Datawhale 动手学大模型应用全栈开发教程
本内容主要为Datawhale的动手学大模型应用全栈开发教程做介绍和让人实践。
目录
背景
大语言模型(LLM)是语言模型演化的第四代产物,基于 “扩展法则” 通过扩大参数规模与训练数据量,形成小模型不具备的 “涌现能力”,代表性模型包括 GPT-3、ChatGPT、Llama 系列等。其发展历经统计语言模型(SLM)、神经语言模型(NLM)、预训练语言模型(PLM)三大阶段,最终实现从特定任务适配到通用能力突破的跨越。
大模型的构建核心分为三阶段:预训练阶段需依托数 T 级 token 的高质多元数据与海量算力(如 Llama-3 训练规模达 15T),为模型参数奠定优质基础;有监督微调(SFT)通过数十万至百万级指令数据,激活模型任务解决能力与指令遵循能力,无需灌输新知;对齐阶段通过 RLHF(基于人类反馈的强化学习)或 DPO(直接偏好优化)等方法,使模型输出契合人类价值观,其中 DPO 以更低复杂度成为高效替代方案。
根据技术开放程度,大模型分为开源与闭源两大阵营:开源阵营(如 Meta AI、浪潮信息)开放代码与数据集,推动技术民主化与学术创新;闭源阵营(如 OpenAI、百度)将模型作为核心竞争力,通过 API 提供专有服务以维持商业优势。两类模式并行发展,共同推动人工智能领域的技术迭代与产业落地。
温馨提示:
以下内容部分借鉴了Datawhale官方教程内容,内容介绍不太完整,完整版请借鉴DataWhale官方内容链接,教程链接如下:
https://www.datawhale.cn/activity/460/learn/242/5483
第一步前期准备
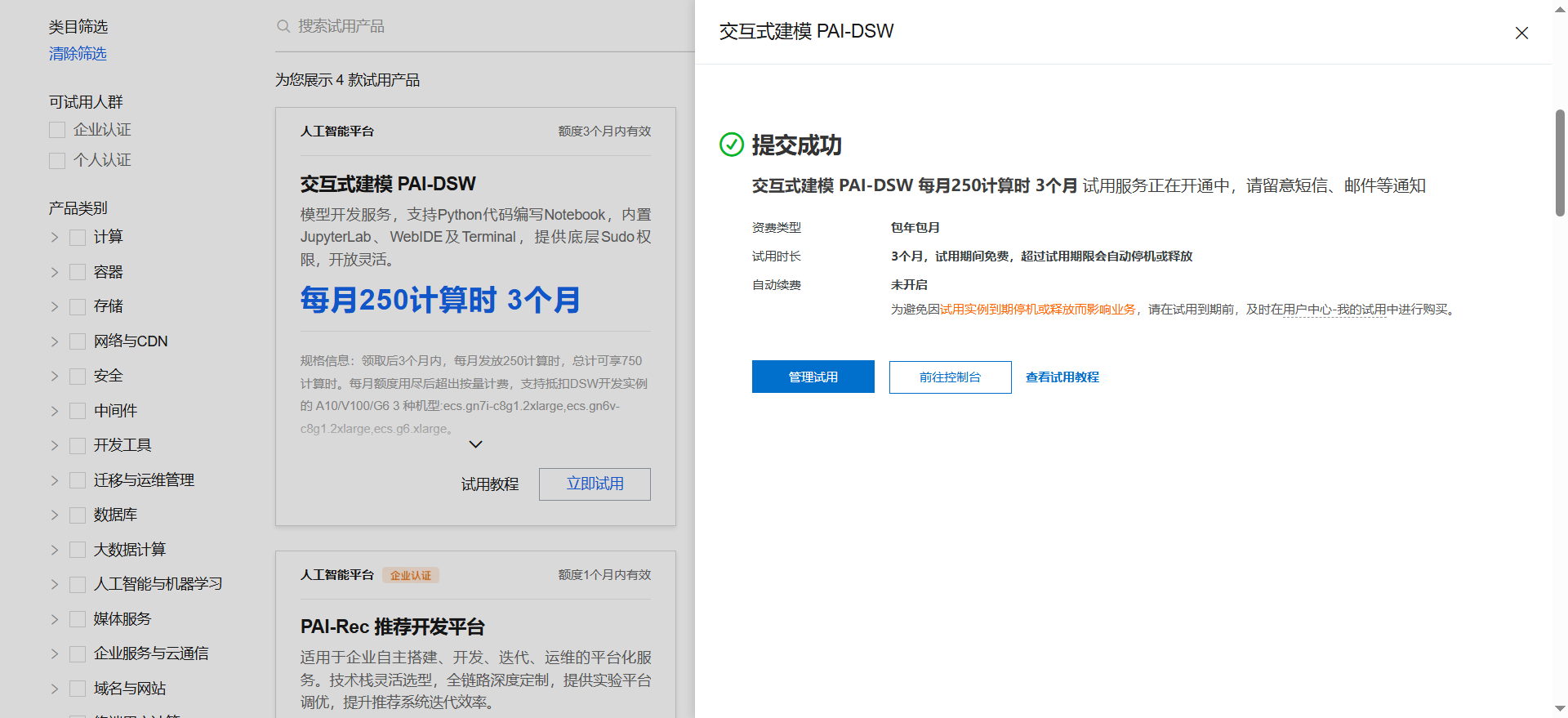
1.进入如下链接,登录,找到交互式建模PAI-DSW(每月250计算时3个月进行租用。如下图。
https://free.aliyun.com/?productCode=learn
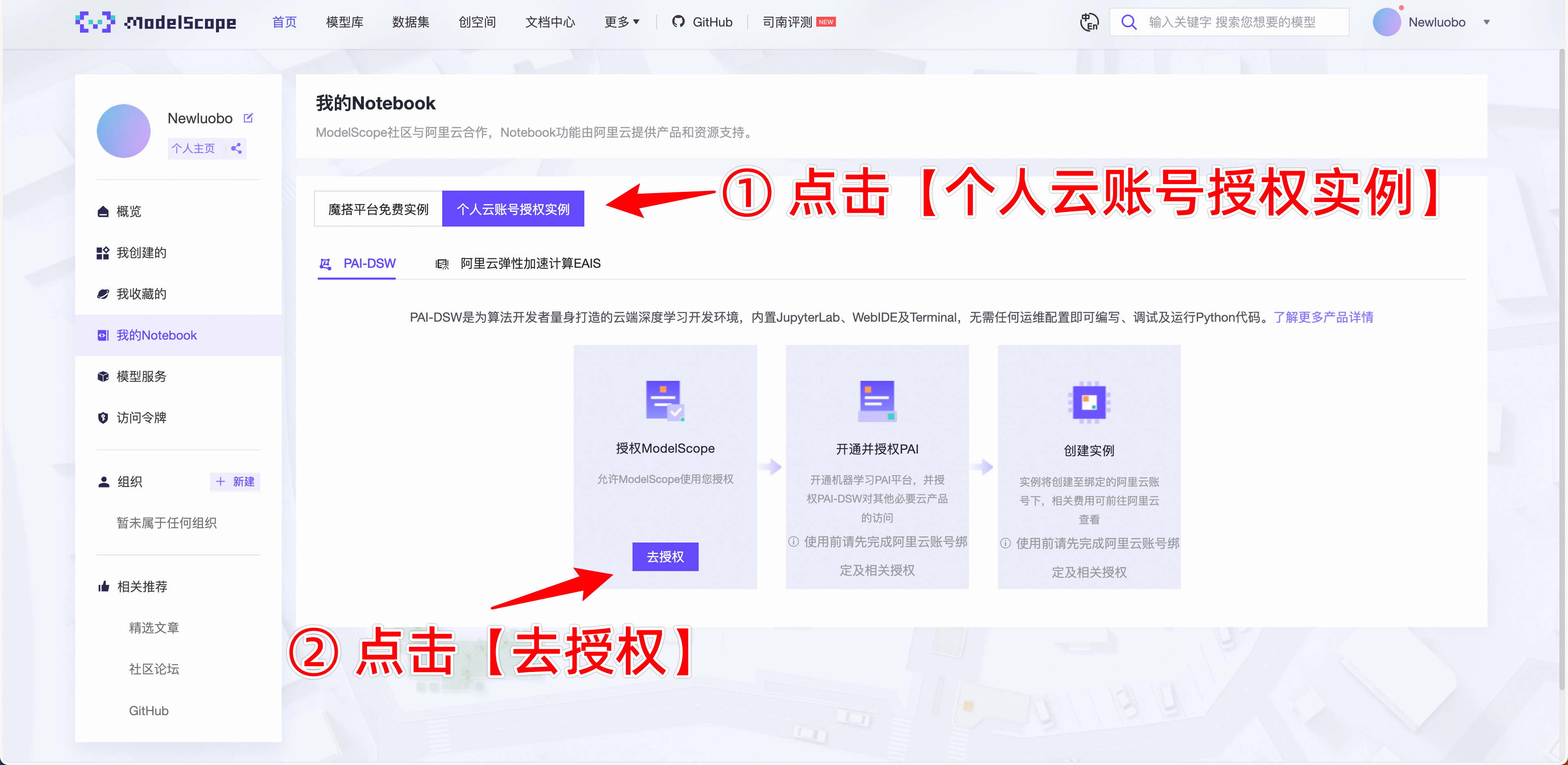
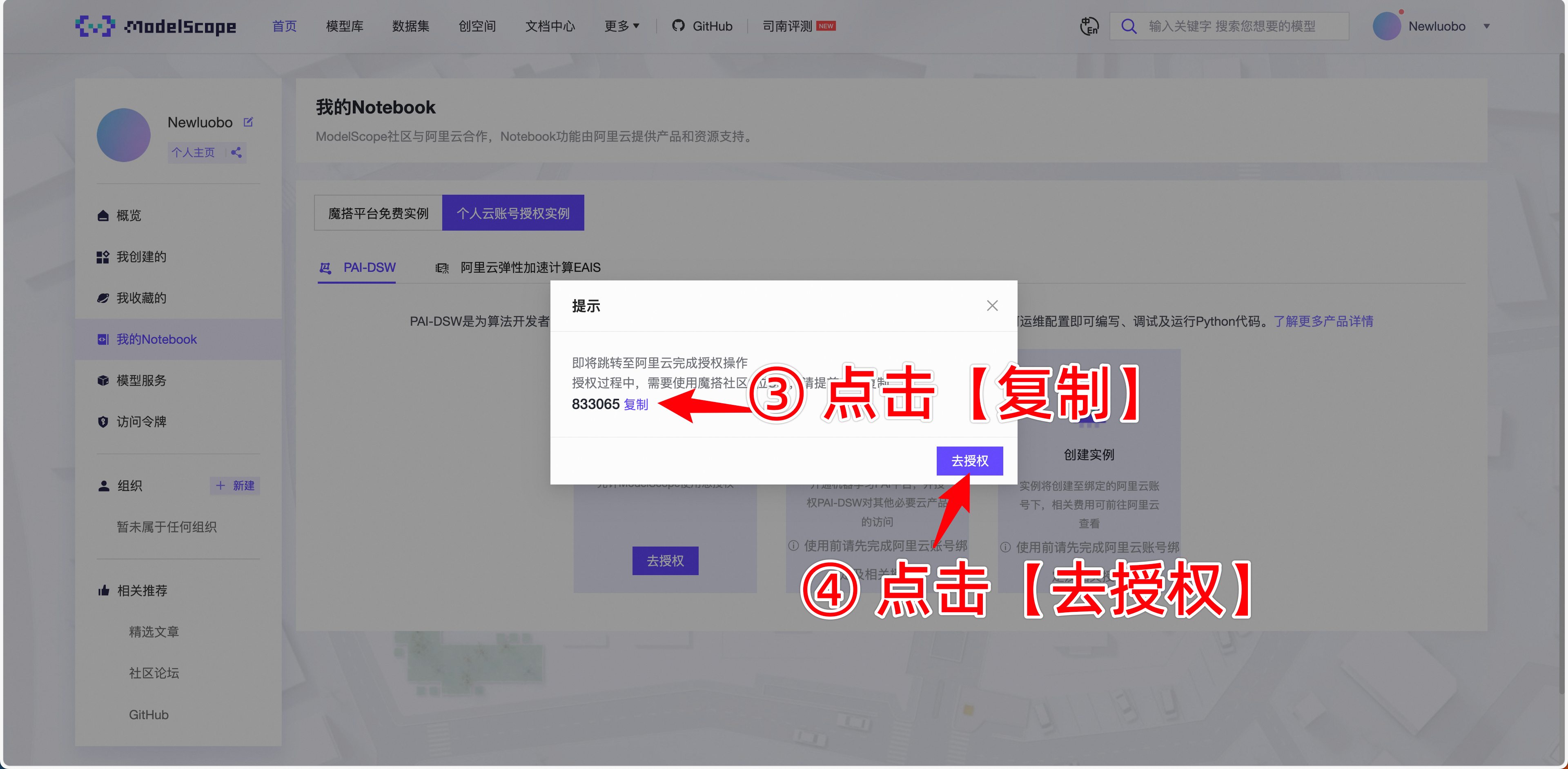
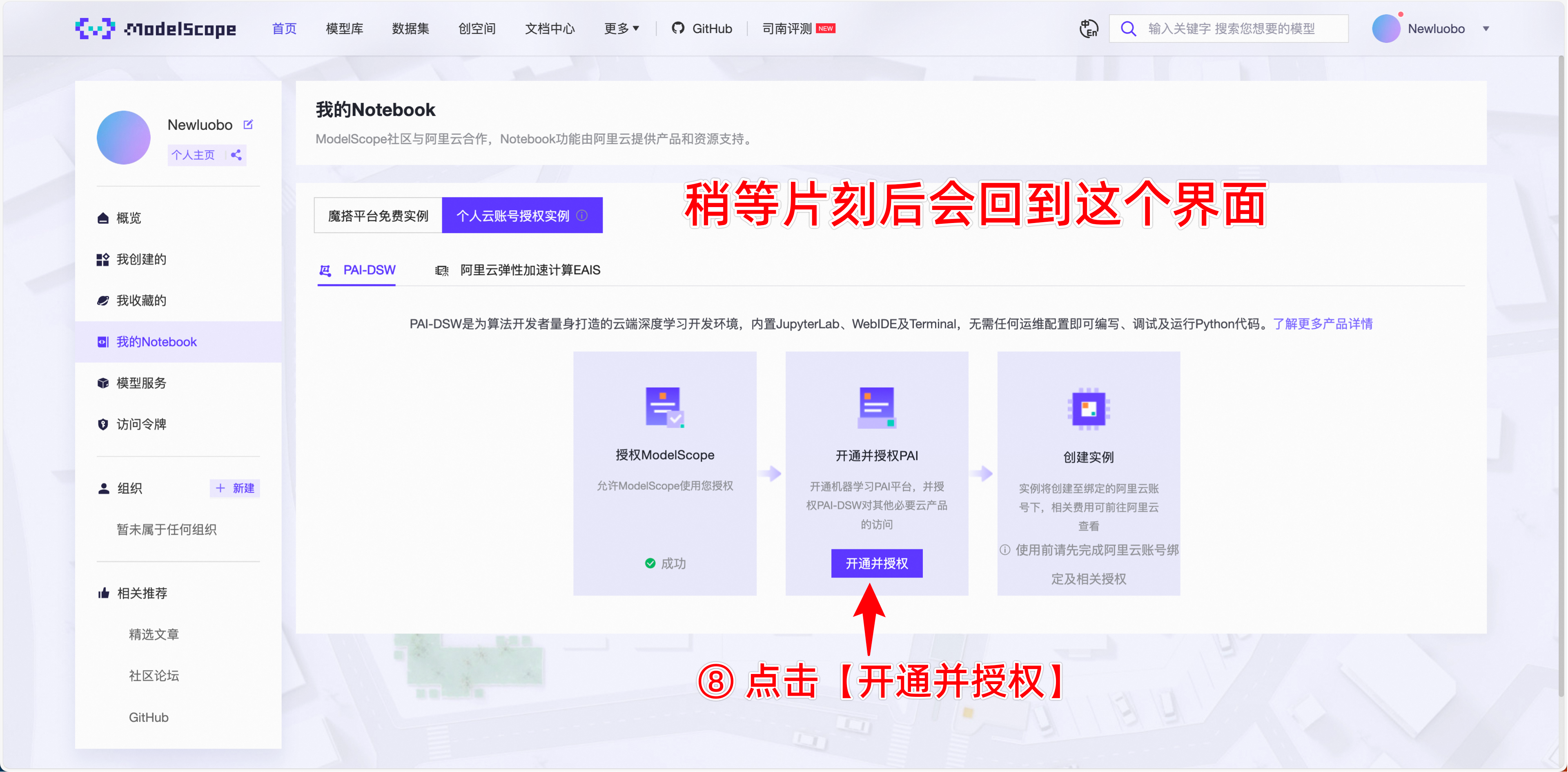
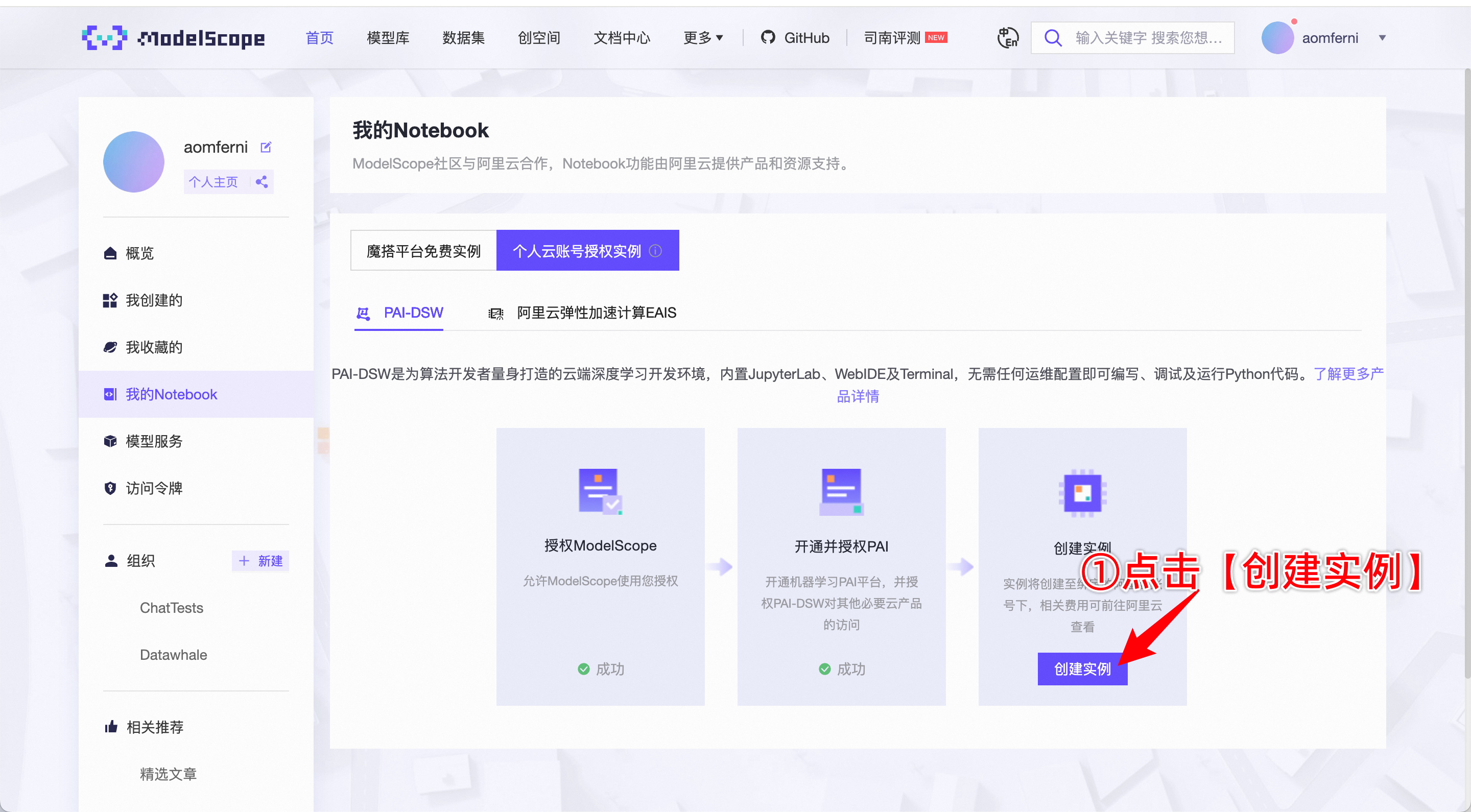
2.进入如下链接(新用户先注册,然后绑定阿里云账号,还需要完成阿里云账号的实名认证,直接完成即可)然后到个人主页,找到我的Notebook,按下图片指引操作。
https://www.modelscope.cn/my/mynotebook/authorization
3.在魔塔社区创建PAI实例,点击下面链接。完成上图的PAI需要。
https://www.modelscope.cn/my/mynotebook/authorization
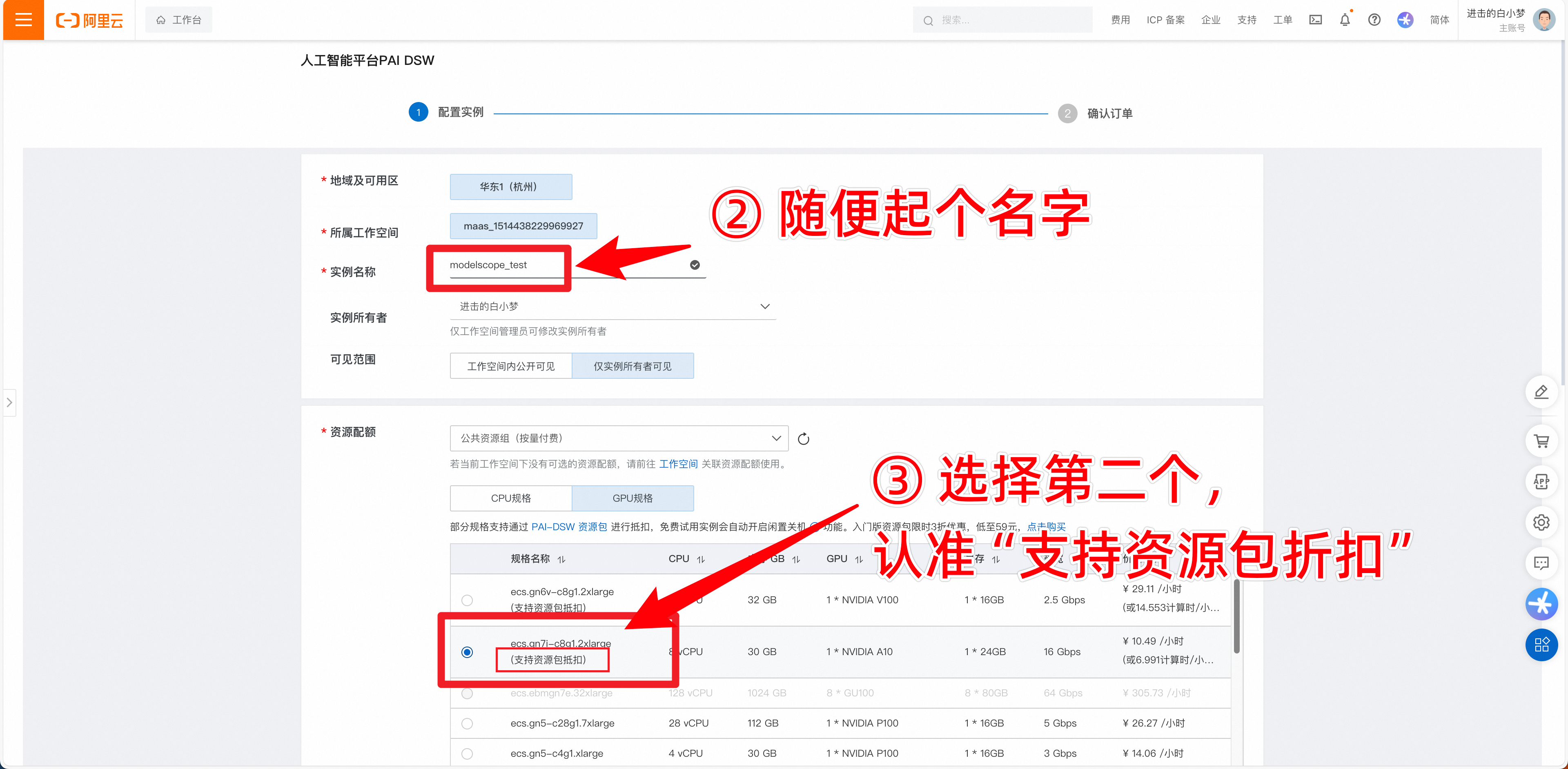
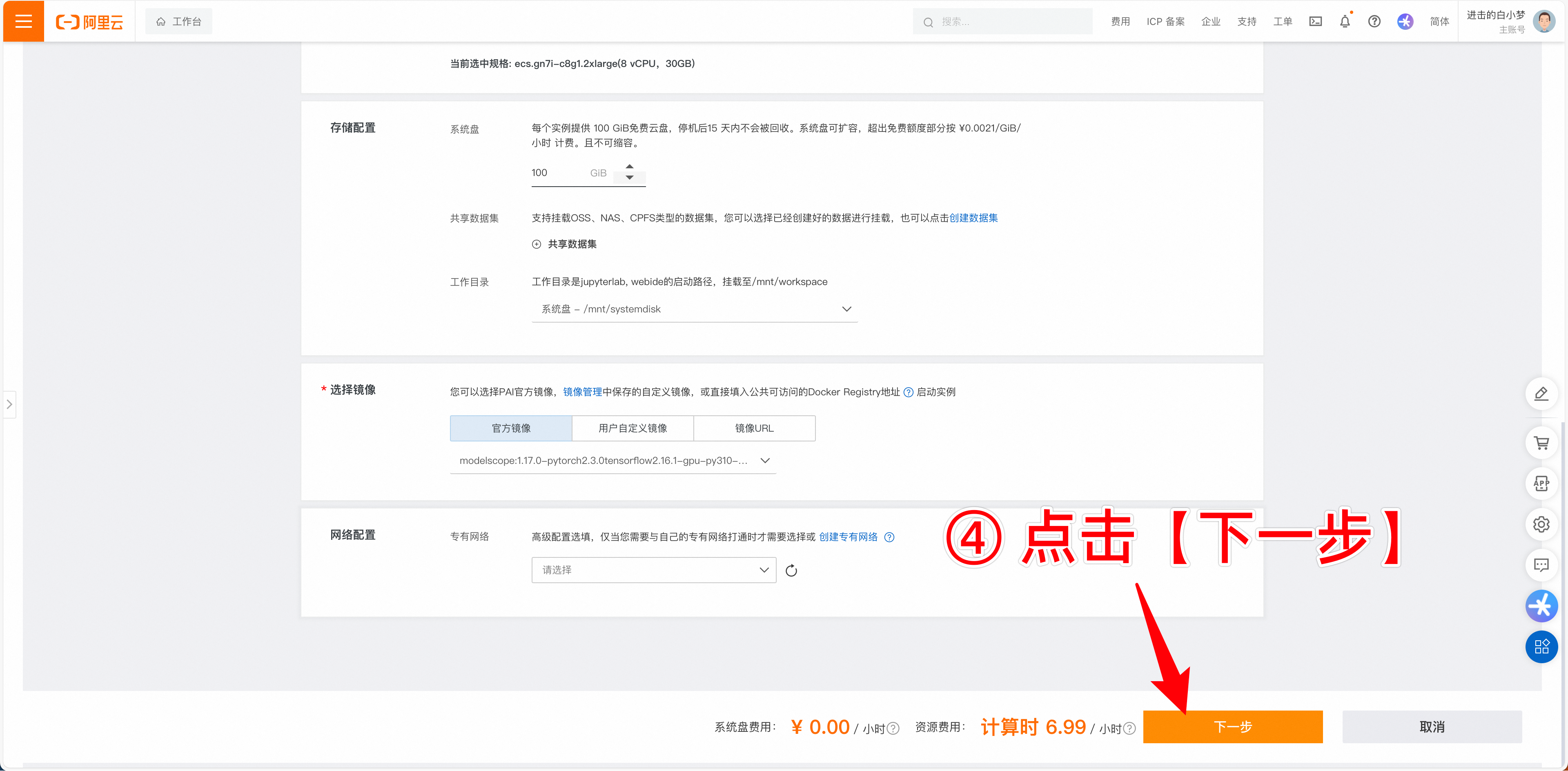
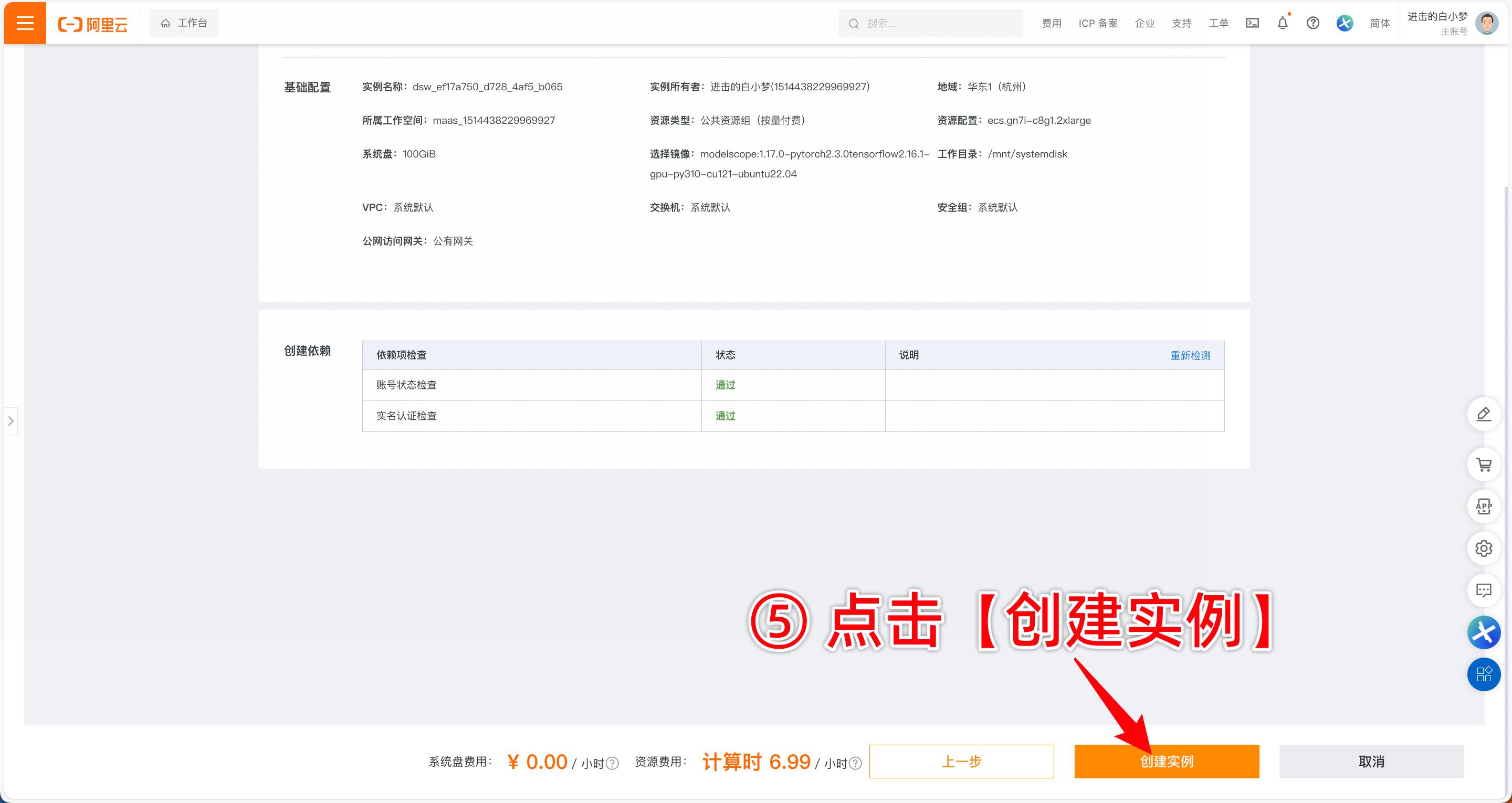
4.开始创建实例,按下图操作。
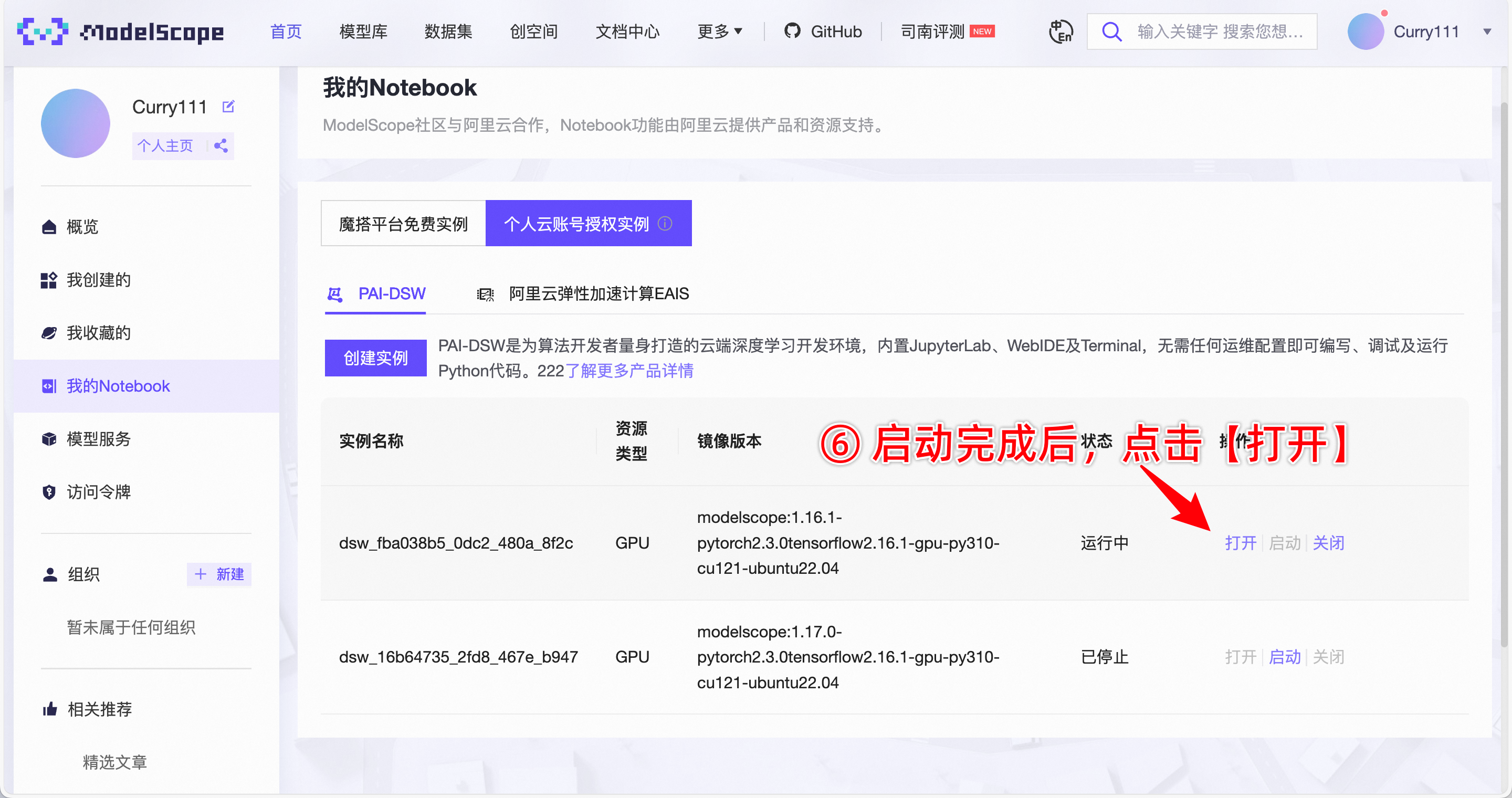
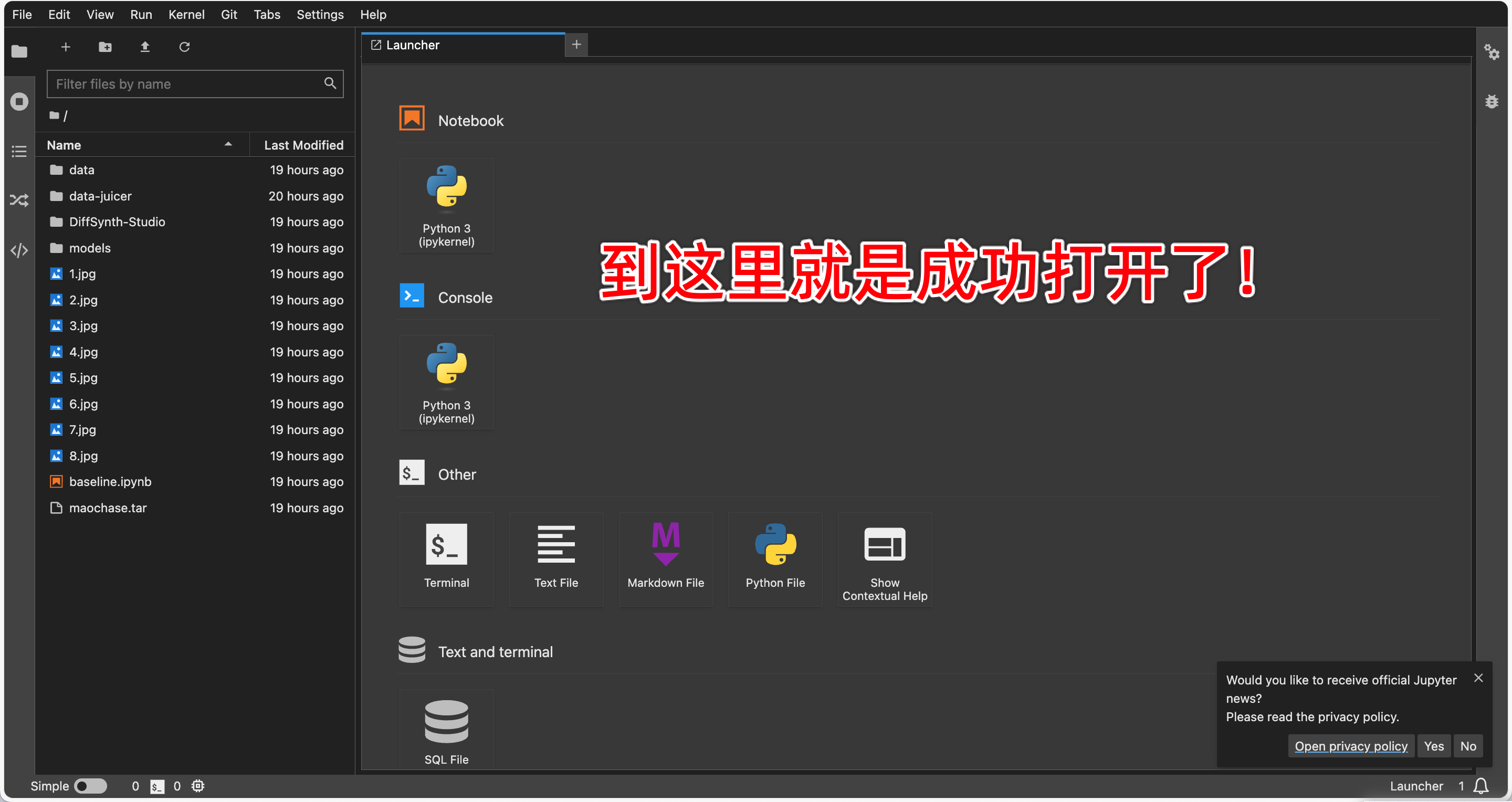
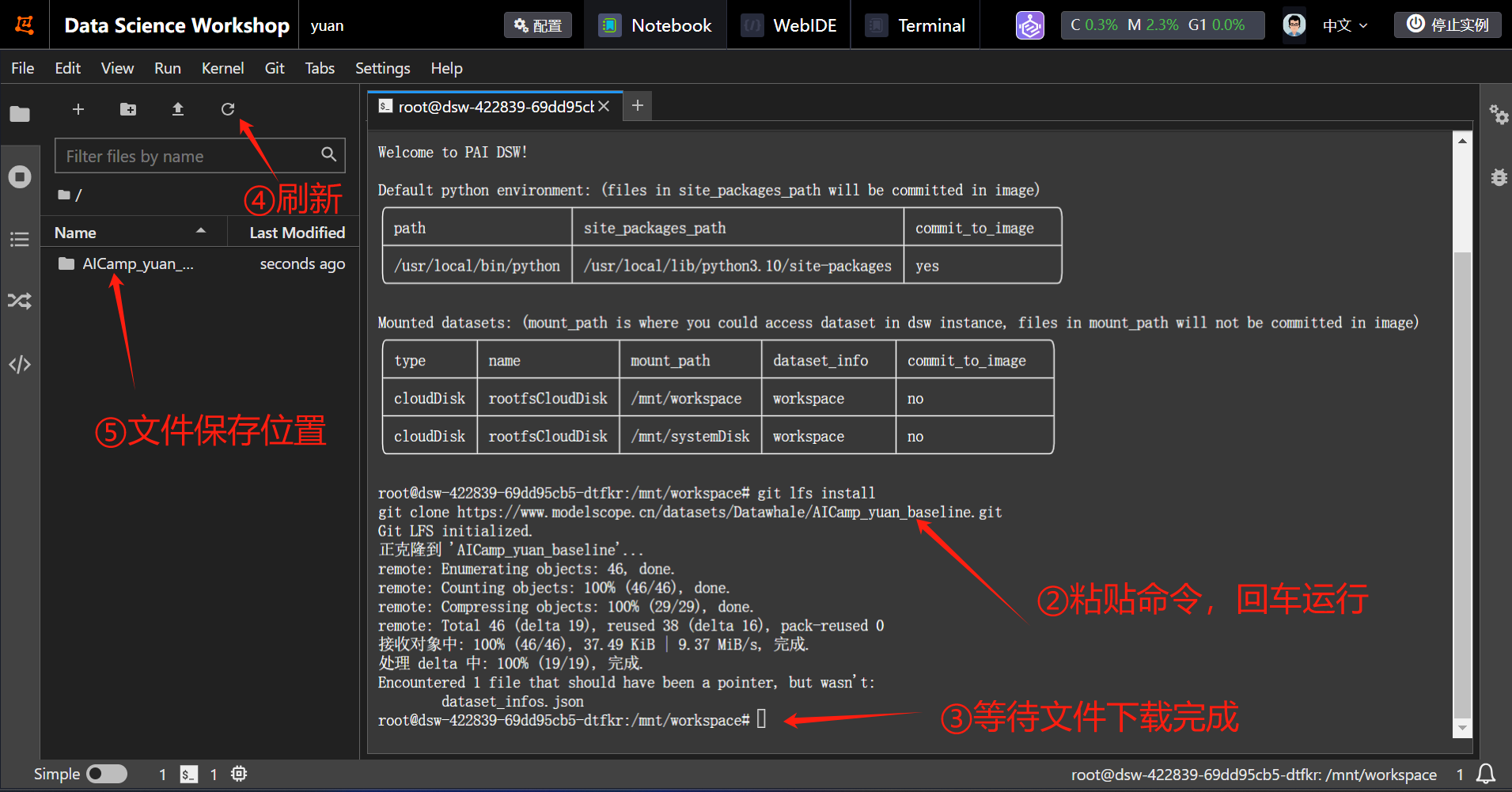
第二步:文件下载
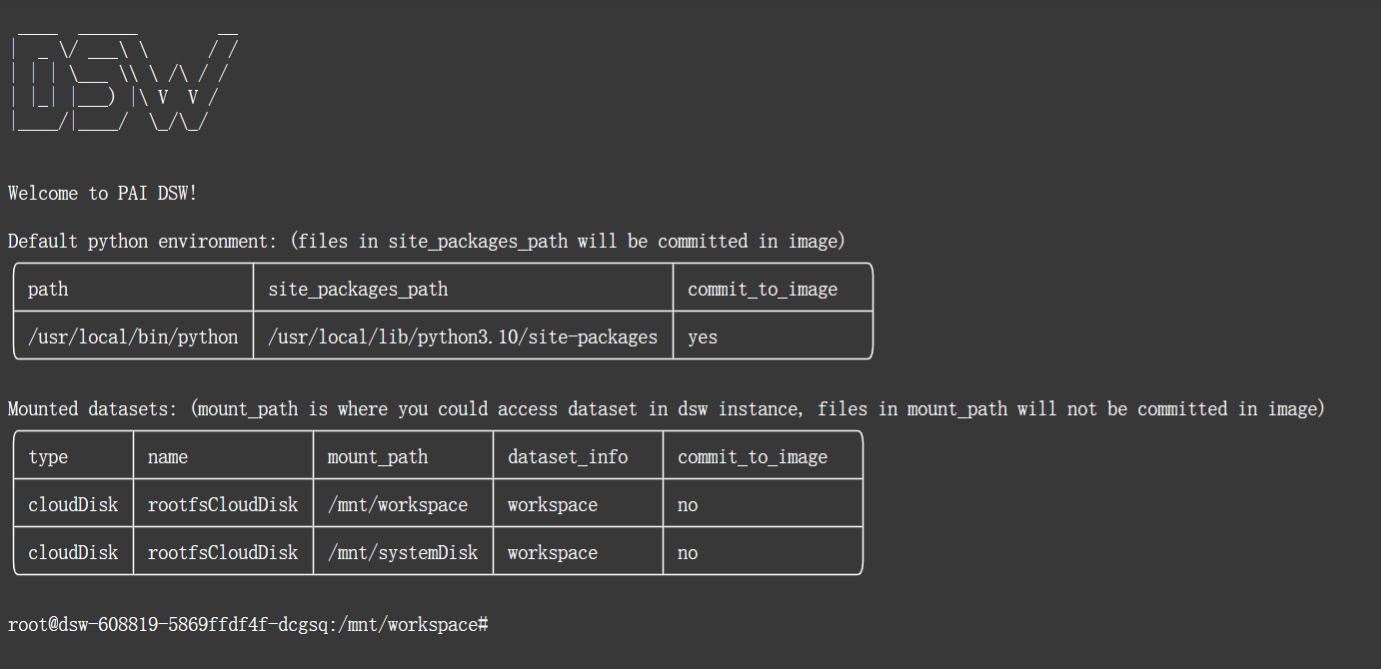
点击终端,然后输入如下命令,回车运行!
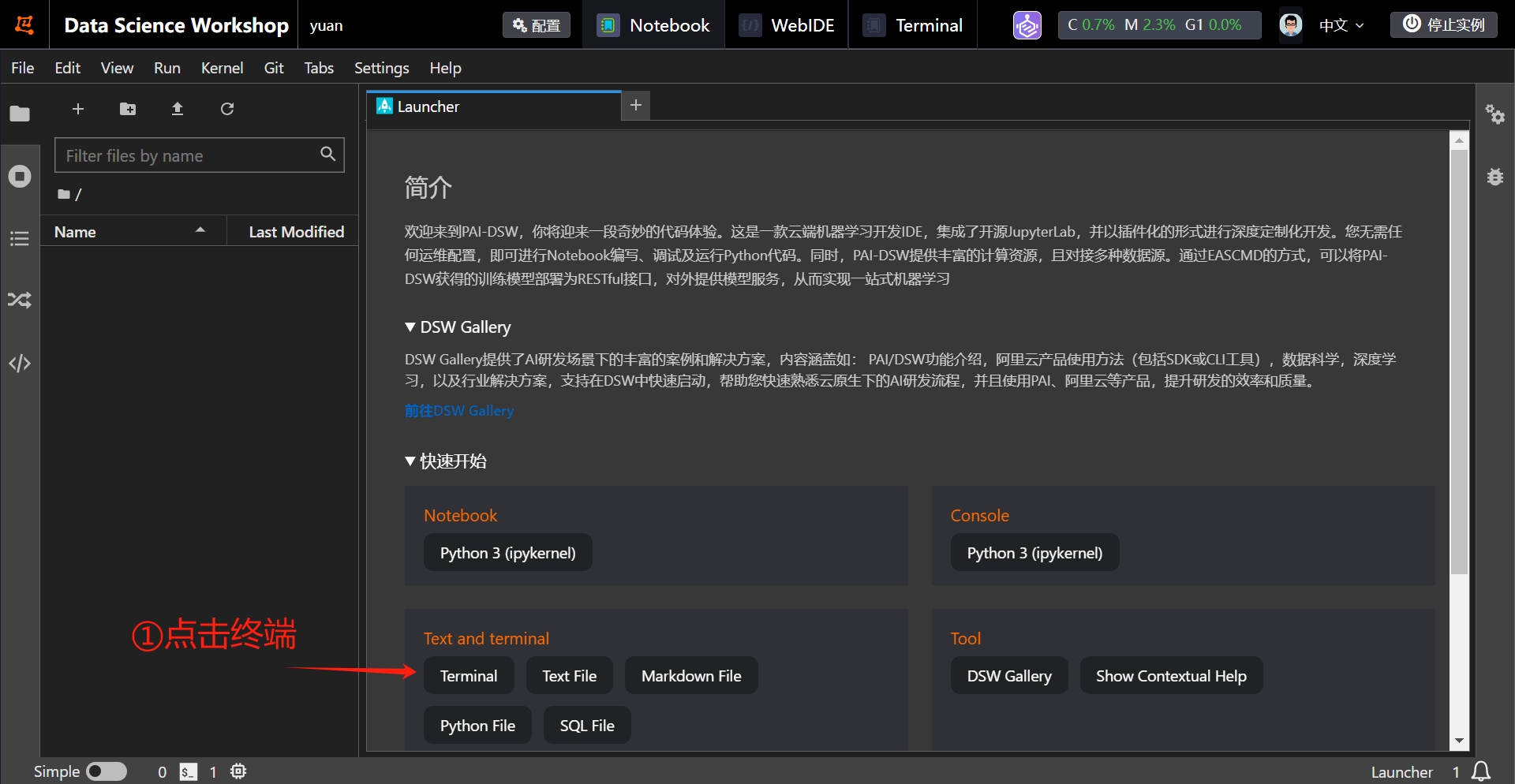
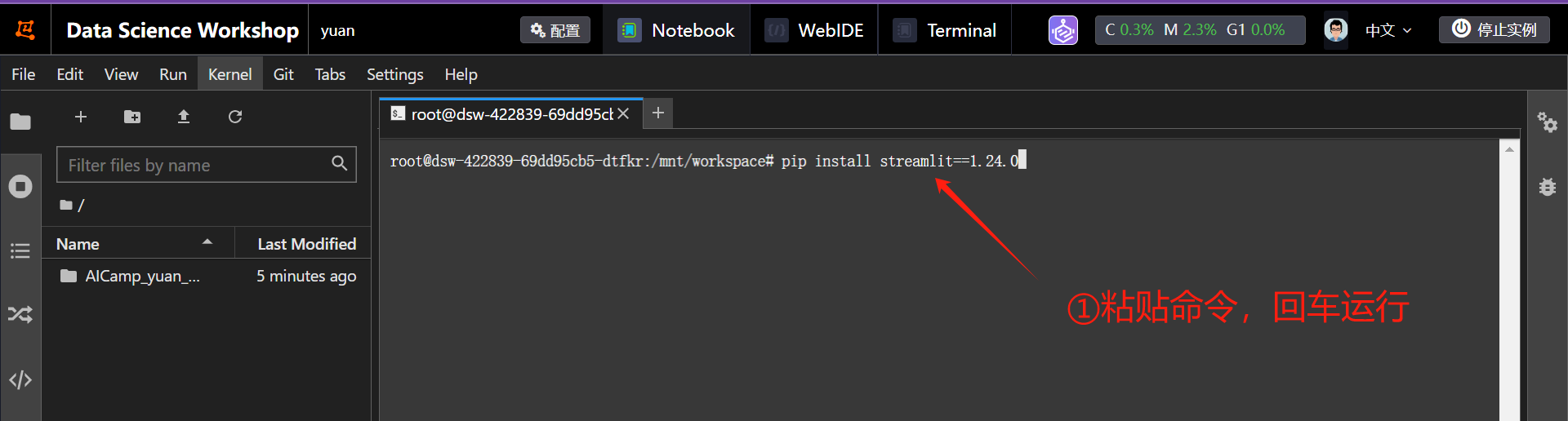
第三步:环境安装
点击终端,然后输入如下命令,回车运行!等待依赖安装成功!
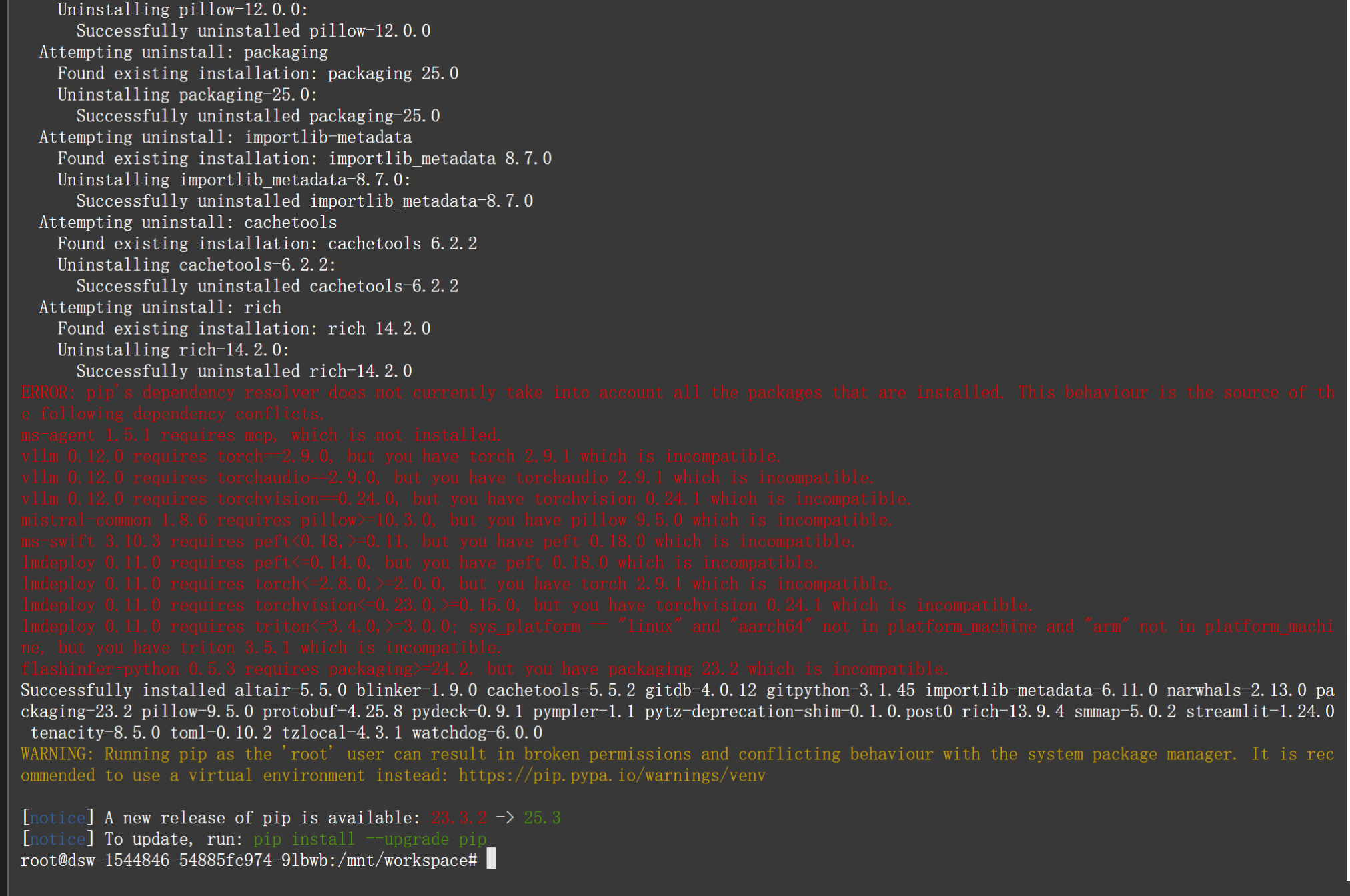
第四步:启动Demo
点击终端,然后输入如下命令,回车运行!点击链接,跳转到浏览器新页面!让他用Java打印一个hello app。
streamlit run AICamp_yuan_baseline/Task\ 1:零基础玩转源大模型/web_demo_2b.py --server.address 127.0.0.1 --server.port 6006
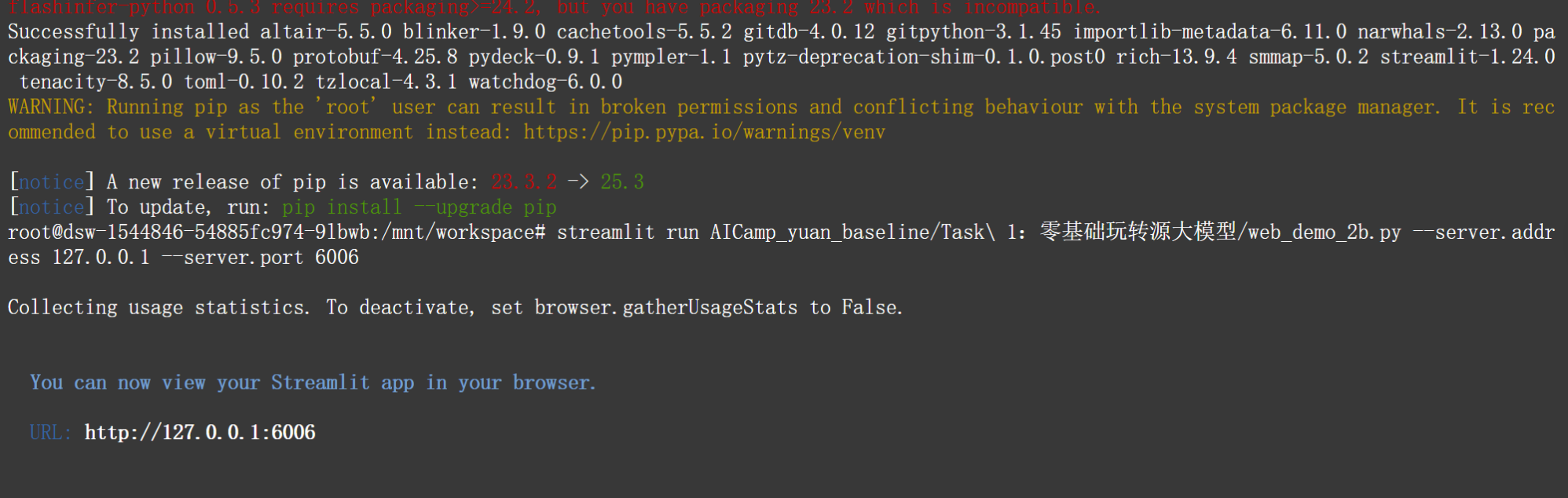
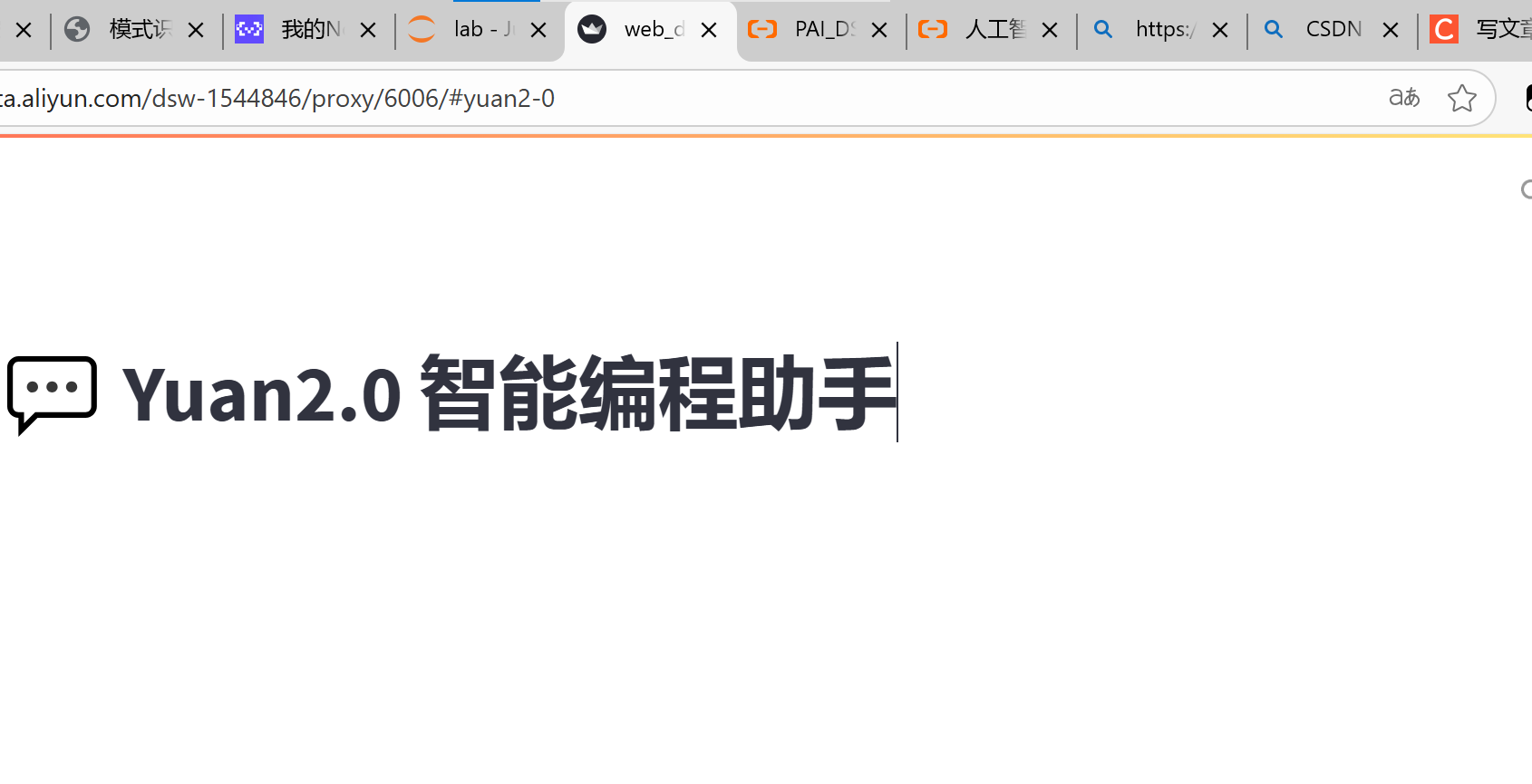
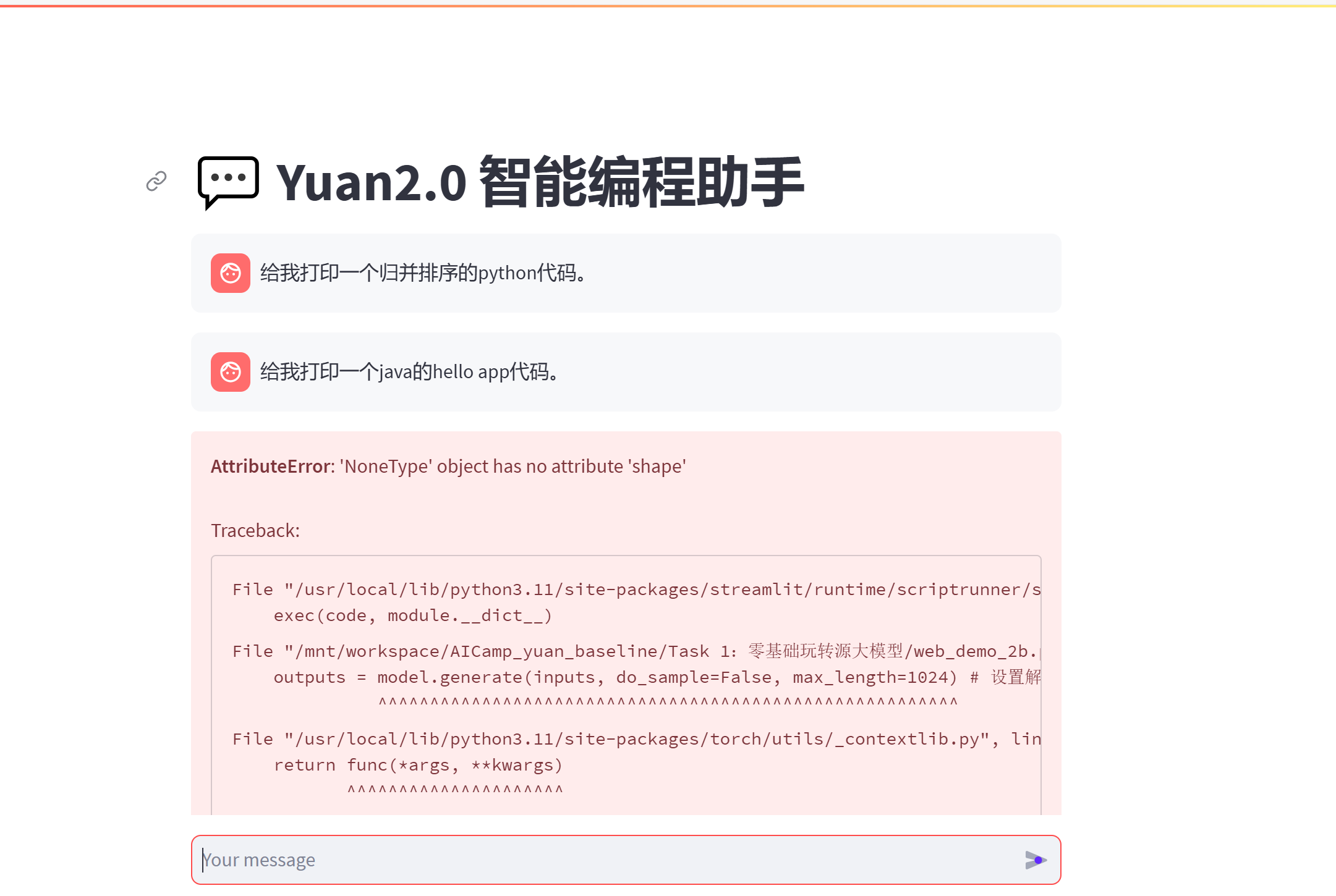
出现上图错误,下面是解决方法:
在运行快速demo的时候 可能会碰到AttributeError: 'NoneType' object has no attribute 'shape'的报错 ,已经找到解决方案:
修改代码内部web_demo_2b.py 第57行 outputs = model.generate(inputs, do_sample=False, max_length=1024)
修改为 outputs = model.generate(inputs, do_sample=False, max_length=1024,use_cache = False)
保存后重新在终端输入指令streamlit 指令运行即可
streamlit run AICamp_yuan_baseline/Task\ 1:零基础玩转源大模型/web_demo_2b.py --server.address 127.0.0.1 --server.port 6006

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)