Deep Research技术总结及文档多模态大模型进展之Dolphin-v2
本文对比了RAG与DeepResearch在复杂任务处理上的差异。DeepResearch展现出三大优势:1)采用动态工作流支持多轮交互和任务分解,而RAG为静态流程;2)适配科研报告等长周期任务,超越RAG的短文本问答局限;3)通过引用验证和内存管理显著降低幻觉风险。文章还分析了字节Dolphin-v2文档多模态模型的创新:支持21类元素解析,采用两阶段混合处理策略(电子版元素级并行解析+拍摄文
看看DeepResearch的一个总结,其实在这个时间节点,可以看看和RAG对比。分几个点看。
在工作流灵活性上,RAG是静态检索-生成流程,DeepResearch是动态自主工作流,支持多轮工具交互、任务分解与迭代优化;在任务适配范围上,RAG侧重短文本问答,DeepResearch适配长周期、复杂开放任务(如科研报告、政策分析);在输出可靠性上,DeepResearch强调可验证输出,通过明确引用、证据合成、内存管理减少幻觉,而RAG对证据的整合与验证能力较弱。
顺着这个点,来看看一个全面些的综述。
多总结,多归纳,多从底层实现分析逻辑,会有收获。
一、文档多模态大模型进展之Dolphin-v2文档多模态大模型进展方面,可以看字节的文档多模态模型Dolphin-v2版本,https://huggingface.co/ByteDance/Dolphin-v2,基于Qwen2.5-VL-3B骨干网络,一共4B参数。看核心几个点。
1、四个优化点
其一,文档支持范围扩展,可同时处理数字原生和拍摄类文档(含真实失真场景);
其三,元素覆盖,类别从14类提升至21类,新增代码块、公式等专用类别;
包括:
sec_0-sec_5:层级标题(含主标题+1-5级子标题)、para:普通段落、half_para:跨列/跨行段落、equ:数学公式(输出LaTeX格式)、tab:表格(输出HTML格式)、code:代码块(保留原始缩进格式)、fig:图表(图像类元素)、cap:图表/表格标题、list:列表(有序/无序列表)、catalogue:目录、reference:参考文献、header/foot:页眉/页脚、fnote:脚注、watermark:水印、anno:注释
其三,坐标定位方面,采用绝对像素坐标定位;
其实,解析策略,采用混合解析策略,数字文档元素级并行解析+拍摄文档整体解析,搭配专用模块(如代码缩进保留、公式LaTeX生成),这个主要用的是分类的思路,分而治之。
2、模型的两阶段架构
首先,第一阶段(联合分类与布局分析):先文档类型分类,区分文档为“电子版”或“拍摄类”,再按阅读顺序生成元素序列并完成21类元素分类;
其次,第二阶段(混合内容解析),针对拍摄类文档采用“整体页面级解析”,适配失真、模糊等问题;
最后,针对电子版文档采用“元素级并行解析”,结合类型专用提示模块(P_formula:公式→LaTeX格式;P_code:代码块→保留缩进;P_table:表格→HTML格式;P_paragraph:段落→文本识别)。
二、Deep Research技术总结
来看一个Deep Research的技术总结,这个之前也有一些,已经有些场景,例如:
智能信息检索场景,处理复杂多跳查询(数据集:HotpotQA、GAIA、BrowseComp);
综合报告生成场景,综述、长文本报告、海报、幻灯片(数据集:ReportBench、SurveyGen、PPTEval);
科研辅助场景,想法生成、实验执行、学术写作、同行评审(数据集:ResearcherBench、REVIEW-5k);
软件工程场景,解决GitHub问题、自动化开发(数据集:SWE-Bench)
但温故而知新,再看看一个最新的总综述。
但温故而知新,再看看一个最新的总综述。

工作在《Deep Research: A Systematic Survey》,https://arxiv.org/pdf/2512.02038,https://github.com/mangopy/Deep-Research-Survey
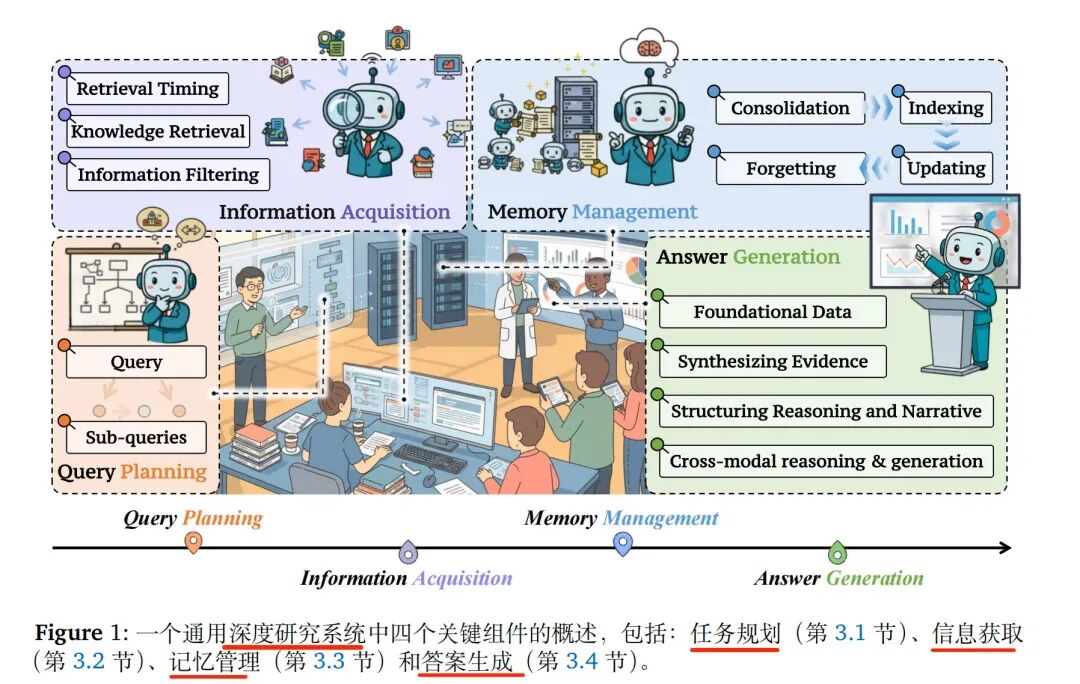
从系统上看,DeepResearch是一个典型闭环工作流,包括四个步骤:
步骤1.查询规划阶段,将复杂问题分解为可执行的子查询(支持并行、顺序、树状三种分解方式);
步骤2.信息获取阶段,通过文本/多模态/商业检索工具获取信息,动态判断检索时机并过滤噪声;
步骤3.内存管理阶段,负责信息的整合、索引、更新与遗忘,维持长周期任务的上下文连贯性;
步骤4.答案生成阶段,整合上游信息,解决证据冲突,结构化推理过程,支持文本、图表、幻灯片等多模态输出。
1、规划类型
查询规划,将复杂问题分解为可执行子查询,如下:
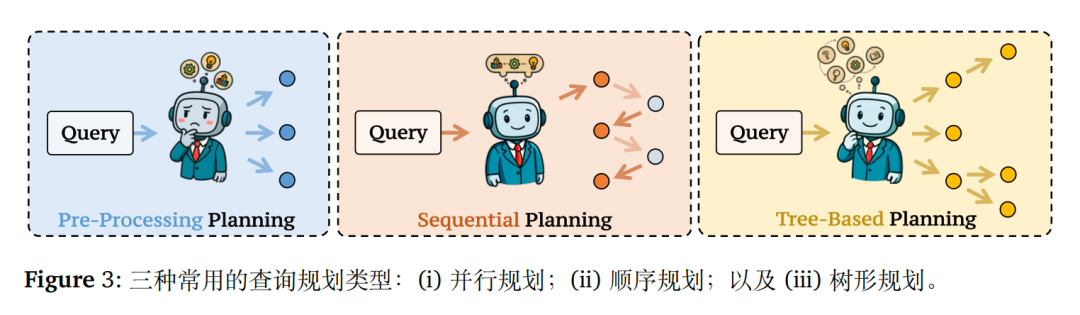
并行规划单次生成独立子查询,高效并行处理(如 Least-to-Most Prompting);
顺序规划迭代分解,依赖前序结果(如 LLatrieval、DRAGIN);
树状规划递归构建推理树,支持分支探索(如 RAG-Star、DeepRAG)
2、信息获取
信息获取,精准获取并筛选外部信息。
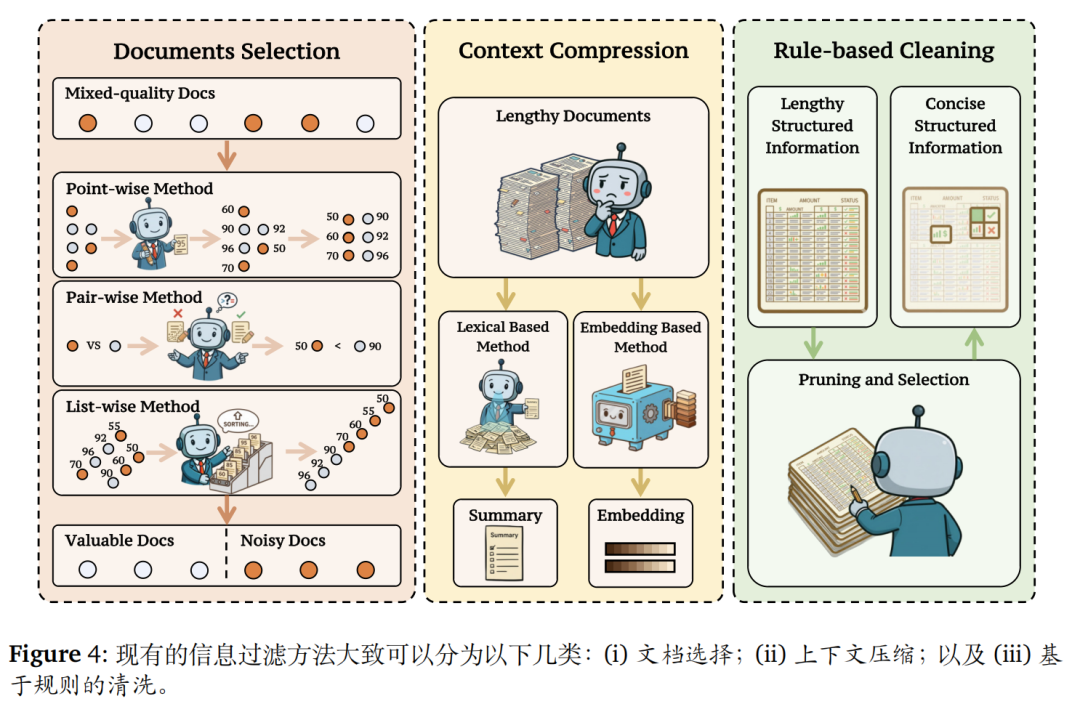
涉及到的点如下:
检索工具上,文本检索(BM25、DPR)、多模态检索(LayoutLM、ChartReader)、商业搜索(Google/Bing);
检索时机上,自适应触发(基于置信度、内部状态、自然语言表达);
信息过滤上,文档选择(点/对/列表级排序)、内容压缩(词汇/嵌入级)、规则清洗(如HtmlRAG去冗余)
3、内存管理
内存管理维持长周期任务的上下文连贯性。
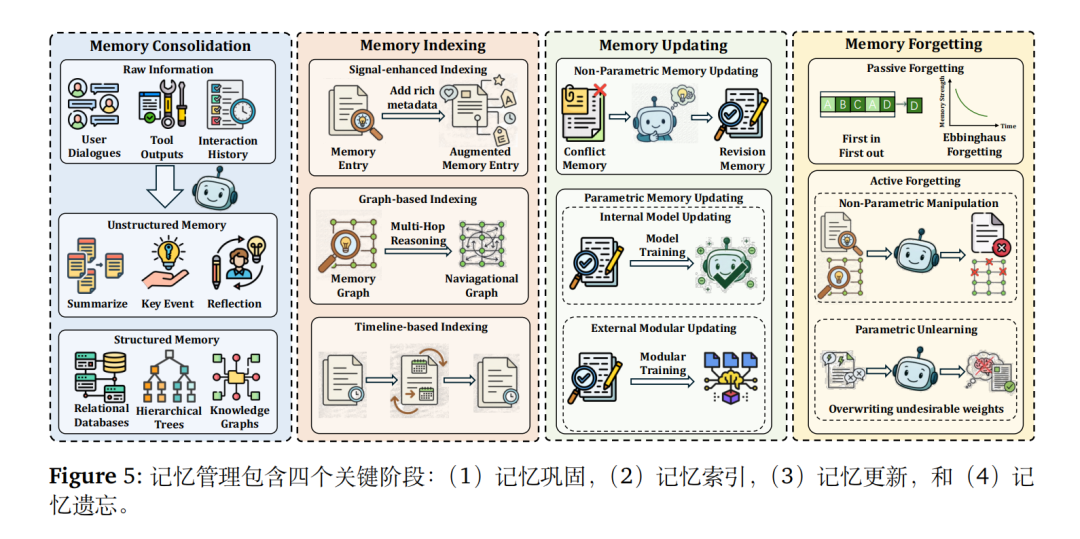
包括以下几个点:
内存整合:将短期信息转化为长期存储(结构化 / 非结构化);
内存索引:信号增强、图结构、时间线索引;
内存更新:非参数更新(整合冲突信息)、参数更新(模型权重微调);
内存遗忘:被动遗忘(FIFO、艾宾浩斯曲线)、主动遗忘(删除无效信息)
4、答案生成
答案生成的核心是合成高质量、可验证输出。
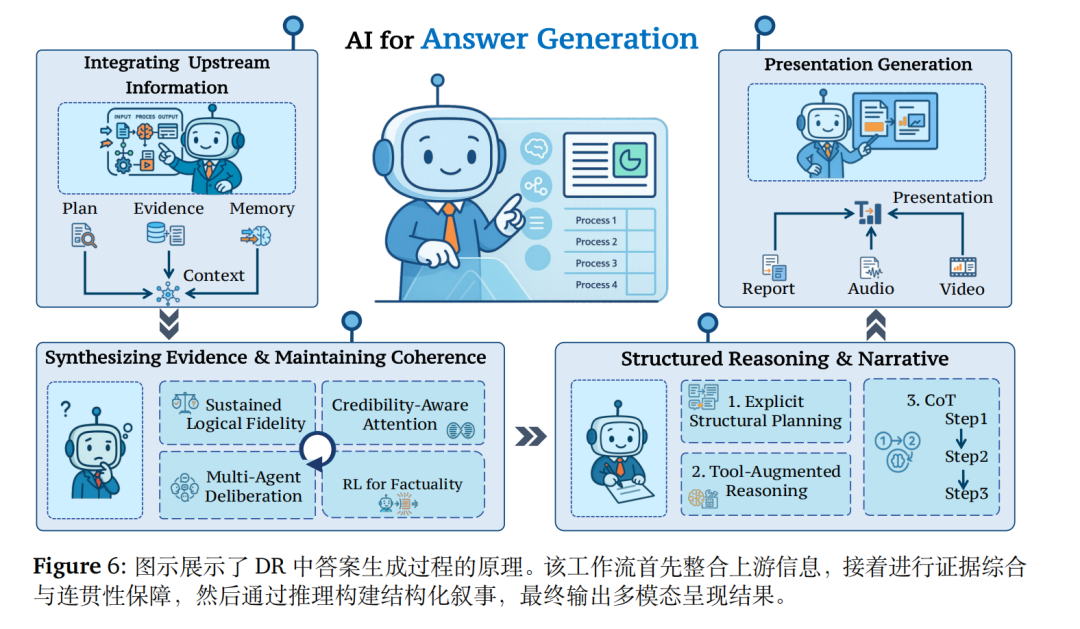
核心步骤上,先整合上游信息->解决证据冲突->结构化推理->多模态呈现,实现难度上,需要做可信度感知注意力、多智能体审议、强化学习优化事实性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)