大模型常用精度
双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4)INT8、INT4 (也有INT3/INT5/INT6的)在正常情况下,大模型的参数多以浮点数的形式存在,不考虑算力的情况下,一般原始的模型的参数是32位的浮点数,也就是FP32。在计算机中一个字节是8位,那么一个。
-
浮点数精度:双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4)
-
量化精度:INT8、INT4 (也有INT3/INT5/INT6的)
在正常情况下,大模型的参数多以浮点数的形式存在,不考虑算力的情况下,一般原始的模型的参数是32位的浮点数,也就是FP32。在计算机中一个字节是8位,那么一个FP32参数也就是4个字节大小,而12B的大模型也就是120亿参数,也就是480亿字节大小,通过二进制(1024)转换,也就是47GB大小,这么大的模型文件对于电脑性能显存的要求是非常高的,为了能够在算了有限的条件下使用大模型,因此就出现了量化的概念。
浮点数存储方式,由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。符号位都是1位,指数位影响浮点数范围,小数位影响精度。
1. FP精度
Floating Point,是最原始的,IEEE定义的标准浮点数类型。由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。
FP64 表示64位浮点数,通常为IEEE 754定义的双精度二进制浮点格式,由1位符号位、11位指数位、52位尾数位组成:
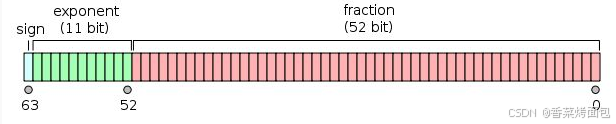
FP32 表示32位浮点数,通常为IEEE 754定义的单精度二进制浮点格式,由1位符号位、8位指数位、23尾数位组成:

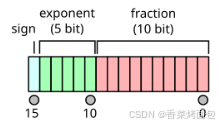
FP16 表示16位浮点数,通常为IEEE 754定义的半精度二进制浮点格式,由1位符号位、5位指数位和10位尾数位组成:

FP8 是由Nvidia在Hopper和Ada Lovelace架构GPU上推出的数据类型,论文地址:https://arxiv.org/abs/2209.05433,有如下两种形式:
- E4M3:由1位符号位、4位指数位和3位尾数位组成
- E5M2:由1位符号位、5位指数位和2位尾数位组成
E4M3支持的动态范围更小,精度更高,E5M2支持的动态范围更广,精度更低,而LLM推理过程对精度要求较高,对数值范围要求较低,故二者中FP8-E4M3更适合推理。
由于浮点数的特性,FP8表示的数值是非均匀的,越靠近0,分布越稠密,越远离0,分布越稀疏,因此FP8对较大值的精度较差,但对较小的值的精度较好。
FP4 代表 4 位浮点数量化,它使用一种特殊的格式来表示数值,具体来说是一位符号位,两位指数位和一位尾数位。这种格式允许表达更广泛的数值范围,相比整数量化,FP4 能在较低的比特率下更好地保持模型精度。FP4 适合于需要更多动态范围的场景,但仍追求低比特率的高效存储和计算。
-
FP4是2023年10月由某学术机构定义,论文地址:https://arxiv.org/abs/2310.16836
FP64、FP32、FP16、FP8、FP4都是类似组成,只是指数位和小数位不一样,但是FP8和FP4不是IEEE的标准格式
|
格式 |
符号位 |
指数位 |
小数位 |
总位数 |
|
FP64 |
1 |
11 |
52 |
64 |
|
FP32 |
1 |
8 |
23 |
32 |
|
FP16 |
1 |
5 |
10 |
16 |
|
FP8-E4M3 |
1 |
4 |
3 |
8 |
|
FP8-E5M2 |
1 |
5 |
2 |
8 |
|
FP4 |
1 |
2 |
1 |
4 |
2. TF32
Tensor Float 32,英伟达针对机器学习设计的一种特殊的数值类型,用于替代FP32,首次在A100 GPU中支持。
TensorFloat-32,是 Nvidia 在 Ampere 架构的 GPU 上推出的专门运用于 TensorCore 的一种计算格式。其与其他常用数据格式的比较:
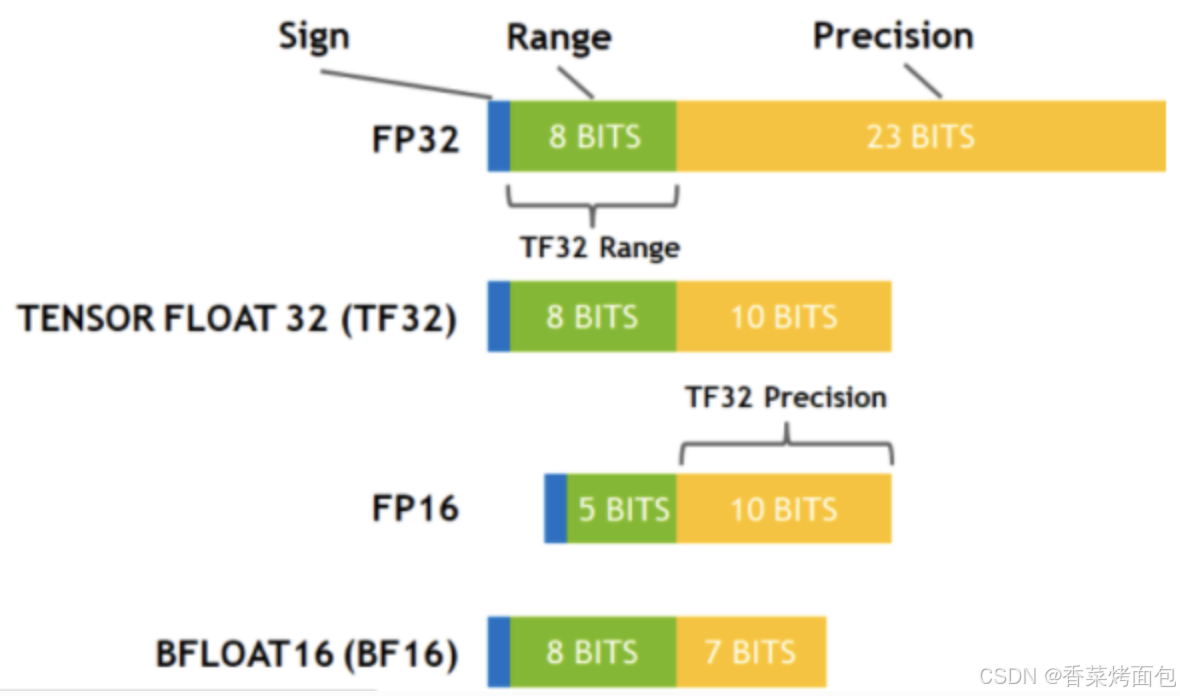
在 A100 上,使用 TF32 进行矩阵乘法运算可以比 V100 上使用 FP32 CUDA Core 运算提升 8x 的速度(TF32 对精度基本无影响)。 请注意,TF32 仅仅是在使用 TensorCore 时的一种中间计算格式,它并不是一个完全的数据类型。
前置条件:
- 矩阵乘法及卷积相关运算,且输入数据类型为 FP32,才可以使用 TF32 作为 TensorCore 的中间计算类型。
- Ampere 架构的 GPU
在 Ampere 架构的 GPU 上,默认启用了 TF32 来进行计算加速。但是并不是每一个矩阵及卷积计算都一定会使用 TF32,跟输入数据类型,输入的形状等因素都有一定的关系。
3. BF16
Brain Float 16,一种特殊的数据存储格式,为解决FP16应用在深度学习上时动态范围太窄的问题,由Google开发的16位格式 Brain Floating Point Format。
由1个符号位,8位指数位(和FP32一致)和7位小数位(低于FP16)组成:
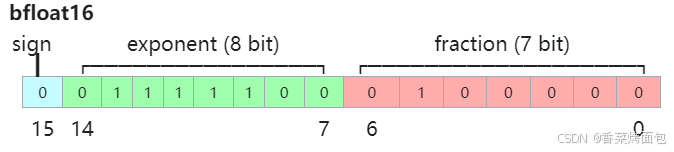
BF16保持与BF32相同的指数范围,但牺牲了一部分精度,所以精度低于FP16,但是表示范围和FP32一致,和FP32之间很容易转换。
4. NF4
4-bit NormalFloat,一种用于量化的特殊格式,于23年5月由华盛顿大学在QLoRA量化论文中提出,论文地址:https://arxiv.org/abs/2305.14314
论文解读参考:https://fancyerii.github.io/2023/12/14/qlora/#4-bit-normalfloat-quantization
NF4 是建立在分位数量化技术的基础之上的一种信息理论上最优的数据类型,把 4 位的数字归一化到均值为 0,标准差为 [-1,1] 的正态分布的固定期望值上。
NF4 相比于FP4,也是一种 4 位的浮点量化格式,但它采用了一种非均匀的数值分布,通常接近正态分布。这意味着 NF4 更适合那些自然数据分布呈现正态特性的模型部分,比如权重或激活值。这种量化方式在某些情况下能够提供比均匀分布的 FP4 更好的精度,因为它能更高效地利用位来表示常见的数值范围。
当提到 “4-bit 量化” 时,如果没有特别指明是 FP4 还是 NF4,通常指的是使用 4 位来表示原本的浮点数值,它可以包括 FP4 或 NF4,或者是其他自定义的 4 位量化方案。4-bit 量化的目标都是在减少模型大小和计算需求的同时,尽可能维持模型性能。
NormalFloat(NF)数据类型建立在分位数量化的基础上,分位数量化是一种在信息理论上最优的数据类型,确保每个量化区间从输入张量中获得相等数量的值。
5. INT8
INT8 量化将模型中的权重和激活值从浮点数转换为 8 位有符号整数。这是最早也是最广泛使用的量化技术之一,因为它能显著减少模型大小并加速推理,但可能以牺牲一定的精度为代价。为了保持模型性能,通常需要精心设计的量化和去量化策略以及校准步骤。
style="display: none !important;">

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)