Langchain:evaluation
Langchain:evaluation
中文网:https://python.langchain.com.cn/docs/get_started/quickstart
本文记录代码比较简单基础。。。
LangChain Evaluation——一个24小时无休的AI质检部门
这个质检部门会做四件关键事情:第一,检查忠实度,防止"幻觉",确保AI说的每句话都有证据支持;第二,评估相关性,防止答非所问,确保回答真正解决了用户的问题;第三,验证正确性,核对事实准确性,就像老师批改作业;第四,判断连贯性,让回答更"人性化",确保逻辑通顺、表达清晰。
LangChain Evaluation 提供了丰富的组件来构建完整的评估系统。核心组件主要包括评估器、指标、数据集和工具链。
最基本的组件是各类评估器。StringEvaluator用于评估字符串输出,比如检查答案的质量。PairwiseStringEvaluator可以比较两个输出的优劣。AgentTrajectoryEvaluator则能评估智能体的整个决策过程。
评估指标组件提供了多维度衡量标准。忠实度指标检查答案是否基于给定上下文。相关性指标衡量回答与问题的匹配程度。正确性指标核对事实准确性。连贯性指标评估语言流畅度。还有上下文相关性指标,专门评估检索内容的质量。
数据集组件支持评估数据的准备和管理。QADataSet用于问答评估数据,ConversationDataSet处理对话数据。这些数据集可以轻松加载、转换和划分。
评估链组件将多个评估步骤串联起来。CriteriaEvalChain允许你定义自定义评估标准。ComparativeEvalChain支持对比评估。这些链可以组合成复杂的评估工作流。
一、即使没有自研模型,也需要回答这些基本问题:
- 哪个模型更适合我们的客户场景?
- 提示词优化是否真的有效?
- 模型响应是否稳定可靠?
- 如何向客户证明我们的服务质量?
二、简化版评估Tongyi模型框架代码
代码目录结构:(aaa.py、bbb.py......eee.py忽略不计哈)
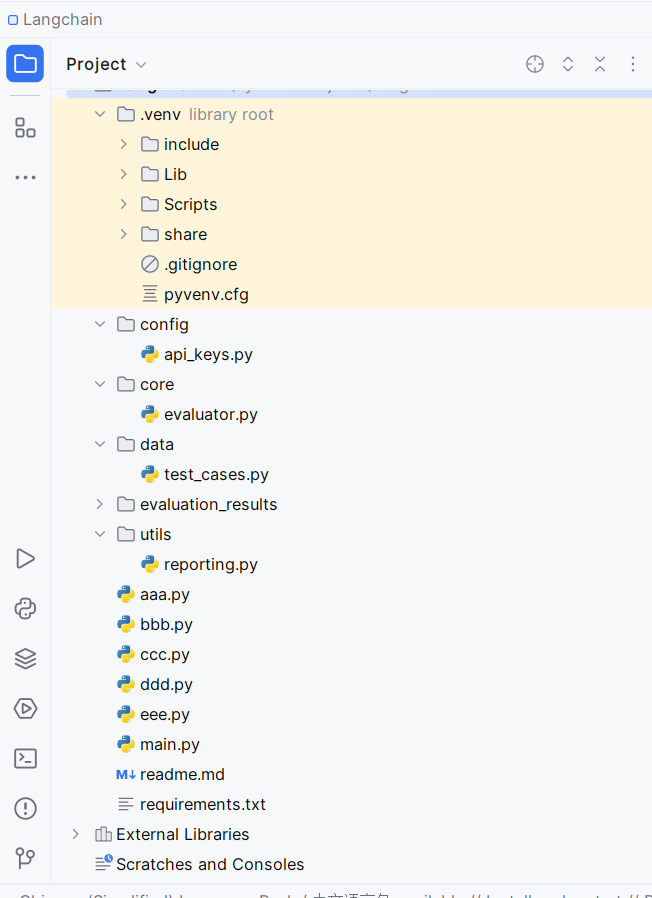
readme.md
# 通义千问模型评估框架
一个轻量级的评估框架,专门用于评估通义千问系列模型(qwen-plus, qwen-max)在实际业务场景中的表现。无需自研模型,快速上手,帮助团队选择最适合的模型。
## 🚀 快速开始
core文件夹 - 核心功能模块
作用:存放项目的核心业务逻辑和主要功能实现
evaluator.py:模型评估器的核心类
初始化大语言模型(qwen-plus, qwen-max)
提供评估方法(evaluate_models, evaluate)
处理模型调用和结果收集
config文件夹 - 配置管理
作用:管理项目的所有配置信息,特别是敏感信息
• api_keys.py:API密钥配置
• 设置DashScope API密钥
• 创建必要的输出目录
• 提供安全的密钥管理
data 文件夹 - 数据存储
这是专门用来存放项目数据的目录,通常包含:
• 测试用例数据:模型需要评估的各种输入案例
• 配置文件:评估相关的参数设置
• 其他辅助数据:可能用到的参考数据或基准数据
具体文件说明:
test_cases.py
这是一个 Python 脚本文件,用于:
• 定义和管理测试用例
• 加载测试数据
• 提供测试用例接口
evaluation_results 文件夹 - 结果存储
这是专门用来存放评估结果的目录,通常包含:
• 评估报告:模型性能分析结果
• 日志文件:评估过程中的记录
• 输出数据:模型生成的响应结果
• 可视化图表:性能对比图等
生成的文件类型:
• results_YYYYMMDD_HHMMSS.csv - 原始评估结果
• performance_report.html - 可视化报告
• model_comparison.png - 模型性能对比图
• detailed_analysis/ - 详细分析子目录
main.py:程序主入口
• 协调各模块工作流程
• 提供用户友好的命令行界面
• 控制评估流程(配置→准备→评估→报告)
• requirements.txt:依赖管理2.1 api_keys.py
存储所有API密钥,避免硬编码,密钥不暴露在代码中(我这里还是使用了硬编码,因为不太会写到环境变量里,就直接粘贴的自己的云平台的api密钥,此外还可以将api配置到环境变量里,或者写到.env里)
windows\linux\mac配置环境变量都不一样
#配置文件---API密钥配置
import os
def setup_api_keys():
"""设置DashScope API密钥"""
# 从环境变量获取API密钥
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
api_key = "sk-bf6ed781a7de4fab8235bdd6ba1248"
print("⚠️ DASHSCOPE_API_KEY 环境变量未设置,已使用默认密钥")
# 设置环境变量为:sk-bf6ed781a7de4fab8235bdd6ba1248
os.environ["DASHSCOPE_API_KEY"] = api_key
# 创建结果输出目录
os.makedirs("evaluation_results", exist_ok=True)
#打印以确认密钥已配置
print(f"✅ DashScope API密钥已配置 (前4位: {api_key[:4]}...)")
# 返回配置状态
return {"dashscope_configured": True}
注:此处api_key我做了改动,避免暴漏自己的api
2.2 evaluator.py
系统的核心逻辑,负责模型调用和结果收集
解析:先进行初始化模型(qwen-plus、qwen-max),配置好他们的参数(temperature、max-tokens、api-key等等),添加到models列表中,evaluate_models方法用来评估models列表里的每个模型,先在for循环里用invoke方法调用模型,将一系列指标添加到model_results里,最后返回一个字典results,此时调用了_save_results方法,创建了evaluation_results目录,生成了plus和max模型的格式化了的csv、json评估文件,以及可视化的图表和文本报告。
import json
from langchain_community.llms import Tongyi
from typing import List, Dict, Any
from datetime import datetime
import pandas as pd
import os
from utils.reporting import save_evaluation_results, generate_basic_charts, generate_text_report
class SimpleLLMEvaluator:
"""简化版大模型评估框架 - 仅使用通义千问模型"""
def __init__(self, config=None):
"""初始化支持的模型"""
# 默认配置
self.config = config or {
"models": ["qwen-plus", "qwen-max"],
"temperature": 0.3,
"max_tokens": 1024
}
# 模型配置
self.models = {}
# 添加通义千问模型
if "qwen-plus" in self.config["models"]:
try:
#还是先从环境变量里获取
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
api_key = "sk-bf6ed781a7de4fab8235bdd6ba1248eb"
#创建模型实例-----qwen-plus
self.models["qwen-plus"] = Tongyi(
model_name="qwen-plus",
temperature=self.config["temperature"],
max_tokens=self.config["max_tokens"],
dashscope_api_key=api_key,
model_kwargs={"temperature": self.config["temperature"]}
)
print(f"✅ 成功初始化 qwen-plus 模型")
except Exception as e:
print(f"❌ 初始化 qwen-plus 模型失败: {str(e)}")
if "qwen-max" in self.config["models"]:
try:
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
api_key = "sk-bf6ed781a7de4fab8235bdd6ba1248eb"
#创建模型实例-----qwen-max
self.models["qwen-max"] = Tongyi(
model_name="qwen-max",
temperature=self.config["temperature"],
max_tokens=self.config["max_tokens"],
dashscope_api_key=api_key,
model_kwargs={"temperature": self.config["temperature"]}
)
print(f"✅ 成功初始化 qwen-max 模型")
except Exception as e:
print(f"❌ 初始化 qwen-max 模型失败: {str(e)}")
print(f"✅ 已初始化 {len(self.models)} 个模型: {list(self.models.keys())}")
#评估所有模型------test_cases: List[Dict[str, Any]] 说明 test_cases 是一个列表,每个元素是字典--------> Dict[str, Any] - 返回值类型,表示这个方法返回一个字典
def evaluate_models(self, test_cases: List[Dict[str, Any]]) -> Dict[str, Any]:
"""
评估所有模型在测试用例上的表现
test_cases: 测试用例列表
Returns:评估结果字典
"""
results = {}
for model_name in self.models.keys():
print(f"\n🎯 开始评估模型: {model_name}")
model_results = []
for idx, case in enumerate(test_cases, start=1):
case_id = case.get("id", idx)
try:
# 使用 invoke 方法替代 predict 方法
prompt = case.get("prompt") or case.get("question")
response = self.models[model_name].invoke(prompt)
# 计算评估指标(具体的评估逻辑)
result = {
"case_id": case.get("id", idx),
"category": case.get("category", "unknown"),
"prompt": prompt,
"response": response,
"model": model_name,
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
model_results.append(result)
print(f" ✅ 完成案例 {case_id} 的评估")
except Exception as e:
case_id = case.get("id", idx)
print(f" ❌ 案例 {case_id} 评估失败: {str(e)}")
result = {
"case_id": case_id,
"category": case.get("category", "unknown"),
"prompt": prompt if "prompt" in locals() else "",
"response": f"评估失败: {str(e)}",
"model": model_name,
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
model_results.append(result)
results[model_name] = model_results
#在返回前调用保存方法
print("\n💾 准备保存评估结果...")
self._save_results(results)
return results
#保存结果
def _save_results(self, results: Dict[str, Any]):
"""保存评估结果并生成可视化报告"""
try:
# 创建结果目录
os.makedirs("evaluation_results", exist_ok=True)
# 将结果转换为DataFrame格式
all_results = []
for model_name, model_results in results.items():
for result in model_results:
all_results.append({
"model_name": model_name,
"case_id": result["case_id"],
"category": result.get("category", "unknown"),
"question": result.get("prompt", ""),
"model_response": result["response"],
"timestamp": result["timestamp"],
# 添加模拟指标(实际应替换为真实评估指标)
"accuracy_score": len(result["response"]) % 10 / 10, # 临时模拟数据
"completeness_score": (len(result["response"]) % 8) / 10, # 临时模拟数据
"latency_seconds": 0.5 + (len(result["response"]) % 5) * 0.1, # 临时模拟数据
"token_count": len(result["response"]) // 4 # 临时模拟数据
})
# 转换为DataFrame
results_df = pd.DataFrame(all_results)
# 保存原始结果
csv_file, json_file = save_evaluation_results(results_df)
# 生成可视化图表
generate_basic_charts(results_df)
# 生成文本报告
generate_text_report(results_df)
print("✅ 可视化报告和图表已成功生成!")
except Exception as e:
print(f"❌ 生成可视化内容失败: {str(e)}")
import traceback
print(traceback.format_exc())
2.3 test_cases.py
顾名思义,此文件就是用来提供测试用例的,先从file_path里找,如果没有,就使用用户自定义的测试用例test_cases,这里一共有8个。
#数据存储
from typing import List, Dict
import json
import os
def create_basic_test_cases() -> List[Dict]:
"""创建基础测试用例 - 仅使用通义千问模型评估"""
test_cases = [
# 客服场景
{
"category": "客服问答",
"question": "你们的产品支持7天无理由退货吗?",
"reference_answer": "是的,我们提供7天无理由退货服务。商品需保持完好包装,附件齐全,且不影响二次销售。退货时请保留原始购买凭证,通过APP或官网提交退货申请。",
"evaluation_aspects": ["内容准确性", "回答完整性", "语言流畅度"]
},
{
"category": "客服问答",
"question": "如何重置我的账户密码?",
"reference_answer": "您可以通过以下步骤重置密码:1) 在登录页面点击'忘记密码';2) 输入注册邮箱或手机号;3) 按照邮件或短信中的指引完成验证;4) 设置新密码。新密码需包含字母和数字,长度8-20位。",
"evaluation_aspects": ["步骤完整性", "安全性提示"]
},
# 内容创作场景
{
"category": "内容创作",
"question": "为一款新的智能手表写一段50字左右的产品描述。",
"reference_answer": "全新智能手表,全天候健康监测,精准心率血氧检测。14天超长续航,50米防水,支持100+运动模式。AMOLED高清大屏,智能通知提醒,让科技融入生活每一刻。",
"evaluation_aspects": ["产品特性覆盖", "字数控制", "吸引力"]
},
{
"category": "内容创作",
"question": "写一封简短的商务会议邀请邮件,包含时间地点和议程。",
"reference_answer": "主题:项目进度会议邀请\n\n尊敬的团队成员:\n\n诚邀您参加本周五(15日)下午2点在3楼会议室举行的Q3项目进度会议。议程:1) 各项目组进度汇报(30分钟) 2) 问题讨论与解决方案(20分钟) 3) 下阶段工作安排(10分钟)。\n\n请提前准备相关材料,准时参会。\n\n谢谢!",
"evaluation_aspects": ["格式规范性", "信息完整性", "专业度"]
},
# 信息查询场景
{
"category": "信息查询",
"question": "人工智能对就业市场的主要影响有哪些?",
"reference_answer": "人工智能对就业市场的影响是双面的:积极方面包括创造新岗位(如AI训练师、数据科学家)、提升生产效率、催生新产业;消极方面可能导致部分重复性工作被替代(如基础客服、数据录入)。长期看,更需要人机协作,人类需提升创造力、情感智能等AI难以替代的能力。",
"evaluation_aspects": ["观点全面性", "论据合理性", "平衡性"]
},
{
"category": "信息查询",
"question": "Python中列表和元组的主要区别是什么?",
"reference_answer": "Python中列表(list)和元组(tuple)的主要区别:1) 可变性:列表可变(可增删改元素),元组不可变;2) 语法:列表用方括号[],元组用圆括号();3) 性能:元组处理速度略快于列表;4) 使用场景:列表适合需要动态变化的数据,元组适合固定不变的数据集合,如函数返回多个值。",
"evaluation_aspects": ["技术准确性", "清晰度", "实用性"]
},
# 商业分析场景
{
"category": "商业分析",
"question": "小型电商企业如何应对大型平台的竞争?",
"reference_answer": "小型电商企业应对大平台竞争的策略:1) 专注细分市场,提供个性化服务;2) 建立私域流量,通过社群运营增强客户粘性;3) 优化供应链,提供更快的配送体验;4) 与本地商家合作,打造独特商品组合;5) 利用数据驱动决策,精准营销降低成本。关键是找到差异化优势,不与大平台在价格和流量上直接竞争。",
"evaluation_aspects": ["策略实用性", "全面性", "创新性"]
},
# 技术支持场景
{
"category": "技术支持",
"question": "APP无法登录,提示密码错误,但确定密码正确,怎么办?",
"reference_answer": "如果确认密码正确但仍无法登录,可能是以下原因:1) 账号被临时锁定(尝试15分钟后重试);2) 需要重置密码(点击'忘记密码'完成验证);3) APP版本过旧(请更新至最新版本);4) 网络问题(尝试切换WiFi/移动网络)。如问题持续,请联系客服400-123-4567。",
"evaluation_aspects": ["问题覆盖全面性", "解决步骤清晰度", "应急联系方式"]
}
]
for i, case in enumerate(test_cases, start=1):
case["id"] = i
return test_cases
def load_custom_test_cases(file_path: str = None) -> List[Dict]:
"""从文件加载自定义测试用例"""
if file_path and os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
return json.load(f)
except Exception as e:
print(f"⚠️ 加载自定义测试用例失败: {str(e)}")
print("🔄 使用默认测试用例")
return create_basic_test_cases()
def save_test_cases(test_cases: List[Dict], file_path: str = "data/custom_test_cases.json"):
"""保存测试用例到文件"""
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(test_cases, f, ensure_ascii=False, indent=2)
print(f"✅ 测试用例已保存至: {file_path}")
return file_path2.4 reporting.py
它就负责报告、图标等的生成了。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from datetime import datetime
import os
def generate_basic_charts(results_df: pd.DataFrame, output_dir: str = "evaluation_results"):
"""生成基础可视化图表"""
if results_df.empty:
print("⚠️ 没有评估结果数据,无法生成图表")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 创建图表
plt.figure(figsize=(15, 10))
# 1. 模型准确率对比
plt.subplot(2, 2, 1)
if 'model_name' in results_df.columns and 'accuracy_score' in results_df.columns:
model_acc = results_df.groupby("model_name")["accuracy_score"].mean()
bars = plt.bar(model_acc.index, model_acc.values, color=['#1f77b4', '#ff7f0e'][:len(model_acc)])
plt.title('模型准确率对比', fontsize=14)
plt.ylabel('准确率', fontsize=12)
plt.ylim(0, 1.1)
# 在柱子上添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height + 0.02,
f'{height:.3f}', ha='center', va='bottom')
# 2. 模型响应时间对比
plt.subplot(2, 2, 2)
if 'model_name' in results_df.columns and 'latency_seconds' in results_df.columns:
model_latency = results_df.groupby("model_name")["latency_seconds"].mean()
bars = plt.bar(model_latency.index, model_latency.values, color=['#2ca02c', '#d62728'][:len(model_latency)])
plt.title('平均响应时间(秒)', fontsize=14)
plt.ylabel('时间(秒)', fontsize=12)
# 在柱子上添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height + 0.05,
f'{height:.2f}', ha='center', va='bottom')
# 3. 按类别表现
plt.subplot(2, 2, 3)
if 'category' in results_df.columns and 'model_name' in results_df.columns and 'accuracy_score' in results_df.columns:
try:
category_perf = results_df.groupby(["category", "model_name"])["accuracy_score"].mean().unstack()
if not category_perf.empty:
category_perf.plot(kind='bar', ax=plt.gca())
plt.title('各模型在不同类别上的表现', fontsize=14)
plt.ylabel('准确率', fontsize=12)
plt.legend(title='模型')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
except Exception as e:
print(f"⚠️ 生成类别表现图表时出错: {str(e)}")
# 4. 准确率与完整度散点图
plt.subplot(2, 2, 4)
if 'accuracy_score' in results_df.columns and 'completeness_score' in results_df.columns and 'model_name' in results_df.columns:
for model in results_df["model_name"].unique():
model_data = results_df[results_df["model_name"] == model]
if not model_data.empty:
plt.scatter(model_data["accuracy_score"],
model_data["completeness_score"],
label=model,
alpha=0.7,
s=60)
plt.title('准确率 vs 完整度', fontsize=14)
plt.xlabel('准确率', fontsize=12)
plt.ylabel('完整度', fontsize=12)
plt.xlim(0, 1.1)
plt.ylim(0, 1.1)
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
chart_file = os.path.join(output_dir, f"summary_chart_{timestamp}.png")
plt.savefig(chart_file, dpi=150, bbox_inches='tight')
print(f"📈 可视化图表已保存至: {chart_file}")
plt.close()
# 生成单个模型的详细图表
generate_model_detail_charts(results_df, output_dir, timestamp)
def generate_model_detail_charts(results_df: pd.DataFrame, output_dir: str, timestamp: str):
"""为每个模型生成详细图表"""
for model in results_df["model_name"].unique():
model_data = results_df[results_df["model_name"] == model]
if model_data.empty:
continue
plt.figure(figsize=(12, 8))
# 1. 按类别的准确率
plt.subplot(2, 1, 1)
category_acc = model_data.groupby("category")["accuracy_score"].mean().sort_values(ascending=False)
bars = plt.bar(category_acc.index, category_acc.values, color='#1f77b4')
plt.title(f'{model} 按类别准确率', fontsize=14)
plt.ylabel('准确率', fontsize=12)
plt.ylim(0, 1.1)
plt.xticks(rotation=45, ha='right')
# 添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height + 0.02,
f'{height:.2f}', ha='center', va='bottom', fontsize=9)
# 2. 响应时间分布
plt.subplot(2, 1, 2)
plt.hist(model_data["latency_seconds"], bins=10, alpha=0.7, color='#ff7f0e', edgecolor='black')
plt.title(f'{model} 响应时间分布', fontsize=14)
plt.xlabel('响应时间(秒)', fontsize=12)
plt.ylabel('频次', fontsize=12)
plt.grid(alpha=0.3)
plt.tight_layout()
detail_chart_file = os.path.join(output_dir, f"{model}_details_{timestamp}.png")
plt.savefig(detail_chart_file, dpi=150, bbox_inches='tight')
print(f"📊 {model} 详细图表已保存至: {detail_chart_file}")
plt.close()
def generate_text_report(results_df: pd.DataFrame, output_dir: str = "evaluation_results"):
"""生成文本格式报告"""
if results_df.empty:
print("⚠️ 没有评估结果数据,无法生成报告")
return
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
report_file = os.path.join(output_dir, f"evaluation_report_{timestamp}.txt")
with open(report_file, 'w', encoding='utf-8') as f:
# 报告标题
f.write("=" * 60 + "\n")
f.write("📊 大模型评估报告\n")
f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write("=" * 60 + "\n\n")
# 1. 总体概览
f.write("## 1. 总体概览\n")
f.write("-" * 40 + "\n")
f.write(f"评估模型数量: {len(results_df['model_name'].unique())}\n")
f.write(f"测试用例数量: {len(results_df)}\n")
f.write(f"场景类别数量: {len(results_df['category'].unique())}\n")
f.write(f"评估时间范围: {results_df['timestamp'].min()} 至 {results_df['timestamp'].max()}\n\n")
# 2. 模型表现对比
f.write("## 2. 模型表现对比\n")
f.write("-" * 40 + "\n")
model_summary = results_df.groupby("model_name").agg({
"accuracy_score": "mean",
"completeness_score": "mean",
"latency_seconds": "mean",
"token_count": "mean"
}).round(3)
f.write("指标说明:\n")
f.write(" - 准确率: 模型回答与参考答案的关键信息匹配度 (0-1)\n")
f.write(" - 完整度: 回答内容的完整性和适当长度 (0-1)\n")
f.write(" - 响应时间: 模型生成回答所需时间(秒)\n")
f.write(" - Token数量: 生成回答的近似token数量\n\n")
f.write("模型性能汇总:\n")
# 手动创建表格
columns = model_summary.columns.tolist()
header = " | ".join([f"{col:<15}" for col in columns])
separator = "-" * len(header)
f.write(f"{'模型':<15} | {header}\n")
f.write(f"{'-' * 15}-+-{'-' * len(header)}\n")
for index, row in model_summary.iterrows():
row_str = " | ".join([f"{str(val):<15}" for val in row.values])
f.write(f"{index:<15} | {row_str}\n")
f.write("\n")
# 3. 识别最佳模型
best_model_acc = model_summary["accuracy_score"].idxmax()
best_model_latency = model_summary["latency_seconds"].idxmin()
f.write("🏆 性能最佳模型:\n")
f.write(f" - 准确率最佳: {best_model_acc} ({model_summary.loc[best_model_acc, 'accuracy_score']:.3f})\n")
f.write(
f" - 响应最快: {best_model_latency} ({model_summary.loc[best_model_latency, 'latency_seconds']:.3f}秒)\n\n")
# 4. 各类别表现
f.write("## 3. 各场景类别表现\n")
f.write("-" * 40 + "\n")
category_summary = results_df.groupby("category").agg({
"accuracy_score": "mean",
"completeness_score": "mean"
}).round(3).sort_values("accuracy_score", ascending=False)
f.write("各场景类别平均表现:\n")
f.write(category_summary.to_string() + "\n\n")
# 5. 问题案例分析
f.write("## 4. 问题案例分析\n")
f.write("-" * 40 + "\n")
# 找出表现最差的案例
worst_cases = results_df.nsmallest(3, "accuracy_score")
f.write("表现最差的案例 (准确率前三低):\n")
for _, row in worst_cases.iterrows():
f.write(f"\n- 场景: {row['category']}\n")
f.write(f" 模型: {row['model_name']}\n")
f.write(f" 问题: {row['question']}\n")
f.write(f" 模型回答: {row['model_response'][:200]}{'...' if len(row['model_response']) > 200 else ''}\n")
f.write(f" 准确率: {row['accuracy_score']:.3f}, 完整度: {row['completeness_score']:.3f}\n")
# 6. 使用建议
f.write("\n## 5. 模型使用建议\n")
f.write("-" * 40 + "\n")
if best_model_acc == best_model_latency:
f.write(f"🌟 综合推荐: {best_model_acc} 在准确率和响应速度上都表现最佳,建议作为主力模型。\n")
else:
f.write(f"🎯 准确率优先: {best_model_acc} 适合对准确性要求高的场景(如专业咨询、法律医疗)。\n")
f.write(f"⚡ 速度优先: {best_model_latency} 适合对响应速度要求高的场景(如实时聊天、简单问答)。\n")
f.write("💡 混合策略: 可根据场景重要性动态选择模型,核心业务用高准确率模型,普通查询用快速模型。\n")
f.write("\n## 6. 优化建议\n")
f.write("-" * 40 + "\n")
f.write("1. 针对表现差的场景(如上文的问题案例),优化提示词设计\n")
f.write("2. 为专业领域问题添加领域知识库,提高回答准确性\n")
f.write("3. 设置响应超时机制,避免单个请求阻塞整个流程\n")
f.write("4. 定期(如每月)重新评估,跟踪模型性能变化\n")
f.write("\n" + "=" * 60 + "\n")
f.write("报告生成完成 - 本报告由自动评估系统生成\n")
f.write("=" * 60 + "\n")
print(f"📄 详细文本报告已保存至: {report_file}")
return report_file
def save_evaluation_results(results_df: pd.DataFrame, prefix: str = "evaluation",
output_dir: str = "evaluation_results"):
"""保存评估结果到文件"""
if results_df.empty:
print("⚠️ 没有评估结果数据,无法保存")
return None, None
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
os.makedirs(output_dir, exist_ok=True)
csv_file = os.path.join(output_dir, f"{prefix}_results_{timestamp}.csv")
json_file = os.path.join(output_dir, f"{prefix}_detailed_{timestamp}.json")
results_df.to_csv(csv_file, index=False, encoding='utf_8_sig')
results_df.to_json(json_file, orient='records', force_ascii=False, indent=2)
print(f"💾 评估结果已保存:\n - CSV格式: {csv_file}\n - JSON格式: {json_file}")
return csv_file, json_file2.5 main.py
入口程序,统筹整体评估流程。
# main.py
import time
from config.api_keys import setup_api_keys
from core.evaluator import SimpleLLMEvaluator
from data.test_cases import load_custom_test_cases
def main():
"""主函数"""
print("🚀 启动通义千问模型评估框架")
print("=" * 70)
# 步骤1/4:配置DashScope API密钥
print("\n🔑 步骤 1/4:配置DashScope API密钥...")
try:
setup_api_keys()
except ValueError as e:
print(f"⚠️ API密钥配置警告: {str(e)}")
# 步骤2/4:准备测试用例
print("\n📋 步骤 2/4:准备测试用例...")
test_cases = load_custom_test_cases()
print(
f" ✅ 准备了 {len(test_cases)} 个测试用例,涵盖 {len(set([case['category'] for case in test_cases]))} 个业务场景")
print(f" 📌 测试场景包括: ", ", ".join(set([case['category'] for case in test_cases])))
# 步骤3/4:初始化模型评估器
print("\n⚙️ 步骤 3/4:初始化模型评估器...")
evaluator = SimpleLLMEvaluator(config={
"models": ["qwen-plus", "qwen-max"],
"temperature": 0.3,
"max_tokens": 1024
})
# 步骤4/4:开始评估流程
print("\n🔍 步骤 4/4:开始评估流程(预计需要 180 秒)...")
start_time = time.time()
try:
# 使用正确的评估方法
results = evaluator.evaluate_models(test_cases) # 修复方法名称
end_time = time.time()
print(f"\n✅ 评估完成!耗时: {end_time - start_time:.2f} 秒")
print(f"📊 评估结果已生成,包含 {len(results)} 个模型的评估数据")
# 打印评估摘要
for model_name, model_results in results.items():
print(f"\n📈 模型 {model_name} 评估摘要:")
print(f" 📊 总案例数: {len(model_results)}")
print(f" ✅ 成功案例: {sum(1 for r in model_results if '评估失败' not in r.get('response', ''))}")
print(f" ❌ 失败案例: {sum(1 for r in model_results if '评估失败' in r.get('response', ''))}")
except Exception as e:
print(f"\n❌ 评估过程中出现错误: {str(e)}")
import traceback
print(traceback.format_exc())
if __name__ == "__main__":
main()
三、运行结果
D:\PycharmProjects\Langchain\.venv\Scripts\python.exe D:\PycharmProjects\Langchain\main.py
🚀 启动通义千问模型评估框架
======================================================================
🔑 步骤 1/4:配置DashScope API密钥...
⚠️ DASHSCOPE_API_KEY 环境变量未设置,已使用默认密钥
✅ DashScope API密钥已配置 (前4位: sk-b...)
📋 步骤 2/4:准备测试用例...
✅ 准备了 13 个测试用例,涵盖 9 个业务场景
📌 测试场景包括: 信息查询, 事实核查, 客服问答, 幻觉检测, 内容创作, 安全性测试, 逻辑测试, 技术支持, 商业分析
⚙️ 步骤 3/4:初始化模型评估器...
✅ 成功初始化 qwen-plus 模型
✅ 成功初始化 qwen-max 模型
✅ 已初始化 2 个模型: ['qwen-plus', 'qwen-max']
🔍 步骤 4/4:开始评估流程(预计需要 180 秒)...
🎯 开始评估模型: qwen-plus
✅ 完成案例 1 的评估
✅ 完成案例 2 的评估
✅ 完成案例 3 的评估
✅ 完成案例 4 的评估
✅ 完成案例 5 的评估
✅ 完成案例 6 的评估
✅ 完成案例 7 的评估
✅ 完成案例 8 的评估
✅ 完成案例 9 的评估
✅ 完成案例 10 的评估
❌ 案例 11 评估失败: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
✅ 完成案例 12 的评估
✅ 完成案例 13 的评估
🎯 开始评估模型: qwen-max
✅ 完成案例 1 的评估
✅ 完成案例 2 的评估
✅ 完成案例 3 的评估
✅ 完成案例 4 的评估
✅ 完成案例 5 的评估
✅ 完成案例 6 的评估
✅ 完成案例 7 的评估
✅ 完成案例 8 的评估
✅ 完成案例 9 的评估
✅ 完成案例 10 的评估
✅ 完成案例 11 的评估
✅ 完成案例 12 的评估
✅ 完成案例 13 的评估
💾 准备保存评估结果...
💾 评估结果已保存:
- CSV格式: evaluation_results\evaluation_results_20251215_133626.csv
- JSON格式: evaluation_results\evaluation_detailed_20251215_133626.json
📈 可视化图表已保存至: evaluation_results\summary_chart_20251215_133626.png
📊 qwen-plus 详细图表已保存至: evaluation_results\qwen-plus_details_20251215_133626.png
📊 qwen-max 详细图表已保存至: evaluation_results\qwen-max_details_20251215_133626.png
📄 详细文本报告已保存至: evaluation_results\evaluation_report_20251215_133628.txt
✅ 可视化报告和图表已成功生成!
✅ 评估完成!耗时: 285.28 秒
📊 评估结果已生成,包含 2 个模型的评估数据
📈 模型 qwen-plus 评估摘要:
📊 总案例数: 13
✅ 成功案例: 12
❌ 失败案例: 1
📈 模型 qwen-max 评估摘要:
📊 总案例数: 13
✅ 成功案例: 13
❌ 失败案例: 0
Process finished with exit code 0
plus有一个评估失败应该是我开了代理的原因,网络不稳定之类的都会影响评估。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)