAAI-Embedding、DeepSeek-Embeddings (语义理解更精准)
-
- 关键优化:
-
增量编码:仅对变化部分重新生成向量,节省 90% 计算资源
-
多模态支持:文本 + 图像 + 音频联合编码,构建统一语义空间
-
2. 向量数据库核心算法
-
HNSW (分层可导航小世界):
-
构建多层图索引,查询速度可达 μs 级,适合大规模数据 (10M+)
-
空间复杂度 O (n log n),检索精度 > 95%,内存占用可控
-
-
IVF-PQ (倒排文件 + 乘积量化):
-
将向量空间聚类,压缩存储 (减少 75% 内存),保持高召回率
-
适合内存受限环境,支持亿级向量高效检索
-
3. 记忆检索策略
|
检索类型 |
实现方式 |
适用场景 |
优势 |
|---|---|---|---|
|
精确检索 |
按命名空间 + 键直接获取 |
用户 ID、订单号等唯一标识查询 |
速度快 (ms 级),无歧义 |
|
语义检索 |
向量相似度匹配 (ANN) |
模糊查询、概念联想 |
理解意图,返回相关记忆 |
|
混合检索 |
关键词 + 向量联合搜索 |
复杂业务场景,需兼顾效率和精度 |
召回率提升 40%,减少误匹配 |
|
元数据过滤 |
时间戳 + 标签 + 权限组合筛选 |
权限管控、时效查询 |
精确缩小检索范围,提升效率 |
记忆生命周期管理:智能体的 "新陈代谢"
1. 记忆创建策略
- 热路径创建
交互过程中实时存储,优点是信息完整,缺点是影响响应速度langchain-ai.github.io
- 异步创建
通过后台任务处理,避免主流程延迟,适合高并发场景langchain-ai.github.io
- LLM 辅助提炼

2. 记忆更新机制
- 增量更新
仅记录变化部分,节省存储 (减少 80% 写入量),保持历史版本
- 冲突消解
-
时间戳优先:新信息覆盖旧信息
-
置信度排序:高可信度源更新低可信度源
-
人工审核:敏感信息更新需确认
-
3. 记忆清理与优化
-
遗忘策略
-
TTL 过期:设置记忆存活时间 (如用户会话 30 天后自动删除)
-
使用频率衰减:长期未访问的记忆优先级降低,最终被淘汰
-
重要性评分:根据信息对任务的价值动态调整保留时长
-
-
记忆压缩
-
对话历史修剪:移除最早 / 最不相关的消息,保持上下文窗口大小
-
摘要替代:用 LLM 生成的摘要替换完整对话,节省 90% 空间
-
知识蒸馏:提取共性模式,形成更高效的 "经验包"
-
上下文管理与记忆整合:让记忆 "活" 起来
1. 对话历史管理技术
-
消息修剪 (Trimming):
-
头部修剪:移除最早的对话 (适合短期任务)
-
尾部保留:只保留最近 N 轮 (适合长对话)
-
LangChain 提供
trim_messages函数,支持灵活策略配置持核心信息,适合超长对话
-
2. 记忆 - 推理融合机制
-
检索增强生成 (RAG):
突破模型参数限制,将外部知识无缝整合到回答中
-
反思机制:
-
执行结果 → 与预期对比 → 生成经验教训 → 更新知识库
-
形成 "行动 - 反馈 - 学习" 闭环,持续优化决策质量
-
3. 多智能体记忆协作
-
记忆共享协议
-
MCP (模型上下文协议):标准化智能体与数据库交互,支持自然语言操作
-
记忆交换格式:定义统一接口,实现跨智能体知识传递
-
-
协作优化技术
-
分层摘要:减少智能体间通信量,保留关键信息 (节省 60-80% 带宽)
-
选择性保留:保存 "经验记录与回放"(AgentRR),在类似任务中复用成功路径
-
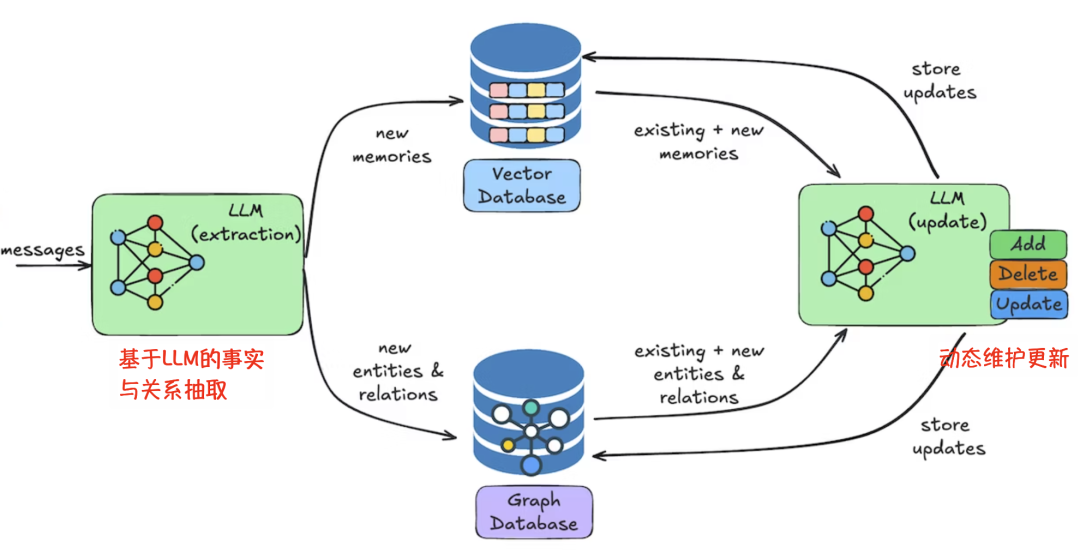
主流记忆管理框架对比
|
框架 |
核心优势 |
适用场景 |
技术特点 |
|---|---|---|---|
|
LangGraph |
与工作流深度集成,状态管理自然 |
流程化应用、Graph 工作流 |
Checkpointer+Store 双引擎,支持短期 / 长期记忆无缝衔接langchain-ai.github.io |
|
Letta (原 MemGPT) |
分层内存架构,自主管理 |
企业级应用、长对话系统 |
内存块 (Memory Blocks)+ 归档记忆,类似操作系统内存管理 |
|
Mem0 |
轻量级 + 高性能,集成图谱记忆 |
个人助手、小型应用 |
向量 + 图数据库双存储,检索速度 < 50ms |
|
MemOS |
记忆为核心的操作系统级抽象 |
大规模 AI 基础设施 |
MemCube 统一记忆表示,支持记忆生命周期全管理 |
|
SEDM |
自进化、分布式记忆网络 |
多智能体协作、长期学习 |
实证主义准入 + 证据驱动调度,记忆可自我优化和进化 |
技术选型与实施路径建议
1. 场景化技术选择
-
轻量级应用 / 个人助手:Mem0+SQLite,成本低 (几乎免费),部署简单,满足基础记忆需求
-
企业级客服 / 知识库:Letta + 向量数据库 (Milvus/Pinecone),支持 TB 级数据和复杂语义检索,提升服务连贯性和个性化水平
-
复杂业务流程 / 工作流:LangGraph+PostgreSQL,将记忆管理自然融入业务流程,支持任务恢复和状态追踪langchain-ai.github.io
-
多智能体协作系统:SEDM + 分布式存储,构建自进化记忆网络,支持跨智能体知识共享和协同优化
2. 实施关键点
-
向量化优先:所有关键信息都应转换为向量存储,实现语义检索和联想能力
-
冷热分离:

-
渐进式增强:先实现基础记忆 (短期 + 简单长期),再逐步添加复杂功能 (如记忆提炼、自动清理)
那么总结一下:
AI 智能体记忆管理已从简单的 "存储 - 检索" 发展为完整的记忆生态系统,核心技术包括:分层记忆架构模拟人类记忆机制;向量化存储实现语义理解和快速检索;生命周期管理确保记忆 "质" 与 "量" 的平衡;上下文整合让记忆与推理深度融合;以及各类专用框架提供一站式解决方案。
选择技术时应根据应用场景、规模和预算进行平衡,建议先从轻量级方案 (Mem0+SQLite) 开始验证,再根据业务增长逐步升级至企业级解决方案 (Letta + 向量数据库),最终构建以记忆为中心的智能体生态。
可着手设计记忆使用指标 (如检索命中率、响应时间、存储效率),持续优化记忆管理策略,让 AI 智能体真正拥有 "持久记忆" 和 "学习能力",实现从工具到伙伴的质变。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)