Spring AI 2.0 开发Java Agent智能体 - 嵌入模型(Embedding Model)与向量数据库(Vector Databases)
《Spring AI 2.0开发Java Agent智能体教程》摘要: 小锋老师推出Spring AI 2.0系列课程,涵盖核心功能如Advisors拦截器、Prompt工程、RAG检索增强等,后续将发布企业级AI实战项目(知识库与客服系统)。课程重点讲解了嵌入模型(Embedding)技术,通过向量化实现语义搜索,并演示了阿里百炼平台text-embedding-v4模型的应用及欧氏距离计算。向
大家好,我是Java1234_小锋老师,最近更新《2027版本 Spring AI 2.0 开发Java Agent智能体 视频教程》专辑,感谢大家支持。
本课程主要介绍和讲解Spring AI 2.0简介,Spring AI 2.0 HelloWorld搭建,Advisors — 拦截器模式增强AI能力,对话与提示词工程(Prompt),工具调用 (Function Calling / Tools) ,RAG (检索增强生成),MCP(模型 上下文协议)和多模态支持。
等这个Spring AI2.0基础课程录制完成,接下来要发布2个 企业级Java AI实战课程,RAG 企业知识库系统和AI智能客服系统。大家可以点点关注,后面更精彩。
视频教程+课件+源码打包下载:
链接:https://pan.baidu.com/s/1o-zRfndo1HHrS_uFroOiCw?pwd=1234
提取码:0000
Spring AI 2.0 开发Java Agent智能体 - 嵌入模型(Embedding Model)与向量数据库(Vector Databases)
一,什么是嵌入模型
1.1 什么是嵌入?
简单来说,嵌入(Embedding)是一种将非数字数据(如单词、句子、图像、甚至整个文档)转换为计算机能够理解的数字向量的技术。
向量是数学、物理学及工程科学中的基础概念,指同时具有大小和方向的量,与只有大小没有方向的标量(如温度、质量)相对。
- 数据:比如一句话:“我喜欢吃苹果”。
- 向量:经过嵌入模型处理后,这句话会变成一个由数百个浮点数组成的数组,例如:
[0.125, -0.342, 0.987, ..., 0.045]。
这个向量不是随机生成的,它通过复杂的神经网络模型训练得出,能够捕获原始数据的语义信息。
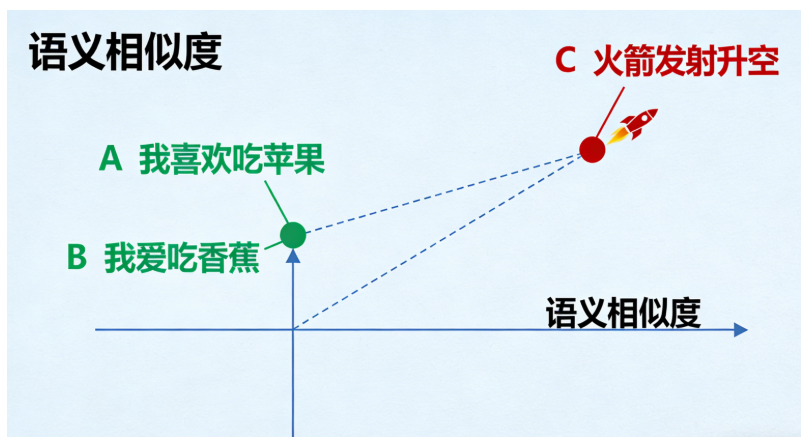
1.2 嵌入模型的核心作用:将“意义”映射到“向量空间”
嵌入模型最关键的特性是,它会把相似的语义内容映射到向量空间中的相近位置。
- 例子:
- 句子A:“我喜欢吃苹果”
- 句子B:“我爱吃香蕉”
- 句子C:“火箭发射升空”
经过嵌入模型后,在向量空间中:
- 句子A和句子B的距离会非常近(因为都是表达对水果的喜爱)。
- 句子C与A、B的距离会非常远(因为讨论的是完全不同的主题)。
1.3 为什么需要嵌入模型?
- 语义搜索:传统的搜索引擎依赖关键词匹配(比如搜索“苹果”只会返回包含“苹果”这两个字的结果)。而基于嵌入的搜索是语义上的理解和匹配,即使搜索“一种富含维生素的水果”,也能找到关于“苹果”的文档。
- 信息压缩与表示:将一个复杂的对象(图片、长文本)压缩成一个固定长度的、富含语义信息的向量。
- 作为大模型的“外部记忆”:这是最广泛的应用之一。大模型的知识是静态的(训练到某个时间点),且上下文窗口有限。通过嵌入,我们可以将海量的私有知识(公司文档、产品手册)向量化,然后在需要时检索出最相关的部分,再“喂”给大模型,让它基于这些知识回答问题,从而解决模型的知识局限和幻觉问题。
1.4 常见嵌入模型
- OpenAI 的 text-embedding-3-small 和 text-embedding-3-large:目前性能强大的通用文本嵌入模型。
- BAAI/bge-* 系列:北京智源研究院开源的优秀中英文嵌入模型。
- sentence-transformers:一个非常流行的Python库,提供了大量预训练的句子、段落嵌入模型。
- 多模态嵌入模型:如
CLIP,可以将图片和文本嵌入到同一个向量空间,实现文本搜图、图搜图等功能。
阿里百炼平台的嵌入模型,

目前文本嵌入模型,最新版本 text-embedding-v4,支持64~2048维用户自定义向量维度。
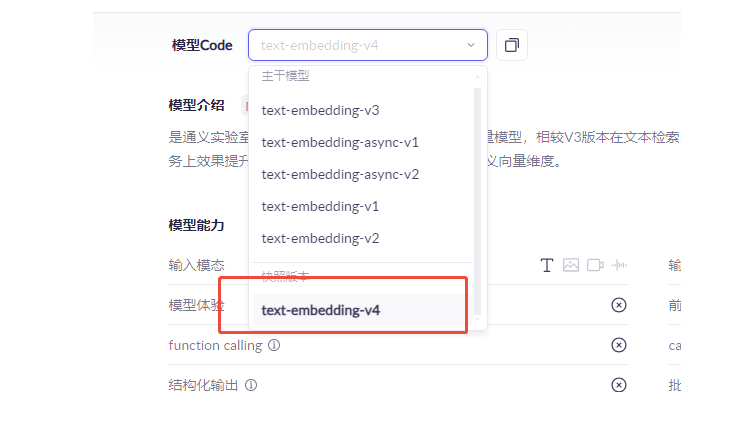
项目里,application.yml里我们指定下嵌入模型和维度
spring:
application:
name: helloWorld
ai:
model:
embedding: openai
openai:
api-key: ${OPENAI_API_KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode
chat:
options:
model: qwen3.6-plus
embedding:
options:
model: text-embedding-v4
dimensions: 2048 # 向量维度
然后controller包下,新建MyEmController,以及注入openAiEmbeddingModel,新建em测试方法。
package com.java1234.controller;
import org.springframework.ai.openai.OpenAiEmbeddingModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
@RestController
public class MyEmController {
@Autowired
private OpenAiEmbeddingModel openAiEmbeddingModel;
@RequestMapping("/em")
public String em() {
float[] textVector1=openAiEmbeddingModel.embed("学java上java1234.com");
System.out.println(textVector1.length+":"+Arrays.toString(textVector1));
return "OK";
}
}
浏览器输入:http://localhost:8080/em
控制台返回:

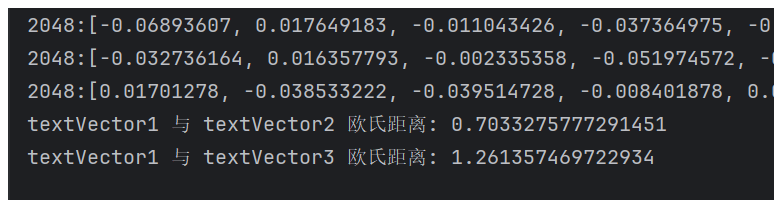
我们在看一个示例,求下欧氏距离,距离越小,说明越相似:
@RequestMapping("/em")
public String em() {
float[] textVector1=openAiEmbeddingModel.embed("学java上java1234.com");
float[] textVector2=openAiEmbeddingModel.embed("java1234.com网站教学Java质量真不错");
float[] textVector3=openAiEmbeddingModel.embed("我喜欢吃苹果");
System.out.println(textVector1.length+":"+Arrays.toString(textVector1));
System.out.println(textVector2.length+":"+Arrays.toString(textVector2));
System.out.println(textVector3.length+":"+Arrays.toString(textVector3));
double dist12 = euclideanDistance(textVector1, textVector2);
double dist13 = euclideanDistance(textVector1, textVector3);
System.out.println("textVector1 与 textVector2 欧氏距离: " + dist12);
System.out.println("textVector1 与 textVector3 欧氏距离: " + dist13);
return "OK";
}
/**
* 计算两个向量的欧氏距离
*
* @param a 向量1
* @param b 向量2
* @return 欧氏距离
*/
private static double euclideanDistance(float[] a, float[] b) {
if (a.length != b.length) {
throw new IllegalArgumentException("向量维度不一致");
}
double sumSq = 0;
for (int i = 0; i < a.length; i++) {
double d = a[i] - b[i];
sumSq += d * d;
}
return Math.sqrt(sumSq);
}
运行结果:
二,什么是向量数据库

2.1 什么是向量数据库?
向量数据库是一种专门设计用来存储、索引和查询向量数据的数据库。
传统的关系型数据库擅长存储和查询结构化数据(如表格中的姓名、年龄),但它们无法高效处理向量的“相似性检索”需求。
2.2 向量数据库的核心功能:相似性搜索
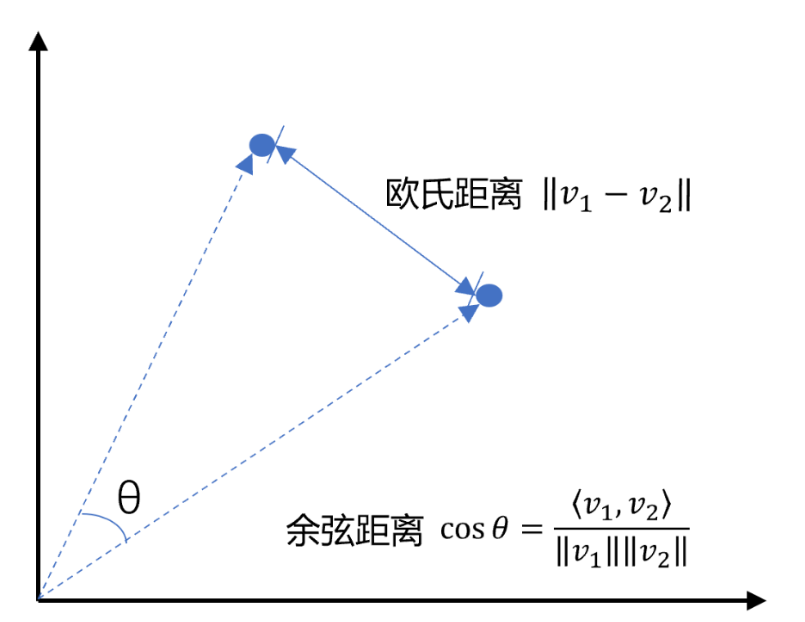
向量数据库的核心能力是近似最近邻检索。
-
任务:给定一个查询向量,在数据库中快速找到与之最相似的K个向量。
-
算法:它不进行暴力的一一比对,而是使用专门的索引算法(如 HNSW——分层可导航小世界图,IVF——倒排文件索引)来极大地提高搜索效率。即便数据库中有十亿个向量,也能在毫秒级内返回结果。
-
距离度量:通常通过计算向量之间的“距离”来衡量相似度。
- 余弦相似度:衡量方向上的相似度(最常用)。
- 欧氏距离:衡量空间中的直线距离。
- 点积:衡量两个向量的投影。
2.3 为什么需要向量数据库?
- 高效的检索性能:专为大规模向量相似性搜索优化,这是传统数据库无法做到的。
- 元数据过滤:在实际应用中,向量通常还附带元数据。例如,一个商品图片的向量可能还附有“商品ID”、“价格”、“类别”等信息。向量数据库允许你在进行相似性搜索时,先或同时根据这些元数据进行过滤(例如,“找到与这件红色T恤最相似的衣服,且价格低于100元”)。
- 数据管理:提供增删改查、数据持久化、备份、容灾等标准的数据库功能。
- 与嵌入模型和大模型的完美集成:它们共同构成了现代AI应用(如RAG——检索增强生成)的数据流水线。
2.4 常用的向量数据库有哪些
以下是5个最常用的向量数据库对比表格:
| 数据库 | 类型 | 特点 | 优点 | 适用场景 |
|---|---|---|---|---|
| Pinecone | 商业SaaS | 全托管云服务 | 上手最快,零运维,提供免费额度 | 快速原型开发,不想自己搭建维护的项目 |
| Milvus | 开源/商业 | 功能最全面的专业向量数据库 | 支持十亿级向量,索引类型丰富,性能强大 | 大规模生产环境,对性能要求高的场景 |
| Qdrant | 开源/商业 | Rust编写,性能优异 | 内存占用低,API友好,支持过滤 | 需要高性能、资源受限的环境 |
| Chroma | 开源 | Python原生,轻量级 | 极简API,与LangChain集成好,本地开发友好 | 本地开发、学习、小型项目 |
| pgvector | PostgreSQL扩展 | 基于PostgreSQL | 支持ACID事务,SQL语法,无需引入新数据库 | 已有PostgreSQL,向量数据量百万级以内 |
三,两者的协同工作 —— RAG流程示例
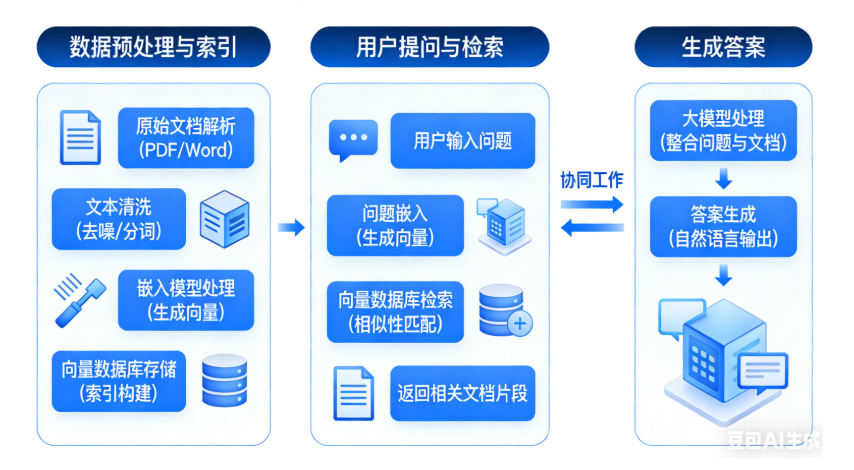
这是目前最经典的AI应用架构,可以清晰地看到嵌入模型和向量数据库是如何配合的。
场景:构建一个基于公司内部知识库的智能问答机器人。
第一步:数据预处理与索引(入库阶段)
- 准备文档:收集所有公司文档(PDF、Word、内部Wiki等)。
- 文本分块:将长文档切分成更小的段落或“块”。
- 生成嵌入:使用嵌入模型,为每一个文本块生成一个向量。
- 存储:将生成的向量,连同原始的文本块和相关的元数据(如文档来源、页码),一起存入向量数据库。
第二步:用户提问与检索(查询阶段)
- 用户提问:用户问:“我们公司的年假政策是什么?”
- 问题嵌入:使用相同的嵌入模型,将用户的这个问题也转换成一个向量。
- 向量检索:将这个代表问题的向量发送到向量数据库进行查询。数据库会迅速返回与问题向量最相似的K个文本块向量。
- 获取上下文:根据返回的向量ID,取出对应的原始文本块内容。
第三步:生成答案(生成阶段)
- 构建提示词:将用户的问题 + 检索到的相关文本块(作为上下文)组合成一个提示词。
- 调用大语言模型:将提示词发送给大语言模型(如GPT-4),并指示它“请根据提供的上下文回答问题”。
- 返回答案:大模型阅读并理解上下文后,生成一个准确、有据可依的答案返回给用户。
Spring AI2.0支持的向量数据库还是比较多的。我们课程选用Redis。
这里的Redis不是普通的Redis Server,而是支持向量存储的redis-stack。
我们windows跑的话,一般都是跑docker里的,windows平台建议大家去安装一个Docker Desktop,比较方便。
https://www.docker.com/products/docker-desktop/
接下来 直接 运行 安装,运行镜像命令:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 -v d:/redis-data:/data redis/redis-stack:latest
6379端口映射的是redis-stack服务,8001端口映射的是可视化服务。
接下来项目里把向量存入Redis-stack向量数据库。
首先第一步,pom.xml加下redis的向量支持依赖以及jedis客户端。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<!--
Spring AI RedisVectorStoreAutoConfiguration 仅在存在 JedisConnectionFactory 时生效(不用 Lettuce)。
因此改用 Jedis,并从 starter 中排除 Lettuce。
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
接下来第二步:application.yml里配置下redis连接,以及redis向量配置
spring:
application:
name: helloWorld
data:
redis:
client-type: jedis
url: redis://localhost:6379
ai:
model:
embedding: openai
vectorstore:
redis:
initialize-schema: true # 是否在启动时创建/初始化向量索引等结构
index-name: java1234_ai_vector_index # RediSearch 里的 索引名
prefix: "java1234_" # 存向量文档用的 Redis 键前缀
openai:
api-key: ${OPENAI_API_KEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode
chat:
options:
model: qwen3.6-plus
embedding:
options:
model: text-embedding-v4
dimensions: 2048 # 向量维度
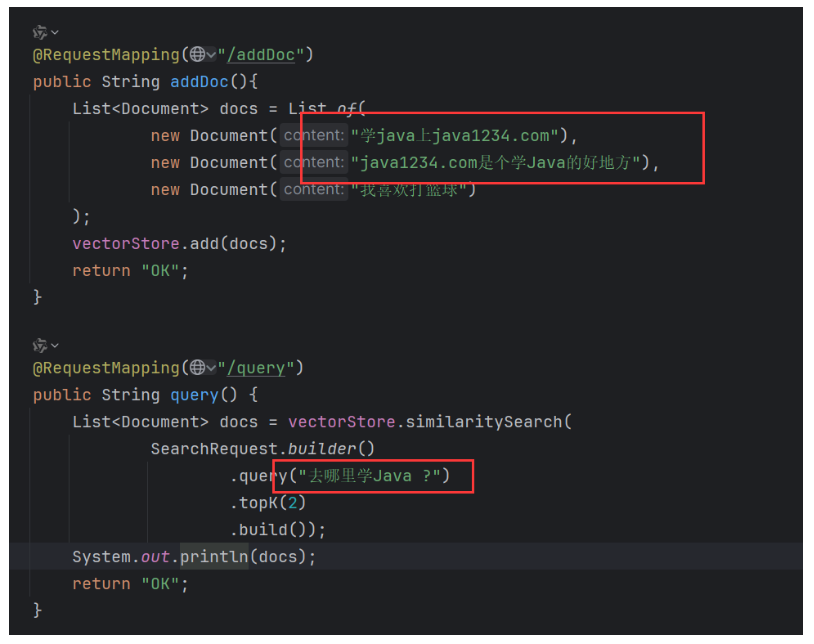
最后第三步,MyEmController里,我们注入VectorStore,以及写一个addDoc和query
package com.java1234.controller;
import org.springframework.ai.document.Document;
import org.springframework.ai.openai.OpenAiEmbeddingModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
@RestController
public class MyEmController {
@Autowired
private OpenAiEmbeddingModel openAiEmbeddingModel;
@Autowired
private VectorStore vectorStore;
@RequestMapping("/addDoc")
public String addDoc(){
List<Document> docs = List.of(
new Document("学java上java1234.com"),
new Document("java1234.com是个学Java的好地方"),
new Document("我喜欢打篮球")
);
vectorStore.add(docs);
return "OK";
}
@RequestMapping("/query")
public String query() {
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder()
.query("去哪里学Java ?")
.topK(2)
.build());
System.out.println(docs);
return "OK";
}
@RequestMapping("/em")
public String em() {
float[] textVector1=openAiEmbeddingModel.embed("学java上java1234.com");
float[] textVector2=openAiEmbeddingModel.embed("java1234.com网站教学Java质量真不错");
float[] textVector3=openAiEmbeddingModel.embed("我喜欢吃苹果");
System.out.println(textVector1.length+":"+Arrays.toString(textVector1));
System.out.println(textVector2.length+":"+Arrays.toString(textVector2));
System.out.println(textVector3.length+":"+Arrays.toString(textVector3));
double dist12 = euclideanDistance(textVector1, textVector2);
double dist13 = euclideanDistance(textVector1, textVector3);
System.out.println("textVector1 与 textVector2 欧氏距离: " + dist12);
System.out.println("textVector1 与 textVector3 欧氏距离: " + dist13);
return "OK";
}
/**
* 计算两个向量的欧氏距离
*
* @param a 向量1
* @param b 向量2
* @return 欧氏距离
*/
private static double euclideanDistance(float[] a, float[] b) {
if (a.length != b.length) {
throw new IllegalArgumentException("向量维度不一致");
}
double sumSq = 0;
for (int i = 0; i < a.length; i++) {
double d = a[i] - b[i];
sumSq += d * d;
}
return Math.sqrt(sumSq);
}
}
我们来测试下,浏览器输入:http://localhost:8080/addDoc
我们可以用 redis-stack可视化服务,来查看redis向量数据。浏览器输入:http://localhost:8001/
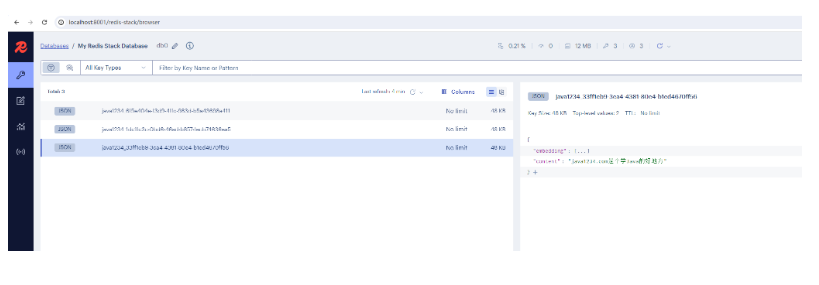
我们在通过VectorStore的 similaritySearch 方法进行相似性搜索。
浏览器输入:http://localhost:8080/query
返回结果:
[Document{id='1dc1fc3c-0bd6-46ad-b857-fecb74636ea5', text='学java上java1234.com', media='null', metadata={distance=0.15828251838684082, vector_score=0.316565096378}, score=0.8417174816131592}, Document{id='33ff1eb9-3ca4-4381-80e4-b1ed4670ff56', text='java1234.com是个学Java的好地方', media='null', metadata={distance=0.15871202945709229, vector_score=0.317424118519}, score=0.8412879705429077}]
找到两个最相似的结果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)